








1、逻辑回归
从名字来理解逻辑回归.在逻辑回归中,逻辑一词是logistics [lə’dʒɪstɪks]的音译字,并不是因为这个算法是突出逻辑的特性.
样本x是有n维的,每一维代表样本的一个特征,每一特征在判断x属于哪一类时所占的权重不一样,所以首先需要对x的各个维度(即特征向量的每一维)加权值w(这里的w未知,逻辑回归的目的就是求出这个w权重向量,表示对特征向量每一维所占的权重)算出一个作为判断分类的一个分数s,s的计算方式如下
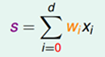
逻辑函数将分数转换为类别
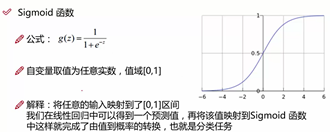
然后有了分数s,就需要利用一个逻辑函数将s转换为0到1的值,0,1也就是分类的结果,0代表负类,1代表正类 ,从而引出了sigmoid函数
逻辑回归中在这一步与其他不同的是它含增加了一个sigmod函数,将分数转换到0到1之间的一个值,得到这个0到1之间的值θ(s),再将其与一个阈值做比较,一般是0.5,大于阈值的为正类1,小于阈值的为负类0
最终得到分类模型与样本特征向量的关系公式如下
得到分类模型(函数)之后,如果想知道某一样本的分类结果,常见的场景应用是将这个样本的特征向量作为x输入到这个函数,得到一个y值,将y值与阈值做比较,大于阈值的为正,小于阈值的为负。
sigmod函数预测结果为一个0到1之间的小数,选定阈值的第一反应,大多都是选0.5,其实实际工作中并不一定是0.5,阈值的设定往往是根据实际情况来判断的
比如做一个肿瘤的良性恶性判断.选定阈值为0.5就意味着,如果一个患者得恶性肿瘤的概率为0.49,模型依旧认为他没有患恶性肿瘤,结果就是造成了严重的医疗事故.此类情况我们应该将阈值设置的小一些.阈值设置的小,加入0.3,一个人患恶性肿瘤的概率超过0.3我们的算法就会报警,造成的结果就是这个人做一个全面检查,比起医疗事故来讲,显然这个更容易接受.
2、数学推导
已经得到每个单条样本预测对的概率公式:
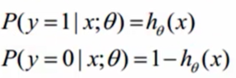
整合:
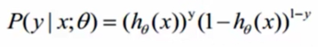
若想让预测出的结果全部正确的概率最大,根据最大似然估计,就是所有样本预测正确的概率相乘得到的P(总体正确)最大,数学表达形式如下:

上述公式最大时公式中W的值就是我们要的最好的W.下面对公式进行求解.
通过两边同取log的形式,并将yi提出来,让其变成连加.

得到的似然函数越大,证明我们得到的W就越好.因为在函数最优化的时候习惯让一个函数越小越好,所以我们在前边加一个负号.得到公式如下:
梯度上升法转为下降法求解:
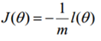
这个函数就是我们逻辑回归(logistics regression)的损失函数,我们叫它交叉熵损失函数.
3、求解交叉熵损失函数

(θTx)′,对第j个θ求偏导,结果即Xj(j表示样本中第几项)
sigmoid的求导:
https://www.cnblogs.com/zhongmiaozhimen/p/6155093.html

θ更新过程可以写成:
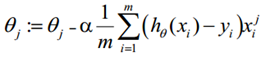
4、question
逻辑回归为什么对切斜的数据特别敏感(正负例数据比例相差悬殊时预测效果不好)
首先从文章开头部分举例的两个图可以看到,使用线性模型进行分类第一个要面对的问题就是如何降低离群值的影响,而第二大问题就是,在正负例数据比例相差悬殊时预测效果不好.为什么会出现这种情况呢?原因来自于逻辑回归交叉熵损失函数是通过最大似然估计来推导出的.
使用最大似然估计来推导损失函数,那无疑,我们得到的结果就是所有样本被预测正确的最大概率.注意重点是我们得到的结果是预测正确率最大的结果,100个样本预测正确90个和预测正确91个的两组w,我们会选正确91个的这一组.那么,当我们的业务场景是来预测垃圾邮件,预测黄色图片时,我们数据中99%的都是负例(不是垃圾邮件不是黄色图片),如果有两组w,第一组为所有的负例都预测正确,而正利预测错误,正确率为99%,第二组是正利预测正确了,但是负例只预测出了97个,正确率为98%.此时我们算法会认为第一组w是比较好的.但实际我们业务需要的是第二组,因为正例检测结果才是业务的根本.
此时我们需要对数据进行欠采样/重采样来让正负例保持一个差不多的平衡,或者使用树型算法来做分类.一般树型分类的算法对数据倾斜并不是很敏感,但我们在使用的时候还是要对数据进行欠采样/重采样来观察结果是不是有变好.
参考原文:https://blog.csdn.net/weixin_39445556/article/details/83930186














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









