






Elasticsearch入门
Elasticsearch是一个基于Lucene的搜索服务器,采用Java语言进行开发的,提供RESTful API 接口。是一个分布式、可扩展、实时的搜索与数据分析引擎,它能从项目一开始就赋予你的数据以搜索、分析和探索的能力。
主要特点
- 分布式实时文件存储,并将每一个字段都编入索引,使其可以被搜索。
- 实时分析的分布式搜索引擎。
- 可以扩展到上百台服务器,处理PB级别的结构化或非结构化数据。
基本概念
先说Elasticsearch的文件存储,Elasticsearch是面向文档型数据库,一条数据在这里就是一个文档,用JSON作为文档序列化的格式,比如下面这条用户数据:
{
"name" : "Declan",
"sex" : "Male",
"age" : 25,
"birthDate": "1990/05/01",
"about" : "I love to go rock climbing",
"interests": [ "sports", "music" ]
}
用Mysql这样的关系型数据库存储就会容易想到建立一张User表,有balabala的字段等。在Elasticsearch里这就是一个文档,当然这个文档会属于一个User的类型,各种各样的类型存在于一个索引当中。这里有一份简易的将Elasticsearch和关系型数据术语对照表:
关系数据库 ⇒ 数据库 ⇒ 表 ⇒ 行 ⇒ 列(Columns)
Elasticsearch ⇒ 索引(Index) ⇒ 类型(type) ⇒ 文档(Docments) ⇒ 字段(Fields)
一个 Elasticsearch 集群可以包含多个索引(数据库),也就是说其中包含了很多类型(表)。这些类型中包含了很多的文档(行),然后每个文档中又包含了很多的字段(列)。Elasticsearch的交互,可以使用Java API,也可以直接使用HTTP的Restful API方式,比如我们打算插入一条记录,可以简单发送一个HTTP的请求: 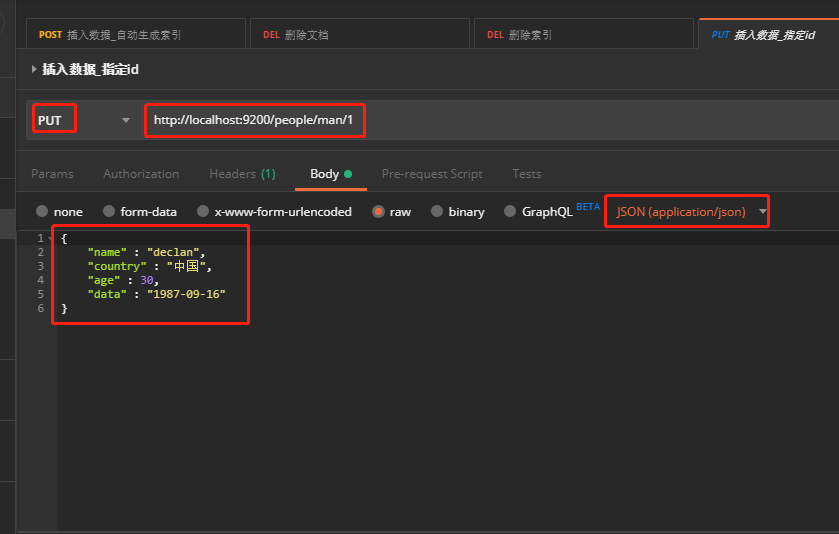
安装和启动
Elasticsearch的安装很简单,从官网上下载下来(我这里演示使用的是5.5.2的版本),进行解压之后,执行bin文件中的elasticsearch.bat(linux是elasticsearch)脚本即可启动,具体目录如下: 
执行启动脚本之后,出现如下界面,说明启动成功: 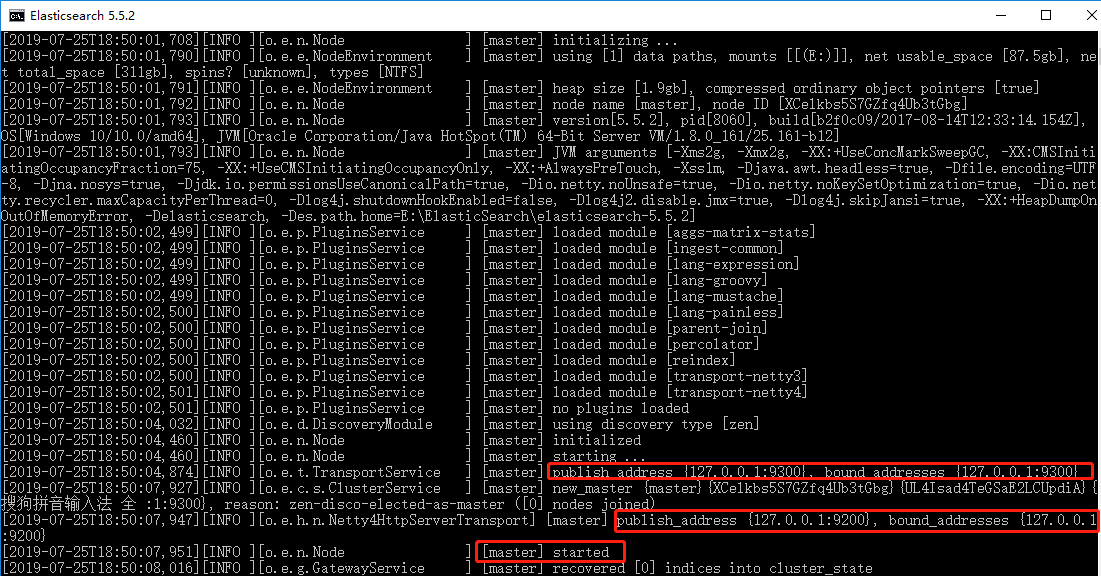
从上图可以看到,这里Elasticsearch占用了两个端口,一个是9200,一个是9300。9200作为Http协议,主要用于外部通讯;9300作为Tcp协议,jar之间就是通过tcp协议通讯;Elasticsearch集群之间是通过9300进行通讯。
启动之后就可以在浏览器中访问9200来查看相关信息了: 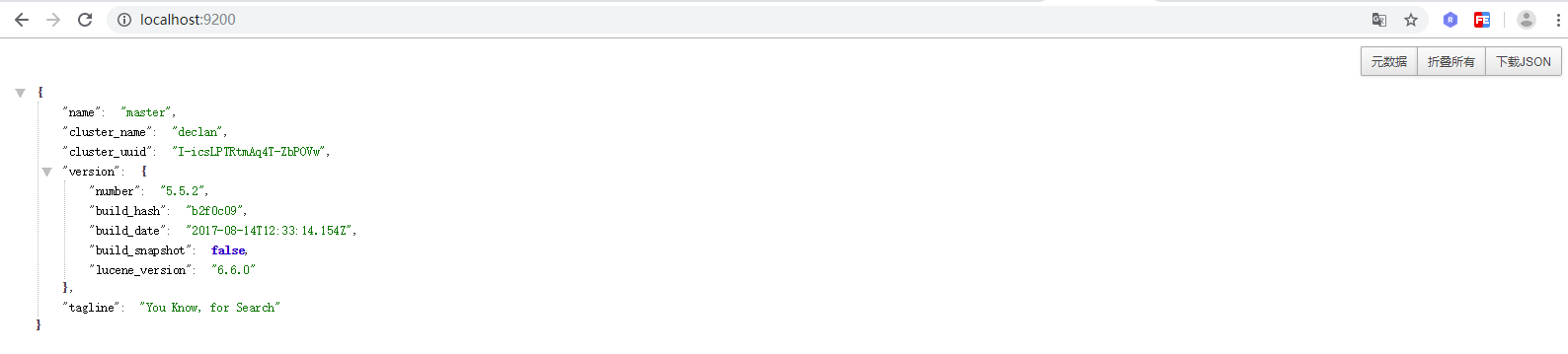
head插件的安装
elasticsearch-head是一个界面化的集群操作和管理工具,可以对集群进行傻瓜式操作。你可以通过插件把它集成到es(首选方式),也可以安装成一个独立webapp。
方式1:作为一个独立的webapp 安装
从github上进行下载:https://github.com/mobz/elasticsearch-head 该项目中有详细的安装说明。
下载之后解压到某个目录 
该项目其实就是基于node.js开发的一个web前端项目,所以在这里需要进行npm install(系统需要安装node.js,通过命令:node -v 和 npm -v可以查看是否已经安装) 
接下来就是下载该项目运行需要的相关模块,在安装完成之后,执行命令:npm run start 来启动服务 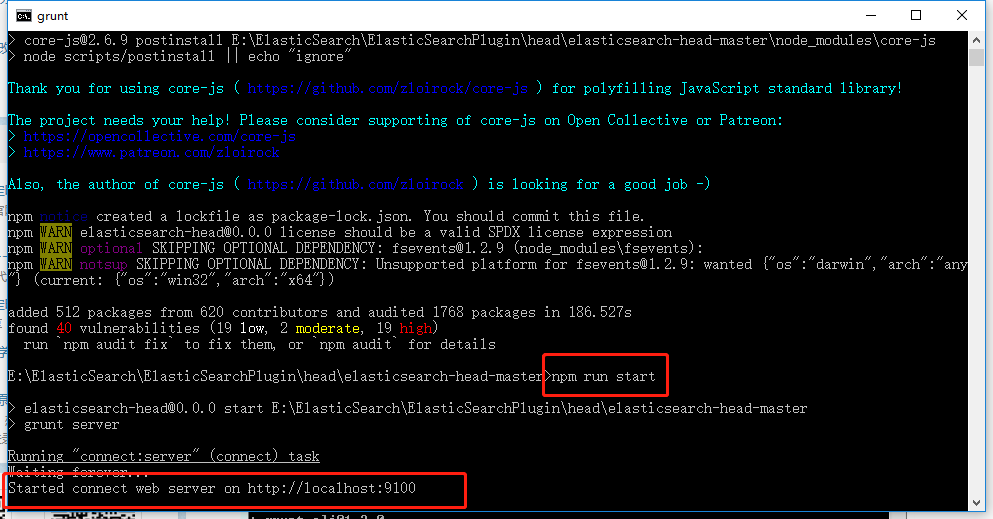
接下来还需要修改elasticsearch相关配置,因为该前端项目作为一个独立的项目,使用的端口是9100,用该服务去连接elasticsearch的9200端口进行RESTful API接口的话会存在跨域的问题,所以这里需要设置为允许跨域。修改elasticsearch.yml文件,添加如下内容:
####### 跨域问题解决 #########
http.cors.enabled: true
http.cors.allow-origin: "*"
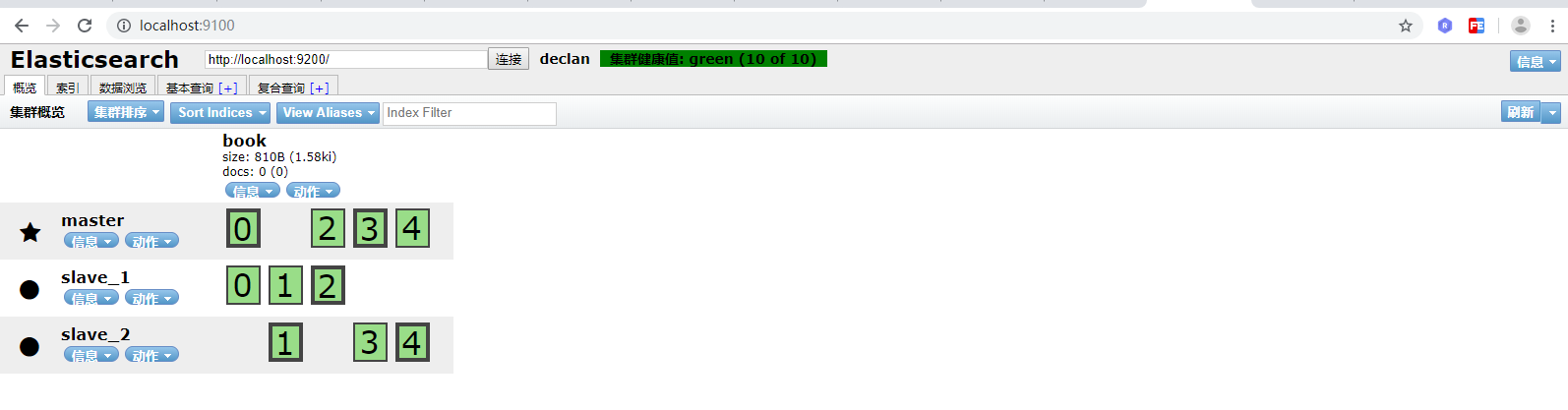
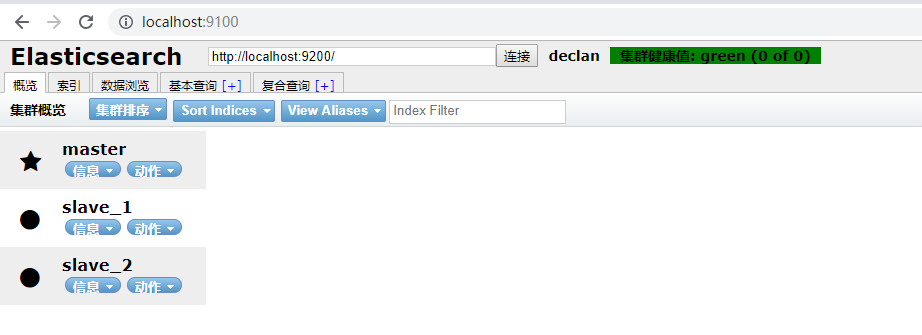
修改完配置文件之后需要重启一下elasticsearch服务,然后启动启动elasticsearch-head工具,访问http://localhost:9100 可以看到如下界面:
方式2:通过elasticseach自带的plugin命令 安装
从elasticsearch-head的github上可以看到如下信息:
- for Elasticsearch 5.x, 6.x, and 7.x: site plugins are not supported. Run as a standalone server
- for Elasticsearch 2.x: sudo elasticsearch/bin/plugin install mobz/elasticsearch-head
- for Elasticsearch 1.x: sudo elasticsearch/bin/plugin -install mobz/elasticsearch-head/1.x
- for Elasticsearch 0.x: sudo elasticsearch/bin/plugin -install mobz/elasticsearch-head/0.9 说明从5.x的版本以后,已经不能使用plugin命令进行安装了,只能通过一个独立服务运行。
分布式的配置
分布式的部署主要是相关配置的修改,这里1个master和2个slave作为例子来进行说明:
- 需要将下载下来的安装包再解压两份,分别作为slave_1和slave_2
- 首先配置master的配置。修改elasticsearch.yml文件,在文件中添加如下内容:
############ 集群的配置 start #########
#集群的名称
cluster.name: declan
#该节点的名称
node.name: master
#指定该节点为master
node.master: true
#指定该节点的ip
network.host: 127.0.0.1
############ 集群的配置 end #########
- 修改slave_1的elasticsearch.yml配置文件,在文件中添加如下内容:
############## Slave集群配置 Start ################
#集群的名称,这个名称必须跟master的集群名称一致
cluster.name: declan
#该节点的名称
node.name: slave_1
#该节点绑定的ip
network.host: 127.0.0.1
#设置http连接的端口号,默认的是9200(目前master中使用的就是9200,为了防止端口冲突,需要重新制定)
http.port: 8200
#该配置是找到master,如果不加该配置的话,该slave节点是游离在集群之外的(即指定master节点是哪个)
discovery.zen.ping.unicast.hosts: ["127.0.0.1"]
############## Slave集群配置 End ################
- 修改slave_2的elasticsearch.yml配置文件,在文件中添加如下内容:
############## Slave集群配置 Start ################
#集群的名称,这个名称必须跟master的集群名称一致
cluster.name: declan
#该节点的名称
node.name: slave_2
#该节点绑定的ip
network.host: 127.0.0.1
#设置http连接的端口号,默认的是9200(目前master中使用的就是9200,为了防止端口冲突,需要重新制定)
http.port: 7200
#该配置是找到master,如果不加该配置的话,该slave节点是游离在集群之外的(即指定master节点是哪个)
discovery.zen.ping.unicast.hosts: ["127.0.0.1"]
############## Slave集群配置 End ################
配置完成之后,就可以将master和两个slave服务进行启动,然后可以分别访问9200,8200,7200三个端口,正常情况下可以看到如下界面:
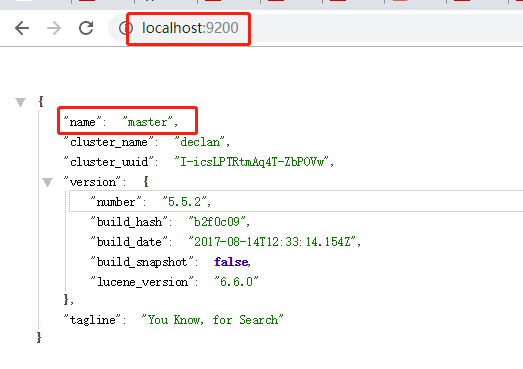
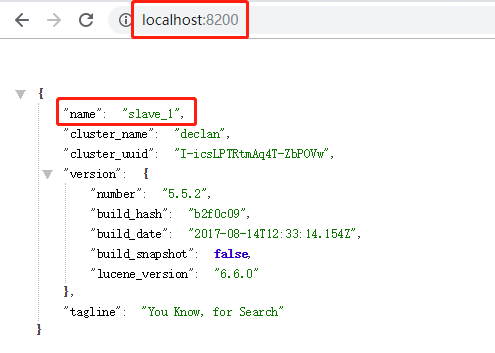
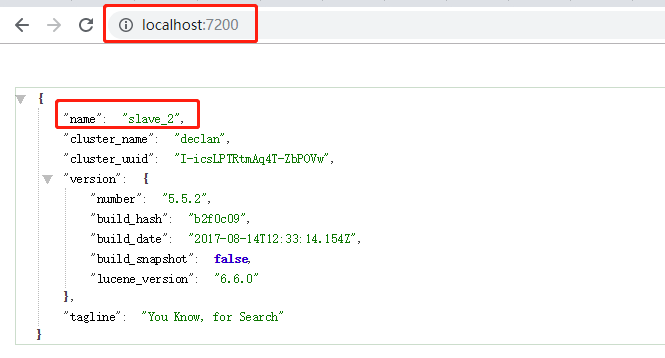
可以通过访问head插件来看相关信息:http://lcoalhost:9100
基本用法
首先了解一下ES的API是RESTful风格的
API节本格式:http://<IP>:<port>/<索引>/<类型>/<文档id>
他的动作是以http方法来决定的:
HTTP动作:GET/PUT/POST/DELETE
- 创建索引 这里以postman工具来进行操作:
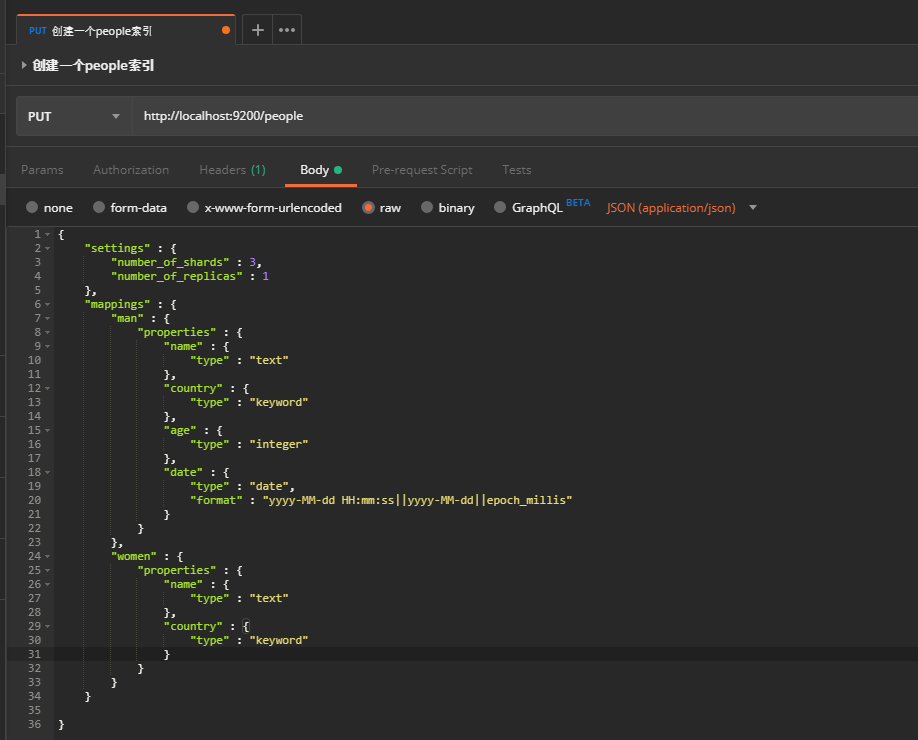
这里的http动作是PUT,url的格式是:http://localhost:9200/people 表示创建people这个索引,这里要注意,这个索引名必须为小写。
Body中json内容如下:
{
"settings" : {
"number_of_shards" : 3,
"number_of_replicas" : 1
},
"mappings" : {
"man" : {
"properties" : {
"name" : {
"type" : "text"
},
"country" : {
"type" : "keyword"
},
"age" : {
"type" : "integer"
},
"date" : {
"type" : "date",
"format" : "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
}
}
},
"women" : {
"properties" : {
"name" : {
"type" : "text"
},
"country" : {
"type" : "keyword"
}
}
}
}
}
其中的settings是对该索引所做的设置,number_of_shards表示创建该索引时其分片数;number_of_replicas表示每个分片副本的个数。
mappings是对类型的定义(可以理解为创建数据表),其中的"man"和"women"是类型的名称(相当于表名),properties就是定义每个字段(相当于数据库中表中的每列的字段)
提交之后通过head插件查看: 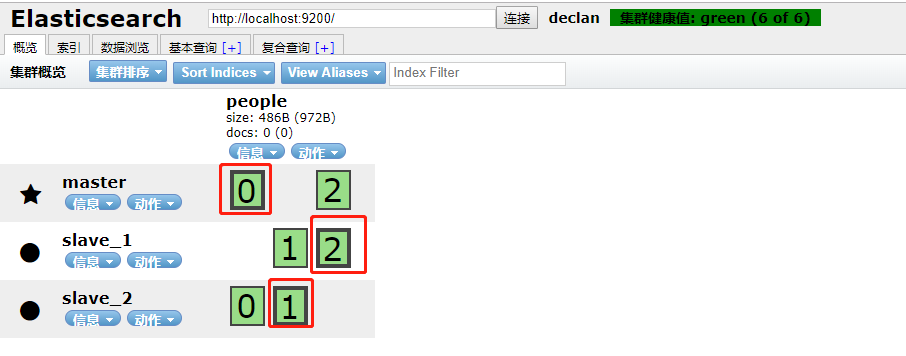
可以看到已经有了people这个索引,同时这个索引有三个主分片(红框标注的),每个分片都处在不同的ES节点上,其中没有被标注的0,1,2分别对应的是三个主分片的备份。从图中可以看出来,粗线框的表示主分片,细线框的表示主分片的备份,对应关系是 0-->0, 1-->1, 2-->2。
- 删除索引

- 插入文档
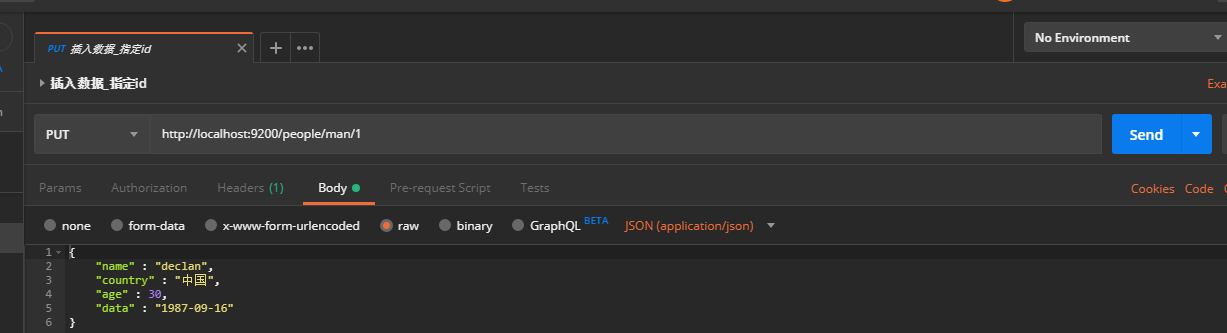
- 指定id的插入文档:
- 自动生成id的插入文档:
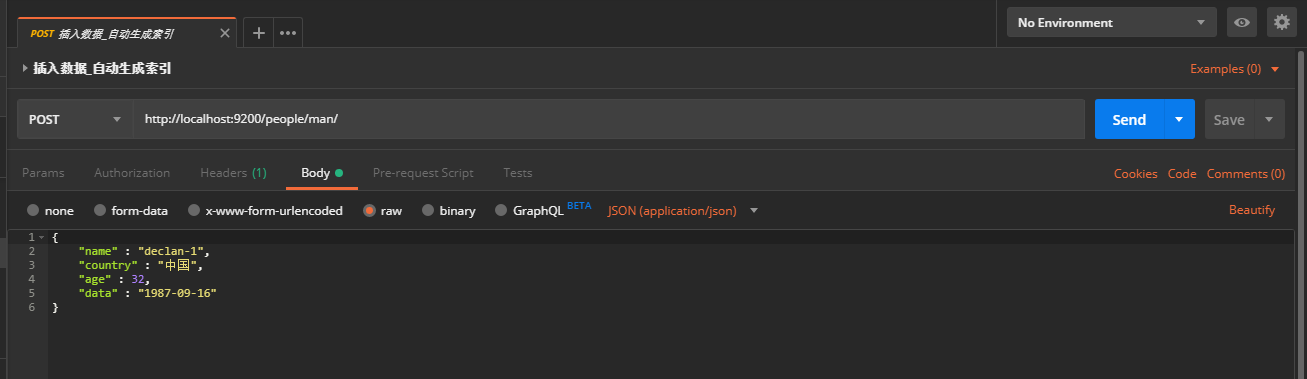
文档写入成功之后可以在head插件中查看数据:
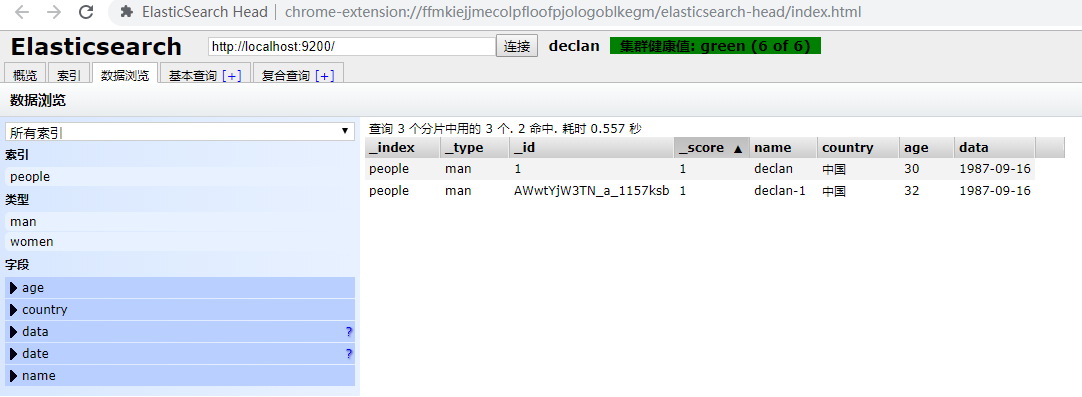
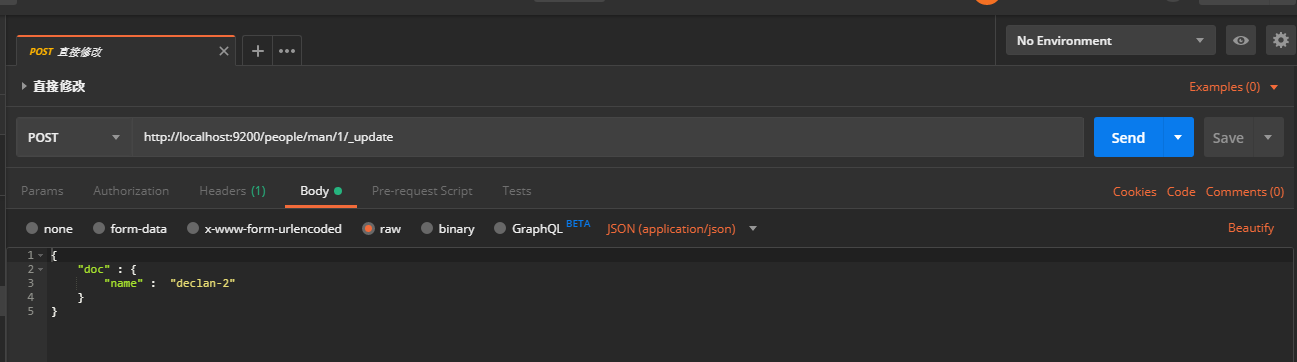
- 修改文档
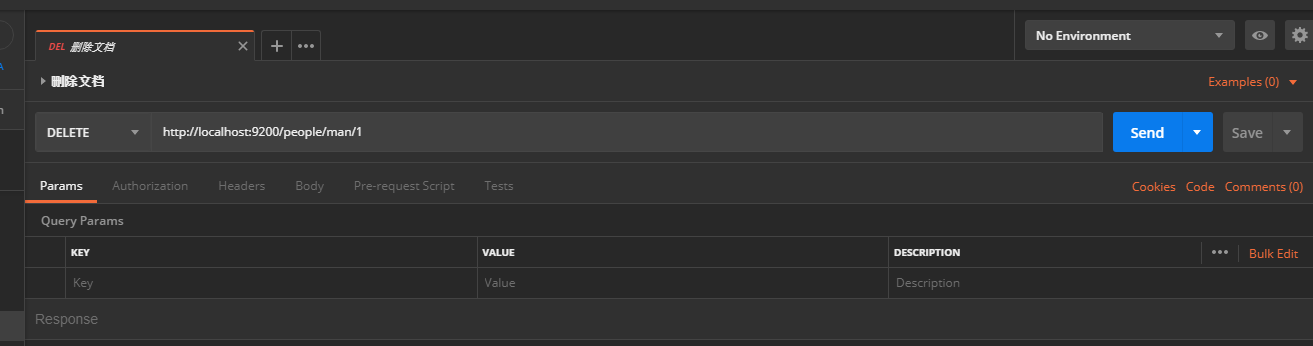
- 删除文档
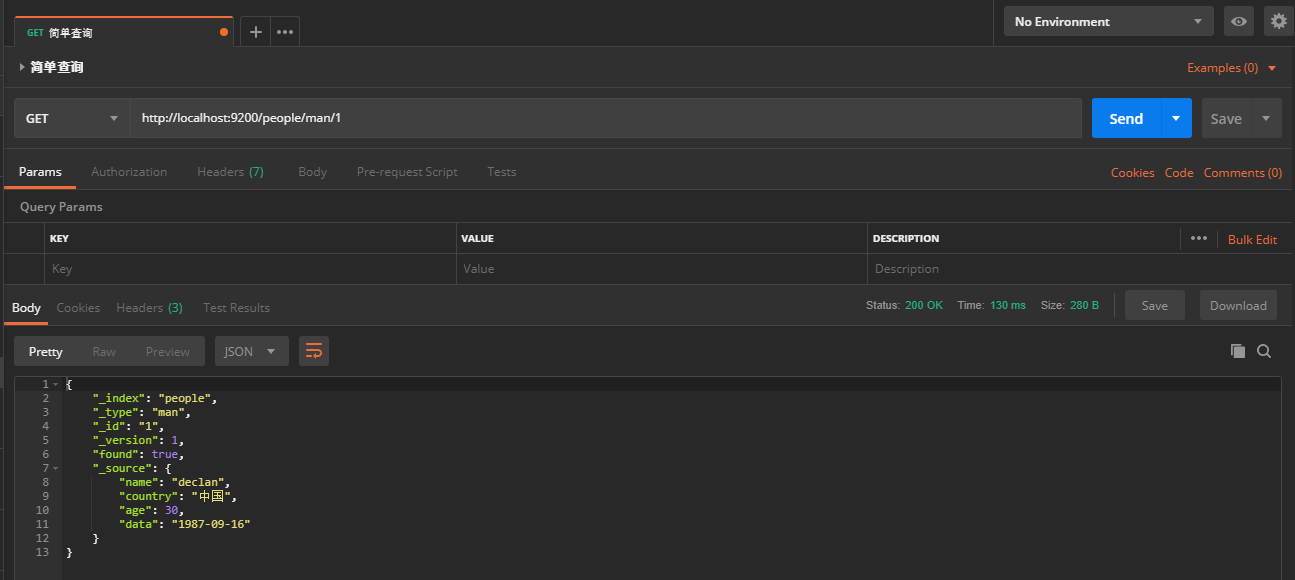
- 查询
- 简单查询
-
条件查询
2.1 查询所有
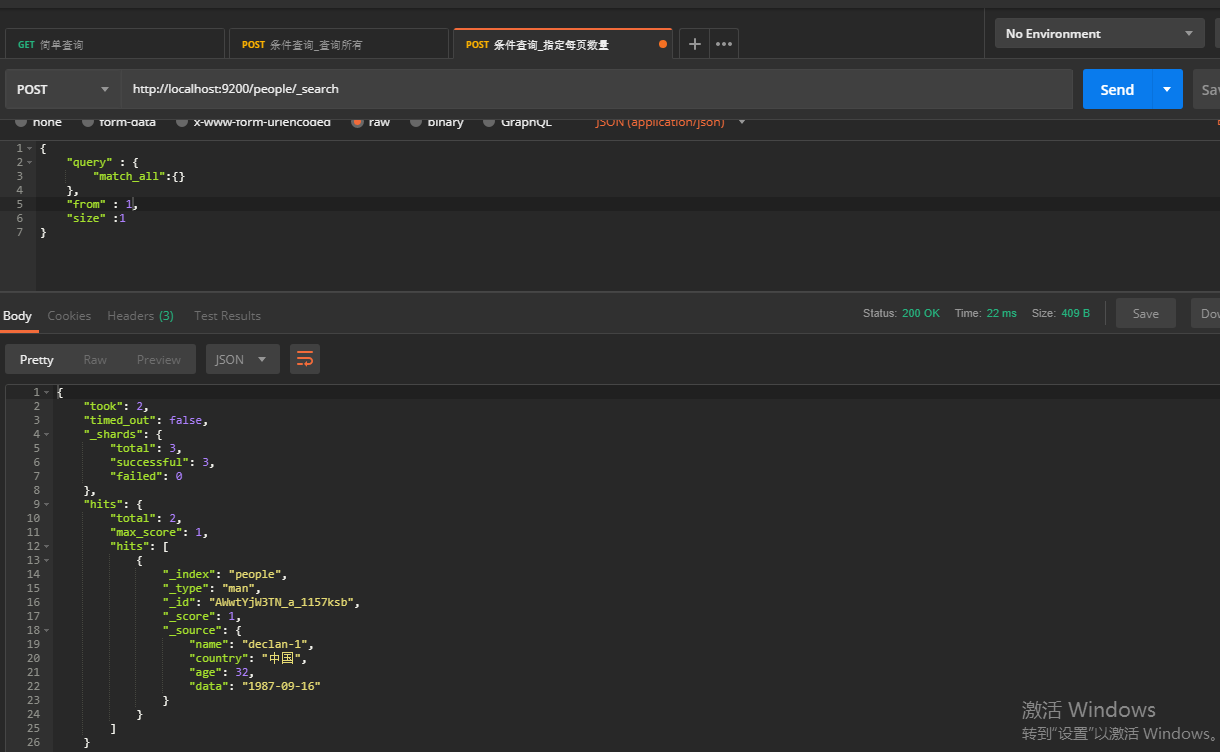
这里需要注意:默认的查询结果最多显示10条,即支持分页的,当然我们也可以指定起始条目和每页数量,需要指定两个参数,如下:
{
"query" : {
"match_all":{}
},
"from" : 1,
"size" :1
}
这里的from表示起始条目(从0开始),size表示返回多少条
2.2 关键字查询 查询name字段含有"-1"这个字符的结果: 
这里使用了关键词match,当然也可以加排序,如下:
{
"query" : {
"match":{
"name" : "declan"
}
},
"sort":[
{
"data" : {"order" : "asc"}
}
]
}















 3105
3105

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









