









SpringBoot用ORM操作数据库
文章目录
前言
首先介绍如何使用 ORM(JPA、MyBatis)操作数据库;然后讲解常用的查询方式、自定义查询方式、原生SQL(Structured Query Language ,结构化查询语言)的开发和映射,最后对比分析 JPA 和 MyBatis 的区别。
认识 Java 的数据库连接模板 JDBCTemplate
了解 JDBC
JDBC(Java Database Connectivity, Java数据库连接),它是 Java 用于连接数据库的规范,即用于执行数据库 SQL 语句的 Java API 。
它可以为多种数据库提供统一访问的接口;它由一组用 Java 语言编写的类和接口组成,为大部分关系型数据库提供访问接口。
使用 JDBC 访问数据库需要每次进行 数据库连接、然后处理 SQL 语句、传值、关闭数据库。如果都由开发人员编写代码,则很容易出错,可能会出现使用完成之后,数据库连接忘记关闭的情况,导致连接被占用而降低性能,为了减少这种可能的错误,减少开发人员的工作量, JDBCTemplate 就被设计出来了。
了解 JDBCTemplate
JDBCTemplate 是对 JDBC 的封装。实现了 JDBC 的底层工作。使用 JDBCTemplate 操作数据库,再不需要每次都进行连接、打开、关闭了。
JDBC 和 JDBCTemplate 就像是仓库管理员,负责从仓库(数据库)中存取物品。而后者不需要“每次进入都开门,取完关门”,因它有电动门自动控制。
要使用 JDBCTemplate ,需要添加其 starter 依赖。因为要操作数据库,所以也需要配置数据库的连接依赖。
使用 JDBCTemplate
1.配置基础依赖,在pom.xml 文件中添加依赖
<!-- JDBCTemplate 依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<!-- MySQL 数据库 依赖 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
2.配置数据库连接信息
# 配置 IP、编码、时区、SSL
spring.datasource.url=jdbc:mysql://127.0.0.1:3306/db_name?useUnicode=true&characterEncoding=urf-8&serverTimezone=UTC&userSSL=true
# 数据库用户名
spring.datasource.username=root
# 数据库密码
spring.datasource.password=root
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
3.查询数据
@Resource
private JdbcTemplate jdbcTemplate;
//...
String sql = "select * from user where username=?";
List<User> userList = jdbcTemplate.query(sql, new User(), new Object[]{name});
认识 ORM
ORM(Object Relation Mapping, 对象/关系映射),它提供了概念性的,易于理解的数据模型,将数据库中的表和内存中的对象建立映射关系。
它是随着面向对象的软件开发方法的发展而产生的,面向对象的开发方法依然是当前主流的开发方法。
对象和关系型数据是业务实体的两种表现形式。业务实体在内存中表现为对象,在数据库中表现为关系型数据。内存中的对象不会被永久保存,只有关系型数据库(或 NoSQL 数据库,或文件)中的对象会被永久保存。
对象/关系映射(ORM) 系统一般以中间件的形式存在,因为内存中的对象之间存在关联的继承关系,而在数据库中,关系型数据无法直接表达多对多的关联和继承关系。
对象、数据库通过ORM映射关系如下:
Object ORM 数 据 库
类 <---- 映射 ----> 数据表
对象 <---- 映射 ----> 数据行
属性 <---- 映射 ----> 数据列(字段)
目前比较常用的 ORM 是国外非常流行的JPA 和国内非常流行的 MyBatis 。
maven dependency 的scope 标签的参数说明

JPA–Java 持久层 API
认识 Spring Data
Spring Data 是 Spring 的一个子项目,旨在统一和简化各类型数据的持久化存储方式,而不拘泥于是关系型数据库还是NoSQL数据库。
无论是哪种持久化存储方式,DAO(Data Access Objects,数据访问对象) 都会提供对对象的增加、删除、修饰和查询的方法,以及排序和分页方法等。
Spring Data 提供了基于这些层面的统一接口(如:CrudRepository、PageingAndSortingRepository),以实现持久化的存储。
Spring Data 包含多个子模块,主要分为主要模块和社区模块。
主要模块:
- Spring Data Commons :提供共享的基础框架,适合各个子项目使用,支持跨数据库持久化。
- Spring Data JDBC :提供了对 JDBC 的支持,其中封装了 JDBCTemplate。
- Spring Data JPA :简化创建 JPA 数据访问层和跨存储的持久层功能。
- Spring Data MongoDB :集成了对数据库 MongoDB 的支持。
- Spring Data Redis :集成了对 Redis 的支持。
- Spring Data REST :集成了对 RESTful 资源的支持。
- …
社区模块:
- Spring Data Elasticsearch :集成了对搜索引擎框架 Elasticsearch 的支持。
- Spring Data Neo4j :集成了对 Neo4j 数据库的支持。
- …
认识 JPA
JPA(Java Persistence API,Java 持久化API),用于对象的持久化。它是一个非常强大的 ORM 持久化的解决方案,免去了使用 JDBCTemplate 开发的编写脚本工作。JPA 通过简单约定好接口方法的规则自动生成相应的 JPQL 语句,然后映射成 POJO 对象。
JPA 是一个规范化接口,封装了 Hibernate 的操作作为默认实现,让用户不通过任何配置即可完成数据库的操作。
Spring Data、JPA、Hibernate的关系:
- Spring Data JPA 是 Spring Data 的一个主要模块,是一套规范和接口。
- JPA 使用 Hibernate 作为默认实现。
- Hibernate是一个 ORM 框架,它对 JDBC 进行了非常轻量级的对象封装,它将POJO与数据库表建立映射关系,是一个全自动的 ORM 框架。
Hibernate 主要通过 hibernate-annotation、hibernate-entitymanager和hibernate-core三个组件来操作数据。
- hibernate-annotation :是 Hibernate 支持 annotation 方式配置的基础,它包括标准的 JPA annotation、Hibernate 自身特殊功能的 annotation 。
- hibernate-core :是 Hibernate 的核心实现,提供了 Hibernate 所有的核心功能。
- hibernate-entitymanager :实现了标准的 JPA ,它是 hibernate-core 和 JPA 之间的适配器,它不直接提供 ORM 的功能,而是对 hibernate-core 进行封装,使得 Hibernate 符合 JPA 的规范。
使用 JPA
1.配置基础依赖,在pom.xml 文件中添加依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<!-- MySQL 数据库 依赖 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
2.配置数据库连接信息
# 配置 IP、编码、时区、SSL
spring.datasource.url=jdbc:mysql://127.0.0.1:3306/db_name?useUnicode=true&characterEncoding=urf-8&serverTimezone=UTC&userSSL=true
# 数据库用户名
spring.datasource.username=root
# 数据库密码
spring.datasource.password=root
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
# hibernate 的配置属性
# spring.jpa.properties.hibernate.hbm2ddl.auto=none
spring.jpa.hibernate.ddl-auto=nono
spring.jpa.properties.hibernate.dialect=org.hibernate.dialect.MySQL5InnoDBDialect
# 开发工具的控制台是否显示 SQL语句
spring.jpa.show-sql=true
spring.jpa.hibernate.ddl-auto 或 spring.jpa.properties.hibernate.hbm2ddl.auto , hibernate 的配置属性,其主要作用是:自动创建、更新、验证数据库表结构。如果不是此方面的需求建议set value=“none”。
spring.jpa.hibernate.ddl-auto 属性是Spring Data JPA 特有的,并且是它指定最终将传递给 Hibernate 的值的方法,该属性在它知道的属性 hibernate.hbm2ddl.auto 值 create , create-drop , validate 和 update 基本上影响框架工具管理在启动时如何操作数据库模式。
hibernate的配置属性参数值列表:
- none : 启动时不做任何操作。默认值,什么都不做,每次启动项目,不会对数据库进行任何验证和操作。
- create :每次加载 Hibernate 时都会删除上一次生成的表,然后根据 Model 类再重新生成新表,哪怕没有任何改变也会这样执行,这会导致数据库数据的丢失。(每次加载 Hibernate,重新创建数据库表结构)
- create-drop :每次加载 Hibernate 时会根据 Model 类生成表,但是 sessionFactory 一旦关闭,表就会自动被删除。(加载 Hibernate 时创建,退出是删除表结构)
- update :最常用的属性。第一次加载 Hibernate 时会根据 Model 类自动建立表的结构(前提是先建立好数据库)。以后加载 Hibernate 时,会根据 Model 类自动更新表结构,即使表结构改变了,但表中的数据仍然存在,不会被删除。要注意的是,当部署到服务器后,表结构是不会被马上建立起来的,要等应用程序第一次运行起来后才会建立。update 表示如果 Entity 实体的字段发生了变化,那么直接在数据库中进行更新。(加载 Hibernate 时自动更新数据库结构)
- validate :每次加载 Hibernate 时,会验证数据库的表结构,只会和数据库中的表进行比较,不会创建新表,但是会插入新值。(加载 Hibernate 时,验证创建数据库表结构)
线上环境建议不要开启这个 ddl-auto 功能,生产环境 spring.jpa.hibernate.ddl-auto=none
【Spring错误笔记】spring.jpa.hibernate.ddl-auto=update 造成删除索引的线上事故 https://blog.csdn.net/SnailMann/article/details/103733230
JPA 的常用注解:
@Entity:标识实体类是JPA实体,告诉JPA在程序运行时生成实体类对应表@Table:设置实体类在数据库所对应的表名@Id:标识类里所在变量为主键@GeneratedValue:设置主键生成策略,此方式依赖于具体的数据库@Column:表示属性所对应字段名进行个性化设置@Transient:表示属性并非数据库表字段的映射,ORM框架将忽略该属性@CreatedDate:表示字段为创建时间字段(insert自动设置)@CreatedBy:表示字段为创建用户字段(insert自动设置),通过实现 “AuditorAware” 接口的 “getCurrentAuditor” 方法来实现赋值。@LastModifiedDate:表示字段为最后修改时间字段(update自动设置)@LastModifiedBy:表示字段为最后修改用户字段(update自动设置),通过实现 “AuditorAware” 接口的 “getCurrentAuditor” 方法来实现赋值。@Embedded和@Embeddable:当一个实体类要在多个不同的实体类中进行使用,而其不需要生成数据库表@Embedded:注解在类上,表示此类是可以被其他类嵌套。@Embeddable:注解在属性上,表示嵌套被@Embeddable注解的同类型类。
@Temporal:在进行属性映射时调整 Date 类型数据的精度;在核心的 Java API 中并没有定义 Date 类型的精度(temporal precision). 而在数据库中,表示 Date 类型的数据有 DATE, TIME, 和 TIMESTAMP 三种精度(即单纯的日期,时间,或者两者 兼备)。@Temporal(TemporalType.DATE)@Temporal(TemporalType.TIME)@Temporal(TemporalType.TIMESTAMP)
@Basic:表示一个简单的属性到数据库表的字段的映射。@Basicfetch: 表示该属性的读取策略,有 EAGER 和 LAZY 两种,分别表示主动抓取和延迟加载,默认为 EAGER。例:@Basic(fetch=FetchType.LAZY)
懒加载 LAZY 和 实时加载 EAGER:
- 懒加载 LAZY 和 实时加载 EAGER 的目的是,实现关联数据的选择性加载。
- 懒加载是在属性被引用时才生成查询语句,抽取相关数据。
- 实时加载则是执行完主查询后,不管是否被引用,都会马上执行后续的关联数据查询
- 使用懒加载来调用关联数据,必须要保证主查询的 session(数据库连接会话)的生命周期没有结束,否则无法抽取到数据的。
映射关系注解:
@JoinColumn:指定一个实体组织或实体集合。用在“多对一”和“一对多”的关联中。@OneToOne:定义表之间“一对一”的关系@OneToMany:定义表之间“一对多”的关系@ManyToOne:定义表之间“多对一”的关系@ManyToMany:定义表之间“多对多”的关系
认识 JPA 的接口
JPA 提供了操作数据库的接口。在开发过程中继承和使用这些接口,可简化现有的持久化开发工作。
JPA 接口 JpaRepository
JpaRepository 继承自 PaingAndSortingRepository 。该接口提供了 JPA 的相关实用功能,以及通过 Example 进行查询的功能。 Example 对象是 JPA 提供用来构造查询条件的对象。
@NoRepositoryBean
public interface JpaRepository<T, ID> extends PagingAndSortingRepository<T, ID>,
QueryByExampleExecutor<T> {
}
在上述代码中, T 表示实体对象, ID 表示主键。 ID 必须实现序列化。
分页排序接口 PagingAndSortingRepository
PagingAndSortingRepository 继承自 CrudRepository 提供的分页和排序方法。
public interface PagingAndSortingRepository<T, ID> extends CrudRepository<T, ID> {
Iterable<T> findAll(Sort var1);
Page<T> findAll(Pageable var1);
}
- findAll(Sort sort) :排序功能。它按照 “sort” 制定的排序返回数据。
- Page findAll(Pageable pageable) :分页查询(含排序功能)。
数据操作接口 CrudRepository
CrudRepository 接口继承自 Repository 接口,并新增了增加、删除、修改和查询方法。
分页接口 Pageable 和 Page
Pageable 接口用于构造翻页查询,返回 Page 对象。 Page 从 0 开始分页。
排序类 Sort
Sort 类专门用来处理排序。最简单的排序就是先传入一个属性列,然后根据属性列的值进行排序。默认情况下是升序排列。它还可以根据提供的多个字段属性值进行排序。
Sort 排序的方法有下面几种:
- 直接创建 Sort 对象,适合对单一属性做排序。
- 通过 Sort.Order 对象创建 Sort 对象,适合对单一属性做排序。
- 通过属性 List 集合创建 Sort 对象,适合对多个属性采取同一种排序方式的排序。
- 通过 Sort.Order 对象的 List 集合创建 Sort 对象,适合所有情况,比较容易设置排序方式。
- 忽略大小写排序。
- 使用 JpaSort.unsafe 进行排序。
- 使用聚合函数进行排序。
JPA 的查询方式
1.使用约定方法名
约定方法一定要根据命名规范来写,Spring Data 会根据前缀、中间连接词(Or、And、Like、NotNull等类似SQL中的关键词)、内部拼接SQL代理生成方法的实现。
约定方法名的方法如下:
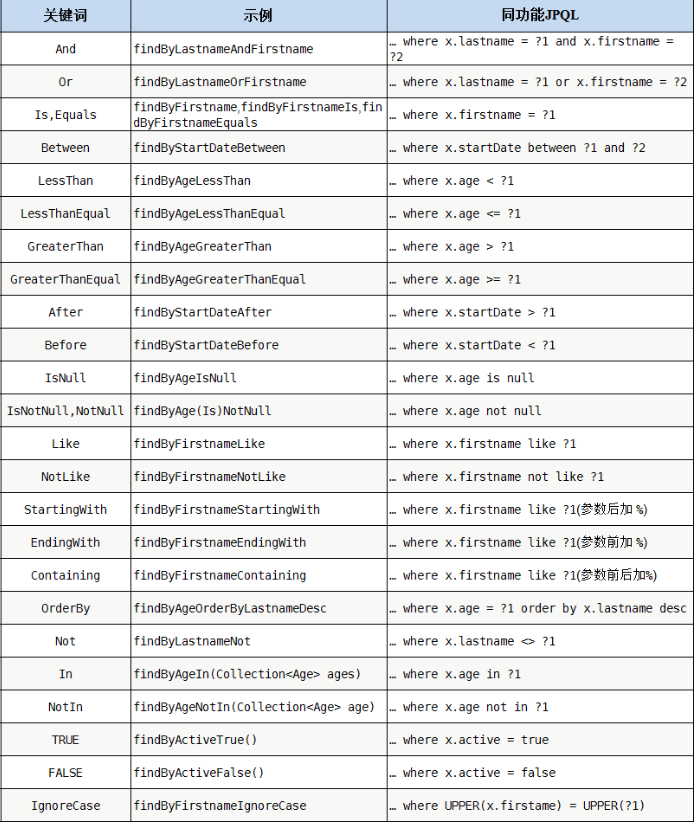
官方地址: https://docs.spring.io/spring-data/jpa/docs/2.0.9.RELEASE/reference/html/#jpa.query-methods.query-creation
2.用 JPQL 进行查询
JPQL语言(Java Persistence Query Language,Java持久化查询语言)是一种和SQL非常类似的中间性和对象化查询语言,它最终会被编译成针对不同底层数据库的SQL语言,从而屏蔽不同数据库的差异。
JPQL 语言通过 Query 接口封装执行,Query 接口封装了执行数据库查询的相关方法。调用 NtityManager 的 Query 、NamedQuery 及 NativeQuery 方法可以获得查询对象,进而可调用 Query 接口的相关方法来执行查询操作。
JPQL 是面向对象进行查询的语言,可以通过自定义的 JPQL 完成 UPDATE 和 DELETE 操作。JPQL 不支持使用 INSERT 。对于 UPDATE 或 DELETE 操作,必须使用注解 @Modifying 进行修饰。
// 根据 name 值进行查找
@Query("select u from User u where u.name = ?1")
User findByName(String name);
3.用原生 SQL 进行查询
在使用原生 SQL 查询时,也使用注解 @Query 。此时,nativeQuery 参数需要设置为 true 。
// 根据 ID 查询用户
@Query(value="select * from user u where u.id=:id", nativeQuery=true)
User findById(@Param("id")Long id);
//根据 name 查询用户,并返回分页对象 Page
@Query(value="select * from user where name=?1",
countQuery="select count(*) from user where name=?1",
nativeQuery = true)
Page<User> findByName(String name, Pageable pageable);
// 根据名字来修改 email 的值
@Modifying
@Query("update user set email = :email where name = :name")
void updateUserEmailByName(@Param("name") String name, @Param("email") String email);
UPDATE 或 DELETE 操作需要使用事务。此时需要在 Service 层的方法上添加事务操作。可通过在方法上使用注解 @Transactional。
在进行多个 Repository 操作时,也应用使这些操作在同一个事务中。按照分层架构的思想,这些操作属于业务逻辑层,因此需要在 Service 实现对多个 Repository 的调用,并在相应的方法上声明事务。
4.用 Specifications 进行查询
如果要使 Repository 支持 Specification 查询,则需要在 Repository 中继承 JpaSpecificationExecutor 接口。
// 继承 JpaSpecificationExecutor 接口
public interface CardRepository extends JpaRepository<Card, Long>, JapSpecificationExecutor<Card>{
Card findById(long id);
}
// 查询
Specification<Card> specification = new Specification<Card>(){
@Override
public Predicate toPredicate(Root<Card> root, CriteriaQuery<?> query, CriteriaBuilder cb){
Predicate predicate1 = cb.gt(root.get("id"), 2);
Predicate predicate2 = cb.equal(root.get("num"), 123);
// 构建组合的 Predicate
Predicate predicate = cb.and(predicate1, predicate2);
return predicate;
}
}
Page<Card> page = cardRepository.findAll(specification, pageable);
- CriteriaQuery 接口: specific 的顶层查询接口,它包含查询的各个部分,比如,select、from、where、group by、order by等。CriteriaQuery 对象只对实体类型或嵌入类型的 Criteria 查询起作用。
- root :代表查询的实体类是 Criteria 查询的根对象。Criteria 查询的根定义了实体类型,能为将来的导航获得想要的结果。它与 SQL 查询中的 From 子句类似。Root 实例是类型化的,且规定了 From 子句中能够出现的类型。查询根实例通过传入一个实体类型给 AbstractQuery.from 方法获得。
- query :可以从中得到 Root 对象,即告知 JPA Criteria 要查询哪一个实体类。还可以添加查询条件,并结合 EntityManager 对象得到最终查询的 TypedQuery 对象。
- CriteriaBuilder 对象:用于创建 Criteria 相关对象的工厂,可以从中获取到 Predicate 对象。
- Predicate 类型:代表一个查询条件。
认识 MyBatis – Java 数据持久层框架
MyBatis 和 JPA 一样,也是一款优秀的持久层框架,它支持定制化 SQL、存储过程,以及高级映射。它可以使用简单的 XML 或注解来配置和映射原生信息,将接口和 Java 的 POJOs 映射成数据库中的记录。
MyBatis 3 提供的注解可以取代XML。例如,使用注解 @Select 直接编写SQL完成数据查询;使用高级注解 @SelectProvider 还可以编写动态 SQL,以应对复杂的业务需求。
CRUD 注解
- 增加、删除、修改和查询是主要的业务操作,MyBatis 提供的操作数据的基础注解有以下4个:
@Select、@Insert、@Update、Delete。
映射注解
映射注解用于建立实体和关系的映射。它有以下3个注解:
@Results:用于填写结果集的多个字段的映射关系。@Result:用于填写结果集的单个字段的映射关系。@ResultMap:根据 ID 关联 XML 里面的 。
高级注解
MyBatis 3.x 版本主要提供了以下4个 CRUD 的高级注解,用于构建动态查询、添加、更新、删除 SQL:@SelectProvider 、 @InsertProvider 、 @UpdateProvider 、 @DeleteProvider 。
高级注解主要用于编写动态 SQL 。
比较 JPA 与 MyBatis
JPA 基于 Hibernate ,所以 JPA 和 MyBatis 的比较实际上是 Hibernate 和 MyBatis 之间的比较。
JPA 在全球范围内的用户数最多,而 MyBatis 是国内互联网公司的主流选择。
Hibernate 的优势:
- DAO 层开发比 MyBatis 简单,MyBatis 需要维护SQL和结果映射。
- 对对象的维护和缓存要比 MyBatis 好,对增加、删除、修改和查询对象的维护更方便。
- 数据库移植性很好。 MyBatis 的数据库移植性不好,不同的数据库需要写不同的 SQL 语句。
- 有更好的二级缓存机制,可以使用第三方缓存。 MyBatis 本身提供的缓存机制不佳。
MyBatis 的优势:
- 可以进行更为细致的 SQL 优化,可以减少查询字段(实际上Hibernate也可以实现)。
- 容易掌握。Hibernate 门槛较高。
简单总结:
- MyBatis :小巧、方便、高效、简单、直接、半自动化。
- Hibernate :强大、方便、高效、复杂、间接、全自动化。
建议:
- 如果没有 SQL 语言的基础,则建议使用 JPA。
- 如果有 SQL 语言基础,则建议使用 MyBatis ,因为国内使用 MyBatis 的人比使用 JPA 的人多很多。
总结
JDBC
JDBC(Java Database Connectivity, Java数据库连接),它是 Java 用于连接数据库的规范,即用于执行数据库 SQL 语句的 Java API 。
它可以为多种数据库提供统一访问的接口;它由一组用 Java 语言编写的类和接口组成,为大部分关系型数据库提供访问接口。
了解 JDBCTemplate
JDBCTemplate 是对 JDBC 的封装。实现了 JDBC 的底层工作。使用 JDBCTemplate 操作数据库,再不需要每次都进行连接、打开、关闭了。
认识 ORM
ORM(Object Relation Mapping, 对象/关系映射),它提供了概念性的,易于理解的数据模型,将数据库中的表和内存中的对象建立映射关系。
它是随着面向对象的软件开发方法的发展而产生的,面向对象的开发方法依然是当前主流的开发方法。
对象和关系型数据是业务实体的两种表现形式。业务实体在内存中表现为对象,在数据库中表现为关系型数据。
对象/关系映射(ORM) 系统一般以中间件的形式存在,因为内存中的对象之间存在关联的继承关系,而在数据库中,关系型数据无法直接表达多对多的关联和继承关系。
目前比较常用的 ORM 是国外非常流行的JPA 和国内非常流行的 MyBatis 。
认识 Spring Data
Spring Data 是 Spring 的一个子项目,旨在统一和简化各类型数据的持久化存储方式,而不拘泥于是关系型数据库还是NoSQL数据库。
无论是哪种持久化存储方式,DAO(Data Access Objects,数据访问对象) 都会提供对对象的增加、删除、修饰和查询的方法,以及排序和分页方法等。Spring Data 提供了基于这些层面的统一接口(如:CrudRepository、PageingAndSortingRepository),以实现持久化的存储。
认识 JPA
JPA(Java Persistence API,Java 持久化API),用于对象的持久化。它是一个非常强大的 ORM 持久化的解决方案,免去了使用 JDBCTemplate 开发的编写脚本工作。JPA 通过简单约定好接口方法的规则自动生成相应的 JPQL 语句,然后映射成 POJO 对象。
JPA 是一个规范化接口,封装了 Hibernate 的操作作为默认实现,让用户不通过任何配置即可完成数据库的操作。
Spring Data、JPA、Hibernate的关系:
- Spring Data JPA 是 Spring Data 的一个主要模块,是一套规范和接口。
- JPA 使用 Hibernate 作为默认实现。
- Hibernate是一个 ORM 框架,它对 JDBC 进行了非常轻量级的对象封装,它将POJO与数据库表建立映射关系,是一个全自动的 ORM 框架。
JPA 的查询方式
1.使用约定方法名
约定方法一定要根据命名规范来写,Spring Data 会根据前缀、中间连接词(Or、And、Like、NotNull等类似SQL中的关键词)、内部拼接SQL代理生成方法的实现。
2.用 JPQL 进行查询
JPQL语言(Java Persistence Query Language,Java持久化查询语言)是一种和SQL非常类似的中间性和对象化查询语言,它最终会被编译成针对不同底层数据库的SQL语言,从而屏蔽不同数据库的差异。
JPQL 语言通过 Query 接口封装执行,Query 接口封装了执行数据库查询的相关方法。调用 NtityManager 的 Query 、NamedQuery 及 NativeQuery 方法可以获得查询对象,进而可调用 Query 接口的相关方法来执行查询操作。
JPQL 是面向对象进行查询的语言,可以通过自定义的 JPQL 完成 UPDATE 和 DELETE 操作。JPQL 不支持使用 INSERT 。对于 UPDATE 或 DELETE 操作,必须使用注解 @Modifying 进行修饰。
3.用原生 SQL 进行查询
在使用原生 SQL 查询时,也使用注解 @Query 。此时,nativeQuery 参数需要设置为 true 。
4.用 Specifications 进行查询
如果要使 Repository 支持 Specification 查询,则需要在 Repository 中继承 JpaSpecificationExecutor 接口。
认识 MyBatis – Java 数据持久层框架
MyBatis 和 JPA 一样,也是一款优秀的持久层框架,它支持定制化 SQL、存储过程,以及高级映射。它可以使用简单的 XML 或注解来配置和映射原生信息,将接口和 Java 的 POJOs 映射成数据库中的记录。
比较 JPA 与 MyBatis
JPA 基于 Hibernate ,所以 JPA 和 MyBatis 的比较实际上是 Hibernate 和 MyBatis 之间的比较。
JPA 在全球范围内的用户数最多,而 MyBatis 是国内互联网公司的主流选择。
简单总结:
- MyBatis :小巧、方便、高效、简单、直接、半自动化。
- Hibernate :强大、方便、高效、复杂、间接、全自动化。
公众号

参考
《Spring Boot 实战派》 龙中华

















 323
323

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









