






基于PaddlePaddle和PaddleHub的口罩检测系统的落地实现
一、项目意义
2020春节,新型冠状病毒肆虐华夏大地,中华儿女举国防止疫情扩散蔓延,为防止疫情扩散,做好个人防护是每个公民的义务,特别是公共场合,火车站、飞机场和汽车站,人流量大的密集地区,做好人员口罩监控相当有必要。
二、项目目标
实现视频实时监测,并且做出简易GUI,打包出EXE文件,达到可以实用的目的
除此之外,做出具有照片检测功能的APP和服务器版,为后续优化提升打下基础
三、模型简介
1.pyramidbox_lite_mobile_mask
PyramidBox-Lite是基于2018年百度发表于计算机视觉顶级会议ECCV 2018的论文PyramidBox而研发的轻量级模型,模型基于主干网络FaceBoxes,对于光照、口罩遮挡、表情变化、尺度变化等常见问题具有很强的鲁棒性。该PaddleHub Module是针对于移动端优化过的模型,适合部署于移动端或者边缘检测等算力受限的设备上,并基于WIDER FACE数据集和百度自采人脸数据集进行训练,支持预测,可用于检测人脸是否佩戴口罩。
2.pyramidbox_lite_server_mask
PyramidBox-Lite是基于2018年百度发表于计算机视觉顶级会议ECCV 2018的论文PyramidBox而研发的轻量级模型,模型基于主干网络FaceBoxes,对于光照、口罩遮挡、表情变化、尺度变化等常见问题具有很强的鲁棒性。该PaddleHub Module基于WIDER FACE数据集和百度自采人脸数据集进行训练,支持预测,可用于检测人脸是否佩戴口罩。
3.模型效果展示

4. YOLO
APP使用了YOLO3模型
四、原理简介
本次重在实现该项目,对原理仅作简要介绍
1.PyramidBox
PyramidBox使用了与 S3FD完全相同的主干网络,包括基础卷积层和额外卷积层。基础卷积层即为 VGG16 中的 conv1_1 层到 pool5 层,额外卷积层将 VGG16 中的 fc6 层和 fc7 层转换为 conv_fc 层,又添加了更多的卷积层使网络变得更深。
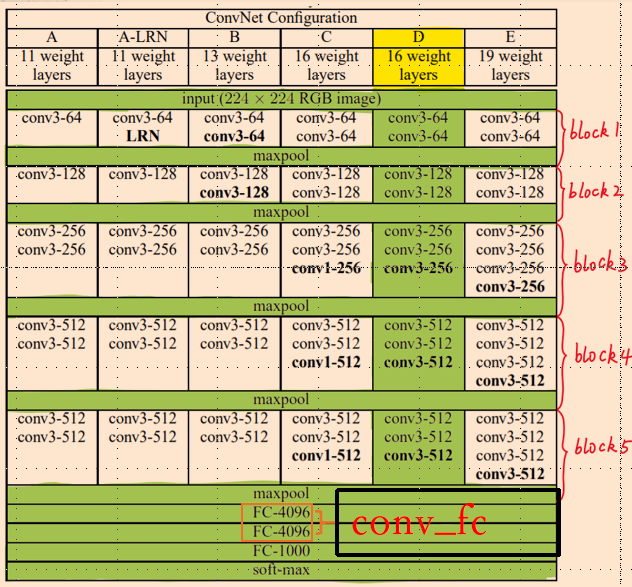
创新点:
-
提出了一种基于anchor的上下文辅助方法,称为pyramid anchors,用于监督学习小、模糊和部分遮挡人脸的上下文特征的监督信息
-
设计了低层特征金字塔网络(LFPN)来更好地融合文本特征和面部特征。同时,该方法可以在一次拍摄中很好地处理不同尺度的人脸
-
设计一个上下文敏感的预测模块,由混合网络结构和max-in-out层组成,从合并的特征中了解精确的位置和分类
-
提出了基于尺度感知的 Data-anchor-sampling,以改变训练样本的分布,将重点放在较小的人脸上
2. yolo3
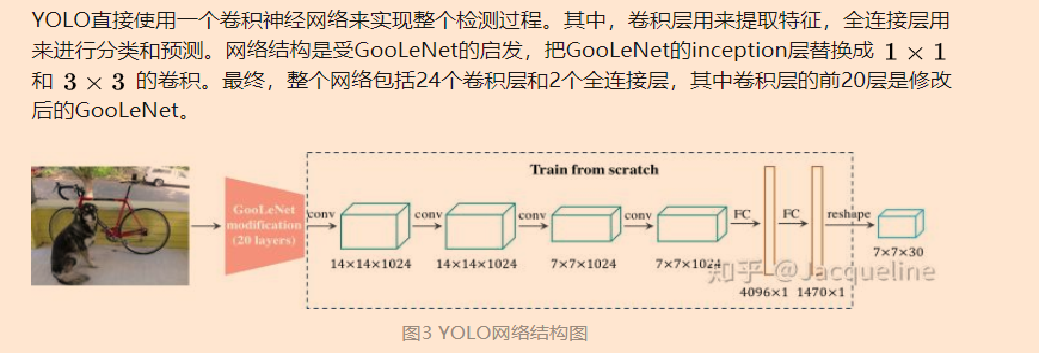
优点:
-
YOLO的结构非常简单,直接使用一个卷积神经网络就可以同时预测bounding box的位置和类别。
-
YOLO速度非常快,所以YOLO也可以实现视频的实时检测。
-
YOLO直接使用整幅图来进行检测,所以可以减少将背景检测为物体的错误。
五、项目实现
I.视频实时监控
1. 视频实时监控的实现
# -*- coding:utf-8 -*-
import paddlehub as hub
import cv2
from PIL import Image, ImageDraw, ImageFont
import numpy as np
import json
import os
module = hub.Module(name="pyramidbox_lite_server_mask", version='1.1.0')
# opencv输出中文
def paint_chinese(im, chinese, position, fontsize, color_bgr):
# 图像从OpenCV格式转换成PIL格式
img_PIL = Image.fromarray(cv2.cvtColor(im, cv2.COLOR_BGR2RGB))
font = ImageFont.truetype(
'SourceHanSansSC-Medium.otf', fontsize, encoding="utf-8")
#color = (255,0,0) # 字体颜色
#position = (100,100)# 文字输出位置
color = color_bgr[::-1]
draw = ImageDraw.Draw(img_PIL)
# PIL图片上打印汉字 # 参数1:打印坐标,参数2:文本,参数3:字体颜色,参数4:字体
draw.text(position, chinese, font=font, fill=color)
img = cv2.cvtColor(np.asarray(img_PIL), cv2.COLOR_RGB2BGR) # PIL图片转cv2 图片
return img
result_path = './result'
if not os.path.exists(result_path):
os.mkdir(result_path)
name = "./result/1-mask_detection.mp4"
width = 1280
height = 720
fps = 30
fourcc = cv2.VideoWriter_fourcc(*'vp90')
writer = cv2.VideoWriter(name, fourcc, fps, (width, height))
maskIndex = 0
index = 0
data = []
capture = cv2.VideoCapture(0) # 打开摄像头
#capture = cv2.VideoCapture('./test_video.mp4') # 打开视频文件
while True:
frameData = {}
ret, frame = capture.read() # frame即视频的一帧数据
if ret == False:
break
frame_copy = frame.copy()
input_dict = {"data": [frame]}
results = module.face_detection(data=input_dict)
maskFrameDatas = []
for result in results:
label = result['data']['label']
confidence_origin = result['data']['confidence']
confidence = round(confidence_origin, 2)
confidence_desc = str(confidence)
top, right, bottom, left = int(result['data']['top']), int(
result['data']['right']), int(result['data']['bottom']), int(
result['data']['left'])
#将当前帧保存为图片
img_name = "avatar_%d.png" % (maskIndex)
path = "./result/" + img_name
image = frame[top - 10:bottom + 10, left - 10:right + 10]
cv2.imwrite(path, image, [int(cv2.IMWRITE_PNG_COMPRESSION), 9])
maskFrameData = {}
maskFrameData['top'] = top
maskFrameData['right'] = right
maskFrameData['bottom'] = bottom
maskFrameData['left'] = left
maskFrameData['confidence'] = float(confidence_origin)
maskFrameData['label'] = label
maskFrameData['img'] = img_name
maskFrameDatas.append(maskFrameData)
maskIndex += 1
color = (0, 255, 0)
label_cn = "有口罩"
if label == 'NO MASK':
color = (0, 0, 255)
label_cn = "无口罩"
cv2.rectangle(frame_copy, (left, top), (right, bottom), color, 3)
cv2.putText(frame_copy, label, (left, top - 10),
cv2.FONT_HERSHEY_SIMPLEX, 0.8, color, 2)
#origin_point = (left, top - 36)
#frame_copy = paint_chinese(frame_copy, label_cn, origin_point, 24,
# color)
writer.write(frame_copy)
cv2.imshow('Mask Detection', frame_copy)
frameData['frame'] = index
# frameData['seconds'] = int(index/fps)
frameData['data'] = maskFrameDatas
data.append(frameData)
print(json.dumps(frameData))
index += 1
if cv2.waitKey(1) & 0xFF == ord('q'):
break
with open("./result/2-mask_detection.json", "w") as f:
json.dump(data, f)
writer.release()
cv2.destroyAllWindows()
2. 简易GUI的实现
首先选择了wxPython,并利用其提供的软件wxFormBuilder尝试制作GUI,但是网上对wxFormBuilder的介绍极少,最终只实现了部分功能:开启与结束。
使用该软件的作用也仅是获取GUI的代码
其对应代码如下
# -*- coding: utf-8 -*-
import wx
import wx.xrc
class MyFrame1 ( wx.Frame ):
def __init__( self, parent ):
wx.Frame.__init__ ( self, parent, id = wx.ID_ANY, title = u"gui", pos = wx.DefaultPosition, size = wx.Size( 552,121 ), style = wx.DEFAULT_FRAME_STYLE|wx.TAB_TRAVERSAL )
self.SetSizeHintsSz( wx.DefaultSize, wx.DefaultSize )
self.SetForegroundColour( wx.SystemSettings.GetColour( wx.SYS_COLOUR_ACTIVECAPTION ) )
self.SetBackgroundColour( wx.SystemSettings.GetColour( wx.SYS_COLOUR_ACTIVECAPTION ) )
gSizer1 = wx.GridSizer( 0, 2, 0, 0 )
self.m_button3 = wx.Button( self, wx.ID_ANY, u"开始", wx.DefaultPosition, wx.DefaultSize, 0 )
self.m_button3.SetForegroundColour( wx.SystemSettings.GetColour( wx.SYS_COLOUR_INFOTEXT ) )
self.m_button3.SetBackgroundColour( wx.SystemSettings.GetColour( wx.SYS_COLOUR_SCROLLBAR ) )
gSizer1.Add( self.m_button3, 0, wx.ALL|wx.ALIGN_CENTER_HORIZONTAL|wx.ALIGN_CENTER_VERTICAL, 5 )
self.m_button4 = wx.Button( self, wx.ID_ANY, u"终止", wx.DefaultPosition, wx.DefaultSize, 0 )
self.m_button4.SetForegroundColour( wx.SystemSettings.GetColour( wx.SYS_COLOUR_WINDOWTEXT ) )
self.m_button4.SetBackgroundColour( wx.SystemSettings.GetColour( wx.SYS_COLOUR_SCROLLBAR ) )
gSizer1.Add( self.m_button4, 0, wx.ALL|wx.ALIGN_CENTER_HORIZONTAL|wx.ALIGN_CENTER_VERTICAL, 5 )
self.SetSizer( gSizer1 )
self.Layout()
self.Centre( wx.BOTH )
# Connect Events
self.Bind( wx.EVT_CLOSE, self.MyFrame1OnClose )
self.m_button3.Bind( wx.EVT_BUTTON, self.m_button3OnButtonClick )
self.m_button4.Bind( wx.EVT_BUTTON, self.m_button4OnButtonClick )
def __del__( self ):
pass
# Virtual event handlers, overide them in your derived class
def MyFrame1OnClose( self, event ):
event.Skip()
def m_button3OnButtonClick( self, event ):
event.Skip()
def m_button4OnButtonClick( self, event ):
event.Skip()
紧接着又使用了Tkinter库实现其余部分可视化
注意:在Python2.x中,引入Tkinter库时T要大写,在Python3.x中,引入该库t要小写,而这在后面也成为了bug之一,很坑
此时实现的功能为选择摄像头与开启检测
对应代码
import tkinter as tk
from tkinter import ttk
import tkinter.messagebox
win = tk.Tk()
win.title("口罩佩戴视频监测系统") # 添加标题
ttk.Label(win, text="选择摄像头(默认为0)").grid(column=0, row=0) # 添加一个标签,并将其列设置为1,行设置为0
# button被点击之后会被执行
def begin(): # 当acction被点击时,该函数则生效
pass
def callbackClose():
tkinter.messagebox.showwarning(title='警告', message='点击了关闭按钮')
sys.exit(0)
# 按钮
win.protocol("WM_DELETE_WINDOW", callbackClose)
action1 = ttk.Button(win, text="开始", command=begin) # 创建一个按钮, text:显示按钮上面显示的文字, command:当这个按钮被点击之后会调用command函数
action1.grid(column=2, row=1) # 设置其在界面中出现的位置 column代表列 row 代表行
# 创建一个下拉列表
number = tk.StringVar()
numberChosen = ttk.Combobox(win, width=12, textvariable=number)
numberChosen['values'] = (0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10) # 设置下拉列表的值
numberChosen.grid(column=0, row=1) # 设置其在界面中出现的位置 column代表列 row 代表行
numberChosen.current(0) # 设置下拉列表默认显示的值,0为 numberChosen['values'] 的下标值
win.mainloop() # 当调用mainloop()时,窗口才会显示出来
3. 完整代码
信息输出部分仅注释掉,与源代码做对比,故略显杂乱
备 注 : 该 项 目 由 于 存 在 G U I 部 分 无 法 直 接 在 A i s t u d i o 上 运 行 , 需 要 f o r k 后 进 入 下 载 p y 文 件 到 本 地 后 才 能 运 行 \color{red}备注:该项目由于存在GUI部分无法直接在Aistudio上运行,需要fork后进入下载py文件到本地后才能运行 备注:该项目由于存在GUI部分无法直接在Aistudio上运行,需要fork后进入下载py文件到本地后才能运行
# -*- coding: utf-8 -*-
#
import os
os.environ['HUB_HOME'] = "./modules"
import sys
import tkinter as tk
from tkinter import ttk
import tkinter.messagebox
import paddlehub as hub
import cv2
from PIL import Image, ImageDraw, ImageFont
import numpy as np
import wx
import wx.xrc
import warnings
warnings.filterwarnings("ignore")
class MyFrame1(wx.Frame):
def __init__(self, parent):
wx.Frame.__init__(self, parent, id=wx.ID_ANY, title="口罩佩戴视频监测系统", pos=wx.DefaultPosition,
size=wx.Size(552, 121), style=wx.DEFAULT_FRAME_STYLE | wx.TAB_TRAVERSAL)
self.SetSizeHintsSz(wx.DefaultSize, wx.DefaultSize)
self.SetForegroundColour(wx.SystemSettings.GetColour(wx.SYS_COLOUR_ACTIVECAPTION))
self.SetBackgroundColour(wx.SystemSettings.GetColour(wx.SYS_COLOUR_ACTIVECAPTION))
gSizer1 = wx.GridSizer(0, 2, 0, 0)
self.m_button3 = wx.Button(self, wx.ID_ANY, u"开始", wx.DefaultPosition, wx.DefaultSize, 0)
self.m_button3.SetForegroundColour(wx.SystemSettings.GetColour(wx.SYS_COLOUR_INFOTEXT))
self.m_button3.SetBackgroundColour(wx.SystemSettings.GetColour(wx.SYS_COLOUR_SCROLLBAR))
gSizer1.Add(self.m_button3, 0, wx.ALL | wx.ALIGN_CENTER_HORIZONTAL | wx.ALIGN_CENTER_VERTICAL, 5)
self.m_button4 = wx.Button(self, wx.ID_ANY, u"终止", wx.DefaultPosition, wx.DefaultSize, 0)
self.m_button4.SetForegroundColour(wx.SystemSettings.GetColour(wx.SYS_COLOUR_WINDOWTEXT))
self.m_button4.SetBackgroundColour(wx.SystemSettings.GetColour(wx.SYS_COLOUR_SCROLLBAR))
gSizer1.Add(self.m_button4, 0, wx.ALL | wx.ALIGN_CENTER_HORIZONTAL | wx.ALIGN_CENTER_VERTICAL, 5)
self.SetSizer(gSizer1)
self.Layout()
self.Centre(wx.BOTH)
# Connect Events
self.Bind(wx.EVT_CLOSE, self.MyFrame1OnClose)
self.m_button3.Bind(wx.EVT_BUTTON, self.m_button3OnButtonClick)
self.m_button4.Bind(wx.EVT_BUTTON, self.m_button4OnButtonClick)
def __del__(self):
pass
# Virtual event handlers, overide them in your derived class
def MyFrame1OnClose( self, event ):
event.Skip()
sys.exit(0)
# Virtual event handlers, overide them in your derived class
def m_button3OnButtonClick(self, event):
event.Skip()
win = tk.Tk()
win.title("口罩佩戴视频监测系统") # 添加标题
ttk.Label(win, text="选择摄像头(默认为0)").grid(column=0, row=0) # 添加一个标签,并将其列设置为1,行设置为0
# button被点击之后会被执行
def begin(): # 当acction被点击时,该函数则生效
action1.configure(text='已开启' + number.get() + '号摄像头检测') # 设置button显示的内容
action1.configure(state='disabled') # 将按钮设置为灰色状态,不可使用状态
num = number.get()
module = hub.Module(name="pyramidbox_lite_server_mask", version='1.2.0')
# result_path = './result'
# if not os.path.exists(result_path):
# os.mkdir(result_path)
# name = "./result/1-mask_detection.mp4"
# width = 1920
# height = 1080
# fps = 120
# fourcc = cv2.VideoWriter_fourcc(*'vp90')
# writer = cv2.VideoWriter(name, fourcc, fps, (width, height))
maskIndex = 0
index = 0
data = []
capture = cv2.VideoCapture(int(num)) # 打开摄像头
# capture = cv2.VideoCapture('./test_video.mp4') # 打开视频文件
while True:
frameData = {}
ret, frame = capture.read() # frame即视频的一帧数据
if ret == False:
break
frame_copy = frame.copy()
input_dict = {"data": [frame]}
results = module.face_detection(data=input_dict, shrink=1, use_multi_scale=True)
maskFrameDatas = []
for result in results:
label = result['data']['label']
confidence_origin = result['data']['confidence']
confidence = round(confidence_origin, 2)
confidence_desc = str(confidence)
top, right, bottom, left = int(result['data']['top']), int(
result['data']['right']), int(result['data']['bottom']), int(
result['data']['left'])
# #将当前帧保存为图片
img_name = "avatar_%d.png" % (maskIndex)
# path = "./result/" + img_name
# image = frame[top - 10:bottom + 10, left - 10:right + 10]
# cv2.imwrite(path, image, [int(cv2.IMWRITE_PNG_COMPRESSION), 9])
maskFrameData = {}
maskFrameData['top'] = top
maskFrameData['right'] = right
maskFrameData['bottom'] = bottom
maskFrameData['left'] = left
maskFrameData['confidence'] = float(confidence_origin)
maskFrameData['label'] = label
maskFrameData['img'] = img_name
maskFrameDatas.append(maskFrameData)
maskIndex += 1
color = (0, 255, 0)
label_cn = "有口罩"
if label == 'NO MASK':
color = (0, 0, 255)
label_cn = "无口罩"
cv2.rectangle(frame_copy, (left, top), (right, bottom), color, 3)
cv2.putText(frame_copy, label, (left, top - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.8, color, 2)
# origin_point = (left, top - 36)
# frame_copy = paint_chinese(frame_copy, label_cn, origin_point, 24,
# color)
# writer.write(frame_copy)
cv2.imshow('Mask Detection', frame_copy)
frameData['frame'] = index
# frameData['seconds'] = int(index/fps)
frameData['data'] = maskFrameDatas
data.append(frameData)
# print(json.dumps(frameData)) # 输出检测结果
index += 1
cv2.waitKey(1)
cv2.destroyAllWindows()
# opencv输出中文
def paint_chinese(im, chinese, position, fontsize, color_bgr):
# 图像从OpenCV格式转换成PIL格式
img_PIL = Image.fromarray(cv2.cvtColor(im, cv2.COLOR_BGR2RGB))
font = ImageFont.truetype(
'SourceHanSansSC-Medium.otf', fontsize, encoding="utf-8")
# color = (255,0,0) # 字体颜色
# position = (100,100)# 文字输出位置
color = color_bgr[::-1]
draw = ImageDraw.Draw(img_PIL)
# PIL图片上打印汉字 # 参数1:打印坐标,参数2:文本,参数3:字体颜色,参数4:字体
draw.text(position, chinese, font=font, fill=color)
img = cv2.cvtColor(np.asarray(img_PIL), cv2.COLOR_RGB2BGR) # PIL图片转cv2 图片
return img
def callbackClose():
tkinter.messagebox.showwarning(title='警告', message='点击了关闭按钮')
sys.exit(0)
# 按钮
win.protocol("WM_DELETE_WINDOW", callbackClose)
action1 = ttk.Button(win, text="开始", command=begin) # 创建一个按钮, text:显示按钮上面显示的文字, command:当这个按钮被点击之后会调用command函数
action1.grid(column=2, row=1) # 设置其在界面中出现的位置 column代表列 row 代表行
# 创建一个下拉列表
number = tk.StringVar()
numberChosen = ttk.Combobox(win, width=12, textvariable=number)
numberChosen['values'] = (0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10) # 设置下拉列表的值
numberChosen.grid(column=0, row=1) # 设置其在界面中出现的位置 column代表列 row 代表行
numberChosen.current(0) # 设置下拉列表默认显示的值,0为 numberChosen['values'] 的下标值
win.mainloop() # 当调用mainloop()时,窗口才会显示出来
def m_button4OnButtonClick(self, event):
event.Skip()
sys.exit(0)
app = wx.App()
main_win = MyFrame1(None)
main_win.Show()
app.MainLoop()
效果图
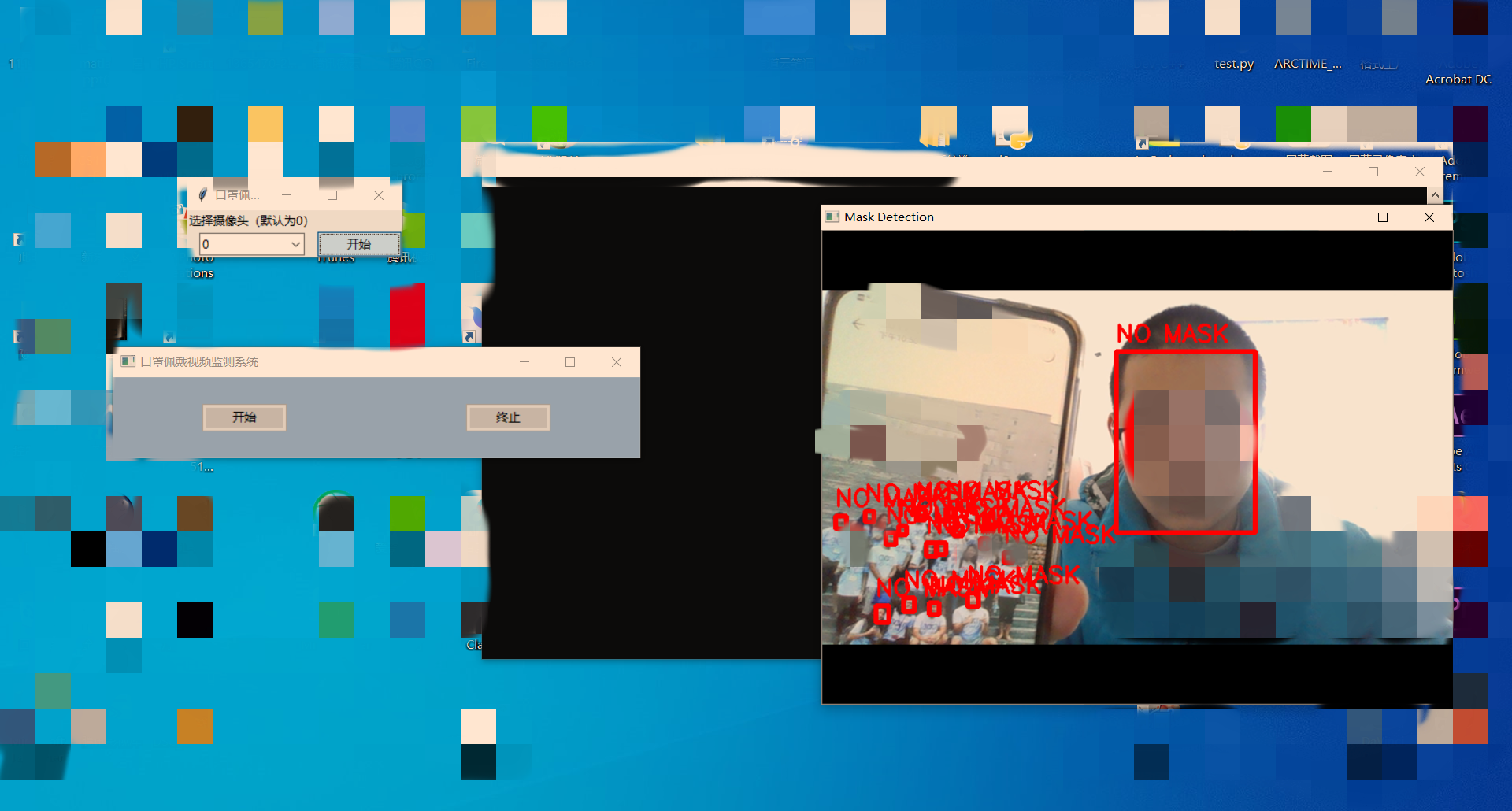
为了增加测试难度,我用手机找了一张人多的照片,而效果也非常不错,当然这确实是视频实时检测的。
4. 打包EXE
这一步中bug极多,道路极其艰难。
首先尝试pyinstaller,打包后出现bug显示索引超出范围,查询后发现是pyinstaller的bug,只能去官方的github下载开发版才能解决,但是后来又出现了新bug
然后尝试了py2exe,发现不支持,放弃
紧接着又尝试了cx_Freeze,结果制作GUI的Tkinter库存在bug,解决后,发现调用不了PaddleHub的模型,寻求百度官方的帮助,告知是cx_Freeze的bug
最终,又回到了pyinstaller,在网上没有教程的情况下,猜测着摸索解决了所有bug,实现了打包exe
那么我就直接讲述Pyinstaller的打包方法,其他两种由于过多的问题不加以赘述。
首先,必须从官方的github下载开发版,否则会出现list index out of range的报错提示
第二步可以开始打包了
- 进入cmd
- cd到目标py文件所在位置
- 使用pyinstaller XXXX.py打包exe,此时我们不加入其他参数,它就会生成__ pycache __,build,dist三个文件夹,并且此时所有依赖文件都会在dist的子文件夹中,除此之外,运行时也会显示doc窗口。
- 最终的exe文件会生成在dist的子文件夹中
第三步,进入cmd,运行dist子文件夹的exe文件,之后会显示报错信息
常见报错信息为缺少或者无法引用某些库或者dll文件
那么我们接下来找到python存储库文件的位置(一般在\Python\Python37\Lib\site-packages中),我们把相关的库文件夹直接复制到dist的子文件夹中(即EXE文件同目录下)。一般缺少的有Paddle库,Paddlehub库等。
其中比较特殊的是google库,在代码中我们并没有用到,但是去会显示缺少该库,那么我们pip下载后复制到dist的子文件夹中(即EXE文件同目录下)即可。
还有一个nltk库,会报错显示缺少nltk_data文件,关于这个问题我在写该文时记不清了,但是出现这个报错是能百度到解决方法的,同样也是下载该库,并且补充bat信息后,再复制到dist的子文件夹中(即EXE文件同目录下)即可。
Ⅱ. 服务器版的实现
1. 服务器端
首先你要拥有一个自己的服务器,然后在安全组中开放你计划的传输端口。
其次连接你的服务器后只需要一条命令就可以完成部署(以xshell连接为例)。
hub serving start -m pyramidbox_lite_server_mask -p 你开放的端口
但是,别着急,这么部署的话一关闭xshell,程序就会结束,我们要部署一个持续运行的,随时连接都能用的。
那么我们将命令改为:
nohup hub serving start -m pyramidbox_lite_server_mask -p 你开放的端口 &
2. 本地端
# coding: utf8
import requests
import json
import base64
import os
# 指定要检测的图片并生成列表[("image", img_1), ("image", img_2), ... ]
file_list = ["test.jpg"]
files = [("image", (open(item, "rb"))) for item in file_list]
# 指定检测方法为pyramidbox_lite_server_mask并发送post请求
url = "http://127.0.0.1:8866/predict/image/pyramidbox_lite_server_mask"
r = requests.post(url=url, files=files)
results = eval(r.json()["results"])
# 保存检测生成的图片到output文件夹,打印模型输出结果
if not os.path.exists("output"):
os.mkdir("output")
for item in results:
with open(os.path.join("output", item["path"]), "wb") as fp:
fp.write(base64.b64decode(item["base64"].split(',')[-1]))
item.pop("base64")
print(json.dumps(results, indent=4, ensure_ascii=False))
3. 简易GUI实现
直接使用Tkinter库实现。
def callbackClose():
tkinter.messagebox.showwarning(title='警告', message='点击了关闭按钮')
sys.exit(0)
def selectPath():
global rpath
# 选择文件path_接收文件地址
path_ = tkinter.filedialog.askopenfilename()
# 通过replace函数替换绝对文件地址中的/来使文件可被程序读取
# 注意:\\转义后为\,所以\\\\转义后为\\
path_ = path_.replace("/", "\\\\")
rpath = path_
# path设置path_的值
path.set(path_)
def begin(): # 当acction被点击时,该函数则生效
pass
main_box = tk.Tk()
#变量path
path = tk.StringVar()
main_box.title("口罩佩戴分类系统") # 添加标题
tk.Label(main_box,text = "目标路径:").grid(row = 0, column = 0)
ttk.Label(main_box, text="请保证路径不含中文").grid(column=1, row=1)
tk.Entry(main_box, textvariable = path).grid(row = 0, column = 1)
tk.Button(main_box, text = "路径选择", command = selectPath).grid(row = 0, column = 2)
main_box.protocol("WM_DELETE_WINDOW", callbackClose)
action1 = ttk.Button(main_box, text="开始", command=begin) # 创建一个按钮, text:显示按钮上面显示的文字, command:当这个按钮被点击之后会调用command函数
action1.grid(column=2, row=1) # 设置其在界面中出现的位置 column代表列 row 代表行
main_box.mainloop()
效果
4. 完整代码
备 注 : 该 项 目 由 于 存 在 G U I 部 分 无 法 直 接 在 A i s t u d i o 上 运 行 , 需 要 f o r k 后 进 入 下 载 p y 文 件 到 本 地 后 才 能 运 行 \color{red}备注:该项目由于存在GUI部分无法直接在Aistudio上运行,需要fork后进入下载py文件到本地后才能运行 备注:该项目由于存在GUI部分无法直接在Aistudio上运行,需要fork后进入下载py文件到本地后才能运行
# coding: utf8
import requests
import json
import base64
import os
import tkinter.filedialog
import tkinter as tk
from tkinter import ttk
import tkinter.messagebox
import sys
rpath = "test.png"
def callbackClose():
tkinter.messagebox.showwarning(title='警告', message='点击了关闭按钮')
sys.exit(0)
def selectPath():
global rpath
# 选择文件path_接收文件地址
path_ = tkinter.filedialog.askopenfilename()
# 通过replace函数替换绝对文件地址中的/来使文件可被程序读取
# 注意:\\转义后为\,所以\\\\转义后为\\
path_ = path_.replace("/", "\\\\")
rpath = path_
# path设置path_的值
path.set(path_)
def begin(): # 当acction被点击时,该函数则生效
global rpath
action1.configure(text='已上传文件') # 设置button显示的内容
action1.configure(state='disabled') # 将按钮设置为灰色状态,不可使用状态
# 指定要检测的图片并生成列表[("image", img_1), ("image", img_2), ... ]
file_list = [rpath]
files = [("image", (open(item, "rb"))) for item in file_list]
# 指定检测方法为pyramidbox_lite_server_mask并发送post请求
url = "http://39.97.120.36:8860/predict/image/pyramidbox_lite_server_mask"
# url = "http://127.0.0.1:8866/predict/image/pyramidbox_lite_server_mask"
#
r = requests.post(url=url, files=files)
results = eval(r.json()["results"])
# 保存检测生成的图片到output文件夹,打印模型输出结果
if not os.path.exists("output"):
os.mkdir("output")
for item in results:
with open(os.path.join("output", item["path"]), "wb") as fp:
fp.write(base64.b64decode(item["base64"].split(',')[-1]))
item.pop("base64")
print(json.dumps(results, indent=4, ensure_ascii=False))
tkinter.messagebox.showwarning(title='提示', message='已保存到output文件夹')
main_box = tk.Tk()
#变量path
path = tk.StringVar()
main_box.title("口罩佩戴分类系统") # 添加标题
tk.Label(main_box,text = "目标路径:").grid(row = 0, column = 0)
ttk.Label(main_box, text="请保证路径不含中文").grid(column=1, row=1)
tk.Entry(main_box, textvariable = path).grid(row = 0, column = 1)
tk.Button(main_box, text = "路径选择", command = selectPath).grid(row = 0, column = 2)
main_box.protocol("WM_DELETE_WINDOW", callbackClose)
action1 = ttk.Button(main_box, text="开始", command=begin) # 创建一个按钮, text:显示按钮上面显示的文字, command:当这个按钮被点击之后会调用command函数
action1.grid(column=2, row=1) # 设置其在界面中出现的位置 column代表列 row 代表行
main_box.mainloop()
5.打包EXE
直接使用Pyinstaller实现,由于该程序引用的库较少,应该可以直接打包成功,如果出现问题,参照上面解决就好。
III. APP的实现
此处可以直接参考该博客:
将其中的模型进行替换即可。
我与Paddle-Lite的官方人员联系后得知,目前已经实现了单模型预测,但还未在官方文档更新,待更新后可以直接替换模型即可实现。
这里放一张我的效果图:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-AhWle8Ek-1616141438935)(https://ai-studio-static-online.cdn.bcebos.com/4c642303df61436f8021e6b957cfea7d3344ba7e0cc445ad8ea255282eb9a1e1)]
六、优化和提升
PC端exe过大,启动过慢,可在继续研究进行优化
PC端的GUI可以增添更多参数,增强软件的可适用性
APP可以经过升级后运用于视频检测,并且可以进一步运用于树莓派等更小型化设备
服务器端如果使用专门服务器进行服务,可以实现视频检测,并且以网页形式呈现,更具实用性(这里分析一下为什么我没有做服务器端的视频检测:由于模型实际上还是对照片进行分类,所以视频检测就需要频繁访问服务器传输数据,且频率极高,如果不特殊设置,就会直接被服务器防护措施断开连接)
AISTUDIO地址:https://aistudio.baidu.com/aistudio/projectdetail/532316?shared=1
Github地址:https://github.com/chenqianhe/Mask_detection_based_on_PaddleHub















 1062
1062











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









