









论文作者:
Minh Tang Luon (Stanford University)
Iiya Sutskever (Google)
Quoc V.Le (Google)
Orial Vinyals (Google)
Wojciech Zaremba (New York Univerity)
这篇论文一看就感觉是一个很好的研究工作,对一个很具体又很重要的问题展开。
摘要
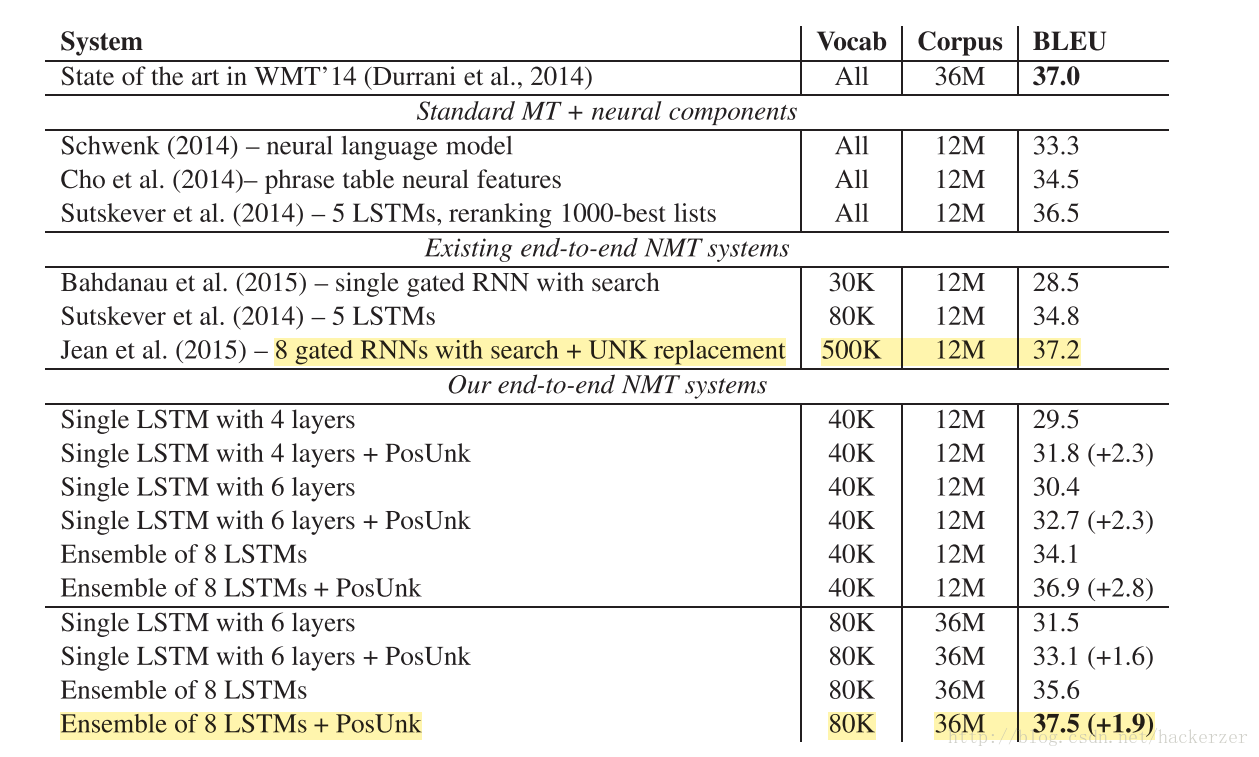
文章的方法是在经过对齐算法处理的数据上进行训练NMT系统,然后再经过post-processing来翻译OOV,模型在WMT’14 English to French的任务提升了2.8 BLUE值,以37.5 BLUE值得分在WMT’14 contest task达到了最优的结果
与Standard phrase-based systems 的比较
pros:
1、模型通用:任何 sequence-to-sequence都可以进行建模处理
2、泛化性能强:在训练语料中没有出现的句子也可以提供翻译
3、不需要额外的短语表与语言模型
4、NMT 系统易于实现
cons:
处理不好OOV情况,如下图对比了phrase-base与NN的翻译结果,phrase-base的方法有显式的对齐处理算法,所以具有处理OOV词语的能力。

NMT related works

similar to Graves (2013) and Graves et al. (2014). TODO
与本文有相似的解决问题的文献,比较感兴趣其中对于softmax的近似 TODO 加入阅读计划
S´ebastien Jean, Kyunghyun Cho, Roland Memisevic, and Yoshua Bengio. 2015. On using very large tar- get vocabulary for neural machine translation. In ACL
对齐数据
本文处理OOV的方法是在训练语料上学对齐规则,对齐模型在phrase-based 模型中也是经常使用的一种。
运用的模型:Berkeley aligner [2] TODO 应该很值得一读
对齐模型也为post-process的翻译过程服务。
文章中尝试了三种对OOV对齐的标注:


注意到unkpos1 是与源端的非OOV对齐的,所以在第二种与第三种采用位移的方法是可以表示出来的,第三种方法解决了第二种需要将target端长度增倍的弊端(训练起来复杂,而且还会引入额外的噪声?)
感受一下训练时间,参数大的情况下,模型复杂优化起来也复杂:Training takes about 10-14 days on an 8-GPU machine
ensemble model 深度学习模型集成|||==》真是不怕麻烦|||
结果
参考文献
非常经典的工作,有时间一定要跑一下这个代码
[1]D. Bahdanau, K. Cho, and Y. Bengio. 2015. Neural machine translation by jointly learning to align and translate. In ICLR
[2]P. Liang, B. Taskar, and D. Klein. 2006. Alignment by agreement. In NAACL.














 897
897











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









