






1、集群规划
5台机器,实现NameNode+HA、ResourceManager+HA集群:主机规划如下:
| master (192.168.1.190) | node1 (192.168.1.191) | node2 (192.168.1.192) | node3 (192.168.1.193) | node4 (192.168.1.194) | |
| NameNode | √ | √ | × | × | × |
| ResourceManager | √ | √ | × | × | × |
| DataNode | × | × | √ | √ | √ |
| JournalNode | √ | √ | √ | √ | √ |
2、环境准备
2.1 修改主机名
依次将主机名更改为master、node1、node2、node3、node4:
vi /etc/hostname
#修改localhost.localdomain 为 master
:wq
reboot
uname -n 查看
2.2 修改host文件
修改host文件使个主机静态ip与主机名对应,以master为例:
# vi /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.1.190 master
192.168.1.191 node1
192.168.1.192 node2
192.168.1.193 node3
192.168.1.194 node42.3 关闭防火墙
这里我们因为是虚拟机,不是正式环境,则直接关闭防火墙,正式环境则添加对应端口策略即可
//临时关闭
# systemctl stop firewalld
//禁止开机启动
# systemctl disable firewalld2.4 配置SSH免密通信
- 依次在master、node1~4 上生成ssh密钥
#root用户操作 ssh-keygen -t rsa cp ~/.ssh/id_rsa.pub ~/.ssh/authorized_keys
- 依次将node1~4的公钥复制到master上
cat ~/.ssh/id_rsa.pub | ssh root@master 'cat >> ~/.ssh/authorized_keys'
- 复制完成后查看~/.ssh/authorized_keys
[root@master ~]# cat ./.ssh/authorized_keys ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQDAzhYbxKgTFYDuy4y3YPZuT4qsUwkQ+w3HnoSkNTxGgHZBc1N0DvBejP9FJGbsmh4iiu7fCkBhF3qlHvOpuV08hmvz4XyZuC8LI3i4GoC7bRpQSGP1yNj7b2ALnym1LdxmH6ZklFR8Pw/mJfbO1tSy+GgTQhZ4q7mHz7UZsX07FqSXKlq7a50YC/Sn07OIouxhOHXP562dRgNCHGPVaKhFDkjNQ20B4Y4Cxp65qpn3i5VxeF7jzPURPctpXGxLGFXtsRN9dhdzGdyveU2y+MCgvaU/56+5+8RY5ntdxDhK2YFQTDV03WvFnQgnwf5phwSMOT4edepKKMt4DB9uV+Xf root@master ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQCweHdeKK1KI5zE30paQz9hIknYs+nEoM+YiRim4MJmT9EQqyg2sGun9Oiiy46pxjT5liNSmt57pNwPiuRS/xcw6E+XaXP1VEmnWmnc/p3PDNkp+KOzAlzlsR0Dmte+XGy5pVhtYLD4VFMznpoT0RplmjwGRJglAL2tbnww4MPF4UHrNW/1BzVAQpYv0lagmSZKd0gAagaMrlzmTrVvnkvYDm3M1R2kWWWxYjI/7H/1sBlvfpFN/G88p/MiX326AP+UtsYXJkrBqURgHk2ujBl9vmfS/pKFIdkr17qy8dDxVw+bkr2hc0XEDcoPZ3p94B4oVFWGdCroBAjf+PSTRDal root@node1 ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQCinDEbLRBDwI6jFFZTD/6Jtj/n8xEXWcY9S8AXLVrsKRyy+MyB9TJTUQSODMdgTm7fHf3OnUMCOdw1z7ASMoxyy4twGCShEofPgjss3rx6Q04RV7M3BJP3r3rlnf4ug0RSKvu5cTUs1uLf20DkYuCr41VEgFqIyf2xbfVn9X3nhE+5KaVzQ91LjUbFPhF+DY/ymwcAndDOMYCEH+l+Oa9Dxf3J89AcuntE+hB4WVAOZZwLRxU8lHHt3SlRPS+wQQR9EPjcUjVPsEIefFAgM1AcVoMA5IcOau1Zq9orXLiLTh6+evpFKi98oj8qty76VrR2uLDy4ERiE5g0ipoAcZ5r root@node2 ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQDhWI2MU66BNQbZx9hvpCnpuugybgPRLMiRAieZWqPnzjDDgtBS+2KEnfWs+7opRgsDt4Y9flRfg8HmNEEu74HbJgLvnivpG9K9Uj+kE04e+RWLKVrzu595slBjQsmN2iDpMeW98dkEpPG48PjGN3Z5NBkCVAB8bo9FqGi16a8KZS7s8hzmCxVjAiBUkoDozu7+lis5ueSvHQFEhtUPglQ094zm0UgnpjTZZSUvM2300zNXpXfAyShaMOQB4XBLDsR5qtQWGjpE++lnzZfCmrHbX1tLnq0HJm09gvp0nVLxkmlZdCx05qtwKOH1zbxJjajB9UyMDkHXyeKBzsckz/zX root@node3 ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQCwfBb3rXgU9KfA5MPwvhb6y5jj4oc3aOnHinnBe9EG2JRFU1TWlInHmHny3JqmryfavUqAId3xxeXwIYWbHzJUnuM3fILQTKuiWdxUJ1Ca+rIfqvAMaoDsQWOytTNJ7hdB9o+d2JOaXyNQUDp69ziuu8iPGg/Loco41uQ+20ci5zKZV/wqWfIUg+JZjgaw28FT6XSI7Eq9UeTLAPlNuGKYE2B6ufIl0aksvJ4zKjkiCHELR9TmaxarAAp7msLJ/Da2L7RMGIjaY3wMSM2qZrnQfK6JppZp+HkYpLs/qceRkXdlYC879rx80tKSH2VQAhwIkZXmoG44zpHBJ5YAnZed root@node4
- 将master上的authorized_keys文件分发到其他node1~4节点
#master上执行 scp -r ~/.ssh/authorized_keys root@node1:~/.ssh/ scp -r ~/.ssh/authorized_keys root@node2:~/.ssh/ scp -r ~/.ssh/authorized_keys root@node3:~/.ssh/ scp -r ~/.ssh/authorized_keys root@node4:~/.ssh/ - 测试,在master上分别ssh node1~4进行测试,不用输入密码即可登录则OK
2.5 安装Zookeeper
2.5.1 下载解压
#下载
wget http://mirrors.hust.edu.cn/apache/zookeeper/stable/zookeeper-3.4.12.tar.gz
#解压
tar -xvf zookeeper-3.4.12.tar.gz -C /usr/local/apps/
#重命名
mv /usr/local/apps/zookeeper-3.4.12 /usr/local/app/zookeeper2.5.2 编辑zoo.cfg
$ cp conf/zoo_sample.cfg conf/zoo.cfg
$ vi zoo.cfg
#修改内容
dataDir=/usr/hadoop/data/zookeeper/zkdata
#追加内容
#log dir
dataLogDir=/usr/hadoop/data/zookeeper/zkdatalog
server.1=master:2888:3888
server.2=node1:2888:3888
server.3=node2:2888:3888
server.4=node3:2888:3888
server.5=node4:2888:38882.5.3 复制zookeeper到其他节点
scp -r /usr/local/apps/zookeeper root@node1:/usr/local/apps
scp -r /usr/local/apps/zookeeper root@node2:/usr/local/apps
scp -r /usr/local/apps/zookeeper root@node3:/usr/local/apps
scp -r /usr/local/apps/zookeeper root@node4:/usr/local/apps2.5.4 创建目录及id文件
#创建data dir
mkdir /usr/hadoop/data/zookeeper/zkdata
#创建日志目录
mkdir /usr/hadoop/data/zookeeper/zkdatalog
#创建安id文件(master~node4 依次填充配置内对应值1~5)
vi /usr/hadoop/data/zookeeper/zkdata/myid2.5.5 配置环境变量
#依次在所有节点服务器上配置zookeeper环境变量
# vi /etc/profile
#zookeeper enviroment
export ZOOKEEPER_HOME=/usr/local/apps/zookeeper
export PATH=$PATH:$ZOOKEEPER_HOME/bin
#source /etc/profile2.5.6 启动测试
[root@master zookeeper]# bin/zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /usr/local/apps/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[root@master zookeeper]# jps
5931 QuorumPeerMain
5949 Jps
[root@master zookeeper]# bin/zkServer.sh stop
ZooKeeper JMX enabled by default
Using config: /usr/local/apps/zookeeper/bin/../conf/zoo.cfg
Stopping zookeeper ... STOPPED
[root@master zookeeper]#
启动所有节点上的zookeeper,并查看状态
ssh master "zkServer.sh status"
ssh node1 "zkServer.sh status"
ssh node2 "zkServer.sh status"
ssh node3 "zkServer.sh status"
ssh node4 "zkServer.sh status"
#出现1个leader,4个follower3、Hadoop配置
3.1 core-site.xml配置
<configuration>
<!-- defalut HDFS path,named cluster1 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://cluster1</value>
</property>
<!-- hadoop temporary directories,split by , -->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/hadoop/data/tmp</value>
</property>
<!-- zookeeper manage hdfs -->
<property>
<name>ha.zookeeper.quorum</name>
<value>master:2181,node1:2181,node2:2181,node3:2181,node4:2181</value>
</property>
</configuration>3.2 hdfs-site.xml配置
<configuration>
<!-- 数据块副本数量:一般设置3,副本数越大,磁盘空间要求越高 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 关闭权限检查 -->
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<!-- 命名空间,该值与fs.defaultFS的值对应,name高可用之后有两个namenode,cluster1是对外提供的统一入口 -->
<property>
<name>dfs.nameservices</name>
<value>cluster1</value>
</property>
<!-- 指定nameService:cluster1下的namenode,‘,’分隔-->
<property>
<name>dfs.ha.namenodes.cluster1</name>
<value>nameService1,nameService2</value>
</property>
<!-- nameService1的RPC地址 -->
<property>
<name>dfs.namenode.rpc-address.cluster1.nameService1</name>
<value>master:9000</value>
</property>
<!-- nameService1的http地址 -->
<property>
<name>dfs.namenode.http-address.cluster1.nameService1</name>
<value>master:50070</value>
</property>
<!-- nameService2的RPC地址 -->
<property>
<name>dfs.namenode.rpc-address.cluster1.nameService2</name>
<value>node1:9000</value>
</property>
<!-- nameService2的http地址 -->
<property>
<name>dfs.namenode.http-address.cluster1.nameService2</name>
<value>node1:50070</value>
</property>
<!-- 启动故障自动恢复 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 设置一组 journalNode 的 URI 地址:qjournal://host1:port1;host2:port2;host3:port3/journalId,其中,journalId 是该命名空间的唯一 ID -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://master:8485;node1:8485;node2:8485;node3:8485;node4:8485/cluster1</value>
</property>
<!-- 指定cluster1出故障时,哪个实现类负责执行故障切换 -->
<property>
<name>dfs.client.failover.proxy.provider.cluster1</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- JournalNode 所在节点上的一个目录,用于存放 editlog 和其他状态信息。该参数只能设置一个目录,你可以对磁盘做 RIAD 提高数据可靠性。 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/usr/hadoop/data/journaldata/jn</value>
</property>
<!-- 主备架构解决单点故障问题时,必须要认真解决的是脑裂问题,即出现两个 master 同时对外提供服务,导致系统处于不一致状态,可能导致数据丢失等潜在问题。在 HDFS HA 中,JournalNode 只允许一个 NameNode 写数据,不会出现两个 active NameNode 的问题, 但是,当主备切换时,之前的 active NameNode 可能仍在处理客户端的 RPC 请求,为此, 需要增加隔离机制(fencing)将之前的 active
NameNode 杀死 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>shell(/bin/true)</value>
</property>
<!-- 设置该值的一般原则是将其设置为集群大小的自然对数乘以20,即20logN,N为集群大小
python -c 'import math ; print int(math.log(N) * 20)'
#N 集群服务器数量 -->
<property>
<name>dfs.namenode.handler.count</name>
<value>32</value>
</property>
</configuration>3.3 slaves配置
node2
node3
node43.4 节点复制
复制master上的配置到node1~node4,如果其他服务器安装好hadoop,则复制配置文件
scp -r /usr/local/apps/hadoop root@node1:/usr/local/apps
scp -r /usr/local/apps/hadoop root@node2:/usr/local/apps
scp -r /usr/local/apps/hadoop root@node3:/usr/local/apps
scp -r /usr/local/apps/hadoop root@node4:/usr/local/apps4、启动
4.1 启动所有节点的journalnode
分别在master、node1~node4上启动journalnode进程:
/usr/local/apps/hadoop/sbin/hadoop-daemon.sh start journalnode4.2 在主节点(master)上进行格式化
- namenode格式化
/usr/local/apps/hadoop/bin/hdfs namenode -format - 格式化高可用
/usr/local/apps/hadoop/bin/hdfs zkfc -formatZK - 启动namenode
/usr/local/apps/hadoop/bin/hdfs namenode
4.3 在备用节点(备用namenode)上执行数据同步
/usr/local/apps/hadoop/bin/hdfs namenode -bootstrapStandby4.4 停止master namenode进程以及所有节点的journalnode
切换到master,Ctrl+C结束namenode进程,并且在所有journalnode节点服务器上停止journalnode服务:/usr/hadoop/app/hadoop/sbin/hadoop-daemon.sh stop journalnode
4.5 一键启动
#在master上执行
/usr/local/apps/hadoop/sbin/start-hdfs.sh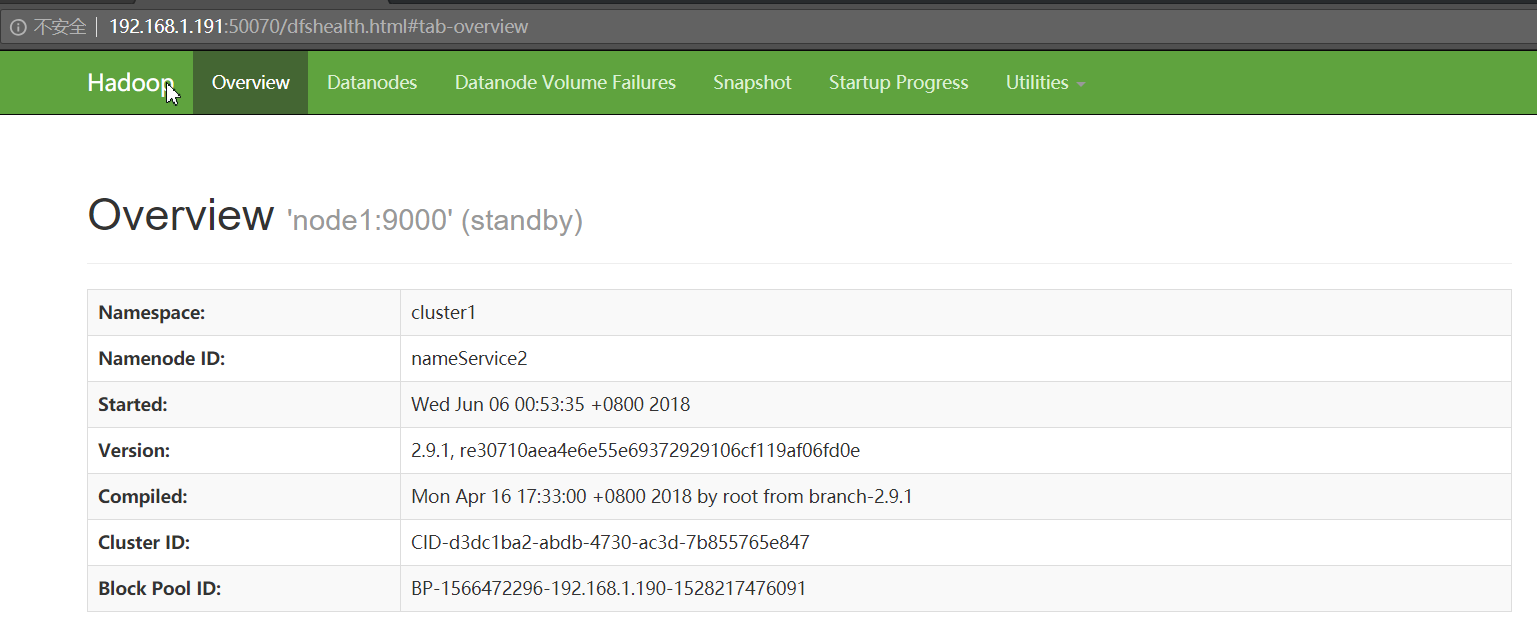
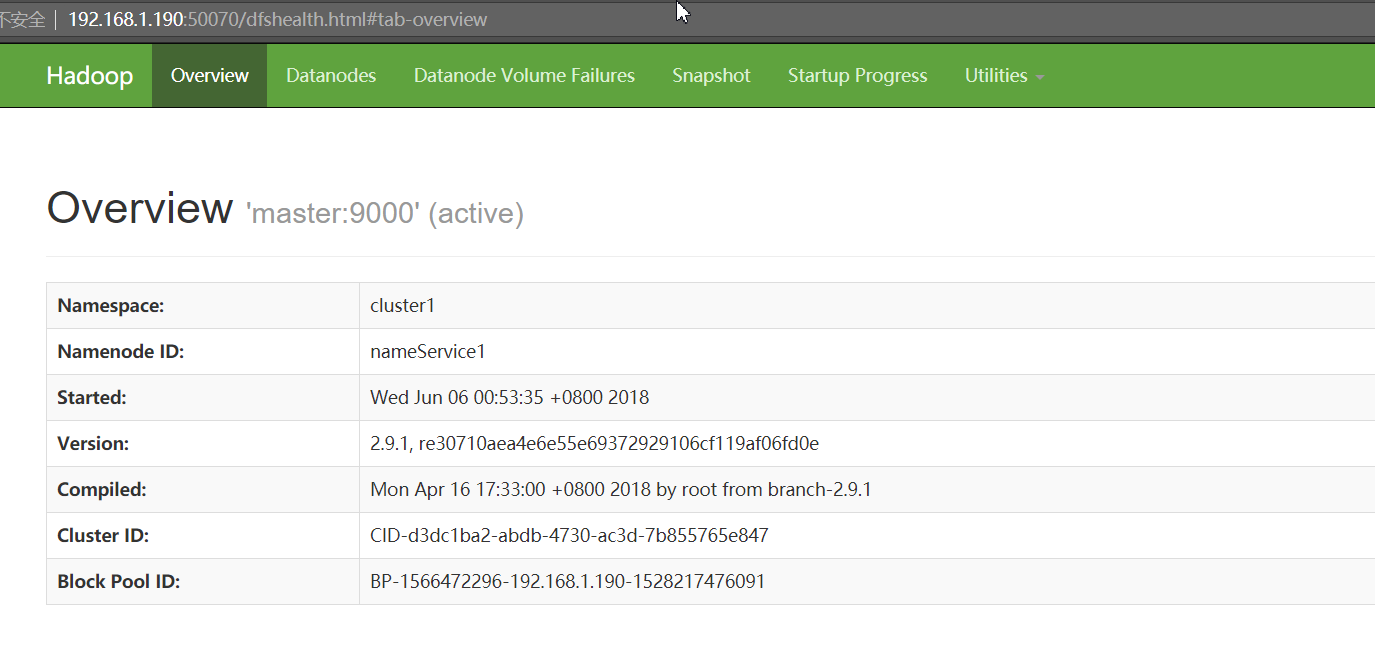
#切换active namenode,将nameService1切换到nameService2
[root@master hadoop]# bin/hdfs haadmin -failover nameService1 nameService2
Failover to NameNode at node1/192.168.1.191:9000 successful
===========
关于hadoop的记录暂且记录到这里,后续在实际应用相关联的时候进行有针对性的记录















 650
650

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









