







一直以来觉得爬虫这个东西很神秘很牛逼,但是又没有学过python,没有很好的学习教程。直到最近看到了Scottl老师的nodejs http爬虫的视频教学,才慢慢揭开爬虫的神秘面纱。根据老师一步一步书写代码爬取慕课网的章节信息,我对爬虫有了以下几个步骤的理解,并在此基础上完成了对熊猫Tv直播频道的爬虫程序。
首先阐述一下我认为的爬虫步骤:
1. 明确自己要爬的东西
2. 根据网页源代码,定义好相应的数据结构
3. 设计算法(笔者还没达到那个水平,只能写出很简单的算法,而且还是通过cheerio模块用的jquery语法)
4. 根据HTTP协议完成两端的通信
我的爬虫程序是用nodejs写的,因为最近在学这个东西,其中使用了express框架,以及cheerio和superagent两个模块。cheerio模块是nodejs处理html内容的神器,例如var $ = cheerio.load(html),将页面的html内容加载下来后,便可使用jquery语法进行操作,极为省力。superagent模块是http模块的升级,其链式的语法极大地方便了http方法的书写,而且代码十分整洁。
接下来看代码:
var express = require('express');
var cheerio = require('cheerio');
var superagent = require('superagent');
var url = 'http://www.panda.tv/all';
var app = express();
app.set('port', process.env.PORT || 3000);
function filterVideos(html) {
var $ = cheerio.load(html);
var videos = $('#later-play-list').children('li');
var videosData = [];
videos.each(function(item) {
var video = $(this);
var videoTitle = video.find('.video-title').text();
var videoInfo = video.find('.video-info');
var videoData = {
videoTitle:videoTitle,
videoInfo: []
}
videoInfo.each(function(item) {
var videoNickname = $(this).find('.video-nickname').text();
var videoId = $(this).find('.video-number').text();
var videoClass = $(this).find('.video-cate').text();
videoData.videoInfo.push({
name:videoNickname,
id:videoId,
cate:videoClass
})
})
videosData.push(videoData);
})
return videosData;
}
function printVideoInfo(videosData) {
var data = [];
videosData.forEach(function(item) {
var videoTitle = item.videoTitle;
item.videoInfo.forEach(function(videoInfo) {
data.push(videoTitle + '--------' + videoInfo.name + ' [' + '人数:' + videoInfo.id + ' ' + '类型:' + videoInfo.cate + ']');
// console.log(videoTitle + '--------' + videoInfo.name);
// console.log('人数:' + videoInfo.id + ' ' + '类型:' +videoInfo.cate + '\n');
})
})
return data;
}
app.get('/', function(req,res,next) {
superagent
.get(url)
.end(function(err,sres) {
if (err) {
return next(err);
} else {
var videosData = filterVideos(sres.text);
var data = printVideoInfo(videosData);
var result = '';
for (var i = 0 ; i < data.length ; i++ ) {
result += '<p>' + (i+1) + ':' + data[i] + '</p>' ;
};
res.send(result);
}
})
})
app.listen(app.get('port'));
filterVideos函数是将请求页面的html内容进行过滤,筛选我所需要的信息。这些数据的结构如图:

printVideoInfo函数是将我的数据结构转化为一定的格式,使之更清晰明了地显示在页面上。
最后通过一个路由把数据发送到页面上。有一个小问题是,通过printVideoInfo函数得到的data是一个数组,如何把数组的每个元素逐行打印到页面上呢?我首先想当然地通过一个for循环,每次send一个元素,结果如何?页面只显示了数组的第一个元素,并且命令行上报了一个cant set headers after they are send.虽然不太懂原理,大概就是不能重复send的意思吧…(逃)。之后便有了这个方法,把每个元素包装上< p>,通过一个循环把所有的< p>语句连接到一个字符串result中,再进行res.send(result)就成功了。结果如下图(不同时间点的直播信息不同):
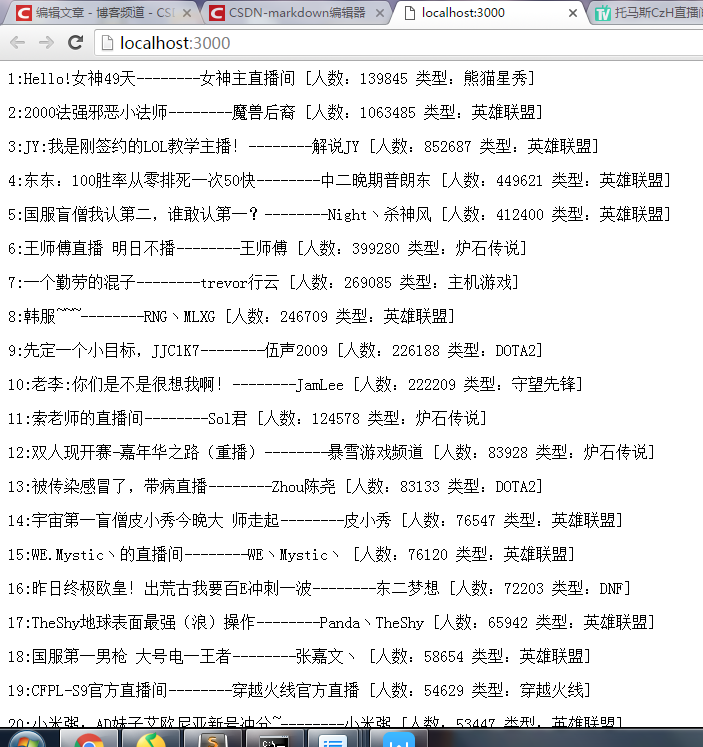
到这里一个简易的爬虫程序就完成了。虽然这个程序没有很复杂的算法,也只取到了首页的直播数据,但也是一个nodejs小白的第一个爬虫程序,各位大神非喜勿喷!















 391
391

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









