






卷积神经网络分类实战
基于唐宇迪老师的神经网络课程,初步实现课堂上的神经网络构建。
1.torchvision
torchvision是pytorch的一个图形库,它服务于PyTorch深度学习框架的,主要用来构建计算机视觉模型。
torchvision.datasets: 加载数据的函数及常用的数据集的接口;
torchvision.models: 包含有模型架构,例如AlexNet、VGG、ResNet等;
torchvision.transforms: 常用的图片变换,例如裁剪、旋转等功能;
torchvision.utils: 其他的一些有用的方法。
搜索数据模型的方法是:进入如下网站
torchvision — Torchvision 0.13 documentation (pytorch.org)
找到Docs模块[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传
下拉到torchvision模块,点击其中的模块即可进入。
1)安装torchvison模块
在命令行输入pip install torchvision
2)datasets模块
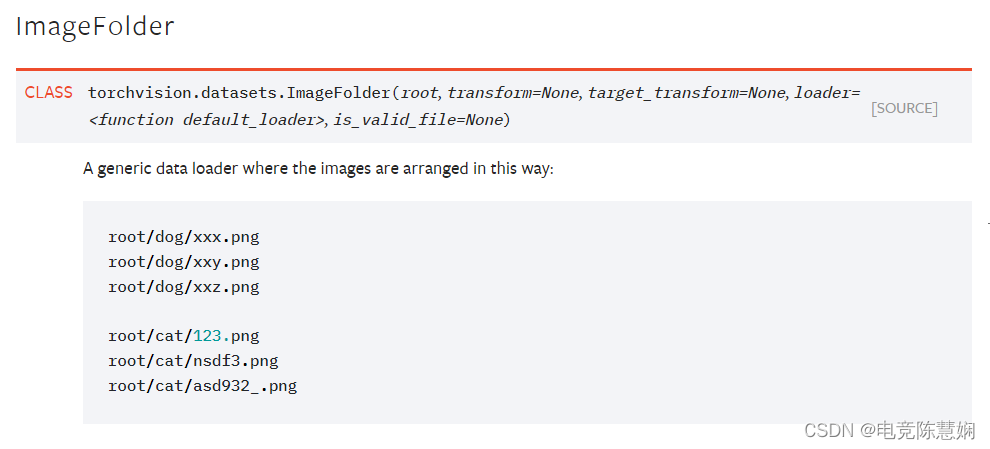
数据存放模式如上,将分类任务按上述存放方式存放在根文件夹下。
根文件夹下创建一个data文件夹,在文件夹的子目录中创建train和test文件夹,在train和test文件夹中分别创建不同的类型的文件夹,文件夹中放置同种类型的图片。
2.分类实战
1)引用库
import os
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
import torch
from torch import nn
import torch.optim as optim
import torchvision
#pip install torchvision
from torchvision import transforms, models, datasets
#https://pytorch.org/docs/stable/torchvision/index.html
import imageio
import time
import warnings
import random
import sys
import copy
import json
from PIL import Image
2)数据预处理
①引用路径

如下图,在建立如下文件,需要分类的花的数据文件存放在flower文件下。
data_dir = './flower_data/'#定义根目录
train_dir = data_dir + '/train'#训练集路径
valid_dir = data_dir + '/valid'#测试集路径
②数据增强
数据增强是将现有数据,经过翻转,旋转,对称等方式将图片的数量增加,从而更高效地利用数据。下列进行数据的变换。
训练集数据增强的方法有:
1.随机旋转 transforms.Compose:为保证数据的正确性,旋转的方式注重随机性。
2.从中心裁剪 transforms.CenterCrop(x):从中心裁剪操作是将原本nn的图形类型从中心裁剪为xx的图形类型。(也可以采用随机裁剪)
3.随机水平翻转transforms.RandomHorizontalFlip(p):有p的概率进行水平翻转
4.随机垂直翻转transforms.RandomVerticalFlip§
5.颜色变化transforms.ColorJitter,参数定义如下代码中所示
6.转为灰度图概率transforms.RandomGrayscale§
在完成变换后进行数据类型的转换,需要将数据转换成Tensor模式。
为使得数据处理效果更好,进行数据的标准化操作,数据的标准化可采用已经过测试的均值与标准差进行标准化,如下:transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])#均值,标准差.
data_transforms = {
'train': transforms.Compose([transforms.RandomRotation(45),#随机旋转,-45到45度之间随机选
transforms.CenterCrop(224),#从中心开始裁剪
transforms.RandomHorizontalFlip(p=0.5),#随机水平翻转 选择一个概率概率
transforms.RandomVerticalFlip(p=0.5),#随机垂直翻转
transforms.ColorJitter(brightness=0.2, contrast=0.1, saturation=0.1, hue=0.1),#参数1为亮度,参数2为对比度,参数3为饱和度,参数4为色相
transforms.RandomGrayscale(p=0.025),#概率转换成灰度率,3通道就是R=G=B
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])#均值,标准差
]),
'valid': transforms.Compose([transforms.Resize(256),#将大小不一的图片先转为同一规格
transforms.CenterCrop(224),#中心裁剪
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])#与训练集保持一致
]),
}
测试集预处理:
测试集预处理无需进行数据增强操作,将测试集数据进行裁剪标准化即可完成测试集数据处理。
③传入数据
1.首先,定义数据的batch批大小
batch_size = 8
2.分类任务数据集构建
image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x), data_transforms[x]) for x in ['train', 'valid']}
利用datasets.ImageFolder模块,参数os.path.join(data_dir, x)表示文件夹的位置,data_transforms[x]表示预处理方案(上一步中定义好的)
3.按batch取数据
dataloaders = {x: torch.utils.data.DataLoader(image_datasets[x], batch_size=batch_size, shuffle=True) for x in ['train', 'valid']}
采用dataloader模块进行数据集的存取。
还记得上一章中的Shuffle参数的定义吗?
这个参数表示的是是否洗牌操作。
4.计算数据集大小以及分类名称
dataset_sizes = {x: len(image_datasets[x]) for x in ['train', 'valid']}
class_names = image_datasets['train'].classes
5.定义类别对应的名称
with open('cat_to_name.json', 'r') as f:
cat_to_name = json.load(f)
首先定义一个json文件,在其中存放类别的名称,如下所示。
{“21”: “fire lily”, “3”: “canterbury bells”, “45”: “bolero deep blue”, “1”: “pink primrose”, “34”: “mexican aster”, “27”: “prince of wales feathers”, “7”: “moon orchid”, “16”: “globe-flower”, “25”: “grape hyacinth”, “26”: “corn poppy”, “79”: “toad lily”, “39”: “siam tulip”, “24”: “red ginger”, “67”: “spring crocus”, “35”: “alpine sea holly”, “32”: “garden phlox”, “10”: “globe thistle”, “6”: “tiger lily”, “93”: “ball moss”, “33”: “love in the mist”, “9”: “monkshood”, “102”: “blackberry lily”, “14”: “spear thistle”, “19”: “balloon flower”, “100”: “blanket flower”, “13”: “king protea”, “49”: “oxeye daisy”, “15”: “yellow iris”, “61”: “cautleya spicata”, “31”: “carnation”, “64”: “silverbush”, “68”: “bearded iris”, “63”: “black-eyed susan”, “69”: “windflower”, “62”: “japanese anemone”, “20”: “giant white arum lily”, “38”: “great masterwort”, “4”: “sweet pea”, “86”: “tree mallow”, “101”: “trumpet creeper”, “42”: “daffodil”, “22”: “pincushion flower”, “2”: “hard-leaved pocket orchid”, “54”: “sunflower”, “66”: “osteospermum”, “70”: “tree poppy”, “85”: “desert-rose”, “99”: “bromelia”, “87”: “magnolia”, “5”: “english marigold”, “92”: “bee balm”, “28”: “stemless gentian”, “97”: “mallow”, “57”: “gaura”, “40”: “lenten rose”, “47”: “marigold”, “59”: “orange dahlia”, “48”: “buttercup”, “55”: “pelargonium”, “36”: “ruby-lipped cattleya”, “91”: “hippeastrum”, “29”: “artichoke”, “71”: “gazania”, “90”: “canna lily”, “18”: “peruvian lily”, “98”: “mexican petunia”, “8”: “bird of paradise”, “30”: “sweet william”, “17”: “purple coneflower”, “52”: “wild pansy”, “84”: “columbine”, “12”: “colt’s foot”, “11”: “snapdragon”, “96”: “camellia”, “23”: “fritillary”, “50”: “common dandelion”, “44”: “poinsettia”, “53”: “primula”, “72”: “azalea”, “65”: “californian poppy”, “80”: “anthurium”, “76”: “morning glory”, “37”: “cape flower”, “56”: “bishop of llandaff”, “60”: “pink-yellow dahlia”, “82”: “clematis”, “58”: “geranium”, “75”: “thorn apple”, “41”: “barbeton daisy”, “95”: “bougainvillea”, “43”: “sword lily”, “83”: “hibiscus”, “78”: “lotus lotus”, “88”: “cyclamen”, “94”: “foxglove”, “81”: “frangipani”, “74”: “rose”, “89”: “watercress”, “73”: “water lily”, “46”: “wallflower”, “77”: “passion flower”, “51”: “petunia”}
④展示数据
3)迁移学习
目标
将某个领域或任务上学习到的知识或模式应用到不同但相关的领域或问题中。
主要思想
从相关领域中迁移标注数据或者知识结构、完成或改进目标领域或任务的学习效果。
注意点
需要将自身数据与已有的迁移数据用有一样的数据类型,数据模式等
①迁移学习的两种方案
1.直接迁移开源的已有的卷积层
在数据量较小时,直接迁移原有卷积层。(数据量<1w)
2.利用开源的已有的卷积层的权重偏移量作为初始化权重偏移量
②model迁移学习
model_name = 'resnet' #可选的比较多 ['resnet', 'alexnet', 'vgg', 'squeezenet', 'densenet', 'inception']
#是否用人家训练好的特征来做
feature_extract = True #使用模块权重进行训练
首先引入网络模型,Resnet模型是最近图像识别技术中比较热门完善的模型之一。
# 是否用GPU训练
train_on_gpu = torch.cuda.is_available()
if not train_on_gpu:
print('CUDA is not available. Training on CPU ...')
else:
print('CUDA is available! Training on GPU ...')
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
采用GPU训练的方式,若有GPU则采用GPU进行训练。
def set_parameter_requires_grad(model, feature_extracting):
if feature_extracting:
for param in model.parameters():
param.requires_grad = False#无需迭代
迁移学习
model_ft = models.resnet152()#152层网络
model_ft
导入152层的网络架构(已有模型,1000分类的全连接分类)
导入resnet模型。
def initialize_model(model_name, num_classes, feature_extract, use_pretrained=True):
# 选择合适的模型,不同模型的初始化方法稍微有点区别
model_ft = None
input_size = 0
if model_name == "resnet":
""" Resnet152
"""
model_ft = models.resnet152(pretrained=use_pretrained)#自动下载模型
set_parameter_requires_grad(model_ft, feature_extract)
num_ftrs = model_ft.fc.in_features#读取输出数据
model_ft.fc = nn.Sequential(nn.Linear(num_ftrs, 102),#将最后一层全连接层改为102分类
nn.LogSoftmax(dim=1))
input_size = 224
模型从官网导入,在数据量较小的情况下,只需要修改最后的一层全连接层,若是分类任务,则将全连接层输出任务数量改为分类数量。
model_ft, input_size = initialize_model(model_name, 102, feature_extract, use_pretrained=True)
#GPU计算
model_ft = model_ft.to(device)
# 模型保存
filename='checkpoint.pth'#读取模型保存
# 是否训练所有层
params_to_update = model_ft.parameters()
print("Params to learn:")
if feature_extract:
params_to_update = []
for name,param in model_ft.named_parameters():
if param.requires_grad == True:
params_to_update.append(param)
print("\t",name)
else:
for name,param in model_ft.named_parameters():
if param.requires_grad == True:
print("\t",name)
③优化器设置
# 优化器设置
optimizer_ft = optim.Adam(params_to_update, lr=1e-2)#优化器
scheduler = optim.lr_scheduler.StepLR(optimizer_ft, step_size=7, gamma=0.1)#学习率每7个epoch衰减成原来的1/10
#最后一层已经LogSoftmax()了,所以不能nn.CrossEntropyLoss()来计算了,nn.CrossEntropyLoss()相当于logSoftmax()和nn.NLLLoss()整合
criterion = nn.NLLLoss()#损失率
学习率及学习率衰减函数设置。
④训练模块
def train_model(model, dataloaders, criterion, optimizer, num_epochs=25, is_inception=False,filename=filename):
since = time.time()
best_acc = 0#保存最好的结果
"""
checkpoint = torch.load(filename)
best_acc = checkpoint['best_acc']
model.load_state_dict(checkpoint['state_dict'])
optimizer.load_state_dict(checkpoint['optimizer'])
model.class_to_idx = checkpoint['mapping']
"""
model.to(device)
val_acc_history = []
train_acc_history = []
train_losses = []
valid_losses = []
LRs = [optimizer.param_groups[0]['lr']]#学习率
best_model_wts = copy.deepcopy(model.state_dict())#将最好一次存下来
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch, num_epochs - 1))
print('-' * 10)
# 训练和验证
for phase in ['train', 'valid']:
if phase == 'train':
model.train() # 训练
else:
model.eval() # 验证
running_loss = 0.0
running_corrects = 0
# 把数据都取个遍
for inputs, labels in dataloaders[phase]:
inputs = inputs.to(device)
labels = labels.to(device)#转为GPU
# 清零
optimizer.zero_grad()
# 只有训练的时候计算和更新梯度
with torch.set_grad_enabled(phase == 'train'):
if is_inception and phase == 'train':#resnet不执行
outputs, aux_outputs = model(inputs)
loss1 = criterion(outputs, labels)
loss2 = criterion(aux_outputs, labels)
loss = loss1 + 0.4*loss2
else:#resnet执行的是这里
outputs = model(inputs)
loss = criterion(outputs, labels)
_, preds = torch.max(outputs, 1)
# 训练阶段更新权重
if phase == 'train':
loss.backward()
optimizer.step()
# 计算损失
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
epoch_loss = running_loss / len(dataloaders[phase].dataset)
epoch_acc = running_corrects.double() / len(dataloaders[phase].dataset)
time_elapsed = time.time() - since
print('Time elapsed {:.0f}m {:.0f}s'.format(time_elapsed // 60, time_elapsed % 60))
print('{} Loss: {:.4f} Acc: {:.4f}'.format(phase, epoch_loss, epoch_acc))
# 得到最好那次的模型
if phase == 'valid' and epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = copy.deepcopy(model.state_dict())#复制最好参数
state = {
'state_dict': model.state_dict(),
'best_acc': best_acc,
'optimizer' : optimizer.state_dict(),
}
torch.save(state, filename)
if phase == 'valid':
val_acc_history.append(epoch_acc)
valid_losses.append(epoch_loss)
scheduler.step(epoch_loss)
if phase == 'train':
train_acc_history.append(epoch_acc)
train_losses.append(epoch_loss)
print('Optimizer learning rate : {:.7f}'.format(optimizer.param_groups[0]['lr']))
LRs.append(optimizer.param_groups[0]['lr'])
print()
time_elapsed = time.time() - since
print('Training complete in {:.0f}m {:.0f}s'.format(time_elapsed // 60, time_elapsed % 60))
print('Best val Acc: {:4f}'.format(best_acc))
# 训练完后用最好的一次当做模型最终的结果
model.load_state_dict(best_model_wts)
return model, val_acc_history, train_acc_history, valid_losses, train_losses, LRs
⑤开始训练
model_ft, val_acc_history, train_acc_history, valid_losses, train_losses, LRs = train_model(model_ft, dataloaders, criterion, optimizer_ft, num_epochs=20, is_inception=(model_name=="inception"))
⑥再次训练
由于训练过程使用的是已经训练好的参数,在此基础之上应该训练自己的图像参数。
for param in model_ft.parameters():
param.requires_grad = True
# 再继续训练所有的参数,学习率调小一点
optimizer = optim.Adam(params_to_update, lr=1e-4)
scheduler = optim.lr_scheduler.StepLR(optimizer_ft, step_size=7, gamma=0.1)
# 损失函数
criterion = nn.NLLLoss()
# Load the checkpoint
checkpoint = torch.load(filename)
best_acc = checkpoint['best_acc']
model_ft.load_state_dict(checkpoint['state_dict'])
optimizer.load_state_dict(checkpoint['optimizer'])
#model_ft.class_to_idx = checkpoint['mapping']
model_ft, val_acc_history, train_acc_history, valid_losses, train_losses, LRs = train_model(model_ft, dataloaders, criterion, optimizer, num_epochs=10, is_inception=(model_name=="inception"))
⑦利用训练好的模型进行测试
1)加载训练好的模型
model_ft, input_size = initialize_model(model_name, 102, feature_extract, use_pretrained=True)#加载训练好的模型
# GPU模式
model_ft = model_ft.to(device)
# 保存文件的名字
filename='seriouscheckpoint.pth'
# 加载模型
checkpoint = torch.load(filename)
best_acc = checkpoint['best_acc']
model_ft.load_state_dict(checkpoint['state_dict'])















 631
631











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









