









1、批量查询
https://www.elastic.co/guide/en/elasticsearch/client/java-api/6.1/java-docs-multi-get.html
Multi Get API
The multi get API allows to get a list of documents based on their index, type and id:
package cn.hadron;
import cn.hadron.es.ESUtil;
import org.elasticsearch.action.get.GetResponse;
import org.elasticsearch.action.get.MultiGetItemResponse;
import org.elasticsearch.action.get.MultiGetResponse;
import org.elasticsearch.client.transport.TransportClient;
public class MultiGetDemo {
public static void main(String[] args) throws Exception{
TransportClient client= ESUtil.getClient();
MultiGetResponse mgResponse = client.prepareMultiGet()
.add("index1","blog","1","2")
.add("my-index","persion","1","2","2")
.get();
for(MultiGetItemResponse response:mgResponse){
GetResponse rp=response.getResponse();
if(rp!=null && rp.isExists()){
System.out.println(rp.getSourceAsString());
}
}
}
}
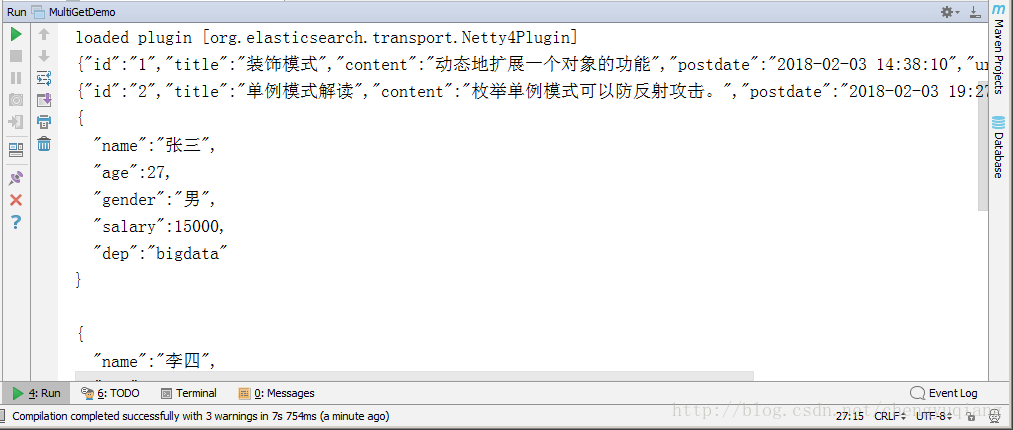
{"id":"1","title":"装饰模式","content":"动态地扩展一个对象的功能","postdate":"2018-02-03 14:38:10","url":"csdn.net/79239072"}
{"id":"2","title":"单例模式解读","content":"枚举单例模式可以防反射攻击。","postdate":"2018-02-03 19:27:00","url":"csdn.net/79247746"}
{
"name":"张三",
"age":27,
"gender":"男",
"salary":15000,
"dep":"bigdata"
}
{
"name":"李四",
"age":26,
"gender":"女",
"salary":15000,
"dep":"bigdata"
}
{
"name":"李四",
"age":26,
"gender":"女",
"salary":15000,
"dep":"bigdata"
}2、批量操作
https://www.elastic.co/guide/en/elasticsearch/client/java-api/6.1/java-docs-bulk.html
package cn.hadron;
import cn.hadron.es.ESUtil;
import org.elasticsearch.action.bulk.BulkRequestBuilder;
import org.elasticsearch.action.bulk.BulkResponse;
import org.elasticsearch.client.transport.TransportClient;
import java.util.Date;
import static org.elasticsearch.common.xcontent.XContentFactory.*;
public class BulkDemo {
public static void main(String[] args) throws Exception{
TransportClient client= ESUtil.getClient();
BulkRequestBuilder bulkRequest = client.prepareBulk();
bulkRequest.add(client.prepareIndex("twitter", "tweet", "1")
.setSource(jsonBuilder()
.startObject()
.field("user", "kimchy")
.field("postDate", new Date())
.field("message", "trying out Elasticsearch")
.endObject()
)
);
bulkRequest.add(client.prepareIndex("twitter", "tweet", "2")
.setSource(jsonBuilder()
.startObject()
.field("user", "kimchy")
.field("postDate", new Date())
.field("message", "another post")
.endObject()
)
);
//批量执行
BulkResponse bulkResponse = bulkRequest.get();
System.out.println(bulkResponse.status());
if (bulkResponse.hasFailures()) {
// process failures by iterating through each bulk response item
System.out.println("存在失败操作");
}
}
}
3、Bulk Processor(批量处理器)
https://www.elastic.co/guide/en/elasticsearch/client/java-api/6.1/java-docs-bulk-processor.html
The BulkProcessor class offers a simple interface to flush bulk operations automatically based on the number or size of requests, or after a given period.
BulkProcessor类提供了一个简单接口,可以根据请求的数量或大小自动刷新批量操作,也可以在给定的时间段之后自动刷新批量操作。
package cn.hadron;
import cn.hadron.es.ESUtil;
import org.elasticsearch.action.bulk.BackoffPolicy;
import org.elasticsearch.action.bulk.BulkProcessor;
import org.elasticsearch.action.bulk.BulkRequest;
import org.elasticsearch.action.bulk.BulkResponse;
import org.elasticsearch.action.delete.DeleteRequest;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.client.transport.TransportClient;
import org.elasticsearch.common.unit.ByteSizeUnit;
import org.elasticsearch.common.unit.ByteSizeValue;
import org.elasticsearch.common.unit.TimeValue;
import java.util.Date;
import static org.elasticsearch.common.xcontent.XContentFactory.jsonBuilder;
public class BulkProcessorDemo {
public static void main(String[] args) throws Exception{
TransportClient client= ESUtil.getClient();
BulkProcessor bulkProcessor = BulkProcessor.builder(
client,
new BulkProcessor.Listener() {
@Override
public void beforeBulk(long executionId,BulkRequest request) {
//设置bulk批处理的预备工作
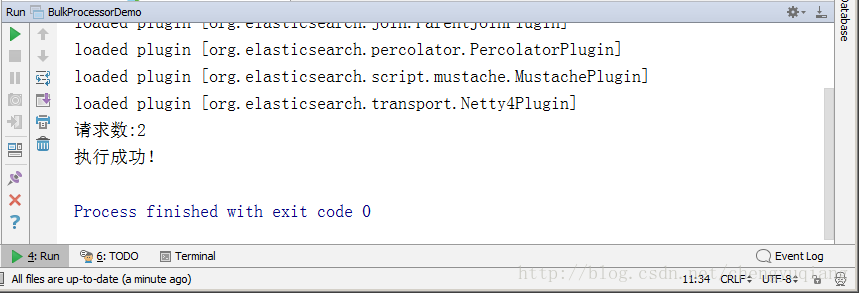
System.out.println("请求数:"+request.numberOfActions());
}
@Override
public void afterBulk(long executionId,BulkRequest request,BulkResponse response) {
//设置bulk批处理的善后工作
if(!response.hasFailures()) {
System.out.println("执行成功!");
}else {
System.out.println("执行失败!");
}
}
@Override
public void afterBulk(long executionId,BulkRequest request,Throwable failure) {
//设置bulk批处理的异常处理工作
System.out.println(failure);
}
})
.setBulkActions(1000)//设置提交批处理操作的请求阀值数
.setBulkSize(new ByteSizeValue(5, ByteSizeUnit.MB))//设置提交批处理操作的请求大小阀值
.setFlushInterval(TimeValue.timeValueSeconds(5))//设置刷新索引时间间隔
.setConcurrentRequests(1)//设置并发处理线程个数
//设置回滚策略,等待时间100ms,retry次数为3次
.setBackoffPolicy(BackoffPolicy.exponentialBackoff(TimeValue.timeValueMillis(100), 3))
.build();
// Add your requests
bulkProcessor.add(new DeleteRequest("twitter", "tweet", "1"));
bulkProcessor.add(new DeleteRequest("twitter", "tweet", "2"));
// 刷新所有请求
bulkProcessor.flush();
// 关闭bulkProcessor
bulkProcessor.close();
// 刷新索引
client.admin().indices().prepareRefresh().get();
// Now you can start searching!
client.prepareSearch().get();
}
}
GET twitter/_search{
"took": 6,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 0,
"max_score": null,
"hits": []
}
}4、查询删除
https://www.elastic.co/guide/en/elasticsearch/client/java-api/6.1/java-docs-delete-by-query.html
package cn.hadron;
import cn.hadron.es.ESUtil;
import org.elasticsearch.client.transport.TransportClient;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.index.reindex.BulkByScrollResponse;
import org.elasticsearch.index.reindex.DeleteByQueryAction;
public class DeleteByQueryDemo {
public static void main(String[] args){
TransportClient client= ESUtil.getClient();
BulkByScrollResponse response =DeleteByQueryAction.INSTANCE
.newRequestBuilder(client)
.filter(QueryBuilders.matchQuery("title", "模式"))
.source("index1")//设置索引名称
.get();
//被删除文档数目
long deleted = response.getDeleted();
System.out.println(deleted);
}
}
执行结果
no modules loaded
loaded plugin [org.elasticsearch.index.reindex.ReindexPlugin]
loaded plugin [org.elasticsearch.join.ParentJoinPlugin]
loaded plugin [org.elasticsearch.percolator.PercolatorPlugin]
loaded plugin [org.elasticsearch.script.mustache.MustachePlugin]
loaded plugin [org.elasticsearch.transport.Netty4Plugin]
2
Process finished with exit code 0
GET index1/_search{
"took": 2,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 0,
"max_score": null,
"hits": []
}
}














 550
550











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









