







Knime简介
一接触数据挖掘,用的就是Knime,什么Weka,SPSS,SAS基本都只限于听说过而已-_-.由于是基于eclipse的,对我来说自然是十分亲切,所以用起来也十分顺手,用了也有一段时间,打算做个阶段性小结,也顺便提高自己。
Knime 是基于 Eclipse 的开源数据挖掘软件,它通过工作流的方式来完成数据仓库以及数据挖掘中数据的抽取 - 转换 - 加载( E xtract- T ransform- L oad )操作。其中工作流又是由各个功能便利的结点来完成,节点之间相互独立,可以单独执行并将执行后的数据传给下一个结点。界面如下:
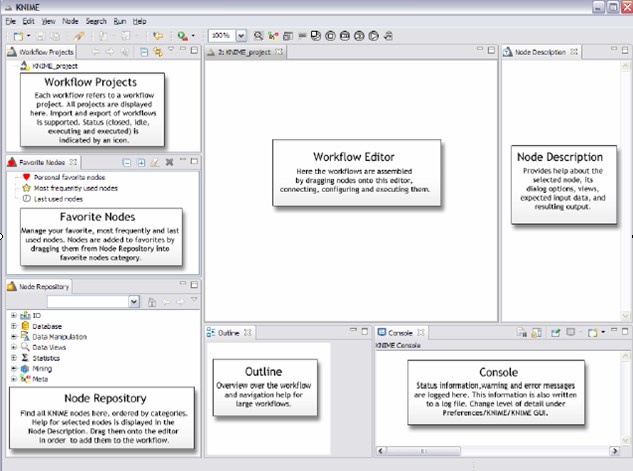
将左下角 Node Repository 区域的结点以此拖入中间的 Worflow Editor 形成工作流:
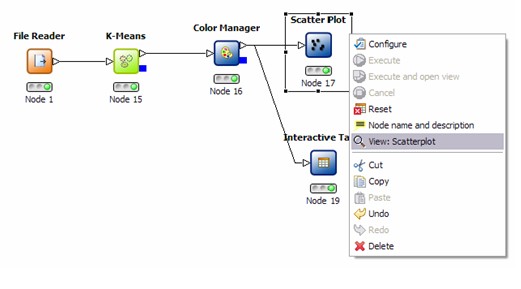
结点的状态:
结点上有三盏灯,就像红黄绿交通灯一样。当结点刚被拖入工作区的时候,红灯亮起表示数据无法通过,这时需要对结点进行配置,让它可以执行。右键单击结点选择“ Configure ”对结点进行配置;配置完成并且正确的话,便会亮起黄灯,表示准备就绪数据可以通过;再次右键单击结点选择“ Execute ”运行这个结点,当绿灯亮起时表示结点执行成功,数据已经通过并传给下一个结点。
结点分类,一共有以下几类结点:
1、IO类结点,用于文件、表格、数据模型的输入和输出操作;
2、数据库操作类结点,通过JDBC驱动对数据库进行操作;
3、数据操作类结点,对上一结点传进来的数据进行筛选、变换以及简单的统计学计算等操作;
4、数据视图类结点,提供了数据挖掘中最常用的表格及图形的展示,包括盒图,饼图,直方图,数据曲线等;
5、统计学模型类结点,封装了统计学模型算法类的结点,如线性回归、多项式回归等;
6、数据挖掘模型类结点,提供了贝叶斯分析,聚类分析,决策树,神经网络等主要的DM分类模型以及相应的预测器;
7、META原子结点,该类结点可以对任意的及结点进行嵌套封装,还提供了后向传播、迭代、循环、交叉验证等方法;
8、其他,可供我们自定义java代码段,以及设置规则引擎。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









