






集合:

-
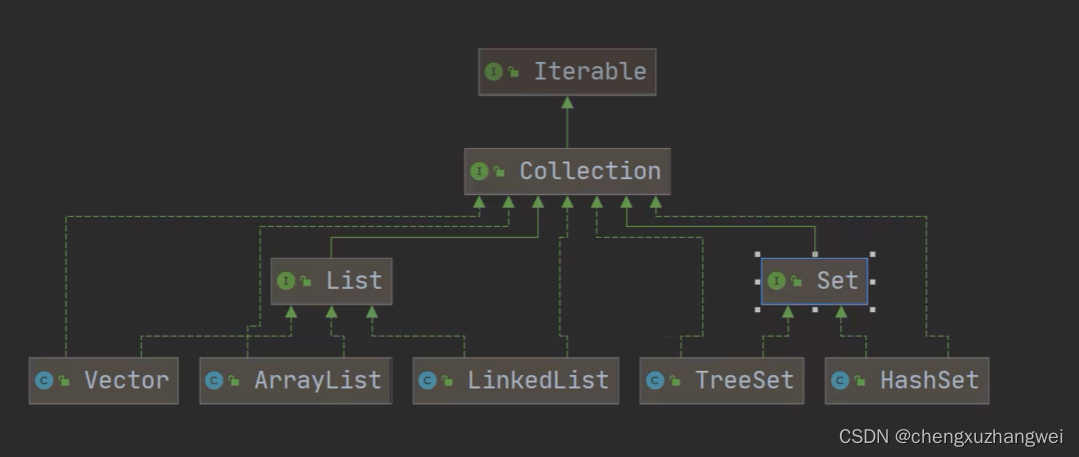
集合主要分成两组(单列集合collection,双列集合map)
-
Collection 接口有两个重要的子接口List Set,他们的实现子类都是单列的集合
-
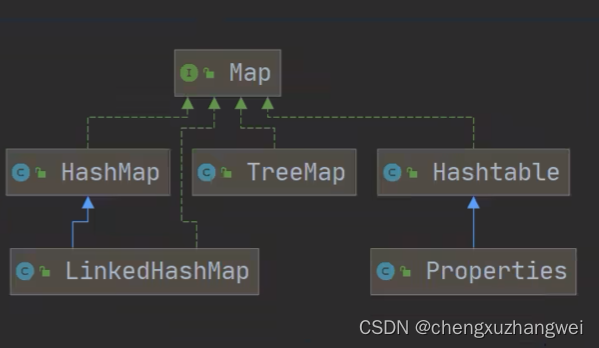
Map 接口的实现子类 都是双列集合,存放的K-V
-
把老师梳理的两张图记住!

Collection的常用方法:
添加和删除:
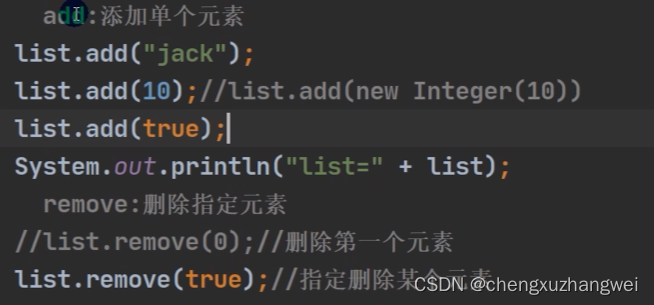
add 和remove ,remove可以根据下标或者指定元素来进行删除
查找,判断是否为空,清空元素,获得集合长度
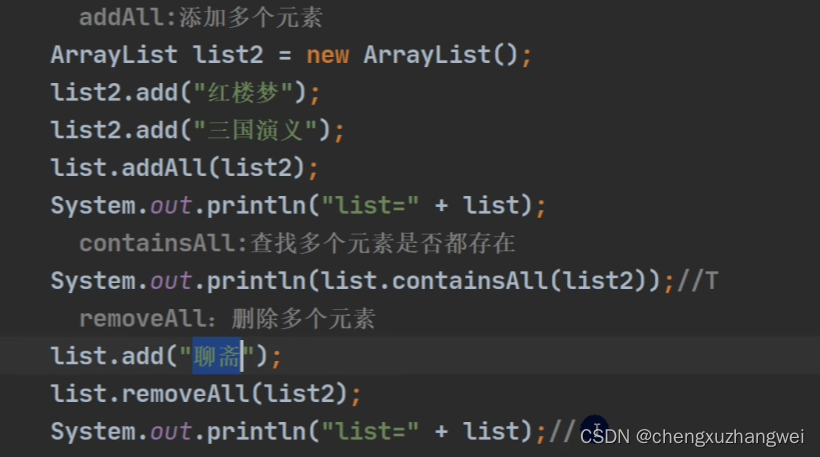
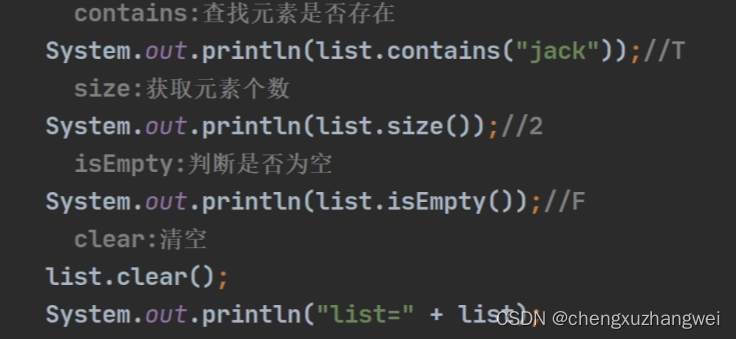
常传入另一个集合~
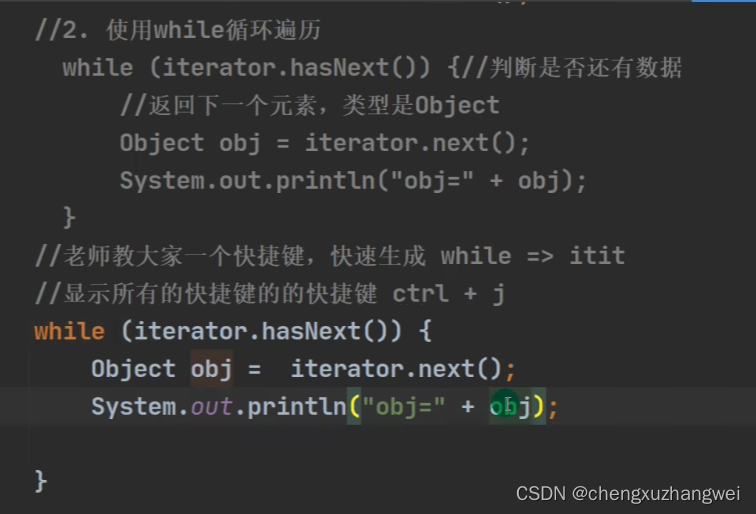
(iterator)迭代器


-
coll为要遍历的集合~
-
一开始,iteerator指向的是集合第一个元素的前一个位置
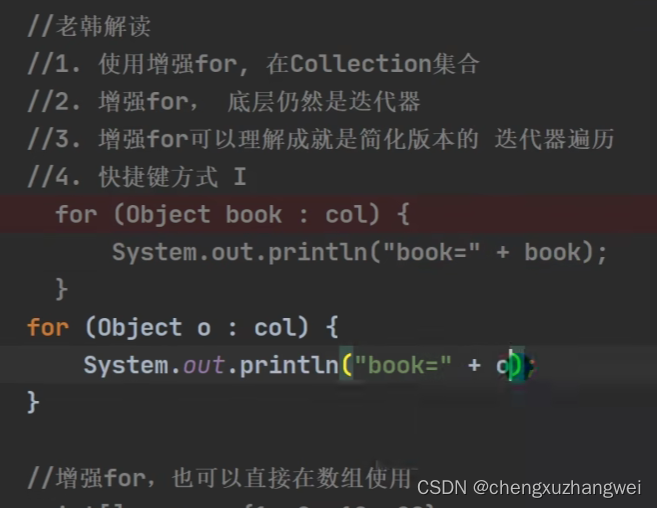
增强for循环:
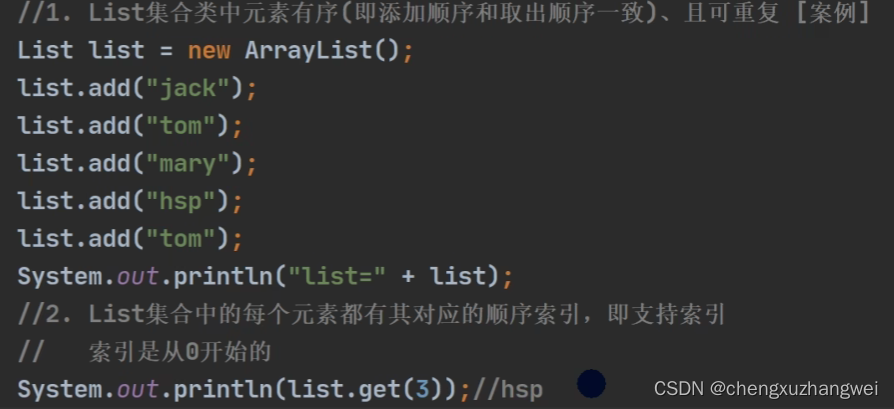
List集合的特点和方法:
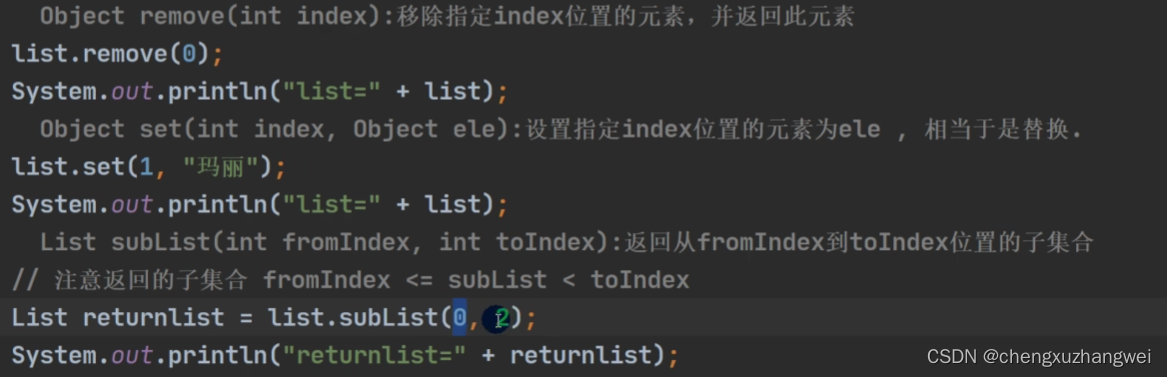

List的三种遍历方式:

返回的类型是object类型,要进行向下转型才可以调用原类里的成员
Arrayslist的注意事项:


Vector于arrayslist的比较!:

LinkList的底层结构:



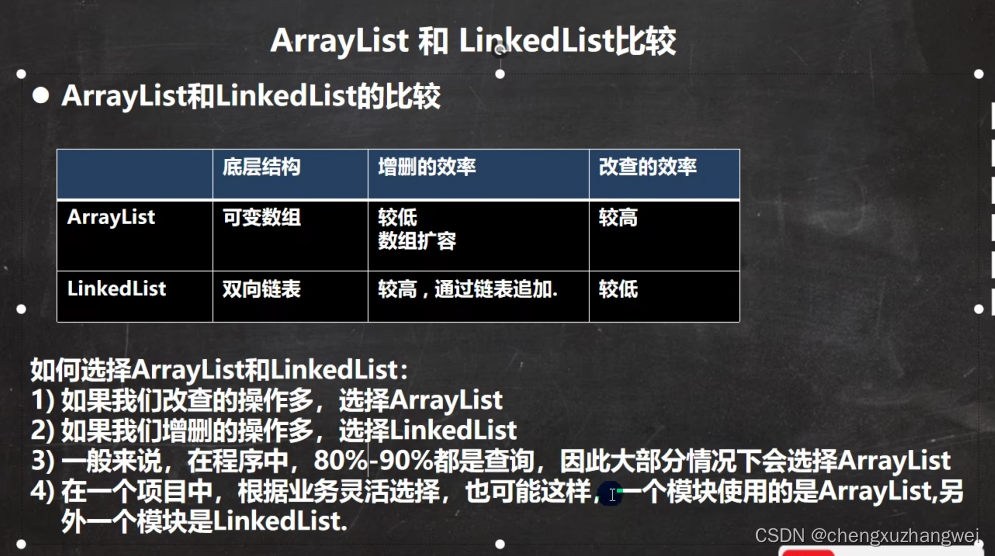
Arrayslist和LinkList的比较:
Set接口和方法:
-
无序(添加和取出的元素的顺序不一样),并且没有索引
-
不允许有重复元素,所以最多包含一个nul
-
虽然取出的顺序不是添加的顺序,但是顺序是固定的,不会因为取的次数而改变
-
set没有get()方法,所以set不能使用普通的for循环进行遍历
-
只能使用迭代器和增强for的方法进行遍历
hashset:实现了set接口

-
在执行add方法后会返回一个布尔值表示是否加入成功(成功 true 失败 false)
add方法的奥秘:如何判断是否加入相同数据的?
-
hashset的底层是hashmap,hahsmap的底层是数组加链表加红黑树!
数组加链表的实现机制:1.创建一个链表数组,2将对应下标的数组进行链表方式的存结点,太妙 了!!
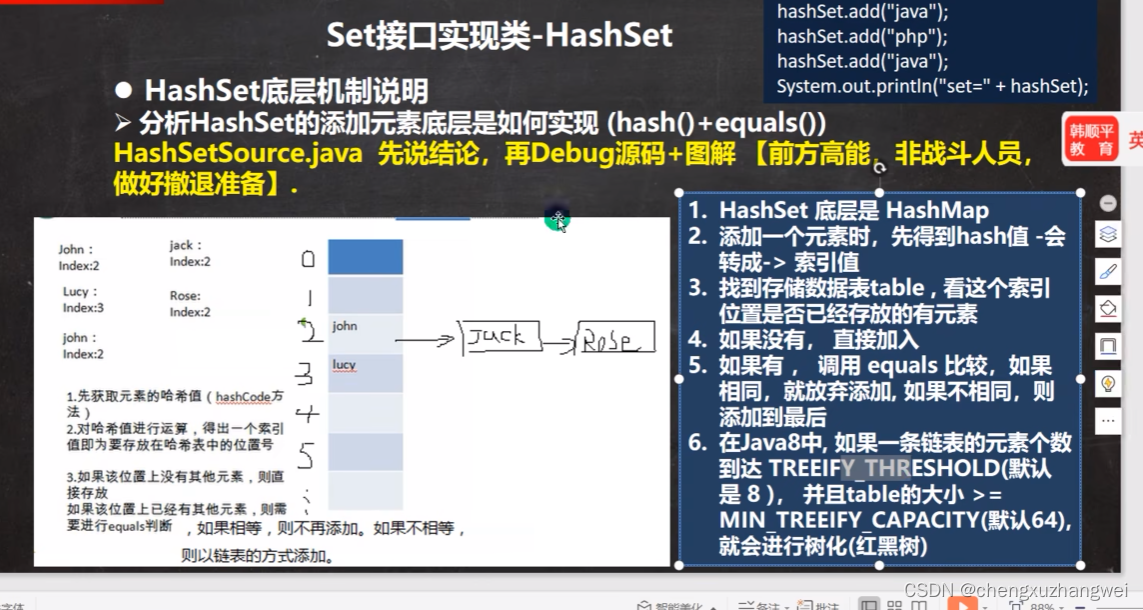

添加多少个结点,这个size就会加一。
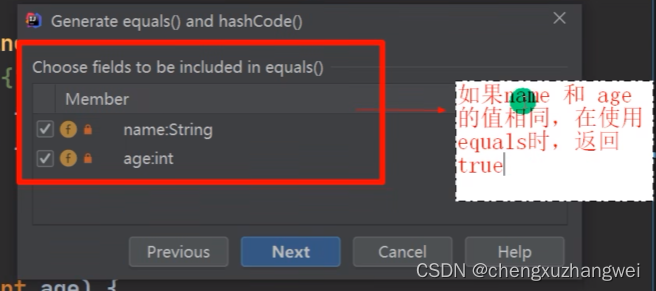
重写hashcode和equals方法!
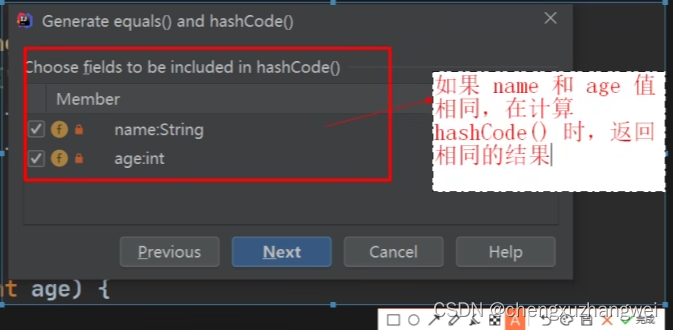
-
对象不同,hashcode这个值就会不同
在值存入哈希表中的时候,是现根据哈希值确定一个索引,然后根据索引找到表中的位置,如果位置为空则直接加入,否则根据equals方法挨个进行比较内容,内容不同则加到链表尾部,否则不加入!
-
可以看出,是否可以加入哈希表取决于hashcode的值跟equals的比较方法!
LinkedHashset:

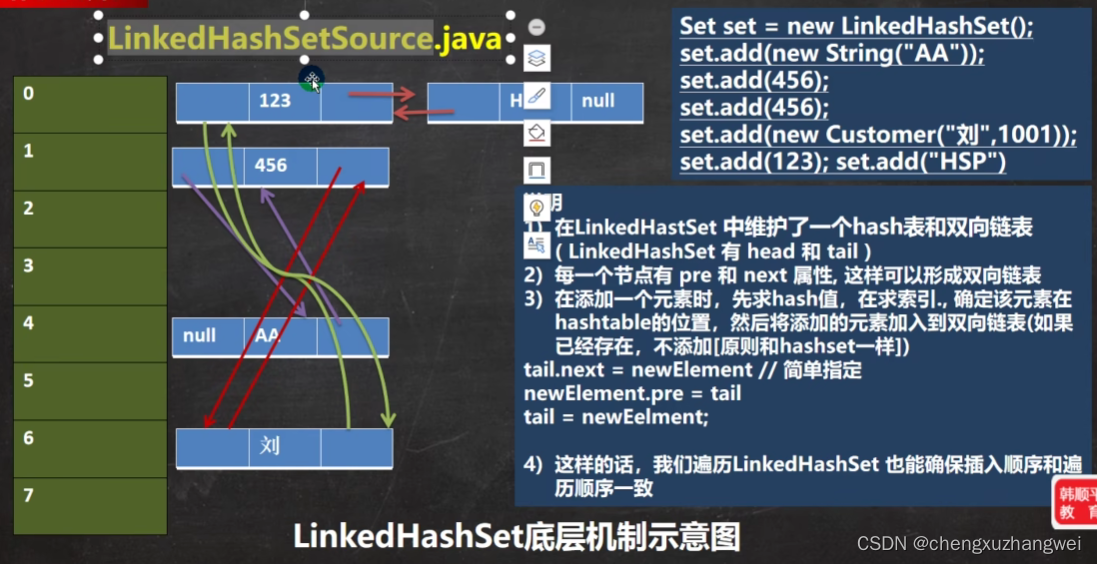
注意:
-
linkhashset**内容是有序的!
-
hashcode确定索引,equals确定同索引下元素的比较!
-
如果只重写hashcode方法,后面有相同内容的对象,是可以储存到表中的,只不过是存放到相同的链表中
-
如果只重写equals方法,创建一个对象就放到hash后的表中的索引,,这时候不管内容是否相同或者不同了,因为底层自带的哈希code方法,是根据对象是否相同来创建的,只要对象不同,hashcode值就不同!
-
equals默认比较的是是否是同一个对象,要比较内容要重写equals方法!
Map!
-
Map与collection并列存在,Map用与保存具有映射关系的数据(键值对)key—-value(双列元素)、
-
Map中的key和value可以是任何引用类型的数据,会封装到hashnode对象中
-
Map中的key不允许重复,但是如果重复了,也就是key的值相同时,等价于替换,会将value的值替换上去
-
但是value的值是可以相同的,Map存储的时候是根据key的哈希值来确定索引的,所以value的值不影响存放
-
Map的key可以为null,value也可以为null,但是key为null时,只能有一个,value为null时可以多个!
-
常用String类作为Map的key
-
key和value之间存在单向一对一的关系,即通过指定的key总能找到对应的value,通过Map的get方法,传入一个key,会返回对应的value值
Map接口和常用方法:

Map的遍历方式:

HashMap map=new HashMap<>();
map.put("zzz","z");
map.put("ccc","v");
map.put("xxx","c");
map.put("bbb","e");
Set keySet = map.keySet();//map的方法,用来获得所有key的一个set集合
//通过获得键的方式,然后获得值
for (Object o :keySet) {
System.out.println(o+"-"+map.get(o));
}
Iterator iterator = keySet.iterator();
while (iterator.hasNext()){
Object key=iterator.next();
Object value=map.get(key);
System.out.println(key+"-"+value);
}
//可以直接获得值
Collection values = map.values();
Iterator iterator1 = values.iterator();
while (iterator1.hasNext()){
System.out.println(iterator1.next());
}
for (Object o :values) {
System.out.println(o);
}
//通过entryset遍历
Set entrySet = map.entrySet();//获得一个key和value的封装集合
//目的是为了更好的遍历,底层时存储在node数组里的,但是运行类型是Entryset,所以下面要是想要调用entry里的getkey和getvalue方法,先要向下转型一次(调用子类的特有方法跟属性时要向下转型才可调用!)
Iterator iterator2 = entrySet.iterator();
while (iterator2.hasNext()){
Map.Entry e=(Map.Entry) iterator2.next();
System.out.println(e.getKey()+""+e.getValue());
}
for (Object o :entrySet) {
Map.Entry e=(Map.Entry) o;
System.out.println(e.getKey()+""+e.getValue());
}

HashMap的底层机制:

HashMap底层源码解读:
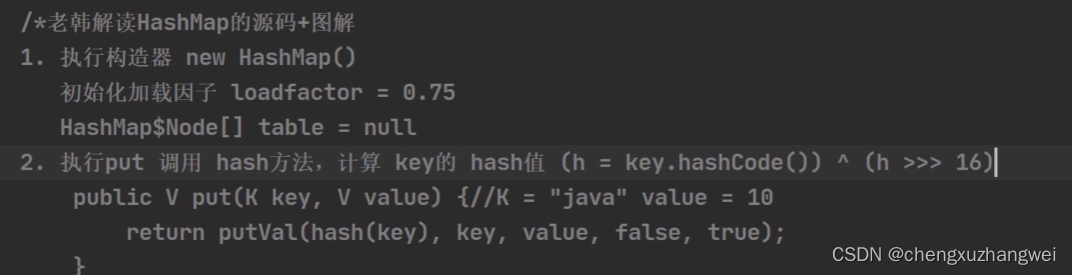
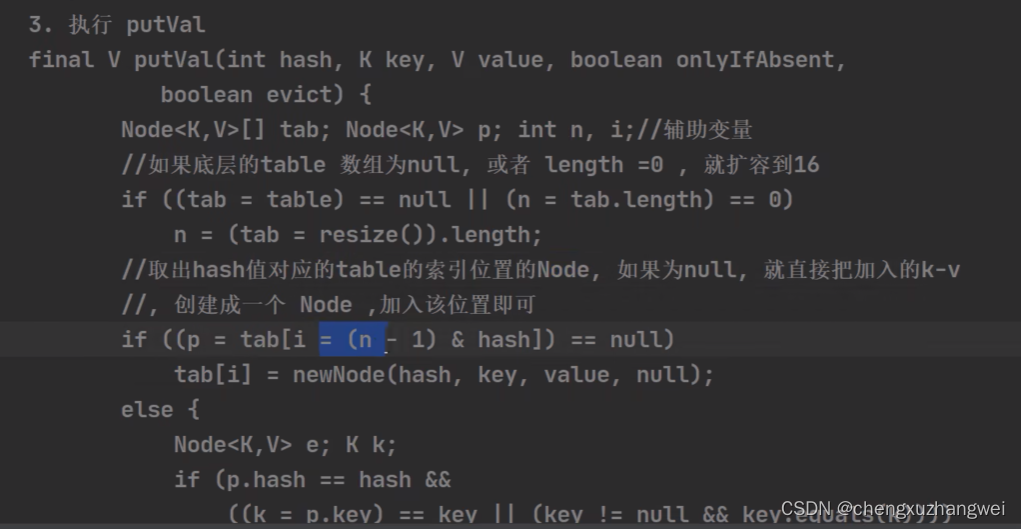
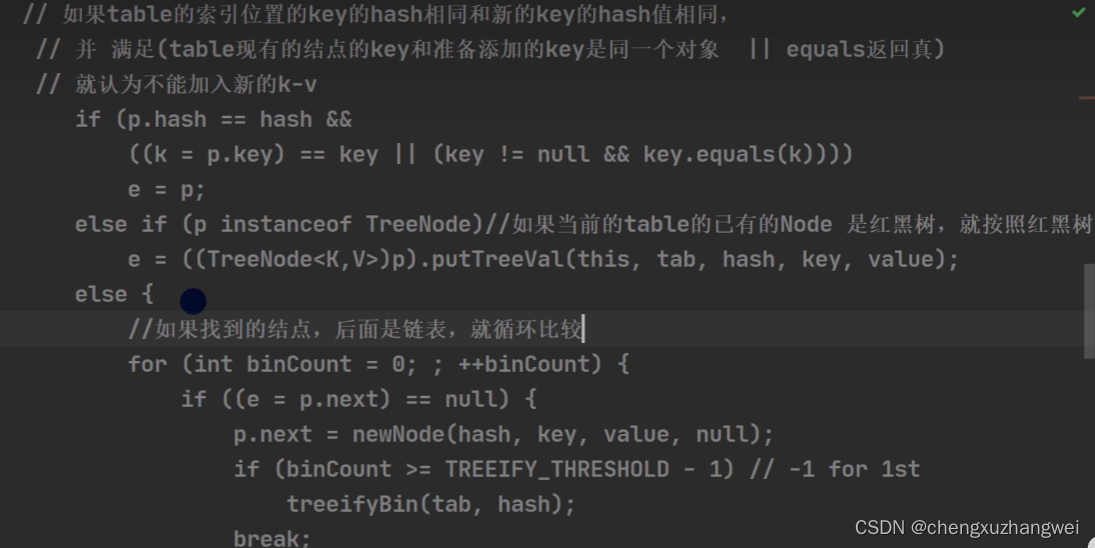
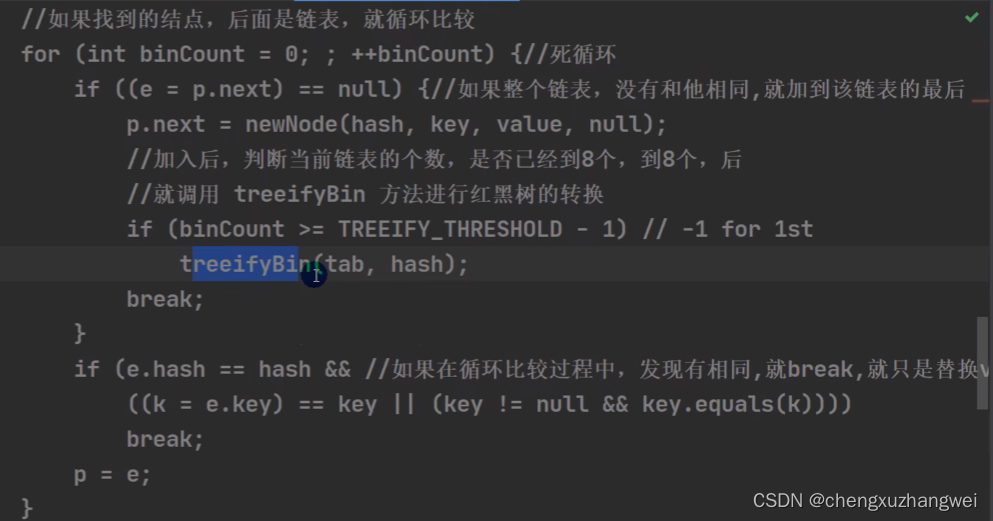
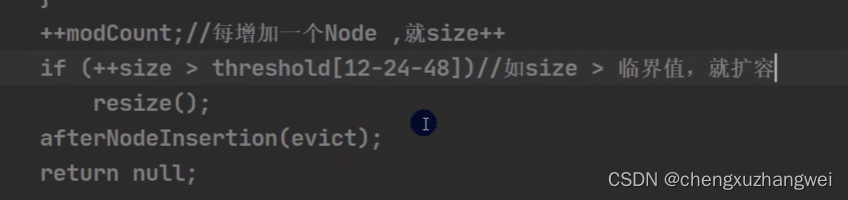
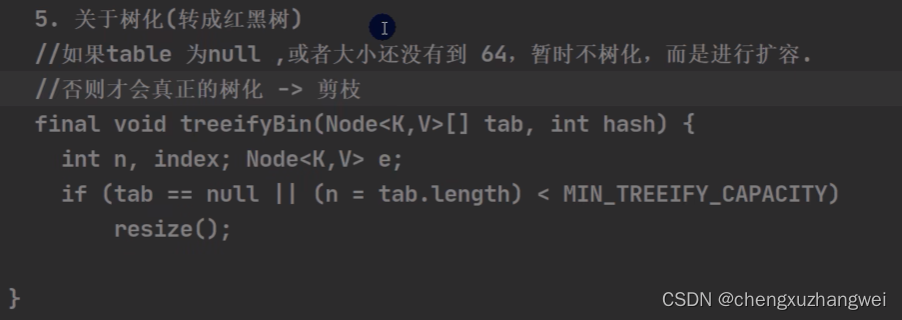
非常重要!!HashMap!
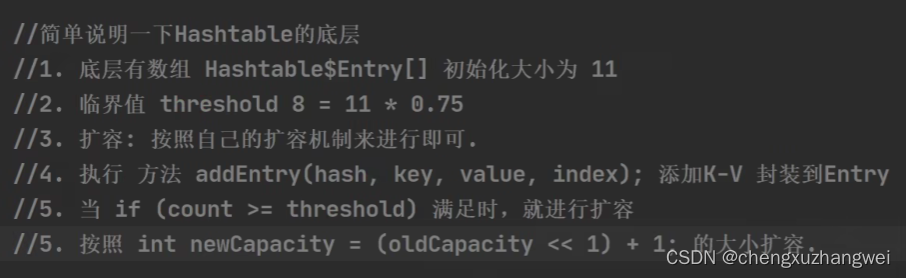
HashTable:

注意:hashtable的键跟值都不能为空!
HashMap的底层和扩容原理:

Properties:

Treeset:
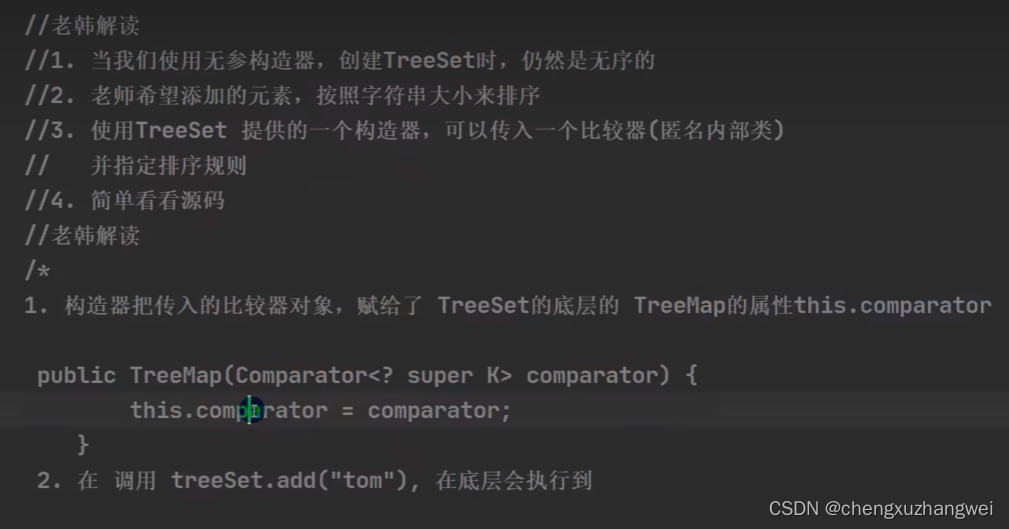
TreeMap:
Key类型决定默认排序类型
Collection类:


开发中如何选择集合:
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









