







目录
写在前面
【课程说明】人体姿态估计(Human Pose Estimation)是计算机理解人类动作、行为必不可少的一步,本次课程涵盖人体姿态估计的介绍与应用、2D 姿态估计、3D 姿态估计、DensePose、Body Mesh 以及 MMPose 等内容。
【讲师介绍】卢策吾 上海交通大学电院计算机系教授、博士生导师。
【课程地址】https://www.bilibili.com/video/BV1k
【ToDo】本课作为概论性质的介绍,内容挺多,因此打算再分为两到三次笔记进行学习和总结,敬请期待!
0. 人体姿态估计的介绍与应用
什么是姿态估计?
从给定图像中识别人、手、身体的关键点(人脸68个关键点,手势21个关键点,人体18个关键点),从而预测人体关键点在二维或者三维空间的坐标,恢复视频中的动作,还原人体的姿态
人体参数化模型:从图像或者视频中会付出运动的3D人体模型
PoseC3D:基于人体姿态识别动作
下游任务:拥抱、CG、动画、人机交互(手势识别)、动物行为分析等
1. 2D姿态估计
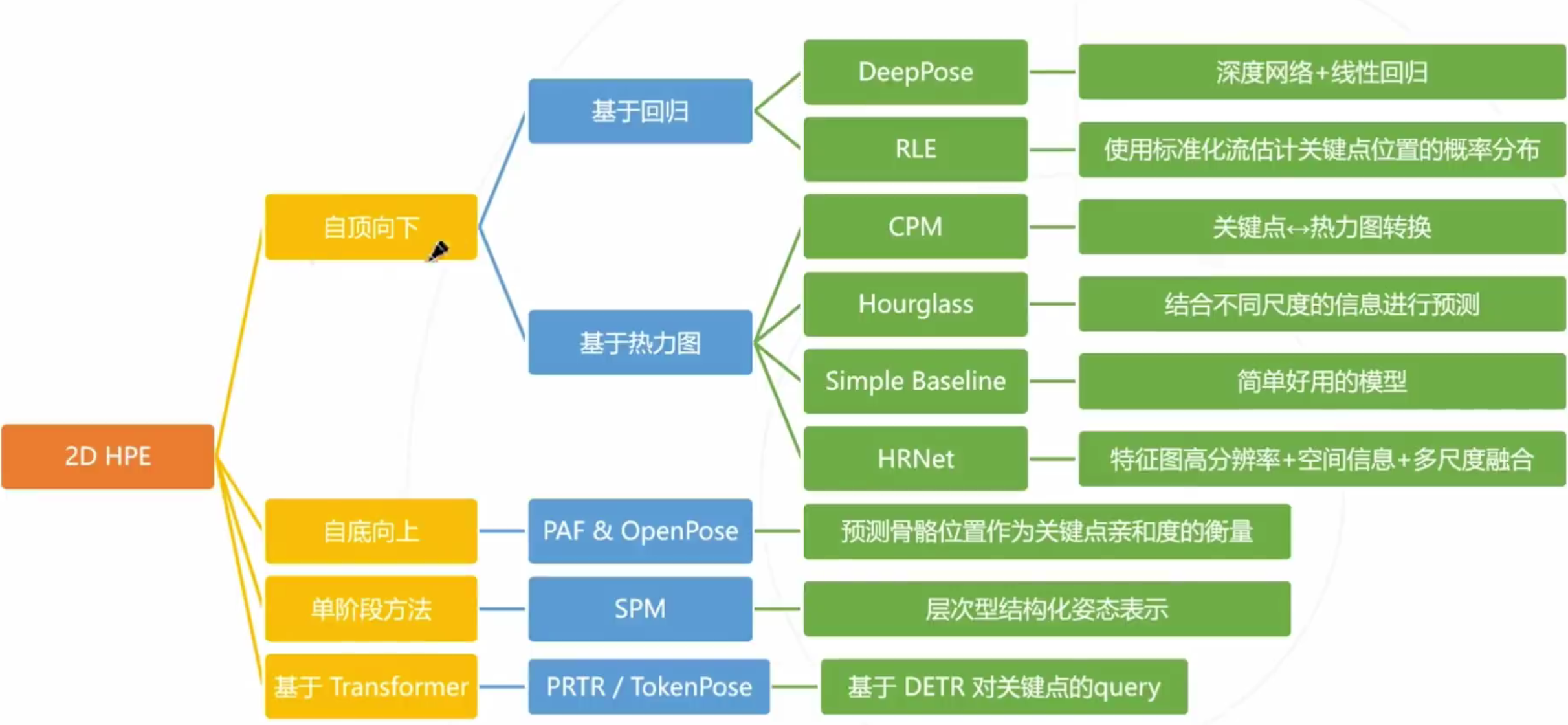
2D人体姿态估计:在图像上定位人体关键点的坐标。
基本思路:
- regression based 基于回归:让模型直接输出关键点的坐标 但精度不够高,全连接层回归
- heatmap based 基于热力图:
- 预测每个位置是关键点的概率,每一个关键点对应一个2D热力图(与原图同尺寸或等比缩小),关键点的真值可以基于原始关键点坐标生成,作为训练网络的监督信息
- 适合用深度学习做,精度高一些,相对于回归更符合神经网络结构,
- 主流算法更多基于热力图,但计算量大于回归,需要维护很大的数据
- 还原关键点:
- 朴素方法:通过求极大值max等方法得到关键点坐标(存在多个最大值问题)
- 进阶:取期望,高斯中心更加鲁棒,计算位置的期望,相当于取高斯的重心(可以求导)
多人姿态估计:
- 自顶向下方法:1、使用object detection检测人体;2、基于单人图像估计姿态
- 缺点:1、整体精度受限于检测器的精度;2速度与计算量会正比于人数;3、无法处理人物动作有交叉的情况 4、一些新工作考虑将两个阶段聚合成一个阶段
1.1 自顶向下方法
Step01: 使用目标检测算法检测出每个人体。
Step02:基于单人图像估计每个人的姿态。
基于回归的自顶向下方法:通过级联提升精度,使用目标检测出每个人体,基于单人图像估计个人姿态
- 问题:精度
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 8652
8652











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









