






前段时间写了有篇有关并发框架的文章《Netty、t-io、Voovan 框架浅谈》得到了大家不少的关注, 与此同时《Netty与Voovan并发性能对比》的留言中有位朋友希望将 Voovan 和 t-io 进行一个性能测试:

@spyv23提到希望我做一个 t-io 和 Voovan 的并发性能测试的比对,应这位朋友的要求我决定这次就来测一把。
有些同学可能也更好奇 Voovan 和 Netty 的性能对比可以参考《Netty与Voovan并发性能对比》这篇文章。
=============================2017-07-20 最新测试结果===========================
测试环境为发生任何变更依旧是那台陪我战斗过无数的 MacBook Pro.
主要优化了并发情况下的锁处理的机制,以及在服务端Accept 时的性能优化.
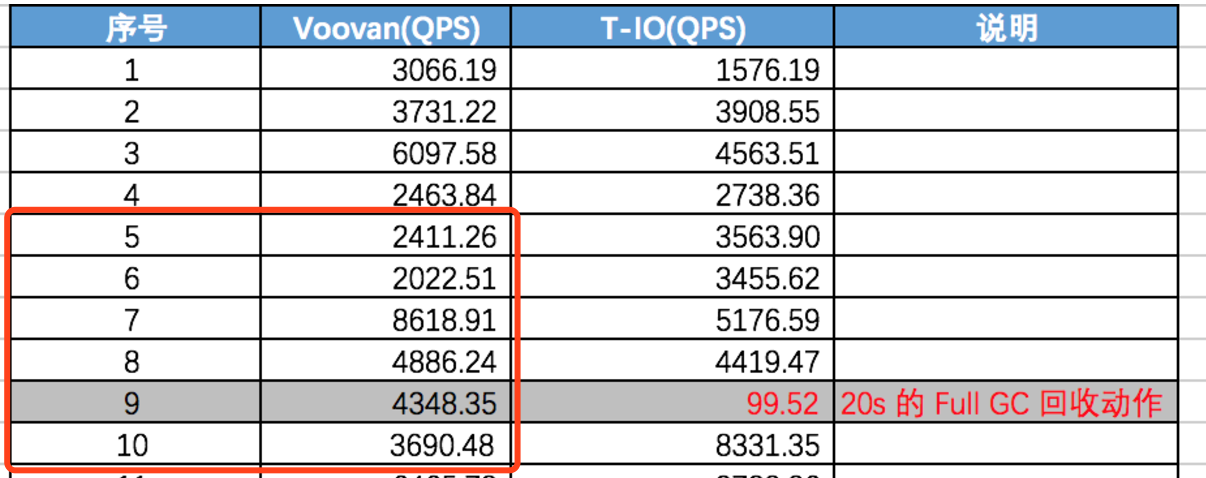
这次测试结果实在预热5次后的数据,可以对比6月28日测试结果中 5-10次的记录数据:
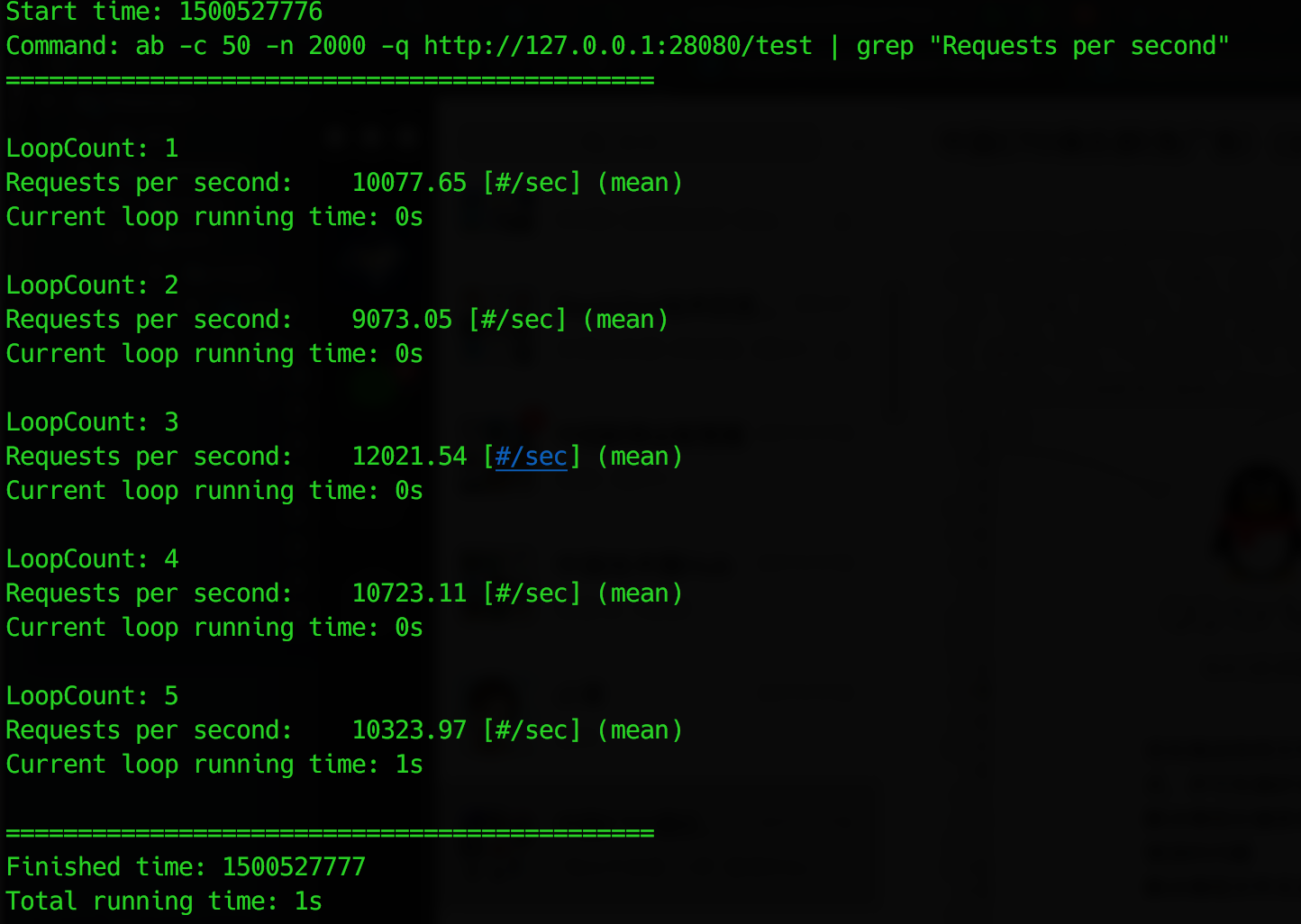
测试效果截图如下:
=============================2017-06-28 测试结果===========================
一、主机环境
首先老规矩说明一下测试的主机:
我的 MacBookPro, 测试时关闭的所有无关的其他软件。
二、测试方法描述:
场景选择: 模拟 HTTP 服务
为什么选择这种测试场景:
首先 HTTP 服务是大家比较常见的服务场景,其次基于 WEB 的性能测试工具也比较多,而且成熟,由测试工具对于测试结果带来的影响也相对较少。
为避免自己编码的压测工具带来各种风险,同时也为了使测试结果更加公平、真实、可信。测试方法如下:
1. 使用 ab (Apache bench)进行压力测试
2. Voovan 和 t-io 两个框架分别模拟 Http 服务,在接受到 HTTP 请求后不进行解析,直接返回相同的 Http 响应后关闭连接。
3. 每次响应都关闭连接,保证不会因 HTTP 的 KeepAlive 头带来的长连接影响测试结果的准确性。
三、测试代码
由于代码我都同步到了 Git@OSC,这里我就放上代码连接。
Tio:
TioServer.java 主类并包含了业务处理类
Voovan:
AioServerSocketBenchTest.java 主类
StringFilter.java 将 Bytebuffer转换成
LineMessageSplitter.java 用于判断报文结束,通过换行
ServerBenchHandlerTest.java 业务处理类,返回请求报文
启动服务命令并未增加任何参数调优,使用 java 启动时均使用的是 jvm 的默认参数设置。
四、测试脚本
ab -c 50 -n 2000 http://127.0.0.1:28080/test/ |grep "Requests per second"
在测试过程中发现对 t-io 调整参数到 -c 100 的时候会出现这个问题

经过测试发现 Voovan 和 Netty 在调整参数到 -c 100 都能够正常响应,所以最终将参数设定为 -c 50
具体以原因并未深究,不知道在其他操作系统是否也会出现类似的问题。
五、结果分析
下面我们来看一下测试结果:
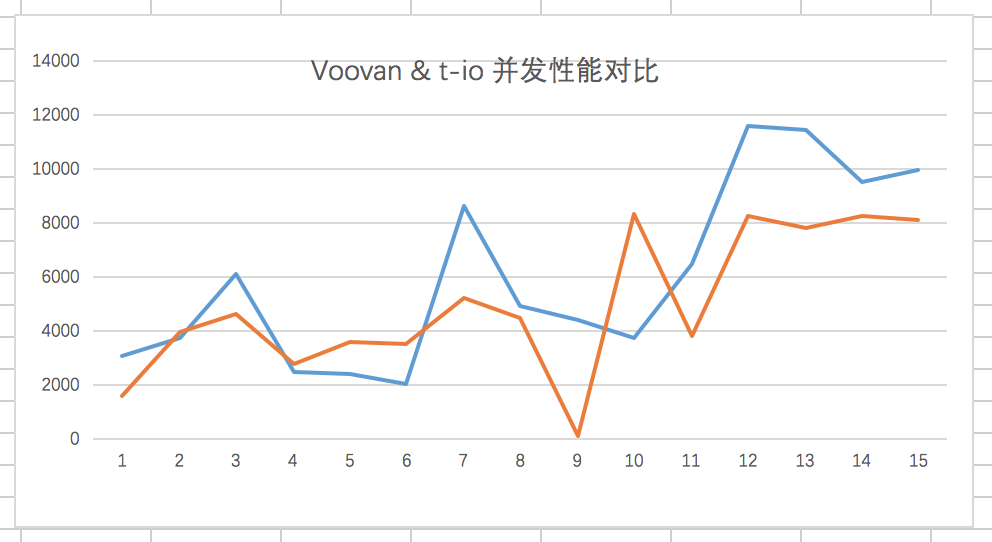
首先来一个线条图方便大家更直观的观察结果:
接下来我们来看看统计数据:
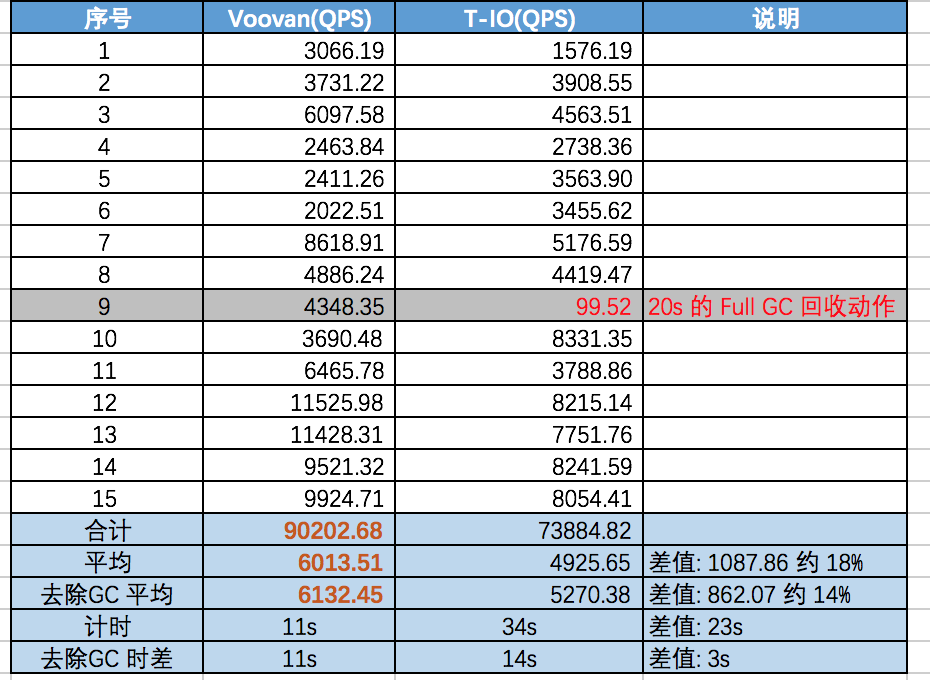
从上面的统计结果看经过15次,在第9次的时候 t-io 出现了一次 full GC 导致了较明显的 GC 停顿。
推测具体原因在之前的分析文章中提到过,极有可能是因为 Voovan 使用了对外内存有效的延缓了 full GC出现的时间,那么在有限的时间里总体来看减少了 full GC 的次数。
- 另外在性能上我们也看到 累计15次下来
Voovan 合计QPS 量为 9.0w
t-io 合计 QPS 量为7.3w.
- 统计15次测试结果后的数据平均下来:
Voovan 的 QPS 为: 6013,
t-io 的 QPS 量为 4925.
- 同时也考虑导去除 GC 导致的停顿的记录的统计结果,也就是去除第9次的结果后:
Voovan 的 QPS 为: 6132
t-io 的 QPS 量为 5270.
- 总的请求量为: 15*2000 = 30000
Voovan 累计用时: 11s
t-io 累计用时: 34s
- 去除 GC 导致的停顿的记录,也就是去除第9次的结果后,总请求量: 14*2000 = 28000
Voovan 累计用时: 11s
t-io 累计用时: 14s
六、内存使用情况对比
有很多个朋友更关注 Voovan 和 t-io 对内存使用的情况:
为了不等待第一次 GC 的发生,因为 GC 会严重干扰内存使用情况的评估,所以必须在一次 full gc 前取得数据,我们采用连续5次执行。
ab -c 50 -n 2000 http://127.0.0.1:28080/test/ |grep "Requests per second" 共计发起 1w 个请求
下面我们来通过 jvm-mon来观察堆内存的使用情况:
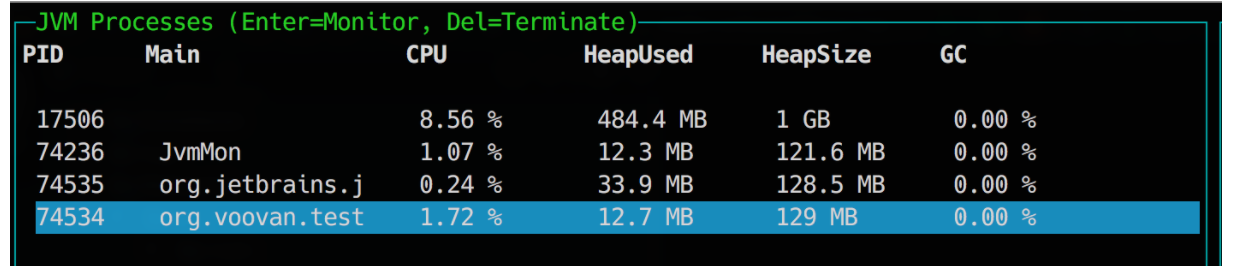
下图是 Voovan 的堆内存消耗情况:
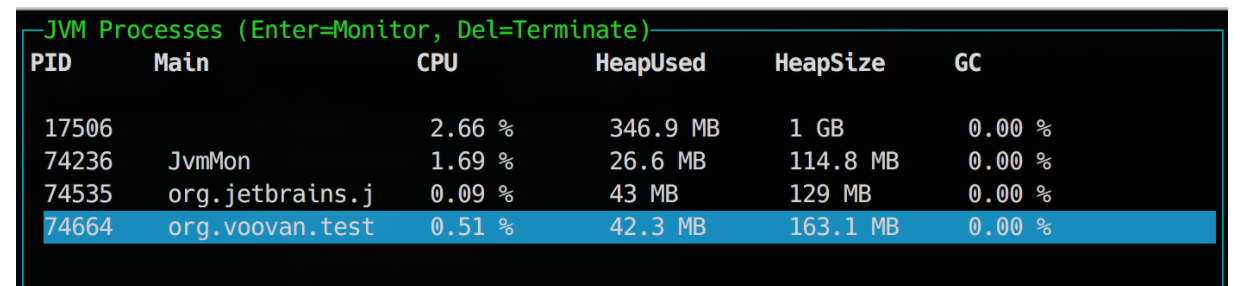
下图是 t-io 的堆内存消耗情况:
可以看到:
- Voovan 在响应1w 个请求后堆内存的消耗为12.7m,申请的最大堆内存为129m,为 jvm 默认分配的数值。
- t-io 在响应1w 个请求后堆内存的消耗为42.3m, 申请的最大堆内存为163.1m。说明曾经在运行过程突破过 jvm 阀值,JVM 增加了堆内存的分配到163.1m。
综合来看我认为 Voovan 在内存管理上相比较还是比较理想的。
=============================本次测试结果仅共各位参考===========================
多说一点点...点...点.....
由于 t-io 是长连接场景,所以可能优化的方向不同,导致了一个这样的测试结果。
关于 t-io 的长连接场景的测试,相关的博客 https://my.oschina.net/u/2369298/blog/915435
下面附上一些我个人之前相关的性能测试文章:















 8393
8393

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









