







一、Gini系数##
1.1什么是基尼系数##
基尼系数是国际上用来综合考察居民内部收入分配差异状况的一个重要分析指标。每个人的收入有多有少,差距大时,基尼系数就高;差距小时,基尼系数就低。
1.2基本概念##
基尼系数表示在全部居民收入中,用于进行不平均分配的那部分收入占总收入的百分比。社会中每个人的收入都一样、收入分配绝对平均时,基尼系数是 0; 全社会的收入都集中于一个人、收入分配绝对不平均时,基尼系数是 1。现实生活中,两种情况都不可能发生,基尼系数的实际数值只能介于 0 ~ 1 之间。
1.3主要作用##
一般认为,基尼系数小于 0.2 时,显示居民收入分配过于平均,0.2—0.3 之间时较为平均,0.3—0.4 之间时比较合理,0.4—0.5 时差距过大,大于 0.5 时差距悬殊。通常而言,与面积或人口较小的国家相比,地域辽阔、人口众多和自然环境差异较大国家的基尼系数会高一些。经济处于起步阶段或工业化前期的国家,基尼系数要大一些,而发达经济体特别是实施高福利政策国家的基尼系数要小一些。
1.4计算方法##
基尼系数是根据洛伦茨曲线,即收入分布曲线计算的。在下图中,横轴是累计人口百分比, 纵轴是累计收入百分比。对角线上的斜线是绝对平均的收入分布线,垂直纵线是绝对不平均的收入分布线,斜线和垂直纵线之间的曲线是通常见到的实际收入分布曲线。斜线和曲线之间的面积 A,相当于用于不平均分配的那部分收入。基尼系数等于 A/(A+B),经济学含义是用于不平均分配的那部分收入占全部收入的比例。
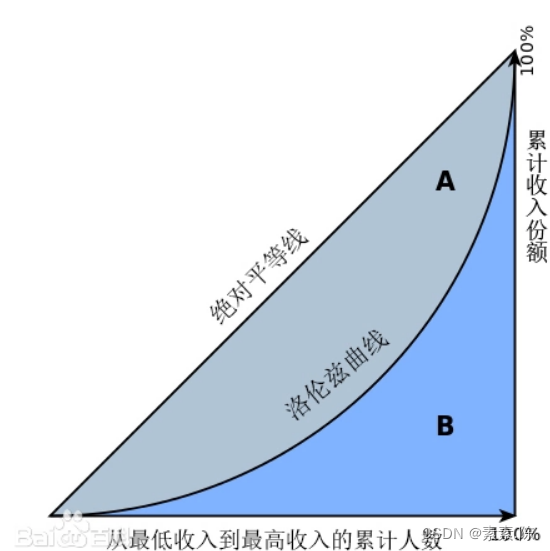
基尼系数最大为“1”,最小等于“0”。基尼系数越接近0表明
基尼系数需要使用分户或分组的居民收入数据来计算。 具体计算公式如下:
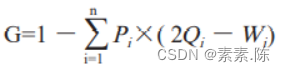
其中:
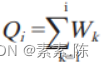
或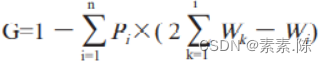
这里Wi 和Pi是指将调查户按收入由低到高进行排序,计算第 i 户代表的人口的收入占总收入比重(Wi)和第 i 户所代表的人口占总人口比重 (Pi)。
二、公平系数(库兹涅茨比率) 标题
库兹涅茨比率是指一个以数值反映总体收入不平等状况的指标。它把各个阶层的收入比重与人口比重的差额的绝对值加总起来。
三、代码实现
import cx_Oracle
import pandas as pd
from scipy.integrate import quad
import cx_Oracle as oracle
import pandas as pd
import numpy as np
# conn=cx_Oracle.connect('用户名/密码@数据库地址:数据库端口/SID')
# 数据库连接地址
def fairness_coefficient(incomes):
# 计算收入的平均值
mean_income = np.mean(incomes)
# 计算方差
variance = np.var(incomes - mean_income, ddof=1) # ddof=1是为了得到无偏估计的方差
# 计算公平系数,这里我们使用1减去方差的平方根,以得到一个0到1之间的值
# 公平系数越高,表示分配越均匀
fairness = 1 / (np.sqrt(variance)/len(incomes) )
return fairness
## 计算洛伦茨曲线
def lorentz_curve(x, incomes):
# 对收入进行排序
incomes = np.sort(incomes)
total_income = np.sum(incomes)
population = len(incomes)
# 计算每个点的累积收入和累积人口比例
cumulative_income = np.cumsum(incomes) / total_income
cumulative_population = np.arange(1, population + 1) / population
# 线性插值以找到对应于x的洛伦茨曲线的y值
y = np.interp(x, cumulative_population, cumulative_income)
return y
def gini_coefficient_integral(incomes):
# 积分函数,用于计算洛伦茨曲线与45度线之间的面积
def integrand(x):
return lorentz_curve(x, incomes) - x
# 积分区间从0到1(因为洛伦茨曲线的x轴和y轴都是比例)
area,_ = quad(integrand, 0, 1)
# 基尼系数是洛伦茨曲线与45度线之间面积的两倍
gini = round( abs(area)/ 0.5,4)
return gini
以一组样例数据最为例子,来示范以上两个方法的具体使用
if __name__ == '__main__':
address = "用户名/密码@ip:端口/实例名"
sql = "SELECT * FROM BDA.YLZCPG_STEP05"
result = visitOracle(address , sql)
dist_code = np.sort(result['AAA027'].unique())
year_code = np.sort(result['AAE002'].unique())
aae140 = np.sort(result['AAE140_2'].unique())
# 定义一个空DataFrame,返回公平系数、基尼系数指标
column_names = ['AAA027', 'AAE140', 'AAE002' , 'FAIRNESS' , 'GINI']
restlt_df1 = pd.DataFrame(columns = column_names)
## 计算指定dist_code + year_code + aae140范围内居民的基尼系数和公平系数
for dist in dist_code :
for year in year_code:
for xz in aae140:
tmp = result[(result['AAA027'] == dist) & (result['AAE002'] == year )& (result['AAE140_2'] == xz)]
## 对tmp中的payments排序,绘制洛伦茨曲线
income = np.sort(tmp['INCOME'])
gini = gini_coefficient_integral(income)
print('===================================')
print('==== dist_code = ' , dist)
print('==== year_code = ' , year)
print('==== aae140 = ' , xz)
print('==== gini = ' , gini)
## 计算库兹涅茨比率
# 筛选出各组人群
group_低 = tmp[tmp['GROUP_FLAG'] == '低收入组']
group_中低 = tmp[tmp['GROUP_FLAG'] == '中低收入组']
group_中 = tmp[tmp['GROUP_FLAG'] == '中收入组']
group_中高 = tmp[tmp['GROUP_FLAG'] == '中高收入组']
group_高 = tmp[tmp['GROUP_FLAG'] == '高收入组']
# 计算这两个群体的总收入
income_低 = group_低['INCOME'].sum()
income_中低 = group_中低['INCOME'].sum()
income_中 = group_中['INCOME'].sum()
income_中高 = group_中高['INCOME'].sum()
income_高 = group_高['INCOME'].sum()
# 计算这五个群体的总人数
total_低 = len(group_低)
total_中低 = len(group_中低)
total_中 = len(group_中)
total_中高 = len(group_中高)
total_高 = len(group_高)
## 计算人口总数、收入总数
total_cnt = len(tmp)
total_income = tmp['INCOME'].sum()
## 收入比重
Kuznets_ratio = round( abs(income_低 / total_income - total_低/ total_cnt) + abs(income_中低 / total_income - total_中低/ total_cnt)+ abs(income_中 / total_income - total_中/ total_cnt) + abs(income_中高 / total_income - total_中高/ total_cnt)
+ abs(income_高 / total_income - total_高/ total_cnt),4)
# 计算库兹涅茨比率
print('==== Kuznets_ratio = ' , Kuznets_ratio)
tmp_res = pd.DataFrame({'AAA027' : [dist],
'AAE140': [xz],
'AAE002': [year],
'FAIRNESS': [Kuznets_ratio] ,
'GINI': [gini]
})
restlt_df1 = restlt_df1.append(tmp_res)
# 将restlt_df1的数据回写到数据库
put_df_toOracle_cluster(restlt_df1 , '结果表名' , 'ip' , 端口,'用户名','密码' , '实例名')















 675
675

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









