









目标检测
目标检测算是计算机视觉中应用最为广泛的一个方向。
目标检测和图片分类的区别
图片分类:
- 在图像分类任务中,假设图像中只有一个主要物体对象,目标是识别出这个主要物体对象的类别(其他东西相对来说就不那么重要了)
目标检测:
- 在目标检测任务中,一张图像里往往不只一个感兴趣的物体对象,目标不仅仅是识别图像中所有感兴趣的物体(找出所有感兴趣的物体),还要找出它们在图像中所在的具体位置(通过方框来表示)
目标检测相对于图片分类来讲所做的工作更多,它需要找出所有感兴趣的物体,当图片中只有一个物体时,可以将目标检测看成是图像分类,把图像中最主要的物体当作是图片的类别,但是当图片中有多个物体的时候,目标检测不仅能将所有的物体都检测出来,还能将他们所在的位置标注出来,所以目标检测的应用场景相对来讲更多
目标检测常见应用
- 无人驾驶
- 无人售货
边缘框
- 一个边缘框可以通过4个数字定义
- (左上x,左上y,右下x,右下y)
- (左上x,左上y,宽,高)
- 其标注的正方向与我们不太相同
- 对于 x 轴来说,向右为 x 轴的正方向,即 x 的值从左到右依次增大
- 对于 y 轴来说,向下为 y 轴的正方向,y 的值从上到下依次增大

总结
- 物体检测识别图片里的多个物体的类别和位置
- 位置通常用边缘框表示
单张图片锚框代码
%matplotlib inline
import torch
from matplotlib import pyplot as plt
img = plt.imread('../img/catdog.jpg')
plt.imshow(img);

定义在这两种表示法之间进行转换的函数
def box_corner_to_center(boxes):
"""从(左上,右下)转换到(中间,宽度,高度)"""
x1, y1, x2, y2 = boxes[:, 0], boxes[:, 1], boxes[:, 2], boxes[:, 3]
cx = (x1 + x2) / 2
cy = (y1 + y2) / 2
w = x2 - x1
h = y2 - y1
boxes = torch.stack((cx, cy, w, h), axis=-1)
return boxes
def box_center_to_corner(boxes):
"""从(中间,宽度,高度)转换到(左上,右下)"""
cx, cy, w, h = boxes[:, 0], boxes[:, 1], boxes[:, 2], boxes[:, 3]
x1 = cx - 0.5 * w
y1 = cy - 0.5 * h
x2 = cx + 0.5 * w
y2 = cy + 0.5 * h
boxes = torch.stack((x1, y1, x2, y2), axis=-1)
return boxes
定义图像中狗和猫的边界框
dog_bbox, cat_bbox = [60.0, 45.0, 378.0, 516.0], [400.0, 112.0, 655.0, 493.0]
boxes = torch.tensor((dog_bbox, cat_bbox))
box_center_to_corner(box_corner_to_center(boxes)) == boxes
tensor([[True, True, True, True],
[True, True, True, True]])
将边界框在图中画出
def bbox_to_rect(bbox, color):
return plt.Rectangle(
xy=(bbox[0], bbox[1]), width=bbox[2]-bbox[0], height=bbox[3]-bbox[1],
fill=False, edgecolor=color, linewidth=2)
fig = plt.imshow(img)
fig.axes.add_patch(bbox_to_rect(dog_bbox, 'blue'))
fig.axes.add_patch(bbox_to_rect(cat_bbox, 'red'));

目标检测数据集
- 目标检测领域没有像MNIST和Fashion-MNIST那样的小数据集
- 目标检测的数据集通常来说比图片分类的数据集小很多,因为标注的成本很高
- 对于图片分类来说,最简单的就是给定一个CSV文件(图片与标号一一对应)或者是给定一个文件夹(每个类对应一个子文件夹,对应标号的图片放在子文件夹下)
- 对于目标检测来说就不能简单的用文件夹的形式,因为一张图片中可能存在多个类,所以就不能放在子文件夹中,所以通常来说目标检测的数据集的标号需要额外存储
- 假设使用文本文件存储的话,每一行表示一个物体,每一行分别由图片文件名(因为一张图片中可能有多个物体,所以同一个文件名可能会出现多次)、物体类别(标号)、边缘框(图片中物体的位置)组成。
CoCo数据集
- 目标检测中比较常见的数据集,类似于Imagenet在图片分类中的地位
- 访问地址:CoCo数据集
- COCO数据集中有 80 个类别,330k 图片,1.5M 物体(每张图片中有多个物体)
数据集的读取
-
读取小批量的时候,图像的小批量的形状为(批量大小、通道数、高度、宽度),与图像分类任务中的相同
-
标签的小批量的形状为(批量大小,m,5)
- m:数据集的任何图像中边界框可能出现的最大数量
- 5:每个边界框的标签将被长度为 5 的数组表示:数组的第一个元素是边界框中对象的类别,其中 -1 表示用于填充的非法边界框;数组的其余 4 个元素是边界框左上角和右下角(x,y)坐标值
-
小批量计算虽然高效,但是要求每张图像含有相同数量的边界框,以便放在同一个批量中
-
通常图像可能拥有不同数量个边界框,所以,在达到 m 之前,边界框少于 m 的图像将被非法边界框填充
示例代码
目标检测数据集
- 这里用的是沐神自己标注的一个小数据集,标注香蕉
%matplotlib inline
import os
import pandas as pd
import torch
import torchvision
from d2l import torch as d2l
d2l.DATA_HUB['banana-detection'] = (
d2l.DATA_URL + 'banana-detection.zip',
'5de26c8fce5ccdea9f91267273464dc968d20d72')
读取香蕉检测数据集
def read_data_bananas(is_train=True):
"""读取香蕉检测数据集中的图像和标签"""
data_dir = d2l.download_extract('banana-detection')
csv_fname = os.path.join(data_dir, 'bananas_train' if is_train
else 'bananas_val', 'label.csv')
csv_data = pd.read_csv(csv_fname)
csv_data = csv_data.set_index('img_name')
images, targets = [], []
for img_name, target in csv_data.iterrows():
images.append(torchvision.io.read_image(
os.path.join(data_dir, 'bananas_train' if is_train else
'bananas_val', 'images', f'{img_name}')))
targets.append(list(target))
return images, torch.tensor(targets).unsqueeze(1) / 256
# 这里包括下面会除以256是为了方便我们可视化
创建一个自定义Dataset实例
class BananasDataset(torch.utils.data.Dataset):
"""一个用于加载香蕉检测数据集的自定义数据集"""
def __init__(self, is_train):
self.features, self.labels = read_data_bananas(is_train)
print('read ' + str(len(self.features)) + (f' training examples' if
is_train else f' validation examples'))
def __getitem__(self, idx):
return (self.features[idx].float(), self.labels[idx])
def __len__(self):
return len(self.features)
为训练集和测试集返回两个数据加载器实例
def load_data_bananas(batch_size):
"""加载香蕉检测数据集"""
train_iter = torch.utils.data.DataLoader(BananasDataset(is_train=True),
batch_size, shuffle=True)
val_iter = torch.utils.data.DataLoader(BananasDataset(is_train=False),
batch_size)
return train_iter, val_iter
读取一个小批量,并打印其中的图像和标签的形状
batch_size, edge_size = 32, 256
train_iter, _ = load_data_bananas(batch_size)
batch = next(iter(train_iter))
batch[0].shape, batch[1].shape
Downloading ..\data\banana-detection.zip from http://d2l-data.s3-accelerate.amazonaws.com/banana-detection.zip...
read 1000 training examples
read 100 validation examples
(torch.Size([32, 3, 256, 256]), torch.Size([32, 1, 5]))
演示
imgs = (batch[0][0:10].permute(0, 2, 3, 1)) / 256
axes = d2l.show_images(imgs, 2, 5, scale=2)
for ax, label in zip(axes, batch[1][0:10]):
d2l.show_bboxes(ax, [label[0][1:5] * edge_size], colors=['b'])

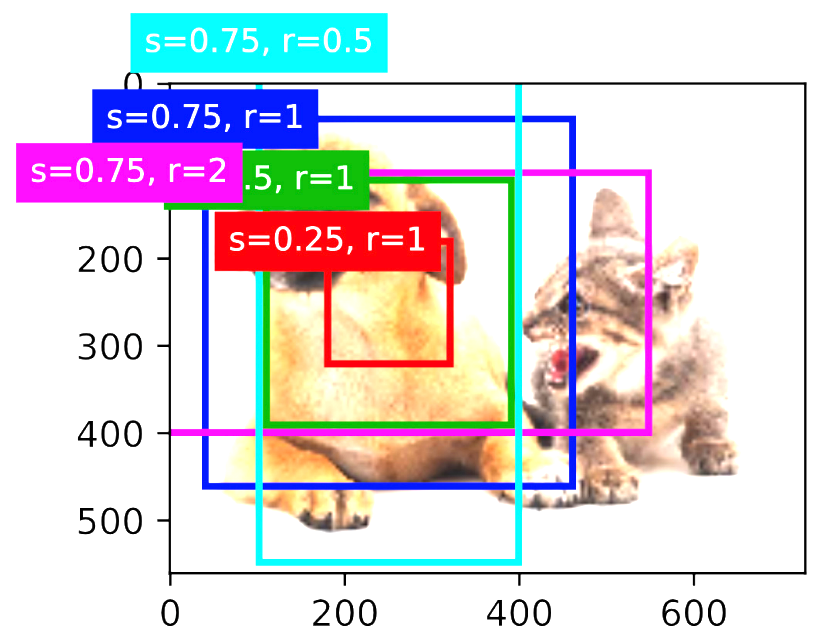
锚框
- 目标检测算法中,通常会在输入图像中采样大量的区域,然后判断这些区域中是否包含所感兴趣的目标,并调整区域边界从而更加准确地预测目标的真实边界框(ground-truth bounding box)
基于锚框的目标检测算法
- 也有不基于锚框的目标检测算法,但是基于锚框的目标检测算法占主流
- 提出多个被称为锚框的区域(边缘框)(这一步是猜测)
- 预测每个锚框里是否含有关注的物体
- 如果是,预测从这个锚框到真实边缘框的偏移
IoU-交并比
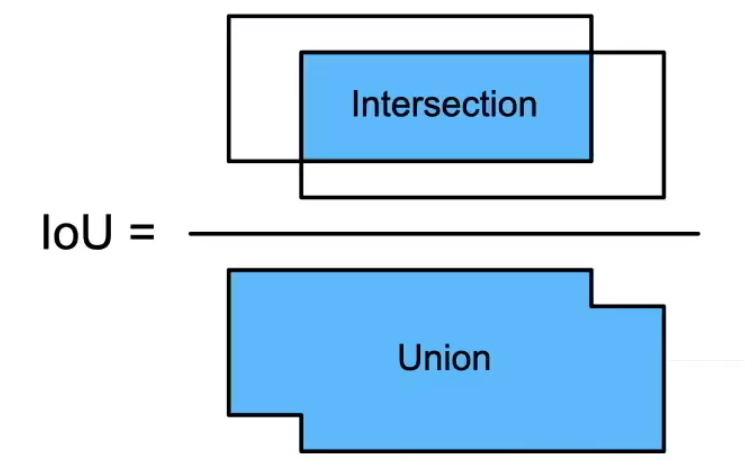
- IoU用来计算两个框之间的相
似度- 0表示无重叠,1表示重合
- 这是Jacquard指数的一个特殊情况
- 给定两个集合A和B
J ( A , B ) = ∣ A ∩ B ∣ ∣ A ∪ B ∣ J(A,B)=\frac{|A\cap B|}{|A\cup B|} J(A,B)=∣A∪B∣∣A∩B∣
- 给定两个集合A和B
赋予锚框标号
- 每个锚框是一个训练样本
- 将每个锚框,要么标注成背景,要么关联上一个真实边缘框
- 我们可能会生成大量的锚框
- 这个导致大量的负类样本(大部分锚框都跟实际物体没有关联)
标号步骤

- 上方的表格表示一个矩阵
- 其中4列代表实际4个物体的边缘框
- 9行代表我们生成了9个锚框
- 每一个相交的点代表锚框与边缘框的IoU值
- 假设
x
23
x_{23}
x23是矩阵中最大的值,那么我们将边缘框3给锚框2
- 即让锚框2去预测边缘框3
- 删掉第2行以及第3列,即下一次不去考虑对应的值
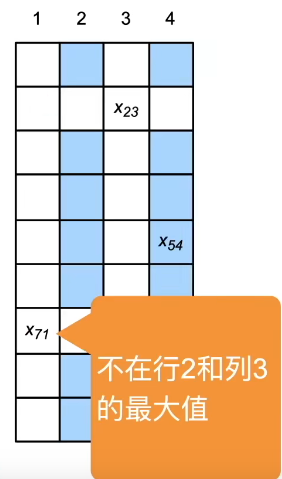
- 假设 x 71 x_{71} x71是不在第2行和第3列最大的值
- 那么我们将边缘框1赋予锚框7
- 同时删掉对应的行列
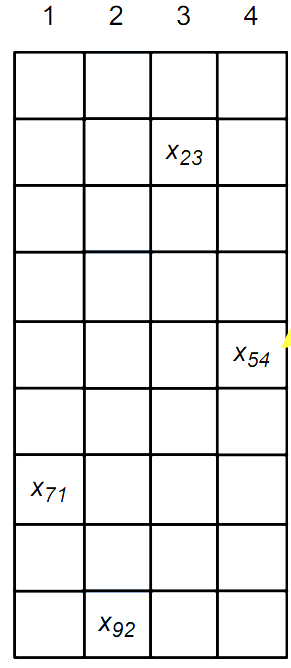
- 重复上述步骤,将所有的边缘框与锚框关联起来
- 剩下的锚框有多种不同的处理方法
- 将剩下的锚框全看作负例样本(会导致负样本太多)
- 跟哪个锚框的IoU值最大就标号为哪个边缘框
至于赋予锚框标号的算法还有很多种,这是较为常用的一种,具体的模型、数据不同可能会有不同的方法,要具体分析。
使用非极大抑制(NMS)输出
-
目前为止的目标检测中可能出现的问题是你的算法可能对同一个对象做出多次检测。非极大值抑制(non-max suppression)这个方法可以确保你的算法对每个对象只检测一次
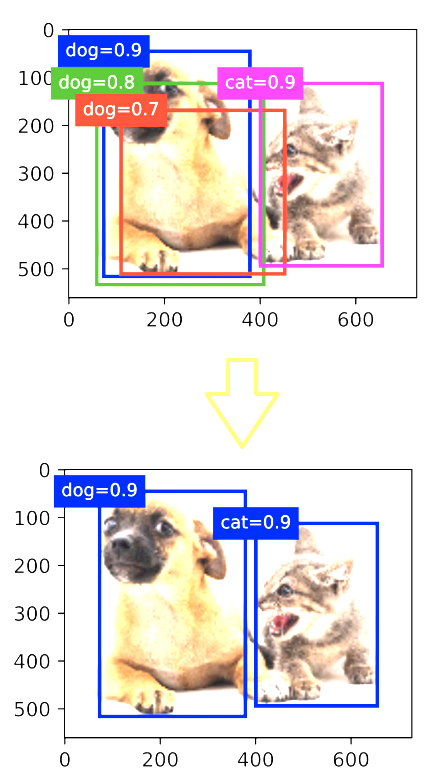
-
每个锚框预测一个边缘框
-
NMS可以合并相似的预测
- 选中是非背景类的最大预测值(对类的预测的softmax值,越接近于1置信度越高)
- 去掉所有其它和它IoU值大于 θ \theta θ的预测
- 重复上述过程直到所有预测要么被选中,要么被去掉
















 2046
2046











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











