







一、什么是聚类分析?
在Jupyter Notebook中进行聚类分析是一种常见的数据分析任务。聚类分析是一种无监督学习方法,用于将数据集划分为多个组或簇,使得同一簇中的数据点彼此相似,而不同簇中的数据点则不相似。以下是一个使用Python和Jupyter Notebook进行聚类分析的示例,主要使用流行的数据科学库,如Pandas、Scikit-learn和Matplotlib。
二、聚类示例
利用不同小麦种子的特征数据进行聚类,聚类算法要求实现KMeans、Birch、DBSCAN。
安装必要的库
如果你还没有安装这些库,可以使用以下命令来安装:
pip install pandas scikit-learn matplotlib seaborn
导入库并加载数据
首先,我们需要导入必要的库并加载数据集。
 KMeans聚类结果可视化
KMeans聚类结果可视化 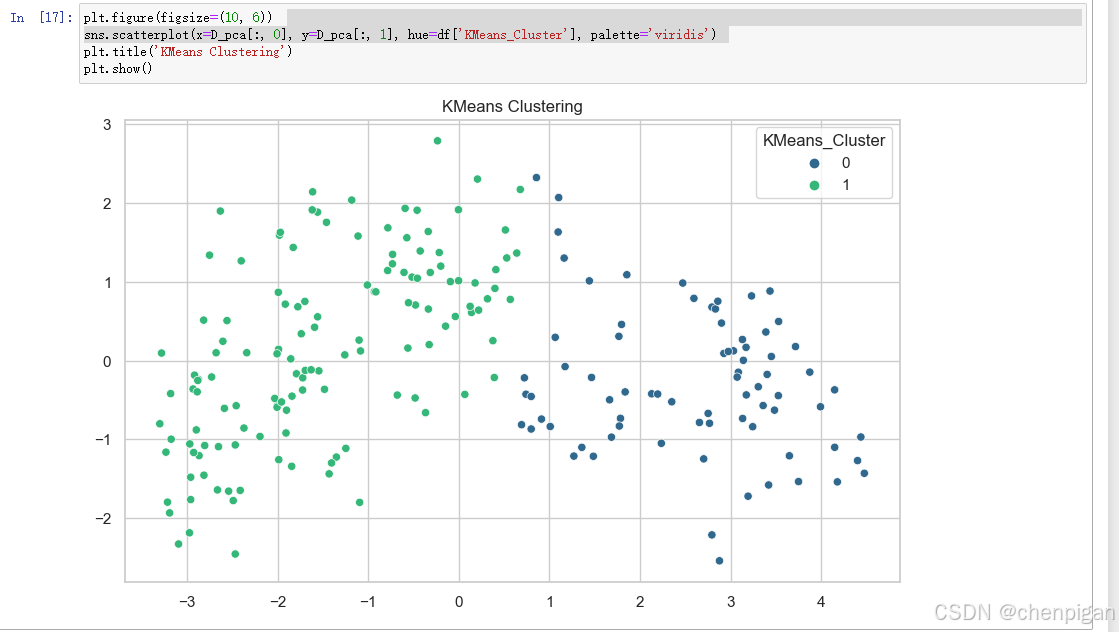 Birch聚类结果可视化
Birch聚类结果可视化 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









