






匈牙利算法
基本概念
- 二分图:二分图又称为二部图.简单来说,如果图中点可以被分为两组,并且使得所有边都跨越组的边界,则这就是一个二分图。准确地说:把一个图的顶点划分为两个不相交集 U 和V ,使得每一条边都分别连接U、V中的顶点。如果存在这样的划分,则此图为一个二分图。二分图的一个等价定义是:不含有"含奇数条边的环"的图。生成子图:子图包含原图的所有顶点
- 匹配: 通俗的说:匹配(matching)是一个边的集合,其中任意两条边都没有公共顶点.定义:对给定二分图G,在G的子图M中,M的边集{E}中的任意两条边不依赖于同一个顶点,则称M为一个匹配
- 最大匹配: 图的所有匹配中,含有边数最多的匹配称为最大匹配
- 完备匹配: 如果图G的某个匹配M,使G的每个顶点都和匹配M中的某条边相关联,则称M为完全匹配(完备匹配); 完备匹配一定是最大匹配.
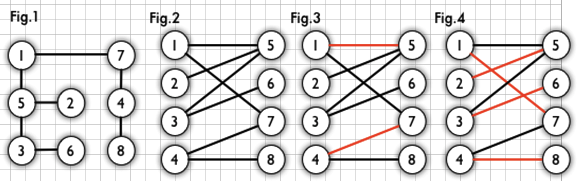 
- 如图: Fig.1为一个二分图,将其改为Fig.2的形式更为直观;Fig.3 红线部分,为一个匹配; Fig.4 为一个最大匹配,也是一个完备匹配
求图最大匹配的匈牙利算法
- 求最大匹配最直接暴力的方法是: 找出全部匹配,然后保留边最多的. 这个方法的复杂度为边数目的指数级函数. 匈牙利算法是效率更高的方法.
- 增广路径: 若P是图G一条连通两个未匹配点的路径,并且属于匹配M的边和不属于M的边(即已匹配边和未匹配边)在P上交替出现,则称P为相对于M的一条增广路径.
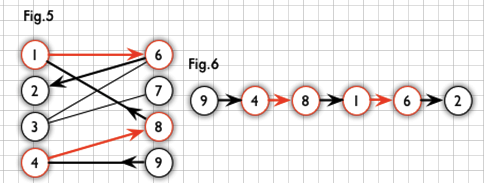 
- 如上图,Fig.5红色为匹配,Fig.6为相对于匹配的一条增广路径
- 由增广路径的定义,可以推出三个结论:
- P的路径长度必定为奇数,第一条边和最后一条边都不属于M;
- P经过取反操作,可以得到一个更大的匹配M1;
- M为G的最大匹配当且仅当不存在相对于M的增广路径.
- 匈牙利算法: 用增广路径求最大匹配(匈牙利科学家Edmonds于1965年提出); 其框架如下:
- 置M为空;
- 找出一条增广路径P,通过取反操作,得到更大的匹配M1;
- 重复步骤2,直到找不出增广路径为止.
- 匈牙利算法实现(java)
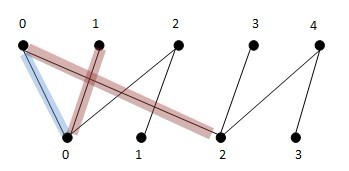 
- 增广路径有两种寻径方法,一个是深搜(DFS),一个是宽搜(BFS)。如上图,蓝色线为第一次匹配子图,现在从x1寻找增广路径,如果是DFS深搜:首先:x1找到y0,发现y0已经被x0匹配,于是深入到x0,为x0找新的匹配点,发现x0可以匹配y2,让x0与y2匹配,然后让x1与y0匹配,得到第二次匹配子图(红色).现在,从x2出发,搜寻增广路径,x2找到y0匹配,但发现y0已经被x1匹配了,于是就深入到x1,去为x1找新的匹配节点,结果发现x1没有其他的匹配节点,于是匹配失败,x2接着找y1,发现y1可以匹配,于是就找到了新的增广路径,将x2-y1加入匹配中。
- DFS实现代码见我的代码java实现|GitHub
KM算法
KM算法原理
- 对于加权完全二分图,找出权和最大的匹配,叫做求最佳匹配; 直接穷举法:效率为n!;用KM算法.
- 定理: 设M是一个带权完全二分图G的一个完备匹配,给每个顶点一个可行顶标(第i个x顶点的可行标用lx[i]表示,第j个y顶点的可行标用ly[j]表示),如果对所有的边(i,j) in G,都有lx[i]+ly[j]>=w[i,j]成立(w[i,j]表示边的权),且对所有的边(i,j) in M,都有lx[i]+ly[j]=w[i,j]成立,则M是图G的一个最佳匹配。证明很容易。
- 对任意的G和M,可行标都是存在的
- 对二分图G和一组可行标,满足可行标边界条件(lx[i]+ly[j]=w[i,j])的所有边构成的生成子图(需要包含所有顶点),称为其等价子图(相等子图),在这个等价子图上,寻找其完备匹配,如果完备匹配存在,则这个完备匹配M就是图G的最大权匹配,最大权等于所有可行标的和; 如果完备匹配不存在,则修改可行标,用贪心的思想,将最优的边加入等价子图. KM算法就是一种逐次修改可行顶标的方法,使之对应的等价子图逐次增广(增加边),最后出现完备匹配.
KM算法流程及实例
- Kuhn-Munkras算法流程:
- 初始化可行顶标的值
- 用匈牙利算法在等价子图中寻找完备匹配
- 若未找到完备匹配则修改可行顶标的值
- 重复(2)(3)直到找到相等子图的完备匹配为止
- 实例解释算法过程:
- 带权二分图如下:
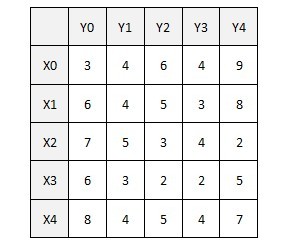 
 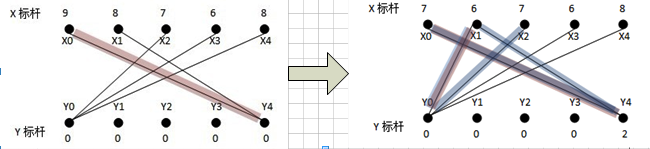 
 从x0找增广路径,找到x0-y4;然后,从x1找不到增广路径,这时,需要修改顶标,加入一条最优的新边到等价子图中:此时搜索过的路径为x1-y4-x0(用匈牙利法DFS),在路径上的X顶点集为S(x0,x1),Y顶点集为T(y4),对所有在S中的点xi及不在T中的点yj,计算d=min{(L(xi)+L(yj)-weight(xiyj))},S中的点的顶标减去d,T中的点的顶标加上d,保持顶标依然为可行顶标.(这个d计算的意义是贪心思想,两种情况:此时让x0与其他点匹配,x1与y4匹配;x0依旧与y4匹配,x1找其他点匹配.d计算的是找到一条新加的边,让x0和x1都搭配后,与x0和x1都同y4搭配的非法搭配这种情况相比,损失的权重值最少).具体来说:此时算出来的最小d=L(X1)+L(Y0)-weight(X1Y0)=2,对顶标进行松弛后,得到的等价子图如上,加了一条边x1-y0,为x1重新找增广路径,找到x1-y0,此时匹配权值和为9+6=15;原来的非法匹配权值和为9+8=17,"损失"的权值最少为2(即加入一条其他的非x1-y0的边如x0-y2,损失的权值为3,比2大,即贪心思想,"损失最小").
KM算法原本的时间复杂度为O(n4),n个节点找n次增广路径,在某次找增光路径之中,顶标最多改变n次,修改顶标的松弛量需n2; 可改进为O(n3)时间复杂度:在寻找增广路径时顺便将slack值算出.















 3930
3930

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









