






分布式存储引擎层负责处理分布式系统中的各种问题,例如数据分布、负载均衡、容错、一致性协议等。与其它NOSQL系统类似,分布式存储引擎层支持根据主键更新、插入、删除、随机读取以及范围查找等操作,数据库功能层构建在分布式存储引擎层之上。
分布式存储引擎层包含三个模块:RootServer、UpdateServer和ChunkServer。
-
RootServer用于整体控制,实现Tablet分布、副本复制、负载均衡、机器管理以及Schema管理。
-
UpdateServer用于存储增量数据,数据结构为一颗内存B+树,并通过主备实时同步实现高可用,另外,UpdateServer的网络框架也经过专门的优化。
-
ChunkServer用于存储基准数据,基准数据按照主键有序划分为一个一个Tablet,每个Tablet在ChunkServer上存储了一个或者多个SSTable,另外,定期合并的主要逻辑也由ChunkServer实现。
OceanBase实现时也采用了很多技巧,例如Group Commit、双缓冲区预读、合并限速、内存管理等。本章将介绍分布式存储引擎的实现以及涉及到的实现技巧。
2.1 RootServer实现机制
RootServer是OceanBase集群对外的窗口,客户端通过RootServer获取集群中其它模块的信息。RootServer实现的功能包括:
- 管理集群中的所有ChunkServer,处理ChunkServer上下线。
- 管理集群中的UpdateServer,实现UpdateServer选主。
- 管理集群中Tablet数据分布,发起Tablet复制、迁移以及合并等操作。
- 与ChunkServer保持心跳,接受ChunkServer汇报,处理Tablet分裂与合并。
- 接受UpdateServer汇报的大版本冻结消息,通知ChunkServer执行定期合并。
- 实现主备RootServer,数据强同步,支持主RootServer宕机自动切换。
2.1.1 数据结构
RootServer的中心数据结构为一张存储了Tablet数据分布的有序表格,称为RootTable。每个Tablet存储的信息包括:Tablet主键范围、Tablet各个副本所在ChunkServer的编号、Tablet各个副本的数据行数、占用的磁盘空间、CRC校验值以及基准数据版本。
RootTable是一个读多写少的数据结构,除了ChunkServer汇报、RootServer发起Tablet复制、迁移以及合并等操作需要修改RootTable外,其它操作都只需要从RootTable中读取某个Tablet所在的ChunkServer。因此,OceanBase设计时考虑以写时复制的方式实现该结构.另外,考虑到RootTable修改特别少,实现时没有采用支持写时复制的B+树或者Skip List,而是采用相对更加简单的有序数组,以减少工作量。
往RootTable增加Tablet信息的操作步骤如下:
- 拷贝当前服务的RootTable为新的RootTable。
- 将Tablet信息追加到新的RootTable,并对新的RootTable重新排序。
- 原子地修改指针使得当前服务的RootTable指向新的RootTable。
ChunkServer一次汇报一批Tablet(默认一批包含1024个),如果每个Tablet修改都需要拷贝整个RootTable并重新排序,性能上显然无法接受。RootServer实现时做了一些优化:拷贝当前服务的RootTable为新的RootTable后,将ChunkServer汇报的一批Tablet一次性追加到新的RootTable中并重新排序,最后再原子地切换当前服务的RootTable为新的RootTable。采用批处理优化后,RootTable的性能基本满足需求,OceanBase单个集群支持的Tablet个数最大达到几百万个。当然,这种实现方式并不优雅,后续我们会将RootTable改造为B+树或者Skip List。
ChunkServer汇报的Tablet信息可能和RootTable中记录的不同,比如发生了Tablet分裂。此时,RootServer需要根据汇报的Tablet信息更新RootTable。
如图2-1所示,假设原来的RootTable包含四个Tablet:r1(min, 10],r2(10, 100],r3(100, 1000],r4(1000, max]。ChunkServer汇报的Tablet列表为:t1(10, 50],t2(50, 100],t3(100, 1000],表示r2发生了Tablet分裂,那么,RootServer会将RootTable修改为:r1(min, 10],r2(10, 50],r3(50, 100],r4(100, 1000],r5(1000, max]。

RootServer中还有一个管理所有ChunkServer信息的数组,称为ChunkServerManager。数组中的每个元素代表一台ChunkServer,存储的信息包括:机器状态(已下线、正在服务、正在汇报、汇报完成等)、启动后注册时间、上次心跳时间、磁盘相关信息、负载均衡相关信息。OceanBase刚上线时依据每台ChunkServer磁盘占用信息执行负载均衡,目的是为了尽可能确保每台ChunkServer占用差不多的磁盘空间。上线运行一段时间后发现这种方式效果并不好。目前的方式为按照每个表格的Tablet个数执行负载均衡,目的是尽可能保证对于每个表格,每台ChunkServer上的Tablet个数大致相同。
2.1.2 Tablet复制与负载均衡
RootServer中有两种操作都可能触发Tablet迁移:Tablet复制(rereplication)和负载均衡(rebalance)。当某些ChunkServer下线超过一段时间后,为了防止数据丢失,需要拷贝副本数小于阀值的Tablet。另外,系统也需要定期执行负载均衡,将Tablet从负载较高的机器迁移到负载较低的机器。
每台ChunkServer记录了Tablet迁移相关信息,包括:ChunkServer上Tablet的个数、所有Tablet的大小总和、正在迁入的Tablet个数、正在迁出的Tablet个数和Tablet迁移任务列表。RootServer包含一个专门的线程定期执行Tablet复制与负载均衡任务。
-
Tablet复制
扫描RootTable中的Tablet,如果某个Tablet的副本数小于阀值,则选取一台包含该Tablet副本的ChunkServer为迁移源,另外一台符合要求的ChunkServer为迁移目的地,生成Tablet迁移任务。迁移目的地需要符合一些条件有:不包含待迁移Tablet、服务的Tablet个数小于平均个数减去可容忍个数(默认值为10)、正在进行的迁移任务不超过阀值等。 -
负载均衡
扫描RootTable中的Tablet,如果某台ChunkServer包含的某个表格的Tablet个数超过平均个数以及可容忍个数(默认值为10)之和,则以这台ChunkServer为迁移源,并选择一台符合要求的ChunkServer为迁移目的地,生成Tablet迁移任务。
Tablet复制和负载均衡生成的Tablet迁移并不会立即执行,而是会加入到迁移源的迁移任务列表中。RootServer中的一个后台线程会扫描所有的ChunkServer,然后执行每台ChunkServer的迁移任务列表中保存的迁移任务。Tablet迁移时限制了每台ChunkServer同时进行的最大迁入和迁出任务数,从而防止一台新的ChunkServer刚上线时,迁入大量Tablet而负载过高。
例如:某OceanBase集群中包含4台ChunkServer:ChunkServer1(包含Tablet A1,A2,A3),ChunkServer2(包含Tablet A3,A4),ChunkServer3(包含Tablet A2),ChunkServer4(包含Tablet A4)。 假设Tablet副本数配置为2,最多能够容忍的不均衡Tablet的个数为0。
- RootServer后台线程首先执行Tablet复制,发现Tablet A1只有一个副本,于是,将ChunkServer1作为迁移源,并选择一台ChunkServer作为迁移目的地(假设为ChunkServer3),生成迁移任务<ChunkServer1,ChunkServer3,A1>。
- 执行负载均衡,发现ChunkServer1包含3个Tablet, 超过平均值(平均值为2),而ChunkServer4包含的Tablet个数小于平均值。
- 将ChunkServer1作为迁移源, ChunkServer4作为迁移目的地,选择某个Tablet(假设为A2),生成迁移任务<ChunkServer1,ChunkServer4,A2>。
- 如果迁移成功,A2将包含3个副本,可以通知ChunkServer1删除上面的A2副本。
此时,Tablet分布情况为:ChunkServer1(包含Tablet A1,A3),ChunkServer2(包含Tablet A3,A4),ChunkServer3(包含Tablet A1,A2),ChunkServer4(包含Tablet A2,A4)。 每个Tablet包含2个副本,且平均分布在4台ChunkServer上。
2.1.3 Tablet分裂与合并
Tablet分裂由ChunkServer在定期合并过程中执行。由于每个Tablet包含多个副本,且分布在多台ChunkServer上,如何确保多个副本之间的分裂点保持一致成为问题的关键。OceanBase采用了一种比较直接的做法:每台ChunkServer使用相同的分裂规则。由于每个Tablet的不同副本之间的基准数据完全一致,且定期合并过程中冻结的增量数据也完全相同,只要分裂规则一致,分裂后的Tablet主键范围也保证相同。
OceanBase曾经有一个线上版本的分裂规则如下:只要定期合并过程中产生的数据量超过256MB,就生成一个新的Tablet。假设定期合并产生的数据量为257MB,那么最后将分裂为两个Tablet,其中,前一个Tablet(记为r1)的数据量为256MB,后一个Tablet(记为r2)的数据量为1MB。接着,r1接受新的修改,数据量很快又超过256MB,于是,又分裂为两个Tablet。系统运行一段时间后,充斥着大量数据量很少的Tablet。
为了解决分裂产生小Tablet的问题,需要确保分裂以后的每个Tablet数据量大致相同。OceanBase对每个Tablet记录了两个元数据:数据行数row_count以及Tablet大小(occupy_size)。根据这两个值,可以计算出每行数据的平均大小,即:occupy_size/row_count。 根据数据行平均大小,可以计算出分裂后的Tablet行数,从而得到分裂点。
Tablet合并过程如下:
- 合并准备:RootServer选择若干个主键范围连续的小Tablet。
- Tablet迁移:将待合并的若干个小Tablet迁移到相同的ChunkServer机器。
- Tablet合并:往ChunkServer机器发送Tablet合并命令,生成合并后的Tablet范围。
例如: 某OceanBase集群中有3台ChunkServer:ChunkServer1(包含Tablet A1,A3),ChunkServer2(包含Tablet A2,A3),ChunkServer3(包含Tablet A1,A2),其中,A1和A2分别为10MB,A3为256MB。
- RootServer扫描RootTable后发现A1和A2满足Tablet合并条件,则发起Tablet迁移。
- 假设将A1迁移到ChunkServer2,使得A1和A2在相同的ChunkServer上。
- 分别向ChunkServer2和ChunkServer3发起Tablet合并命令。
Tablet合并完成以后,Tablet分布情况为:ChunkServer1(包含Tablet A3),ChunkServer2(包含Tablet A4(A1, A2),A3),ChunkServer3(包含Tablet A4(A1, A2)),其中,A4是Tablet A1和A2合并后的结果。
说明:每个Tablet包含多个副本,只要某一个副本合并成功,OceanBase就认为Tablet合并成功,其它合并失败的Tablet将通过垃圾回收机制删除掉。
2.1.4 UpdateServer选主
为了确保一致性,RootServer需要确保每个集群中只有一台UpdateServer提供写服务,这个UpdateServer称为主UpdateServer。
RootServer通过租约(Lease)机制实现UpdateServer选主。主UpdateServer必须持有RootServer的租约才能提供写服务,租约的有效期一般为3~5秒。正常情况下,RootServer会定期给主UpdateServer发送命令,延长租约的有效期。如果主UpdateServer出现异常,RootServer等待主UpdateServer的租约过期后才能选择其它的UpdateServer为主UpdateServer继续提供写服务。
RootServer可能需要频繁升级,升级过程中UpdateServer的租约将很快过期,系统也会因此停服务。为了解决这个问题,RootServer设计了优雅退出的机制,即RootServer退出之前给UpdateServer发送一个有效期超长的租约(比如半小时),承诺这段时间不进行主UpdateServer选举,用于RootServer升级。
2.1.5 RootServer主备
每个集群一般部署一主一备两台RootServer,主备之间数据强同步,即所有的操作都需要首先同步到备机,接着修改主机,最后才能返回操作成功。
RootServer主备之间需要同步的数据包括:RootTable中记录的Tablet分布信息、ChunkServerManager中记录的ChunkServer机器变化信息以及UpdateServer机器信息。Tablet复制、负载均衡、合并、分裂以及ChunkServer和UpdateServer上下线等操作都会引起RootServer内部数据变化,这些变化都将以操作日志的形式同步到备RootServer。备RootServer实时回放这些操作日志,从而与主RootServer保持同步。
OceanBase中的其它模块,比如ChunkServer和UpdateServer,以及客户端通过VIP(Virtual IP)访问RootServer,正常情况下,VIP总是指向主RootServer。当主RootServer出现故障时,部署在主备RootServer上的Linux HA(heartbeat)软件能够检测到,并将VIP漂移到备RootServer。
Linux HA软件的核心包含两个部分:心跳检测部分和资源接管部分。心跳检测部分通过网络链接或者串口线进行,主备RootServer上的heartbeat软件相互发送报文来告诉对方自己当前的状态。如果在指定的时间内未收到对方发送的报文,那么就认为对方失败。这时需启动资源接管模块来接管运行在对方主机上的资源,这里的资源就是VIP。备RootServer后台线程能够检测到VIP漂移到自身,于是自动切换为主机提供服务。
2.2 UpdateServer实现机制
UpdateServer用于存储增量数据,它是一个单机存储系统,由如下几个部分组成:
- 内存存储引擎:在内存中存储修改增量,支持冻结以及转储操作。
- 任务处理模型:包括网络框架、任务队列、工作线程等,针对小数据包做了专门的优化。
- 主备同步模块:将更新事务以操作日志的形式同步到备UpdateServer。
UpdateServer是OceanBase性能瓶颈点,核心是高效,实现时对锁(例如,无锁数据结构)、索引结构、内存占用、任务处理模型以及主备同步都需要做专门的优化。
2.2.1 内存存储引擎
UpdateServer存储引擎如图2-2所示。
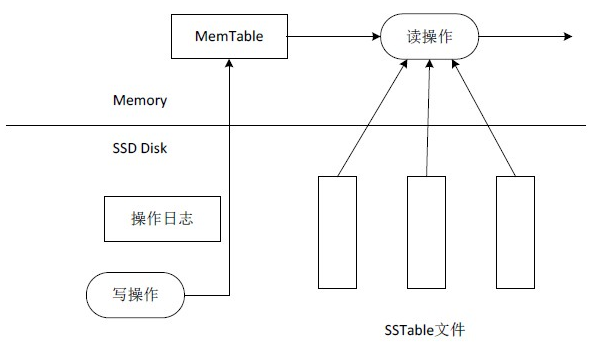
UpdateServer存储引擎与Bigtable存储引擎相似,不同点在于:
- UpdateServer只存储了增量更新数据,基准数据以SSTable的形式存储在ChunkServer上,而Bigtable存储引擎同时包含某个Tablet的基准数据和增量数据。
- UpdateServer内部所有表格共用MemTable以及SSTable,而Bigtable中每个Tablet的MemTable和SSTable分开存放。
- UpdateServer的SSTable存储在SSD盘中,而Bigtable的SSTable存储在GFS中。
UpdateServer存储引擎包含几个部分:操作日志、内存表(底层为一颗高性能的B+树)以及SSTable。更新操作首先记录到操作日志中,接着更新内存中活跃的MemTable(Active MemTable),活跃的MemTable到达一定大小后将被冻结,成为Frozen MemTable,同时创建新的Active MemTable。Frozen MemTable将以SSTable文件的形式转储到SSD盘中。
- 操作日志
OceanBase中有一个专门的提交线程负责确定多个写事务的顺序(即事务id)。将这些写事务的操作追加到日志缓冲区,并将日志缓冲区的内容写入日志文件。为了防止写操作日志污染操作系统的缓存,写操作日志文件采用Direct IO的方式实现。 - MemTable
MemTable底层是一颗高性能内存B+树。MemTable封装了B+树,对外提供统一的读写接口。
B+树中的每个元素对应MemTable中的一行操作,key为行主键,value为行操作链表的指针。每行的操作按照时间顺序构成一个行操作链表,如图2-3所示。

MemTable内存结构包含两部分:索引结构以及行操作链表,索引结构为B+树,支持插入、删除、更新、随机读取以及范围查询操作。行操作链表保存的是对某一行各个列(每个行和列确定一个单元,称为Cell)的操作,例如,对主键为1的商品有3个操作,分别是:将商品购买人数修改为100,删除该商品,将商品名称修改为“女鞋”。那么,该商品的行操作链中将保存三个Cell,分别为: <update,购买人数,100>、<delete,*> 以及<update,商品名,“女鞋”>。 也就是说,MemTable中存储的是对该商品的所有操作,而不是最终结果。另外,MemTable删除一行也只是往行操作链表的末尾加入一个逻辑删除标记,即<delete,*>,而不是实际删除索引结构或者行操作链表中的行内容。
MemTable实现时做了很多优化,包括:
-
Hash索引
针对主要操作为随机读取的应用,MemTable不仅支持B+树索引,还支持Hash索引,UpdateServer内部会保证两个索引之间的一致性。 -
内存优化
行操作链表中每个cell操作都需要存储操作列的编号(column_id)、操作类型(更新操作还是删除操作)、操作值以及指向下一个cell操作的指针,如果不做优化,内存膨胀会很大。为了减少内存占用,MemTable实现时会对整数值进行变长编码,并将多个cell操作编码后序列到同一块缓冲区中,共用一个指向下一个cell操作缓冲区的指针。// 开启一个事务 // @param =in] trans_type 事务类型,可能为读事务或者写事务 // @param =out] td 返回的事务描述符 int start_transaction(const TETransType trans_type, MemTableTransDescriptor& td);
// 提交或者回滚一个事务 // @param =in] td 事务描述符 // @param =in] rollback 是否回滚,默认为false int end_transaction(const MemTableTransDescriptor td, bool rollback = false);
// 执行随机读取操作,返回一个迭代器 // @param =in] td 事务描述符 // @param =in] table_id 表格编号 // @param =in] row_key 待查询的主键 // @param =out] iter 返回的迭代器 int get(const MemTableTransDescriptor td, const uint64_t table_id, const ObRowkey& row_key, MemTableIterator& iter);
// 执行范围查询操作,返回一个迭代器 // @param =in] td 事务描述符 // @param =in] range 查询范围,包括起始行、结束行,开区间或者闭区间 // @param =out] iter 返回的迭代器 int scan(const MemTableTransDescriptor td, const ObRange& range, MemTableIterator& iter);
// 开始执行一次更新操作 // @param =in] td 事务描述符 int start_mutation(const MemTableTransDescriptor td);
// 提交或者回滚一次更新操作 // @param =in] td 事务描述符 // @param =in] rollback 是否回滚 int end_mutation(const MemTableTransDescriptor td, bool rollback);
// 执行更新操作 // @param =in] td 事务描述符 // @param =in] mutator 更新操作,包含一个或者多个对多个表格的cell操作 int set(const MemTableTransDescriptor td, ObUpsMutator& mutator);对于读事务,操作步骤如下:
- 调用start_transaction开始一个读事务,获得事务描述符。
- 执行随机读取或者扫描操作,返回一个迭代器。
- 调用end_transaction提交或者回滚一个事务。
class MemTableIterator { public: // 迭代器移动到下一个cell int next_cell(); // 获取当前cell的内容 // @param [out] cell_info 当前cell的内容,包括表名(table_id),行主键(row_key),列编号(column_id)以及列值(column_value) int get_cell(ObCellInfo** cell_info); // 获取当前cell的内容 // @param [out] cell_info 当前cell的内容 // @param is_row_changed 是否迭代到下一行 int get_cell(ObCellInfo** cell_info, bool * is_row_changed); };读事务返回一个迭代器MemTableIterator,通过它可以不断地获取下一个读到的cell。上面的例子中,读取编号为1的商品可以得到一个迭代器,从这个迭代器中可以读出行操作链中保存的3个Cell,依次为:<update,购买人数,100>,<delete,*>,<update,商品名,“女鞋”>。
写事务总是批量执行,步骤如下:
- 调用start_transaction开始一批写事务,获得事务描述符。
- 调用start_mutation开始一次写操作。
- 执行写操作,将数据写入到MemTable中。
- 调用end_mutation提交或者回滚一次写操作;如果还有写事务,转到“步骤2”。
- 调用end_transaction提交写事务。
- SSTable
当活跃的MemTable超过一定大小或者管理员主动发起冻结命令时,活跃的MemTable将被冻结,生成冻结的MemTable,并同时以SSTable的形式转储到SSD盘中。
SSTable的详细格式请参见本手册“2.3 ChunkServer实现机制”章节。与ChunkServer中的SSTable不同的是,UpdateServer中所有的表格共用一个SSTable,且SSTable为稀疏格式。也就是说,每一行数据的每一列可能存在,也可能不存在更新操作。
另外,OceanBase设计时也尽量避免读取UpdateServer中的SSTable。只要内存足够,冻结的MemTable会保留在内存中。系统会尽快将冻结的数据通过定期合并转移到ChunkServer中去,以后不再需要访问UpdateServer中的SSTable数据。
2.2.2 任务处理模型
任务模型包括网络框架、任务队列和工作线程。UpdateServer最初的任务模型基于淘宝网实现的Tbnet框架(已开源,请参见http://code.taobao.org/p/tb-common-utils/src/trunk/tbnet/)。Tbnet封装得很好,使用比较方便,每秒收包个数最多可以达到接近10万,不过仍然无法完全发挥UpdateServer收发小数据包以及内存服务的特点。OceanBase后来采用优化过的任务模型Libeasy,小数据包处理能力得到进一步提升。
- Tbnet
如图2-4所示,Tbnet队列模型本质上是一个“生产者-消费者”队列模型,有两个线程:网络读写线程和超时检查线程。其中,网络读写线程执行事件循环,当服务器端有可读事件时,调用回调函数读取请求数据包,生成请求任务,并加入到任务队列中。工作线程从任务队列中获取任务,处理完成后触发可写事件,网络读写线程会将处理结果发送给客户端。超时检查线程用于将超时的请求移除。
图2-4 Tbnet队列模型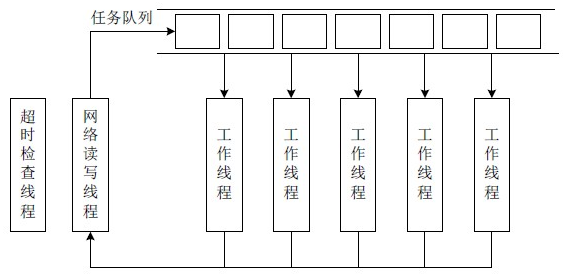
Tbnet模型的问题在于多个工作线程从任务队列获取任务需要加锁互斥,这个过程将产生大量的上下文切换,测试发现,当UpdateServer每秒处理包的数量超过8万个时,UpdateServer每秒的上下文切换次数接近30万次,在测试环境中已经达到极限(测试环境配置:Linux内核2.6.18,CPU为2 * Intel Nehalem E5520,共8核16线程)。
- Libeasy
为了解决收发小数据包带来的上下文切换问题,OceanBase目前采用Libeasy任务模型。Libeasy采用多个线程收发包,增强了网络收发能力,每个线程收到网络包后立即处理,减少了上下文切换。
如图2-5所示,UpdateServer有多个网络读写线程。每个线程通过Linux epool监测一个套接字集合上的网络读写事件。每个套接字只能同时分配给一个线程。当网络读写线程收到网络包后,立即调用任务处理函数,如果任务处理时间很短,可以很快完成并回复客户端,不需要加锁,避免了上下文切换。UpdateServer中大部分任务为短任务,比如随机读取内存表,另外还有少量任务需要等待共享资源上的锁,可以将这些任务加入到长任务队列中,交给专门的长任务处理线程处理。
图2-5 Libeasy任务模型
由于每个网络读写线程处理一部分预先分配的套接字,这就可能出现某些套接字上请求特别多而导致负载不均衡的情况。例如,有两个网络读写线程thread1和thread2,其中thread1处理套接字fd1、fd2,thread2处理套接字fd3、fd4,fd1和fd2上每秒1000次请求,fd3和fd4上每秒10次请求,两个线程之间的负载很不均衡。为了处理这种情况,Libeasy内部会自动在网络读写线程之间执行负载均衡操作,将套接字从负载较高的线程迁移到负载较低的线程。
2.2.3 主备同步模块
在本手册的“1.4.1 一致性选择”章节已经介绍了UpdateServer的一致性选择。OceanBase选择了强一致性,主UpdateServer往备UpdateServer同步操作日志,如果同步成功,则主UpdateServer读写操作生效,并将更新成功消息返回给客户端;否则,主UpdateServer会把备UpdateServer从同步列表中剔除。另外,剔除备UpdateServer之前需要通知RootServer,从而防止RootServer将不一致的备UpdateServer选为主UpdateServer。
如图2-6所示,主UpdateServer往备机推送操作日志,备UpdateServer的接收线程接收日志,并写入到一块全局日志缓冲区中。主UpdateServer接着更新本地内存并将日志刷到磁盘文件中,最后回复客户端写入操作成功。这种方式实现了强一致性,如果主UpdateServer出现故障,备UpdateServer包含所有的更新操作,因而能够完全无缝地切换为主UpdateServer继续提供服务。另外,主备同步过程中要求主机刷磁盘文件,备机只需要写内存缓冲区,强同步带来的额外延时也几乎可以忽略。
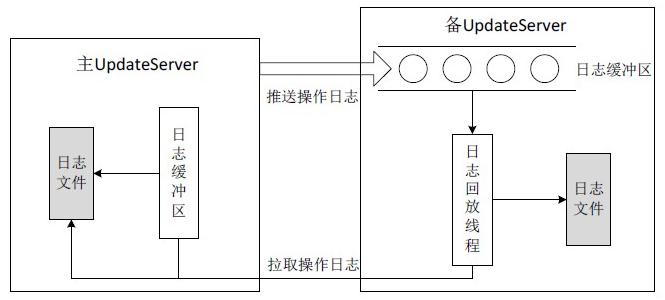
正常情况下,备UpdateServer的日志回放线程会从全局日志缓冲区中读取操作日志,在内存中回放并同时将操作日志刷到备机的日志文件中。如果发生异常,比如备UpdateServer刚启动或者主备之间网络刚恢复,全局日志缓冲区中没有日志或者日志不连续,此时,备UpdateServer需要主动请求主UpdateServer拉取操作日志。主UpdateServer首先查找日志缓冲区,如果缓冲区中没有数据,还需要读取磁盘日志文件,并将操作日志回复备UpdateServer。
2.3 ChunkServer实现机制
ChunkServer用于存储基线数据,它由如下基本部分组成:
- SSTable,根据主键有序存储每个Tablet的基线数据。
- 基于LRU(Least Recently Used)实现块缓存(Block cache)以及行缓存(Row cache)。
- 实现Direct IO,磁盘IO与CPU计算并行化。
- 通过定期合并获取UpdateServer的冻结数据,从而分散到整个集群。
- 主动实现Tablet分裂,配合RootServer实现Tablet迁移、删除、合并。
每台ChunkServer服务着几千到几万个Tablet的基线数据,每个Tablet由若干个SSTable组成(一般为1个)。
2.3.1 SSTable
如图2-7所示,SSTable中的数据按主键排序后存放在连续的数据块(Block)中,Block之间也有序。接着,存放数据块索引(Block Index),由每个Block最后一行的主键(End Key)组成,用于数据查询中的Block定位。接着,存放Bloom Filter和表格的Schema信息。最后,存放固定大小的Trailer以及Trailer的偏移位置。
图2-7 SSTable包含多个Table/Column Group

查找SSTable时,首先从Tablet的索引信息中读取SSTable Trailer的偏移位置,接着获取Trailer信息。根据Trailer中记录的信息,可以获取Block Index的大小和偏移,从而将整个Block Index加载到内存中。根据Block Index记录的每个Block的End Key,可以通过二分查找定位到查找的Block。最后将Block加载到内存中,通过二分查找Block中记录的行索引(Row Index)查找到具体某一行。本质上看,SSTable是一个两级索引结构:块索引和行索引。而整个ChunkServer是一个三级索引结构:Tablet索引、块索引和行索引。
SSTable分为两种格式:稀疏格式和稠密格式。对于稀疏格式,某些列可能存在,也可能不存在,因此每一行只存储包含实际值的列,每一列存储的内容为:<Column ID,Column Value>;而稠密格式中每一行都需要存储所有列,每一列只需要存储Column Value,不需要存储Column ID,这是因为Column ID可以从表格Schema中获取。
例如:假设有一张表格包含10列,列ID为1~10,表格中有一行的数据内容为:column_id=2 column_id =3 column_id =5 column_id =7 column_id =8 20 30 50 70 80
那么,如果采用稀疏格式存储,内容为:<2,20>,<3,30>,<5,50>,<7,70>,<8,80>;如果采用稠密格式存储,内容为:null,20,30,null,50,null,70,80,null,null。
ChunkServer中的SSTable为稠密格式,而UpdateServer中的SSTable为稀疏格式,且存储了多张表格的数据。另外,SSTable支持列组(Column Group),将同一个Column Group下的多个列的内容存储在一块。
当一个SSTable中包含多个Table/Column Group时,数据按照[table_id,column group id,row_key]的形式有序存储。另外,SSTable支持压缩功能,压缩以Block为单位。每个Block写入磁盘之前调用压缩算法执行压缩,读取时需要解压缩。用户可以自定义SSTable的压缩算法,目前支持的算法包括LZO和Snappy。
SSTable的操作接口分为写入和读取两个部分:写入类为ObSSTableWriter,读取类为ObSSTableGetter(随机读取)和ObSSTableScanner(范围查询)。
class ObSSTableWriter
{
public:
// 创建SSTable
// @param [in] schema 表格schema信息
// @param [in] path SSTable在磁盘中的路径名
// @param [in] compressor_name 压缩算法名
// @param [in] store_type SSTable格式,稀疏格式或者稠密格式
// @param [in] block_size 块大小,默认64KB
int create_sstable(const ObSSTableSchema& schema, const ObString& path, const ObString& compressor_name, const int store_type, const int64_t block_size);// 往SSTable中追加一行数据
// @param [in] row 一行SSTable数据
// @param [out] space_usage 追加完这一行后SSTable大致占用的磁盘空间
int append_row(const ObSSTableRow& row, int64_t& space_usage);// 关闭SSTable,将往磁盘中写入Block Index,Bloom Filter,Schema,Trailer等信息。
// @param [out] trailer_offset 返回SSTable的Trailer偏移量
int close_sstable(int64_t& trailer_offset); };定期合并过程将产生新的SSTable的过程如下:
- 调用create_sstable函数创建一个新的SSTable。
- 不断调用append_row函数往SSTable中追加一行一行数据。
- 调用close_sstable完成SSTable写入。
与“2.2.1 内存存储引擎”节中的MemTableIterator一样,ObSSTableGetter和ObSSTableScanner实现了迭代器接口,通过它可以不断地获取SSTable的下一个cell。
class ObIterator
{
public:
// 迭代器移动到下一个cell
int next_cell();// 获取当前cell的内容
// @param [out] cell_info 当前cell的内容,包括表名(table_id),行主键(row_key),列编号(column_id)以及列值(column_value)
int get_cell(ObCellInfo** cell_info);// 获取当前cell的内容
// @param [out] cell_info 当前cell的内容
// @param is_row_changed 是否迭代到下一行
int get_cell(ObCellInfo** cell_info, bool * is_row_changed); };OceanBase读取的数据可能来源于MemTable,也可能来源于SSTable,或者是合并多个MemTable和多个SSTable生成的结果。无论底层数据来源如何变化,上层的读取接口总是ObIterator。
2.3.2 缓存实现
ChunkServer中包含三种缓存:块缓存(Block Cache),行缓存(Row Cache)和块索引缓存(Block Index Cache)。不同缓存的底层采用相同的实现方式。
经典的LRU缓存实现包含两个部分:Hash表和LRU链表。其中,Hash表用于查找缓存中的元素,LRU链表用于淘汰。每次访问LRU缓存时,需要将被访问的元素移动到LRU链表的头部,从而避免被很快淘汰,这个过程需要锁住LRU链表。
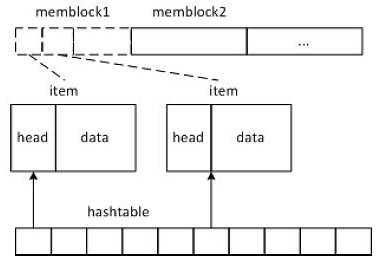
如图2-8所示,块缓存和行缓存底层都是一个Key-Value Cache,实现如下:
-
OceanBase一次分配1MB的连续内存块(称为memblock),每个memblock包含若干缓存项(item)。添加item时,只需要简单地将item追加到memblock的尾部;另外,缓存淘汰以memblock为单位,而不是以item为单位。
-
OceanBase没有维护LRU链表,而是对每个memblock都维护了访问次数和最近访问时间。淘汰memblock时,对所有的memblock按照访问次数和最近访问时间排序,淘汰访问次数少且长时间没有访问的memblock。这种实现方式通过牺牲LRU算法的精确性,来规避访问LRU链表的全局锁。
-
每个memblock维护了引用计数,读取缓存项时所在memblock的引用计数加1,淘汰memblock时引用计数减1,引用计数为0时memblock可以回收重用。通过引用计数,实现读取memblock中的缓存项不加锁。
2.3.3 IO实现
OceanBase没有使用操作系统本身的page cache机制,而是自己实现缓存。相应地,IO也采用Direct IO实现,并且支持磁盘IO与CPU计算并行化。
ChunkServer采用Linux的Libaio实现异步IO,并通过双缓冲区机制实现磁盘预读与CPU处 理并行化,步骤如下:
- 分配current以及ahead两个缓冲区,current为当前缓冲区,ahead为预读缓冲区。
- 使用current缓冲区读取数据,current缓冲区通过Libaio发起异步读取请求,接着等待异步读取完成。
- 异步读取完成后,将current缓冲区返回上层执行CPU计算,同时,原来的ahead变为新的current,发送异步读取请求将数据读取到新的current缓冲区。CPU计算完成后,原来的current缓冲区变为空闲,成为新的ahead,准备作为下一次预读的缓冲区。
- 重复“步骤3”,直到所有数据全部读完。
例如:假设需要读取的数据范围为(1, 150]。分三次读取:(1, 50], (50, 100], (100, 150],current和ahead缓冲区分别记为A和B。
- 发送异步请求将(1, 50]读取到缓冲区A,等待读取完成。
- 对缓冲区A执行CPU计算,发送异步请求,将(50, 100]读取到缓冲区B。
- 如果CPU计算先于磁盘读取完成,那么,缓冲区A变为空闲,等到(50, 100]读取完成后将缓冲区B返回上层执行CPU计算,同时,发送异步请求,将(100, 150]读取到缓冲区。
- 如果磁盘读取先于CPU计算完成,那么,首先等待缓冲区A上的CPU计算完成,接着,将缓冲区B返回上层执行CPU计算,同时,发送异步请求,将(100,150]读取到缓冲区A。
- 等待(100, 150]读取完成后,将缓冲区A返回给上层执行CPU计算。
2.3.4 定期合并
定期合并也称为每日合并,主要将UpdateServer中的增量更新分发到ChunkServer中,其主要流程如下:
-
UpdateServer冻结当前的活跃内存表(Active MemTable),生成冻结内存表,并开启新的活跃内存表。后续的更新操作都写入新的活跃内存表。
-
UpdateServer通知RootServer数据版本发生了变化。之后,RootServer通过心跳消息通知ChunkServer。
-
每台ChunkServer启动定期合并操作,从UpdateServer获取每个Tablet对应的增量更新数据。
定期合并过程中ChunkServer需要将本地SSTable中的基准数据与冻结内存表的增量更新数据执行一次多路归并,融合后生成新的基准数据并存放到新的SSTable中。定期合并对系统服务能力影响很大,往往安排在每天服务低峰期执行(例如凌晨1点开始)。
如图2-9所示,活跃内存表冻结后生成冻结内存表,后续的写操作进入新的活跃内存表。定期合并过程中ChunkServer需要读取UpdateServer中冻结内存表的数据、融合后生成新的Tablet,即:
新Tablet = 旧Tablet + 冻结内存表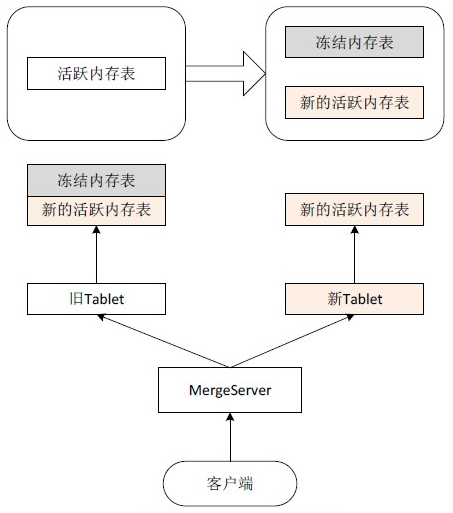
虽然定期合并过程中各个ChunkServer的各个Tablet合并时间和完成时间可能都不相同,但并不影响读取服务。如果Tablet没有合并完成,那么使用旧Tablet,并且读取UpdateServer中的冻结内存表以及新的活跃内存表;否则,使用新Tablet,只读取新的活跃内存表,即:
查询结果 = 旧Tablet + 冻结内存表 + 新的活跃内存表 = 新Tablet + 新的活跃内存表UpdateServer进行数据冻结可以分为大版本冻结和小版本冻结:假设UpdateServer中的数据版本为“111”,其允许的小版本数为“3”。在UpdateServer中会先产生一个小版本数据“111-1”,当小版本的数据达到一定大小时会进行冻结(数据大小与UpdateServer服务器内存相关),我们称为“小版本冻结”。同时将产生一个新的小版本“111-2”,以此类推。当冻结的小版本数达到UpdateServer允许的最大小版本数时,即所有小版本数据均冻结,我们称为“大版本冻结”。
当UpdateServer执行了大版本冻结时,ChunkServer将执行定期合并。ChunkServer唤醒若干个定期合并线程(比如10个),每个线程执行如下流程:
-
加锁获取下一个需要定期合并的Tablet。
-
根据Tablet的主键范围读取UpdateServer中的更新操作。
-
将每行数据的基线数据和增量数据合并后,产生新的基线数据,并写入到新的SSTable中。
-
更改Tablet索引信息,指向新的SSTable。
等到ChunkServer上所有的Tablet定期合并都执行完成后,ChunkServer会向RootServer汇报,RootServer会更新RootTable中记录的Tablet版本信息。另外,定期合并过程中ChunkServer的压力比较大,需要控制合并速度,否则可能影响正常的读取服务。
2.4 消除更新瓶颈
从表面上看,UpdateServer单点像是OceanBase架构的软肋,然而经过OceanBase团队持续不断地的性能优化以及旁路导入功能的开发,单点的架构在实践过程中经受住了线上考验。每年淘宝网“双十一”光棍节,OceanBase系统都承载着核心的数据库业务,系统访问量出现5到10倍的增长,而OceanBase只需简单地增加机器即可。
本节介绍OceanBase的优化工作,包括读写性能优化以及旁路导入功能。
2.4.1 读写优化回顾
OceanBase中的UpdateServer相当于一个内存数据库,能够支持每秒数百万次单行读写操作,这样的性能对于目前关系数据库的应用场景都是足够的。为了达到这样的性能指标,我们已经完成或正在进行的工作如下:
- 网络框架优化
在本手册的“2.2.2 任务处理模型”章节中提到,如果不经过优化,UpdateServer单机每秒最多能够接收的数据包个数只有10万个左右,而经过优化后的libeasy框架对于千兆网卡每秒最多收包个数超过50万,对于万兆网卡则超过100万。另外,UpdateServer内部还会在软件层面实现多块网卡的负载均衡,从而更好地发挥多网卡的优势。通过网络框架优化,使得单机支持百万次操作成为可能。
- 高性能内存数据结构
UpdateServer的底层是一颗高性能内存B+树。为了最大程度地发挥多核的优势,B+树实现时大部分情况下都做到了无锁(lock*free)。测试数据表明,即使在普通的16核机器上,OceanBase的B+树每秒支持的单行修改操作都超过150万次。
- 写操作日志优化
在软件层面,写操作日志涉及到的工作主要有以下三点:- Group commit。将多个写操作聚合在一起,一次性刷入磁盘中。
- 降低日志缓冲区的锁冲突。多个线程同时往日志缓冲区中追加数据,实现时需要尽可能地减少追加过程的锁冲突。追加过程包含两个阶段:第一个阶段是占位,第二个阶段是拷贝数据。相比较而言,拷贝数据比较耗时。实现的关键在于只对占位操作互斥,而允许多线程并发拷贝数据。例如,有两个线程,线程1和线程2,他们分别需要往缓冲区追加大小为100字节和大小为300字节的数据。假设缓冲区初始为空,那么,线程1可以首先占住位置0~100,线程2接着占住100~300。最后,线程1和线程2同时将数据拷贝到刚才占住的位置。
- 日志文件并发写入。UpdateServer中每个日志缓冲区的大小一般为64MB,如果写入太快,那么,很快会产生多个日志缓冲区需要刷入磁盘,可以并发地将这些日志缓冲区刷入不同的磁盘。
在硬件层面,UpdateServer机器需要配置较好的RAID卡。这些RAID卡自带缓存,而且容量比较大(例如1GB),从而进一步提升写磁盘性能。
- 内存容量优化
随着数据不断写入,UpdateServer的内存容量将成为瓶颈。因此,有两种解决思路。第一种思路是精心设计UpdateServer的内存数据结构,尽可能地节省内存使用;另外一种思路就是将UpdateServer内存中的数据很快地分发出去。
OceanBase实现了这两种思路。首先,UpdateServer会将内存中的数据编码为精心设计的格式。例如,100以内的64位整数在内存中只需要占用两个字节。这种编码格式不仅能够有效地减少内存占用,而且往往使得CPU缓存能够容纳更多的数据。因此,也不会造成太多额外的CPU消耗。另外,当UpdateServer的内存使用量到达一定大小时,OceanBase会触发数据合并操作,将UpdateServer的数据分发到集群中的ChunkServer中,从而避免UpdateServer的内存容量成为瓶颈。
2.4.2 数据旁路导入
虽然OceanBase内部实现了大量优化技术,但是UpdateServer单点写入对于某些OLAP应用仍然可能成为问题。这些应用往往需要定期(例如每天、每月)导入大批数据,对导入性能要求很高。为此,OceanBase专门开发了旁路导入功能,本节介绍直接将数据导入到ChunkServer中的方法。
OceanBase的数据按照全局有序排列,因此,ChunkServer旁路导入的过程如下:
- 使用工具(例如:Hadoop MapReduce)将所有的数据排序,并且划分为一个一个有序的范围,每个范围对应一个SSTable文件。
- 将SSTable文件并行拷贝到集群内所有的ChunkServer中。
- 通过RootServer要求每个ChunkServer并行加载这些SSTable文件。每个SSTable文件对应ChunkServer的一个子表。
- ChunkServer加载完本地的SSTable文件后向RootServer汇报,RootServer接着将汇报的子表信息更新到RootTable中。
例如:有4台ChunkServer分别为A、B、C和D。所有的数据排好序后划分为6个范围:r1(0~100],r2(100~200],r3(200~300],r4(300~400],r5(400~500],r6(500~600],对应的SSTable文件分别记为sst1,sst2,…,sst6。
- 假设每个子表存储两个副本,那么,拷贝完SSTable文件后,可能的分布情况为:
A:sst1,sst3,sst4
B:sst2,sst3,sst5
C:sst1,sst4,sst6
D:sst2,sst5,sst6 - 接着,每个ChunkServer分别加载本地的SSTable文件,完成后向RootServer汇报。RootServer最终会将这些信息记录到RootTable中,如下:
r1(0~100]:A、C
r2(100~200]:B、D
r3(200~300]:A、B
r4(300~400]:A、C
r5(400~500]:B、D
r6(500~600]:C、D - 如果导入的过程中ChunkServer发生故障,例如拷贝sst1到机器C失败,那么,旁路导入模块会自动选择另外一台机器拷贝数据。
当然,实现旁路导入功能时还需要考虑很多问题。例如:如何支持将数据导入到多个数据中心的主备OceanBase集群等。
2.5 实现技巧
OceanBase开发过程中使用了一些小技巧,这些技巧说起来相当朴实,却实实在在地解决了当时面临的问题。本节通过几个例子介绍开发过程中用到的实现技巧。
2.5.1 内存管理
内存管理是C++高性能服务器的核心问题。一些通用的内存管理库,比如Google TCMalloc在内存申请/释放速度、小内存管理、锁开销等方面都已经做得相当卓越了,然而,我们并没有采用。这是因为,通用内存管理库在性能上毕竟不如专用的内存池,更为严重的是,它鼓励了开发人员忽视内存管理的陋习,比如在服务器程序中滥用C++标准模板库(STL)。
在分布式存储系统开发初期,内存相关的Bug相当常见,比如内存越界,服务器出现Core Dump,这些Bug都非常难以调试。因此,这个时期内存管理的首要问题并不是高效,而是可控性,并防止内存碎片。
OceanBase系统有一个全局的定长内存池,这个内存池维护了由64KB大小的定长内存块组成的空闲链表。
-
如果申请的内存不超过64KB,则尝试从空闲链表中获取一个64KB的内存块返回给申请者。如果空闲链表为空,则先从操作系统中申请一批大小为64KB的内存块加入空闲链表。释放时将64KB的内存块加入到空闲链表中以便下次重用。
-
如果申请的内存超过64KB,则直接调用Glibc的malloc函数,向操作系统申请用户所需大小的内存块。释放时直接调用Glibc的free函数,将内存块归还操作系统。
OceanBase的全局内存池实现简单,但内存使用率比较低,即使申请几个字节的内存,也需要占用大小为64KB的内存块。因此,全局内存池不适合管理小块内存,每个需要申请内存的模块,比如UpdateServer中的MemTable,ChunkServer中的缓存等,都只能从全局内存池中申请大块内存,每个模块内部再实现专用的内存池。每个线程处理读写请求时需要使用临时内存,为了提高效率,每个线程会缓存若干个大小分别为64KB和2MB的内存块,每个线程总是首先尝试从线程局部缓存中申请内存,如果申请不到,则再从全局内存池中申请。
全局内存池的意义如下:
-
全局内存池可以统计每个模块的内存使用情况。如果出现内存泄露,可以很快定位到发生问题的模块。
-
全局内存池可用于辅助调试。例如,可以将全局内存池中申请到的内存块按字节填充为某个非法的值(比如0xFE),当出现内存越界等问题时,服务器程序会很快在出现问题的位置Core Dump,而不是带着错误运行一段时间后才Core Dump,从而方便问题定位。
总而言之,OceanBase的内存管理没有采用高深的技术,也没有做到通用或者最优,但是很好地满足了系统初期的两个最主要的需求:可控性以及没有内存碎片。
2.5.2 成组提交
为了提高写性能,UpdateServer会将多个写操作的日志组成一批,一次性写到日志文件中,这种技术称为成组提交(Group Commit)。
考虑如下模型:生产者不断地将写任务加入到任务队列中,有一个批处理线程从任务队列中每次取一批写任务进行批量处理。由于写操作的时间消耗主要在于写日志文件,批处理1个写任务与批处理10个写任务花费的时间相差不大。因此,批处理线程总是尽量提高一次处理的任务数。假设一批任务最多包含1024个,常见的Group Commit做法为:批处理线程尝试从任务队列中取出1024个任务,如果队列中任务不够,那么等待一段时间(比如5ms),直到取到1024个任务或者超时为止。
这种做法的问题在于延时,当系统比较空闲时,批处理线程经常需要额外等待一段时间。然而仔细观察可以发现,这里其实是不需要等待的。如果批处理线程前一次处理的任务数较少,下一次任务队列中自然会积攒较多的任务,相应地,批处理线程也能处理得更快。
例如:假设生产者每隔1ms会往任务队列中加入一个新的任务,批处理线程处理1个任务和10个任务的时间都是5ms。
- 方式1(等待 5ms):5ms的时候开始处理第一批共5个任务,10ms的时候处理完成。接着等待5ms,直到15ms的时候开始处理第二批任务共10个任务,25ms的时候处理完成。依次类推。
- 方式2(不等待):1ms的时候开始处理第一批共1个任务,6ms的时候处理完成。接着开始处理第二批共5个任务,11ms的时候处理完成。依次类推。
“方式1”每隔10ms处理10个任务,“方式2”每隔5ms处理5个任务。无论采用哪种方式,批处理线程的处理能力为1ms一个任务,与生产者产生任务的速率相同。“方式1”和“方式2”处理的并发数相同,而“方式2”的任务响应时间更短。
2.5.3 双缓冲区
双缓冲区广泛用于“生产者/消费者”模型。ChunkServer中使用了双缓冲区异步预读的技术,生产者为磁盘,消费者为CPU,磁盘中生产的原始数据需要给CPU计算消费掉。
所谓“双缓冲区”,顾名思义就是两个缓冲区(假设为A和B)。这两个缓冲区,总是一个用于生产者,一个用于消费者。当两个缓冲区都操作完,再进行一次切换,先前被生产者写入的被消费者读取,先前消费者读取的转为生产者写入。为了做到不冲突,给每个缓冲区分配一把互斥锁(假设为La和Lb)。生产者或者消费者如果要操作某个缓冲区,必须先拥有对应的互斥锁。
双缓冲区包括如下几种状态:
-
双缓冲区都在使用的状态(并发读写)
大多数情况下,生产者和消费者都处于并发读写状态。不妨设生产者写入A,消费者读取B。在这种状态下,生产者拥有锁La;同样地,消费者拥有锁Lb。由于俩缓冲区都是处于独占状态,因此每次读写缓冲区中的元素都不需要再进行加锁、解锁操作。这是节约开销的主要来源。 -
单个缓冲区空闲状态
由于两个并发实体的速度会有差异,必然会出现一个缓冲区已经操作完,而另一个尚未操作完。不妨假设生产者快于消费者。在这种情况下,当生产者把A写满的时候,生产者要先释放La(表示它已经不再操作A),然后尝试获取Lb。由于B还没有被读空,Lb还被消费者持有,所以生产者进入等待(wait)状态。 -
缓冲区的切换
过了若干时间,消费者终于把B读完。这时候,消费者也要先释放Lb,然后尝试获取La。由于La刚才已经被生产者释放,所以消费者能立即拥有La并开始读取A的数据。而由于Lb被消费者释放,所以刚才等待的生产者会苏醒过来(wakeup)并拥有Lb,然后生产者继续往B写入数据。
2.5.4 定期合并限速
定期合并期间系统的压力较大,需要控制定期合并的速度,避免影响正常服务。定期合并限速的措施包括:
-
ChunkServer:ChunkServer定期合并过程中,每合并完成若干行(默认2000行)数据,就查看本机的负载(查看Linux系统的Load值)。如果负载过高,一部分定期合并线程转入休眠状态;如果负载过低,唤醒更多的定期合并线程。另外,RootServer将UpdateServer冻结的大版本通知所有的ChunkServer,每台ChunkServer会随机等待一段时间再开始执行定期合并,防止所有的ChunkServer同时将大量的请求发给UpdateServer。
-
UpdateServer:定期合并过程中ChunkServer需要从UpdateServer读取大量的数据,为了防止定期合并任务占满带宽而阻塞用户的正常请求,UpdateServer将任务区分为高优先级(用户正常请求)和低优先级(定期合并任务),并单独统计每种任务的输出带宽。如果低优先级任务的输出带宽超过上限,降低低优先级任务的处理速度;反之,适当提高低优先级任务的处理速度。
如果OceanBase部署了两个集群,还能够支持主备集群在不同时间段进行“错峰合并”:一个集群执行定期合并时,把全部或大部分读写流量切到另一个集群。该集群合并完成后,把全部或大部分流量切回,以便另一个集群接着进行定期合并。两个集群都合并完成后,恢复正常的流量分配。
2.5.5 缓存预热
UpdateServer中的Frozen MemTable将会以SSTable的形式转储到SSD盘中。如果内存不够需要丢弃Frozen MemTable,则大量请求只能读取SSD盘,UpdateServer性能将大幅下降。因此,希望能够在丢弃Frozen MemTable之前将SSTable的缓存预热。
UpdateServer的缓存预热机制实现如下:在丢弃Frozen MemTable之前的一段时间(比如10分钟),每隔一段时间(比如30秒),将一定比率(比如5%)的请求发给SSTable,而不是Frozen MemTable。这样,SSTable上的读请求将从5%到10%,再到15%,依次类推,直到100%,很自然地实现了缓存预热。
另外,ChunkServer定期合并后需要使用生成的新的SSTable提供服务,这里也需要缓存预热。OceanBase最初的版本实现了主动缓存预热:扫描原来的缓存,根据每个缓存项的key读取新的SSTable并将结果加入到新的缓存中。例如,原来缓存数据项的主键分别为100、200、500,那么只需要从新的SSTable中读取主键为100、200、500的数据并加入新的缓存。扫描完成后,原来的缓存可以丢弃。
线上运行一段时间后发现,定期合并基本上都安排在凌晨业务低峰期,合并完成后OceanBase集群收到的用户请求总是由少到多(早上7点之前请求很少,9点以后请求逐步增多),能够很自然地实现被动缓存预热。由于ChunkServer在主动缓存预热期间需要占用两倍的内存,因此,目前的线上版本放弃了这种方式,转而采用被动缓存预热。















 342
342











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









