







Android volley架构分析
我们在开发Android应用时,网络技术是非常普遍的,大多数情况下我们都是使用Http协议,Android系统中主要有两种方式来进行Http的通信,HttpURLConnection和HttpClient。我们在实际编程过程中会发现这两个类用起来还是很复杂的,而Volley就是将其进行适当的封装,使开发者用起来就比较简单。
一、Volley例子
(1)初始化对象
RequestQueue mQueue = Volley.newRequestQueue(context);
(2)Get请求
StringRequest stringRequest = new StringRequest("http://www.baidu.com",
new Response.Listener<String>() {
@Override
public void onResponse(String response) {
Toast.makeText(MainActivity.this, response, Toast.LENGTH_SHORT).show();
}
}, new Response.ErrorListener() {
@Override
public void onErrorResponse(VolleyError error) {
showlog(error.getMessage());
}
})
(3)发送请求
mQueue.add(stringRequest);
二、Volley总体设计
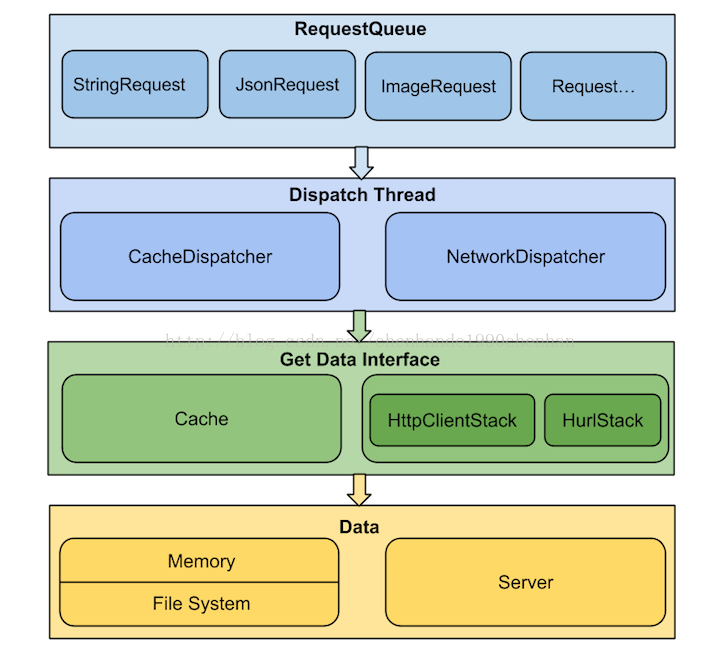
Volley 的调用比较简单,通过 newRequestQueue(…) 函数新建并启动一个请求队列RequestQueue后,只需要往这个RequestQueue不断 add Request 即可。
Volley:Volley 对外暴露的 API,通过 newRequestQueue(…) 函数新建并启动一个请求队列RequestQueue。
Request:表示一个请求的抽象类。StringRequest、JsonRequest、ImageRequest都是它的子类,表示某种类型的请求。
RequestQueue:表示请求队列,里面包含一个CacheDispatcher(用于处理走缓存请求的调度线程)、NetworkDispatcher数组(用于处理走网络请求的调度线程),一个ResponseDelivery(返回结果分发接口),通过 start() 函数启动时会启动CacheDispatcher和NetworkDispatchers。
CacheDispatcher:一个线程,用于调度处理走缓存的请求。启动后会不断从缓存请求队列中取请求处理,队列为空则等待,请求处理结束则将结果传递给ResponseDelivery去执行后续处理。当结果未缓存过、缓存失效或缓存需要刷新的情况下,该请求都需要重新进入NetworkDispatcher去调度处理。
NetworkDispatcher:一个线程,用于调度处理走网络的请求。启动后会不断从网络请求队列中取请求处理,队列为空则等待,请求处理结束则将结果传递给ResponseDelivery去执行后续处理,并判断结果是否要进行缓存。
ResponseDelivery:返回结果分发接口,目前只有基于ExecutorDelivery的在入参 handler 对应线程内进行分发。
HttpStack:处理 Http 请求,返回请求结果。目前 Volley 中有基于 HttpURLConnection 的HurlStack和 基于 Apache HttpClient 的HttpClientStack。
Network:调用HttpStack处理请求,并将结果转换为可被ResponseDelivery处理的NetworkResponse。
Cache:缓存请求结果,Volley 默认使用的是基于 sdcard 的DiskBasedCache。NetworkDispatcher得到请求结果后判断是否需要存储在 Cache,CacheDispatcher会从 Cache 中取缓存结果。
三、Volley类图

上面的类图我们采用从上往下,从左往右的顺利进行:
1、用户通过Volley对象新建一个RequestQueue,然后再创建一个Request的请求方式;(通过Request下面有继承的几种请求方式,我们完全可以通过继承Request定义自己的请求方式,比如XML方式)
2、RequestQueue被初始化后会分别启动NetworkDispatch线程和CacheDispatch线程;
3、NetworkDispatch线程将用户的Request请求通过Network接口去启用具体的Http请求;(BaseNetwork实现Network接口,并且调用HttpStack接口)
4、HttpStack接口下面有HttpURLConnection和HttpClient方法的进一步封装;
5、通过用户设置的HTTP方式最后调用HttpURLConnection或者HttpClient,并得到网络的返回值;
6、返回值最终由NetworkDispatch去进行处理,如果用户没有设置缓存,则直接交给ResponseDelivery接口去处理,最后通过Response里面的接口回调给用户类去处理;如果用户设置了缓存,该请求和回复会被放入缓存队列,此时CacheDispatch线程检测到缓存队列有数据后会进行相应的缓存处理。
7、DiskBasedCache是Cache接口实现的一种方式,主要用于文件的缓存(下面我们会进行详细的介绍),当然用户也可以自己定义缓存的方式,则只需要实现Cache接口即可,DiskBasedCache线程处理完返回消息后,还是交给esponseDelivery接口去处理,最后通过Response里面的接口回调给用户类去处理。
四、Volley DiskBasedCache类
DiskBasedCache里面主要的两个方法是put和get方法。
/**
* 把缓存数据Entry写进磁盘里
*/
@Override
public synchronized void put(String key, Entry entry) {
//判断是否有足够的缓存空间来缓存新的数据
pruneIfNeeded(entry.data.length);
File file = getFileForKey(key);
try {
FileOutputStream fos = new FileOutputStream(file);
//用enry里面的数据,再封装成一个CacheHeader
CacheHeader e = new CacheHeader(key, entry);
//先写头部缓存信息
boolean success = e.writeHeader(fos);
if (!success) {
fos.close();
VolleyLog.d("Failed to write header for %s", file.getAbsolutePath());
throw new IOException();
}
//成功后再写缓存内容
fos.write(entry.data);
fos.close();
//把头部信息先暂时保存在一个容器里
putEntry(key, e);
return;
} catch (IOException e) {
}
boolean deleted = file.delete();
if (!deleted) {
VolleyLog.d("Could not clean up file %s", file.getAbsolutePath());
}
}每次调用put方法时,也就是写入缓存时,都先调用pruneIfNeeded()检查对象的大小,当缓冲区空间足够新对象的加入时就直接添加进来,否则会删除部分对象,一直到新对象添加进来后还会有10%的空间剩余时为止,文件引用以LinkHashMap保存。添加时,首先以URL为key,经过个文本转换后,以转换后的文本为名称,获取一个file对象。首先向这个对象写入缓存的头文件,然后是真正有用的网络返回数据。最后是当前内存占有量数值的更新,这里需要注意的是真实数据被写入磁盘文件后,在内存中维护的应用,存的只是数据的相关属性。
public synchronized Entry get(String key) {
CacheHeader entry = mEntries.get(key);
// 如果entry不为空,就直接返回
if (entry == null) {
return null;
}
File file = getFileForKey(key);
CountingInputStream cis = null;
try {
cis = new CountingInputStream(new FileInputStream(file));
CacheHeader.readHeader(cis); // eat header
byte[] data = streamToBytes(cis, (int) (file.length() - cis.bytesRead));
return entry.toCacheEntry(data);
} catch (IOException e) {
VolleyLog.d("%s: %s", file.getAbsolutePath(), e.toString());
remove(key);
return null;
} finally {
if (cis != null) {
try {
cis.close();
} catch (IOException ioe) {
return null;
}
}
}
}每次调用get方法时,先从文件里获得字节数输入流,从中减去头部文件的字节数,最后把真正内容的data[]数据拿到再组装成一个Cache.Entry返回。从上面的分析可见,cache在做一些基础判断时都会先用到缓存的头部数据,如果确定头部信息没问题了,再真正读写内容,原因是头部数据比较小,放在内存中也不占地方,但处理速度会快很多。而真正的数据内容,可能会比较大,处理的开销也大,只在真正需要的地方读写。
public ImageContainer get(String requestUrl, ImageListener imageListener,
int maxWidth, int maxHeight) {
//请求只能在主线程里,不然会报错
throwIfNotOnMainThread();
//用url和宽高组成key
final String cacheKey = getCacheKey(requestUrl, maxWidth, maxHeight);
//从内存缓存里获取数据
Bitmap cachedBitmap = mCache.getBitmap(cacheKey);
if (cachedBitmap != null) {
// 如果内存不为空,直接返回图片信息
ImageContainer container = new ImageContainer(cachedBitmap, requestUrl, null, null);
imageListener.onResponse(container, true);
return container;
}
...
// 如果为空,就正常请求网络数据,下面用的是ImageRequest取请求网络数据
Request<?> newRequest =
new ImageRequest(requestUrl, new Listener<Bitmap>() {
@Override
public void onResponse(Bitmap response) {
//请求成功后,在这个方法里,把图片放进内存缓存中
onGetImageSuccess(cacheKey, response);
}
}, maxWidth, maxHeight,
Config.RGB_565, new ErrorListener() {
@Override
public void onErrorResponse(VolleyError error) {
onGetImageError(cacheKey, error);
}
});
...
}
private void onGetImageSuccess(String cacheKey, Bitmap response) {
//把图片放进内存里
mCache.putBitmap(cacheKey, response);
...
}从上面的代码注释中已经能比较清晰的看出,每次调用ImageLoader.get()方法,会先从内存缓存里先看有没有数据,有就直接返回,没有就走正常的网络流程,先查看磁盘缓存,不存在或过期再去请求网络。图片比普通数据多一层缓存的原因也很简单,因为图片较大,读取和网络成本都大,能用缓存就用缓存,能省一点是一点。
五、HttpURLConnection和HttpClient
HttpClient:
DefaultHttpClient和它的兄弟AndroidHttpClient都是HttpClient具体的实现类,它们都拥有众多的API,而且实现比较稳定,bug数量也很少。
但同时也由于HttpClient的API数量过多,使得我们很难在不破坏兼容性的情况下对它进行升级和扩展,所以目前Android团队在提升和优化HttpClient方面的工作态度并不积极。
HttpURLConnection:
HttpURLConnection是一种多用途、轻量极的HTTP客户端,使用它来进行HTTP操作可以适用于大多数的应用程序。虽然HttpURLConnection的API提供的比较简单,但是同时这也使得我们可以更加容易地去使用和扩展它。
HTTP 协议可能是现在 Internet上使用得最多、最重要的协议了,越来越多的 Java应用程序需要直接通过 HTTP协议来访问网络资源。在 JDK的 java.net包中已经提供了访问 HTTP协议的基本功能:HttpURLConnection。
HttpURLConnection是java的标准类,HttpURLConnection继承自URLConnection,可用于向指定网站发送GET请求、POST请求。它在URLConnection的基础上提供了如下便捷的方法:
int getResponseCode():获取服务器的响应代码。
String getResponseMessage():获取服务器的响应消息。
String getResponseMethod():获取发送请求的方法。
void setRequestMethod(String method):设置发送请求的方法。
在一般情况下,如果只是需要Web站点的某个简单页面提交请求并获取服务器响应,HttpURLConnection完全可以胜任。但在绝大部分情况下,Web站点的网页可能没这么简单,这些页面并不是通过一个简单的URL就可访问的,可能需要用户登录而且具有相应的权限才可访问该页面。在这种情况下,就需要涉及Session、Cookie的处理了,如果打算使用HttpURLConnection来处理这些细节,当然也是可能实现的,只是处理起来难度就大了。
为了更好地处理向Web站点请求,包括处理Session、Cookie等细节问题,Apache开源组织提供了一个HttpClient项目,看它的名称就知道,它是一个简单的HTTP客户端(并不是浏览器),可以用于发送HTTP请求,接收HTTP响应。但不会缓存服务器的响应,不能执行HTML页面中嵌入的Javascript代码;也不会对页面内容进行任何解析、处理。
简单来说,HttpClient就是一个增强版的HttpURLConnection,HttpURLConnection可以做的事情HttpClient全部可以做;HttpURLConnection没有提供的有些功能,HttpClient也提供了,但它只是关注于如何发送请求、接收响应,以及管理HTTP连接。















 9079
9079

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









