







一、一阶指数平滑
- 一阶指数平滑,也称为一次指数平滑或简单指数平滑(Simple Exponential Smoothing, SES),是时间序列预测中的一种方法。这种方法适用于没有明显趋势和季节性成分的时间序列数据。
- 一阶指数平滑的基本思想是最近的观测值比远期的观测值在预测未来时更为重要。因此,这种方法给予近期的数据更高的权重,而远期数据的权重则按指数规律递减。
一阶指数平滑的计算包括以下几个步骤: - 选择平滑系数(alpha):平滑系数决定了指数递减的速度,其值通常在0和1之间。alpha越接近1,模型对近期数据的关注越多;alpha越接近0,模型对历史数据的关注越多。
- 初始化:对于数据序列的初始值,如果数据点较多(大于20个),可以取第一个数据点作为初始平滑值;如果数据点较少,可以取前几个数据点的平均值。
- 平滑计算:一旦确定了alpha和初始值,就可以用以下公式进行平滑计算:
预测值 = a * 实际值 + (1 - a) * 上一期的预测值
from visitOracle import visitOracle
import pandas as pd
import numpy as np
from math_tool import *
# 时间序列指数平滑算法
###一阶指数平滑
## datas: 待预测的原始数据
## alfa: 平滑系数
## initial: 平滑初始值
## 返回结果:一次指数平滑结果
def expenontionSmooth(test_data , alfa , initial):
expenontionResult = []
expenontionResult.append(initial)
for i in range(len(test_data) -1):
# 指数平滑公式
tempResult = alfa * test_data[i+1] + (1 - alfa) * expenontionResult[i]
expenontionResult.append(round(tempResult , 2))
return expenontionResult
二、二次平滑指数
当时间数列无明显的趋势变化,可用一次指数平滑预测。其预测公式为:
yt+1’=a*yt+(1-a)*yt’ 式中,
• yt+1’–t+1期的预测值,即本期(t期)的平滑值St ;
• yt–t期的实际值;
• yt’–t期的预测值,即上期的平滑值St-1 。
三、二次指数平滑预测
1) a为加权系数;
2) 指数平滑法对实际序列具有平滑作用,权系数(平滑系数)越小,平滑作用越强,但是对实际数据的变动反映较迟缓;
3) 在实际序列的线性变动部分,指数平滑值序列出现一定的滞后偏差的程度随着权系数(平滑系数)的增大而减少;但当时间序列的变动出现直线趋势时,用一次指数平滑法来进行预测仍将存在着明显的滞后偏差。因此,也需要进行修正。
4) 修正的方法也是在一次指数平滑的基础上再进行二次指数平滑,利用滞后偏差的规律找出曲线的发展方向和发展趋势,然后建立直线趋势预测模型,故称为二次指数平滑法。
在一次指数平滑的基础上得二次指数平滑 的计算公式为:
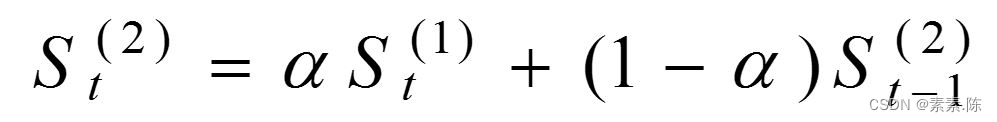
• 式中: St(2)——第t周期的二次指数平滑值;
• St(1)——第t周期的一次指数平滑值;
• St-1(2)——第t-1周期的二次指数平滑值;
• a ——加权系数(也称为平滑系数)。
二次指数平滑法是对一次指数平滑值作再一次指数平滑的方法。它不能单独地进行预测,必须与一次指数平滑法配合,建立预测的数学模型,然后运用数学模型确定预测值。
二次指数平滑数学模型:
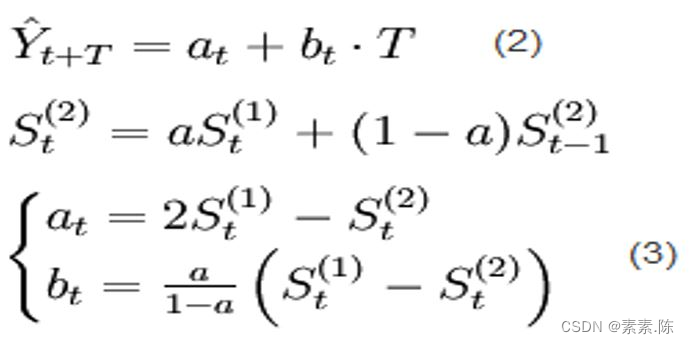
根据二次平滑指数数学模型进行计算a、b值。
python代码如下
###计算二阶指数平滑模型的参数
## datas: 待预测的原始数据
## alfa: 平滑系数
## initial: 平滑初始值
## 返回结果:二次指数平滑所对应的参数值
def paramCompute_TwoOrder(test_data, alfa,initial) :
param0 = [] #param0: 存放各个时刻的截距
param1 = [] #param1: 存放各个时刻的斜率
## 得到一次指数平滑结果
SmoothResult_oneOrder = expenontionSmooth(test_data , alfa , initial)
## 得到二次指数平滑结果
SmoothResult_twoOrder = expenontionSmooth(SmoothResult_oneOrder , alfa , SmoothResult_oneOrder[0] *1.1)
for i in range(len(SmoothResult_oneOrder)):
# 截距计算公式
param0_temp = 2 * SmoothResult_oneOrder[i] - SmoothResult_twoOrder[i]
# 斜率计算公式
param1_temp =( alfa / (1- alfa ) ) *  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 15万+
15万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









