







一、首先介绍几种常用的相似度计算
1.1最长公共子序列(LCS)
最长公共子序列(Longest Common Subsequence,简称LCS)是在两个或多个序列中寻找最长的公共子序列的问题。这里所说的“子序列”指的是原序列中元素的子集,但保持元素的原始顺序。
动态规划算法
最长公共子序列问题可以通过动态规划方法解决。以下是算法的步骤:
初始化:创建一个二维数组 dp,其大小为 (len(X) + 1) x (len(Y) + 1),其中 X 和 Y 是两个序列。数组的每个元素 dp[i][j] 表示序列 X[0…i-1] 和序列 Y[0…j-1] 的最长公共子序列的长度。
填充数组:按照以下规则填充数组:
如果 X[i-1] == Y[j-1],则 dp[i][j] = dp[i-1][j-1] + 1。
如果 X[i-1] != Y[j-1],则 dp[i][j] = max(dp[i-1][j], dp[i][j-1])。
结果:dp[len(X)][len(Y)] 就是两个序列的最长公共子序列的长度。
#---------------1 采用动态规划方法计算文本相似度------------------
## 最长公共子序列计算最长公共子串-------------------
def LCS(str_a, str_b):
if len(str_a) == 0 or len(str_b) == 0:
return 0
dp = [0 for _ in range(len(str_b) + 1)]
for i in range(1, len(str_a) + 1):
left_up = 0
dp[0] = 0
for j in range(1, len(str_b) + 1):
left = dp[j-1]
up = dp[j]
if str_a[i-1] == str_b[j-1]:
dp[j] = left_up + 1
else:
dp[j] = max([left, up])
left_up = up
return dp[len(str_b)]
#转换最长公共子序列为0-1之间的数值,结果越接近1,相似度越大
def LCS_Score(str_a, str_b):
return np.round(LCS(str_a, str_b)*2/(len(str_a)+len(str_b)),2)
#LCS_Score(str_a, str_b)
## 对dataframe的2列按照最长公共子序列计算相似度
## df: 数据来源变量
## col_name1、col_name2:用于计算相似度的2个列名
## simarity_score_name: 返回的相似度结果的列名
## 返回数据框,则simarity_score_name是用该计算方法对2列文本相似度的计算结果
def df_simarity_lcs(df , col_name1 , col_name2 , simarity_score_name):
df[simarity_score_name] = list(map(lambda str_a, str_b:LCS_Score(str_a, str_b),df[col_name1],df[col_name2]))
return df
1.2 余弦相似度
余弦相似度,是用向量空间中两个向量夹角的余弦值作为衡量两个个体间差异的大小的度量。 向量,是多维空间中有方向的线段,如果两个向量的方向一致,即夹角接近零,那么这两个向量就相近。对于2个向量a和b,余弦相似度计算公式如下所示:


使用场景:对于待比较的字段都为数值型变量时,这一部分的相似度可通过该方式进行计算。
## vec1, vec2:待计算的向量
## 返回2个向量的相似度
def cosine_simi(vec1, vec2):
from scipy import spatial
return 1 - spatial.distance.cosine(vec1, vec2)
## 对dataframe的2列按照最长公共子序列计算相似度
## df: 数据来源变量
## col_name1、col_name2:用于计算相似度的2个列名
## simarity_score_name: 返回的相似度结果的列名
## 返回数据框,则simarity_score_name是用该计算方法对2列文本相似度的计算结果
def df_simarity_cosine(df , col_name1 , col_name2 , simarity_score_name):
df[simarity_score_name] = list(map(lambda str_a, str_b:cosine_simi(str_a, str_b),df[col_name1],df[col_name2]))
return df
1.3 集合运算
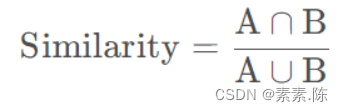
## 采用集合的方法计算2个集合的相似度
def similarity(a, b):
try:
return np.round(len(a & b) / len(a | b),2)
except ZeroDivisionError:
return -1e-4
## 采用集合的方法计算一个数据框中2个列的文本相似度
## df: 数据来源变量
## col_name1、col_name2:用于计算相似度的2个列名
## simarity_score_name: 返回的相似度结果的列名
## 返回数据框,则simarity_score_name是用该计算方法对2列文本相似度的计算结果
#对dataframe的2列按照海明威计算相似度
def df_simarity_jh(df , col_name1 , col_name2 , simarity_score_name):
df[simarity_score_name] = list(map(lambda str_a, str_b:similarity(set(str_a), set(str_b)),df[col_name1],df[col_name2]))
return df
1.4汉明距离
表示两个相同长度的字符串在相同位置上不同字符的个数。用d(x,y)来表示x和y两个字符串的汉明距离。汉明距离可以用来计算两个文本之间的相似度,根据不同字符的个数来判断两个文本是否相似。对于2个变量X1、X2,他们之间的汉明距离如下式所示:

使用场景:对于2条记录的同一个字段如果是类别变量,常采用该算法进行计算,码值相同时相似度取值为1,码值不同时相似度取值为0。
## 计算汉明距离,相同时取值为1,不同时取值为0,用来计算类别变量之间的相似度
def hmw_dist(str_a, str_b):
if str_a == str_b:
return 1
else :
return 0
## 对dataframe的2列按照最长公共子序列计算相似度
## df: 数据来源变量
## col_name1、col_name2:用于计算相似度的2个列名
## simarity_score_name: 返回的相似度结果的列名
## 返回数据框,则simarity_score_name是用该计算方法对2列文本相似度的计算结果
#对dataframe的2列按照海明威计算相似度
def df_simarity_hmw(df , col_name1 , col_name2 , simarity_score_name):
df[simarity_score_name] = list(map(lambda str_a, str_b:hmw_dist(str_a, str_b),df[col_name1],df[col_name2]))
return df
1.5 基于欧式距离的文本相似度计算

import numpy as np
def embedding_simi(vec1, vec2):
from scipy import spatial
return 1/(np.linalg.norm(feature_1 - feature_2) + 0.01)
## df: 数据来源变量
## col_name1、col_name2:用于计算相似度的2个列名
## simarity_score_name: 返回的相似度结果的列名
## 返回数据框,则simarity_score_name是用该计算方法对2列文本相似度的计算结果-------------------
def df_simarity_embedding(df , col_name1 , col_name2 , simarity_score_name):
df[simarity_score_name] = list(map(lambda str_a, str_b:embedding_simi(set(str_a), set(str_b)),df[col_name1],df[col_name2]))
return df
二、来自两个不同系统的数据匹配
由于字段都不统一时,用2个系统的数据海量匹配会面临运算量大的问题,因此需要想办法提升运算效率,用key,value时会大幅度提升,下面是一段代码的示例:
首先:对某一个系统中某一个字段取定值时为例,比如以地市编码为区分:
dict_adcode_sx = adcode_sx[['adcode','dict']].set_index('adcode')['dict'].to_dict()
column_lst = ['cust_no', 'id' , 'semi_score']
recomand_index = pd.DataFrame(columns = column_lst)
inner_tmp = pd.DataFrame(columns = ['cust_no','cust_name_brief'])
outer_tmp = pd.DataFrame(columns = ['id','name_brief'])
## 循环地区编码,在同一个地区编码内进行内外部数据的比对
for tmp_dict in dict_adcode_sx.keys():
# 提取内部数据的 cust_no 和 cust_name_brief 转换为dict
inner_tmpx = inner_data[inner_data['dict_code'] == tmp_dict]
inner_tmp = inner_tmpx[['cust_no','cust_name_brief']]
inner_tmp_dict = inner_tmp.set_index('cust_no')['cust_name_brief'].to_dict()
#dict_semi_result = semi_result.set_index('cust_no')['cust_name'].to_dict()
# 提取外部数据的 id 和 name_brief 转换为dict
# outer_tmpx = outer_data[outer_data['dict_code'] == tmp_dict]
outer_tmp = outer_data[['id','name_brief']]
outer_tmp_dict = outer_tmp.set_index('id')['name_brief'].to_dict()
#semi_lst = []
## 大循环内部数的信息
for cust_no , cust_name_brief in inner_tmp_dict.items():
semi = 0
key_id = 0
tmp_cust_no = cust_no
# 小循环外部数据的信息
for key, value in outer_tmp_dict .items():
#semi_r = LCS_Score(cust_name_brief, value)
semi_r = similarity(set(cust_name_brief), set(value))
if semi_r > semi:
key_id = key
semi = semi_r
## 给内部数据推荐名称相似度最大的外部数据
tmp_df = pd.DataFrame({'cust_no': [tmp_cust_no],
'id': [key_id],
'semi_score': [semi]
})
recomand_index = recomand_index.append(tmp_df)
recomand_index = recomand_index[recomand_index['semi_score'] > 0.88]
# 拎出来其他的字段
recomand_result = pd.merge( pd.merge(recomand_index ,
inner_data[['cust_no' , 'cust_name' , 'cert_number','ec_addr','cust_name_brief']]
),
outer_data[['id','name', 'credit_code' , 'reg_location','name_brief']])
recomand_result_unique = recomand_result.drop_duplicates(subset=['cust_no','id'], keep='last')
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









