






一.全文检索
1.1全文检索的定义:全文检索,即全文搜索,是对文本数据进行索引搜索。
1.2全文检索的特点:做了索引;对关键字做了高亮显示;摘要截取;搜索效果更加准确;只关注文本,不关注语意。
1.3使用场景:替换数据库的模糊查询,提高查询效率;全文检索是搜索引擎的基础;垂直搜索;在word,pdf等格式的内容
中检索内容;用在各种输入法中。
二.全文检索的核心
2.1创建索引:建立单词与句子之间的对应关系,以便通过单词搜索到对应句子编号。
分词-->语法处理-->排序--.>去重
2.2搜索索引:通过关键字到索引中搜多,找到对应句子的编号。
输入搜索关键字-->关键字分词-->搜索得到具体的编号-->通过编号获取句子-->封装成对象传到前台展示
三.lucene入门
3.1.lucene是什么:lucene是全文检索的一种实现,是用java写的一种工具包。
3.2.lucene的核心API:
增删改:IndexWriter(索引写入器)
查: IndexSearcher(索引搜索器)
3.3入门步骤:
1)下载Lucene
2)导入jar包
3)测试:
创建索引:
创建IndexWriter;
把要创建索引的文本数据放入Document的字段中;
通过IndexWriter把document进行写入
搜索索引:
创建IndexSearcher;
创建Query对象--把特定格式字符串解析得到
使用IndexSearcher传入Query进行搜索
从结果中获取documentId,再通过它获取document
把document转换为我们想要的对象进行返回
四.创建索引的代码实现:
package practice;
import org.apache.lucene.analysis.core.SimpleAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import java.nio.file.Paths;
/**
* lucene创建索引
*
* @author he
* @date 2018/9/20
*/
public class Writer {
private static final String PATH = "H:/JAVAEE/ideaCode/lucene/src/main/resources/index";
public static void main(String[] args) throws Exception {
String doc1 = "hello world";
String doc2 = "hello java world";
String doc3 = "hello lucene world";
// 创建IndexWriter
Directory d = FSDirectory.open(Paths.get(PATH));
IndexWriterConfig conf = new IndexWriterConfig(new SimpleAnalyzer());
IndexWriter indexWriter = new IndexWriter(d, conf);
// 把要创建的索引的文本数据放入Document中
Document ducument1 = new Document();
ducument1.add(new TextField("id", "1", Field.Store.YES));
ducument1.add(new TextField("title", "doc1", Field.Store.YES));
ducument1.add(new TextField("content", doc1, Field.Store.YES));
Document ducument2 = new Document();
ducument2.add(new TextField("id", "2", Field.Store.YES));
ducument2.add(new TextField("title", "doc2", Field.Store.YES));
ducument2.add(new TextField("content", doc2, Field.Store.YES));
Document ducument3 = new Document();
ducument3.add(new TextField("id", "3", Field.Store.YES));
ducument3.add(new TextField("title", "doc3", Field.Store.YES));
ducument3.add(new TextField("content", doc3, Field.Store.YES));
// 通过IndexWriter把Document写入
indexWriter.addDocument(ducument1);
indexWriter.addDocument(ducument2);
indexWriter.addDocument(ducument3);
indexWriter.commit();
indexWriter.close();
}
}
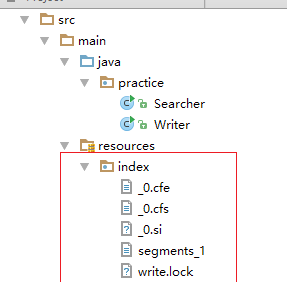
代码结果:
五.查询的代码实现:
package practice;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.core.SimpleAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import java.nio.file.Paths;
/**
* lucene搜索索引
*
* @author he
* @date 2018/9/20
*/
public class Searcher {
private static final String PATH = "H:/JAVAEE/ideaCode/lucene/src/main/resources/index";
public static void main(String[] args) throws Exception {
// 创建IndexSearcher
Directory directory = FSDirectory.open(Paths.get(PATH));
IndexReader r = DirectoryReader.open(directory);
IndexSearcher indexSearcher = new IndexSearcher(r);
String parStr = "content:java";
// 创建搜索解析器
String defaultField = "content";
Analyzer analyzer = new SimpleAnalyzer();
QueryParser queryParser = new QueryParser(defaultField, analyzer);
// 解析搜索
Query query = queryParser.parse(parStr);
TopDocs topDocs = indexSearcher.search(query, 10000);
System.out.println("总命中数: " + topDocs.totalHits);
//读取搜索到的内容
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
for (ScoreDoc scoreDoc : scoreDocs) {
Document document = indexSearcher.doc(scoreDoc.doc);
System.out.println("id -> " + document.get("id"));
System.out.println("title -> " + document.get("title"));
System.out.println("content -> " + document.get("content"));
}
}
}
代码结果:
















 2610
2610











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









