






Kaggle用简单一句话来概括是一个数据分析的竞赛平台,现在已经被Google收购了。
作为机器学习、数据分析、数据挖掘方面的专业人员或爱好者,可以在上面学习到很多先进的方法和经验。
本文介绍一下如何参与Kaggle平台,如何参加一个比赛,如何提交自己的算法并看到排行榜的排名情况。
首先,注册一个自己的账号。注册过程中由于用到了Google的验证码服务,而这个服务国内是被墙的,所以请自行翻墙。
接下来,我们选择一个最简单的例子来进行。我们选择的是泰坦尼克求人员生存率的问题。具体地址https://www.kaggle.com/c/titanic
下载数据集
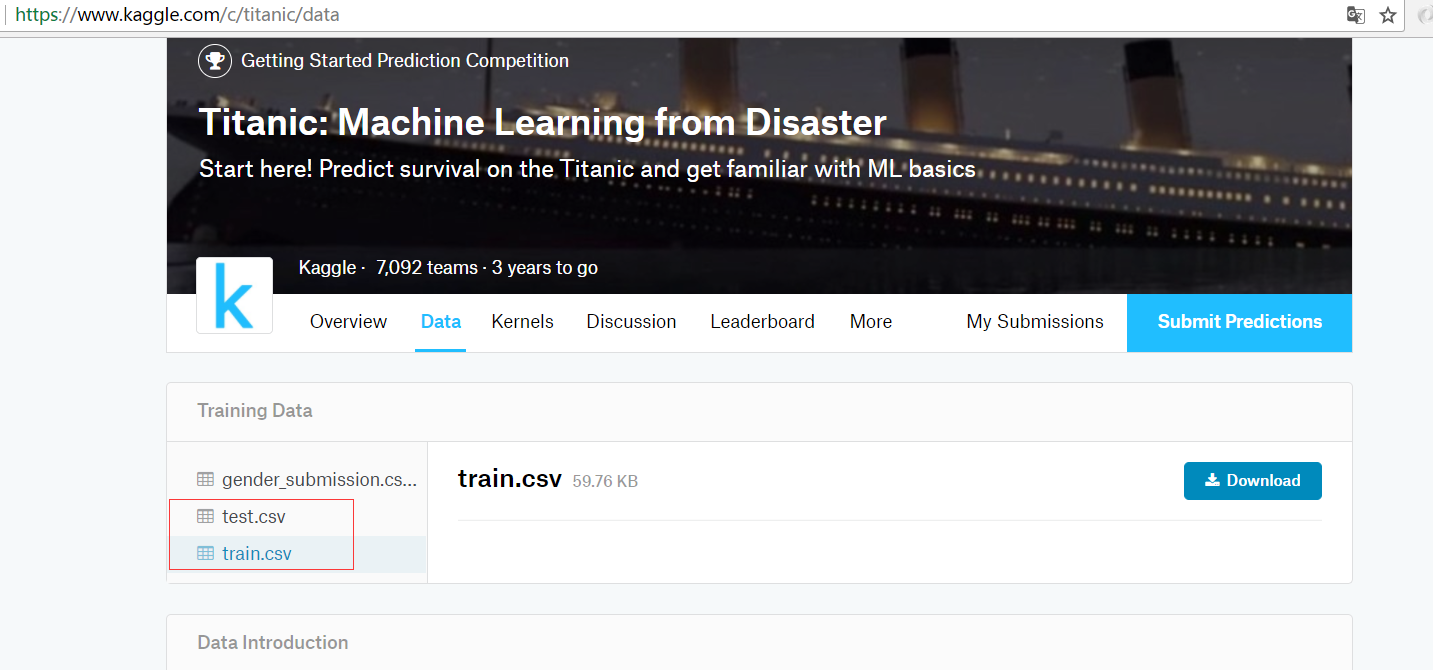
train.csv用于训练,test.csv用于评估
数据集字段说明
PassengerId 乘客ID
Survived 是否幸存
Pclass 客舱客级
Name 乘客姓名
Sex 乘客性别
Age 乘客年龄
SibSp 兄弟姐妹和配偶在船数量
ParCh 父母孩子在船数量
Ticket 船票号
Fare船票价格
Cabin客舱位置
Embarked 登船港口的编号
下面我们通过代码来演示如何基于Tensorflow框架使用逻辑回归算法来预测幸存率。
import numpy as np
import pandas as pd
import tensorflow as tf
# 读训练数据
data = pd.read_csv('data/train.csv')
#数据预处理
data['Sex'] = data['Sex'].apply(lambda s: 1 if s == 'male' else 0) #把性别从字符串类型转换为0或1数值型数据
data = data.fillna(0) #缺失字段填0
# 选取特征
dataset_X = data[['Sex', 'Age', 'Pclass', 'SibSp', 'Parch', 'Fare']].as_matrix()
#字段说明:性别,年龄,客舱等级,兄弟姐妹和配偶在船数量,父母孩子在船的数量,船票价格
# 建立标签数据集
data['Deceased'] = data['Survived'].apply(lambda s: 1 - s)
dataset_Y = data[['Deceased', 'Survived']].as_matrix()
# 定义计算图
# 定义占位符
X = tf.placeholder(tf.float32, shape=[None, 6])
y = tf.placeholder(tf.float32, shape=[None, 2])
#使用逻辑回归算法
weights = tf.Variable(tf.random_normal([6, 2]), name='weights')
bias = tf.Variable(tf.zeros([2]), name='bias')
y_pred = tf.nn.softmax(tf.matmul(X, weights) + bias)
# 定义交叉熵
cross_entropy = - tf.reduce_sum(y * tf.log(y_pred + 1e-10), reduction_indices=1)
#定义损失函数
cost = tf.reduce_mean(cross_entropy)
# 使用梯度下降优化算法最小化损失函数
train_op = tf.train.GradientDescentOptimizer(0.001).minimize(cost)
with tf.Session() as sess:
# 变量初始化
tf.global_variables_initializer().run()
# 训练模型
for epoch in range(50):
total_loss = 0.
for i in range(len(dataset_X)):
# prepare feed data and run
feed_dict = {X: [dataset_X[i]], y: [dataset_Y[i]]}
_, loss = sess.run([train_op, cost], feed_dict=feed_dict)
total_loss += loss
# display loss per epoch
print('Epoch: %04d, total loss=%.9f' % (epoch + 1, total_loss))
print("Train Complete")
# 读测试数据
testdata = pd.read_csv('data/test.csv')
#数据清洗, 数据预处理
testdata = testdata.fillna(0)
testdata['Sex'] = testdata['Sex'].apply(lambda s: 1 if s == 'male' else 0)
#特征选择
X_test = testdata[['Sex', 'Age', 'Pclass', 'SibSp', 'Parch', 'Fare']]
#评估模型
predictions = np.argmax(sess.run(y_pred, feed_dict={X: X_test}), 1)
#保存结果
submission = pd.DataFrame({
"PassengerId": testdata["PassengerId"],
"Survived": predictions
})
submission.to_csv("titanic-submission.csv", index=False)
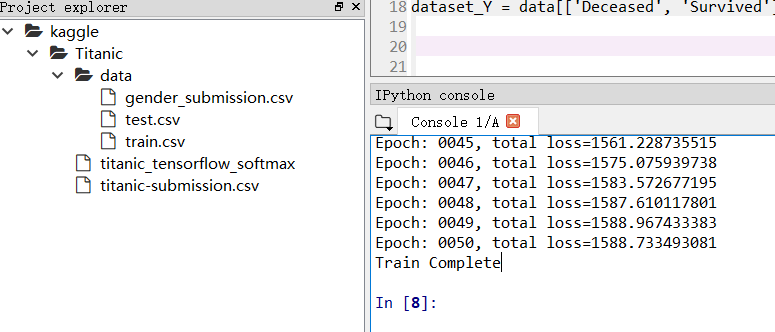
运行结果
把保存的结果titanic-submission.csv上传到Kaggle平台。如下图所示,把titanic-submission.csv拖入文件上传区域即可。
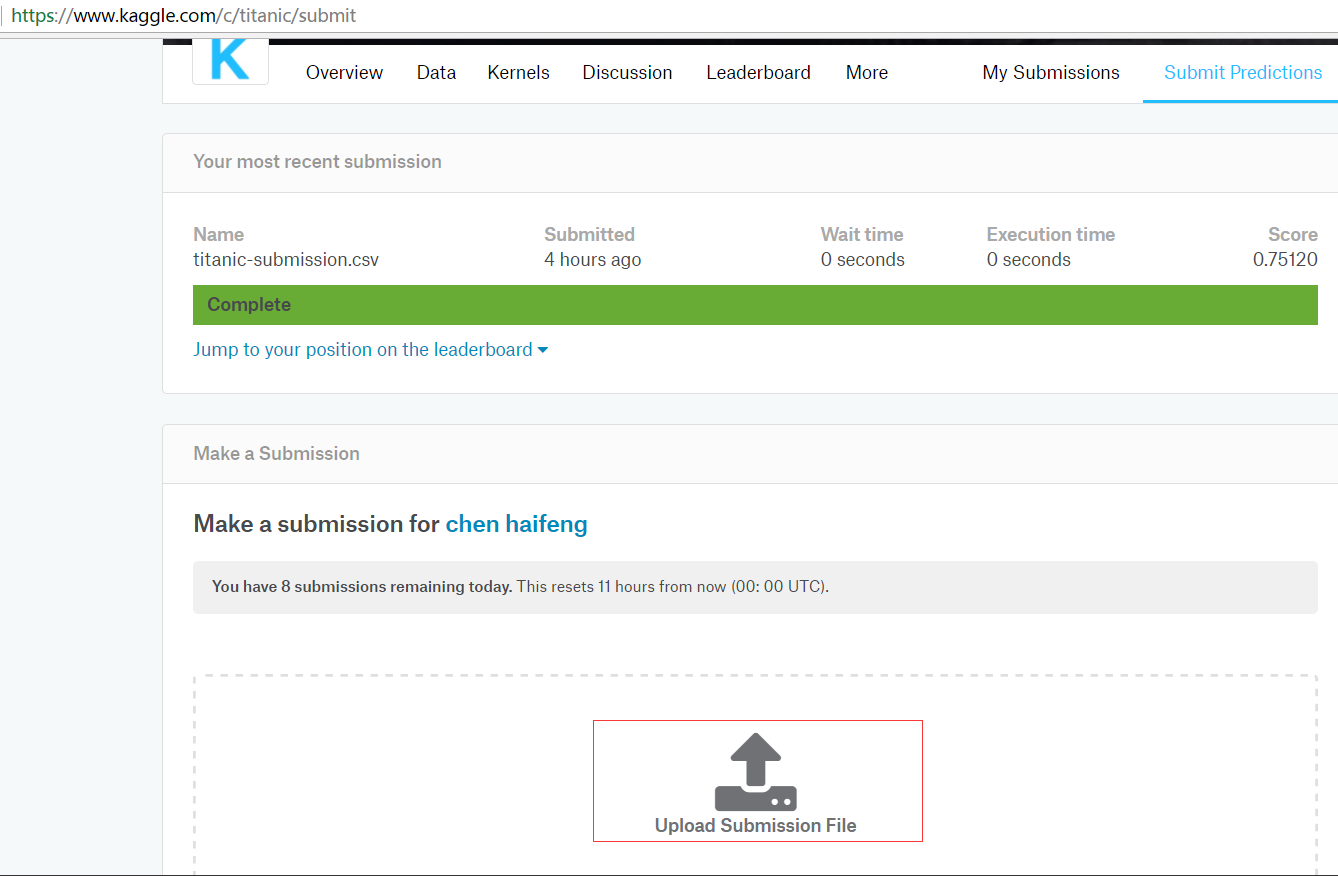
稍等片刻就会出现此次结果的一个评分排名情况。
















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









