







机器学习笔记1:基于Logistic回归进行数据预测
一、背景
近期项目的一个核心部分就是实现对数据的预测,因为没有实际的数据样本,所以我准备近期学习Machine Learning的几种方式,从简单的线性非线性回归到TensorFlow及其他几种深度学习的方式,搭建相关的数据预测核心部分,并且完成各个系统的测试。等到实际数据获取后,进行系统测试与比对,选择最适合数据预测的类型。
因为Machine Learning涉及到很多数学相关的知识,因此在基础知识方面,我看的是Coursera中的斯坦福大学的Machine Learning的网课。在实际操作的过程中参考Peter Harrington的《机器学习实战》一书,但是本书在深度学习方面没有相关的章节,因此我会从CSDN中找到合适的学习资源进行学习与更新。
二、基础知识
1.logistic回归介绍
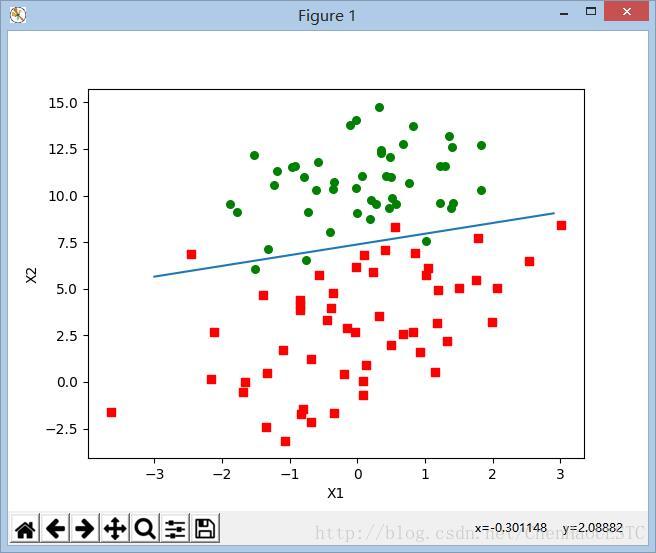
Logistic回归也就是逻辑回归,在下面的这个例子中,就是找到一条拟合的直线,将两类数据分开,下面的例子就是采用二维的数据,用一条直线将绿点和红点分开。
2.Logistic公式原理
关于这条直线,我们可以用下面的公式来表现:

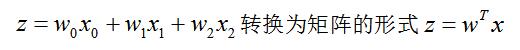
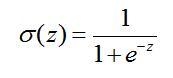
3.算法步骤
(1)算法的第一步就是实现数据的初始化,将二维的数据转换为三维的数据,上面提到便于计算将x0设置为1,因此可以人为的将其转换为三维数组。
(2)首先对参量w进行初始化为n行1列的单元数组。
(3)根据实际情况通过梯度下降方式,取得直线上拟合值与真实值之差的最小值,通过多次迭代的方式来求出最优的w值。
(4)经过迭代后获得w值,做出拟合直线,用X2表示纵坐标,作出直线,观察效果。
4.梯度算法

5.梯度下降算法应用
关于参数w的迭代方程的推导过程如下:
(1)在测试的过程中,在构建误差函数的时候,采用最小二乘法,用分类误差评估分类的效果。其中label就是数据集的第三列数据,将x与m的乘积采用sigmoid函数处理。
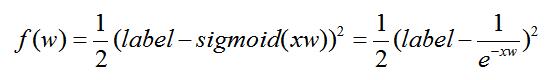
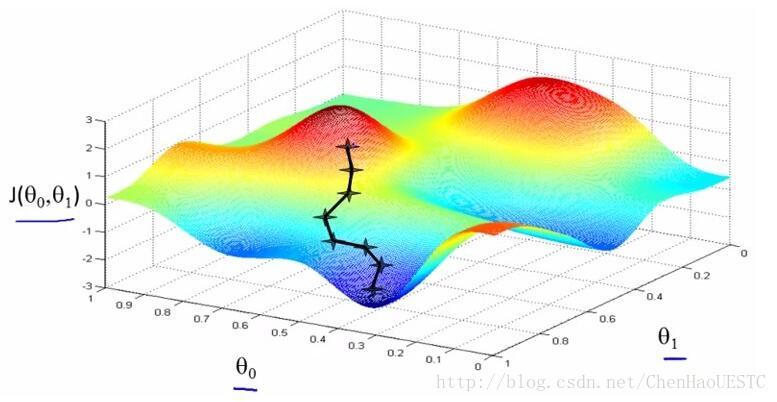
(2)想要w值达到达到最小值,可以参考Coursera里面的课程内容,如图所示,如何到达最小值的点,需要一步步来进行迭代更新,在每一步求导,找到该点能够得到最小值的方向。所以算法的第二步就是进行求导运算。
求导过程如下:

6.处理数据中的缺失值
(1)使用可用特征的均值来填补缺失值;
(2)使用特殊值来填补缺失值,如-1;
(3)忽略有缺失的样本;
(4)使用相似样本的均值填补缺失值;
(5)使用另外的机器学习的算法预测缺失值。
三、代码部分
这个部分会尽量对整个项目的每个函数给出解释,同时书中的source code关于梯度上升的算法,给出了一种基本算法以及两种改进方式,会在下面部分有所解释。完整的代码段及数据可以在第四部分中下载得到。
(1)导入数据
def loadDataset():
dataSet = [] # 数据集
labels = [] # 标签
fr = open("testSet.txt")
for line in fr.readlines():
lineVec = line.strip().split() # 读取每一行,[x1,x2,label]
# [x0,x1,x2],其中x0表示常数项
dataSet.append([1.0, float(lineVec[0]), float(lineVec[1])])
labels.append(float(lineVec[2])) # 添 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 7762
7762











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









