







又到了假期,忙碌了一个学期,终于可以休息一下了。
一直想再Kaggle上参加一次比赛,在学校要上课,还跟老师做个项目,现在有时间了,就马上用Kaggle的入门比赛试试手。
一场比赛,总的来说收获不小,平时学习的时候总是眼高手低,结果中间出现令人吐血的失误 >_<
Kaggle比赛介绍
简而言之,Kaggle 是玩数据、ML 的开发者们展示功力、扬名立万的江湖,网址:https://www.kaggle.com/
Kaggle虽然高手云集,但是对于萌新们来说也是非常友好的,这次的Titanic问题就是适合萌新Getting Started的入门题。
Kaggle 是当今最大的数据科学家、机器学习开发者社区,其行业地位独一无二。
Titanic问题概述
Titanic: Machine Learning from Disaster
比赛说明
RMS泰坦尼克号的沉没是历史上最臭名昭着的沉船之一。 1912年4月15日,在首航期间,泰坦尼克号撞上一座冰山后沉没,2224名乘客和机组人员中有1502人遇难。这一耸人听闻的悲剧震撼了国际社会,导致了更好的船舶安全条例。
沉船导致生命损失的原因之一是乘客和船员没有足够的救生艇。虽然幸存下来的运气有一些因素,但一些人比其他人更有可能生存,比如妇女,儿童和上层阶级。
在这个挑战中,我们要求你完成对什么样的人可能生存的分析。特别是,我们要求你运用机器学习的工具来预测哪些乘客幸存下来的悲剧。
目标
这是你的工作,以预测是否有乘客幸存下来的泰坦尼克号或不。
对于测试集中的每个PassengerId,您必须预测Survived变量的0或1值。
度量值
您的分数是您正确预测的乘客的百分比。这被称为“准确性”。
提交文件格式
你应该提交一个csv文件,正好有418个条目和一个标题行。如果您有额外的列(超出PassengerId和Survived)或行,您的提交将会显示错误。
该文件应该有2列:
PassengerId(按任意顺序排序)
生存(包含你的二元预测:1存活,0死亡)
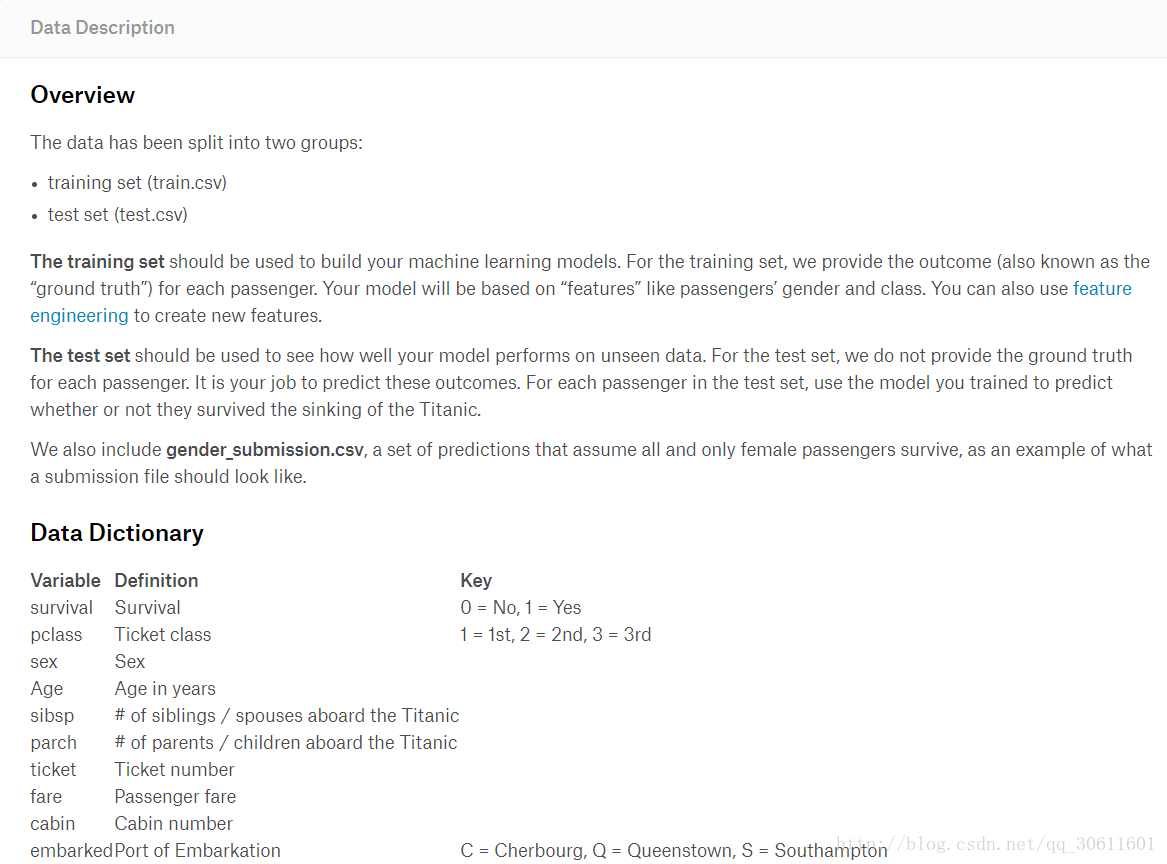
数据总览
首先,我们先把一些库和训练数据导入
import os
import numpy as np
import pandas as pd
import tensorflow as tf
train_data = pd.read_csv('train.csv')
print(train_data.info())简单的看一下训练数据的信息,其中Embarked有两个缺失值,Age缺失值较多,Cabin有效值太少了跟本没什么用。
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
PassengerId 891 non-null int64
Survived 891 non-null int64
Pclass 891 non-null int64
Name 891 non-null object
Sex 891 non-null object
Age 714 non-null float64
SibSp <
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











