




 本文详细介绍了MapReduce的基本用法,包括自定义序列化、排序、分区、分组和TopN的操作,通过实例展示了如何在MapReduce中实现这些功能。
本文详细介绍了MapReduce的基本用法,包括自定义序列化、排序、分区、分组和TopN的操作,通过实例展示了如何在MapReduce中实现这些功能。
Hadoop系列文章目录
1、hadoop3.1.4简单介绍及部署、简单验证
2、HDFS操作 - shell客户端
3、HDFS的使用(读写、上传、下载、遍历、查找文件、整个目录拷贝、只拷贝文件、列出文件夹下文件、删除文件及目录、获取文件及文件夹属性等)-java
4、HDFS-java操作类HDFSUtil及junit测试(HDFS的常见操作以及HA环境的配置)
5、HDFS API的RESTful风格–WebHDFS
6、HDFS的HttpFS-代理服务
7、大数据中常见的文件存储格式以及hadoop中支持的压缩算法
8、HDFS内存存储策略支持和“冷热温”存储
9、hadoop高可用HA集群部署及三种方式验证
10、HDFS小文件解决方案–Archive
11、hadoop环境下的Sequence File的读写与合并
12、HDFS Trash垃圾桶回收介绍与示例
13、HDFS Snapshot快照
14、HDFS 透明加密KMS
15、MapReduce介绍及wordcount
16、MapReduce的基本用法示例-自定义序列化、排序、分区、分组和topN
17、MapReduce的分区Partition介绍
18、MapReduce的计数器与通过MapReduce读取/写入数据库示例
19、Join操作map side join 和 reduce side join
20、MapReduce 工作流介绍
21、MapReduce读写SequenceFile、MapFile、ORCFile和ParquetFile文件
22、MapReduce使用Gzip压缩、Snappy压缩和Lzo压缩算法写文件和读取相应的文件
23、hadoop集群中yarn运行mapreduce的内存、CPU分配调度计算与优化
本文介绍MapReduce常见的基本用法。
前提是hadoop环境可正常运行。
本文分为五个部分,即介绍自定义序列化、排序、分区、分组和topN。
一、pom.xml与测试数据说明、日志配置
1、pom.xml
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.22</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.1.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>3.1.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>3.1.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>3.1.4</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.springframework/spring-core -->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-core</artifactId>
<version>2.5.6</version>
</dependency>
2、数据字段说明
date(日期),county(县),state(州),fips(县编码code),cases(累计确诊病例),deaths(累计死亡病例)

3、日志配置
log4j.properties文件放在resources目录下。log4j.properties内容如下:
# Define some default values that can be overridden by system properties
hadoop.root.logger=INFO,console
hadoop.log.dir=.
hadoop.log.file=hadoop.log
# Define the root logger to the system property "hadoop.root.logger".
log4j.rootLogger=${hadoop.root.logger}, EventCounter
# Logging Threshold
log4j.threshold=ALL
# Null Appender
log4j.appender.NullAppender=org.apache.log4j.varia.NullAppender
#
# Rolling File Appender - cap space usage at 5gb.
#
hadoop.log.maxfilesize=256MB
hadoop.log.maxbackupindex=20
log4j.appender.RFA=org.apache.log4j.RollingFileAppender
log4j.appender.RFA.File=${hadoop.log.dir}/${hadoop.log.file}
log4j.appender.RFA.MaxFileSize=${hadoop.log.maxfilesize}
log4j.appender.RFA.MaxBackupIndex=${hadoop.log.maxbackupindex}
log4j.appender.RFA.layout=org.apache.log4j.PatternLayout
# Pattern format: Date LogLevel LoggerName LogMessage
log4j.appender.RFA.layout.ConversionPattern=%d{ISO8601} %p %c: %m%n
# Debugging Pattern format
# Daily Rolling File Appender
#
log4j.appender.DRFA=org.apache.log4j.DailyRollingFileAppender
log4j.appender.DRFA.File=${hadoop.log.dir}/${hadoop.log.file}
# Rollover at midnight
log4j.appender.DRFA.DatePattern=.yyyy-MM-dd
log4j.appender.DRFA.layout=org.apache.log4j.PatternLayout
# Pattern format: Date LogLevel LoggerName LogMessage
log4j.appender.DRFA.layout.ConversionPattern=%d{ISO8601} %p %c: %m%n
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.err
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{ISO8601} %p %c{2}: %m%n
#
# TaskLog Appender
#
log4j.appender.TLA=org.apache.hadoop.mapred.TaskLogAppender
log4j.appender.TLA.layout=org.apache.log4j.PatternLayout
log4j.appender.TLA.layout.ConversionPattern=%d{ISO8601} %p %c: %m%n
log4j.appender.EventCounter=org.apache.hadoop.log.metrics.EventCounter
二、序列化
1、需求
统计美国2021-01-28,每个州state累计确诊案例数、累计死亡案例数
2、实现说明
自定义对象CovidBean,用于封装每个州的确诊病例数和死亡病例数。
以州作为map阶段输出的key,以CovidBean作为value,这样属于同一个州的数据就会变成一组进行reduce处理,进行累加即可得出每个州累计确诊病例。
3、实现
1)、bean
import org.apache.hadoop.io.Writable;
import lombok.Data;
@Data
public class CovidBean implements Writable {
private String state;
private long cases;
private long deaths;
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(state);
out.writeLong(cases);
out.writeLong(deaths);
}
@Override
public void readFields(DataInput in) throws IOException {
this.state = in.readUTF();
this.cases = in.readLong();
this.deaths = in.readLong();
}
public String toString() {
return this.cases + "," + this.deaths;
}
}
2)、Mapper
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.hadoop.mr.covid.bean.CovidBean;
//KEYIN, VALUEIN, KEYOUT, VALUEOUT
public class EachStateMapper extends Mapper<LongWritable, Text, Text, CovidBean> {
Text outKey = new Text();
CovidBean outValue = new CovidBean();
// 2021-01-28,Autauga,Alabama,01001,5554,69
/**
* LongWritable key 行的偏移量
* Text value 每行值
* Context context 上下文
*/
@Override
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//根据每行的数据标志进行截取
String values[] = value.toString().split(",");
//输出key赋值
outKey.set(values[2]);
//输出value赋值
outValue.setState(values[2]);
outValue.setCases(Long.parseLong(values[values.length - 2]));
outValue.setDeaths(Long.parseLong(values[values.length - 1]));
//将输出key-value输出
context.write(outKey, outValue);
}
}
3)、Reducer
import java.io.IOException;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import org.hadoop.mr.covid.bean.CovidBean;
//KEYIN,VALUEIN,KEYOUT,VALUEOUT
public class EachStateReducer extends Reducer<Text, CovidBean, Text, CovidBean> {
/**
* Text key map的输出key
* Iterable<CovidBean> values 根据key分组后的value,类型是map的输出value类型
* Context context 上下文
*/
@Override
protected void reduce(Text key, Iterable<CovidBean> values, Context context) throws IOException, InterruptedException {
long cases = 0, deaths = 0;
CovidBean outValue = new CovidBean();
for (CovidBean cb : values) {
cases += cb.getCases();
deaths += cb.getDeaths();
}
outValue.setState(key.toString());
outValue.setCases(cases);
outValue.setDeaths(deaths);
context.write(key, outValue);
}
}
4)、Driver
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import org.hadoop.mr.covid.bean.CovidBean;
/**
* @author alanchan
*
*/
public class EachStateDriver extends Configured implements Tool {
static String in = "D:/workspace/bigdata-component/hadoop/test/in";
static String out = "D:/workspace/bigdata-component/hadoop/test/out/covid";
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
int status = ToolRunner.run(conf, new EachStateDriver(), args);
System.exit(status);
}
@Override
public int run(String[] args) throws Exception {
Job job = Job.getInstance(getConf(), EachStateDriver.class.getSimpleName());
job.setJarByClass(EachStateDriver.class);
job.setMapperClass(EachStateMapper.class);
job.setReducerClass(EachStateReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(CovidBean.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(CovidBean.class);
FileInputFormat.addInputPath(job, new Path(in));
FileSystem fs = FileSystem.get(getConf());
if (fs.exists(new Path(out))) {
fs.delete(new Path(out), true);
}
FileOutputFormat.setOutputPath(job, new Path(out));
return job.waitForCompletion(true) ? 0 : 1;
}
}
4、验证
输出结果如下:
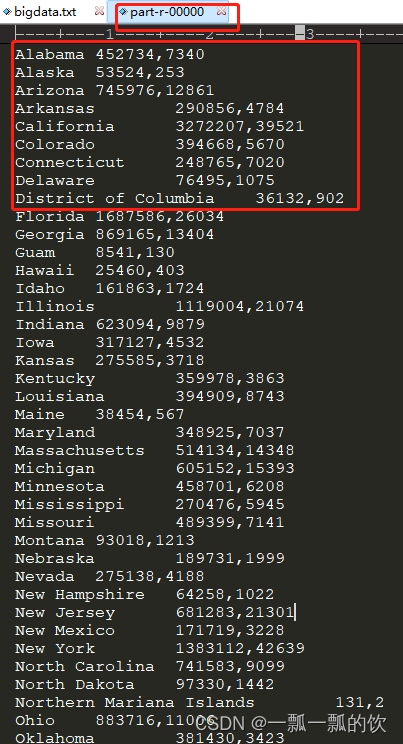
以上完成了基本的计算,主要是展示自定义对象实现序列化。
三、排序
1、需求
将美国2021-01-28,每个州state的确诊案例数进行倒序排序。
2、实现说明
MapReduce中key有默认(按字典序升序)排序行为。
- 如果是正序,且数据类型是Hadoop封装好的类型,这种情况下不需要修改,直接使用Hadoop类型作为key即可。
- 如果是倒序,或者数据类型是自定义对象。需要重写排序规则。对象实现Comparable接口重写CompareTo方法。
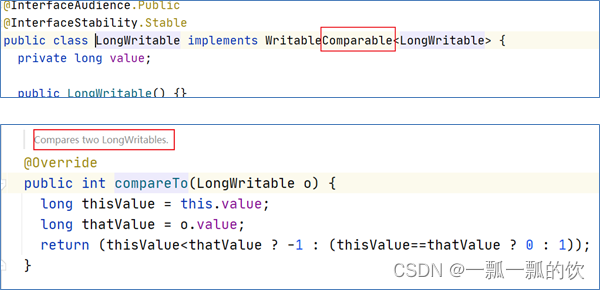
compareTo方法用于将当前对象与方法的参数进行比较。 - 如果指定的数小于参数返回 -1。
- 如果指定的数大于参数返回 1。
例如:o1.compareTo(o2);
返回正数的话,当前对象(调用compareTo方法的对象o1)要排在比较对象(compareTo传参对象o2)后面,返回负数的话,放在前面。
本示例需要按照州进行倒序排序,如此,则需要自己实现排序。
3、实现
1)、bean
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.WritableComparable;
import lombok.Data;
@Data
public class CovidBean implements WritableComparable<CovidBean> {
private String state;
private long cases;
private long deaths;
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(state);
out.writeLong(cases);
out.writeLong(deaths);
}
@Override
public void readFields(DataInput in) throws IOException {
this.state = in.readUTF();
this.cases = in.readLong();
this.deaths = in.readLong();
}
public String toString() {
return this.state + "\t" + this.cases + "\t" + this.deaths;
}
// /** Compares two LongWritables. */
// @Override
// public int compareTo(LongWritable o) {
// long thisValue = this.value;
// long thatValue = o.value;
// return (thisValue<thatValue ? -1 : (thisValue==thatValue ? 0 : 1));
// }
@Override
public int compareTo(CovidBean o) {
long thisCases = this.cases;
long thatCases = o.getCases();
int result = 0;
result = (thisCases > thatCases ? -1 : (thisCases == thatCases ? 0 : 1));
return result;
}
}
2)、Mapper
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class EachStateDescSortMapper extends Mapper<LongWritable, Text, CovidBean, NullWritable> {
CovidBean outKey = new CovidBean();
// 数据样式
// Alabama 452734 7340
// Arizona 745976 12861
// Arkansas 290856 4784
// California 3272207 39521
@Override
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 根据每行的数据标志进行截取
String values[] = value.toString().split("\t");
// 输出key赋值
outKey.setState(values[0]);
outKey.setCases(Long.parseLong(values[1]));
outKey.setDeaths(Long.parseLong(values[2]));
// 将输出key-value输出
context.write(outKey, NullWritable.get());
}
}
3)、Reducer
import java.io.IOException;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class EachStateDescSortReducer extends Reducer<CovidBean, NullWritable, CovidBean, NullWritable> {
// 数据样式
// Alabama 452734 7340
// Arizona 745976 12861
// Arkansas 290856 4784
// California 3272207 39521
@Override
protected void reduce(CovidBean key, Iterable<NullWritable> values, Context context)
throws IOException, InterruptedException {
// 由于map的输出仅仅是key的输出,故value的值为空,
// 并且本例仅仅是需要key,且是针对key值的部分进行倒序排列好了,故直接输出key即可
context.write(key, NullWritable.get());
}
}
4)、Driver
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
/**
* @author alanchan
*
* 每个州state的确诊案例数进行倒序排序
*/
public class EachStateDescSortDriver extends Configured implements Tool {
//本示例是在req1的基础上做的,即需要req1的输出文件
static String in = "D:/workspace/bigdata-component/hadoop/test/out/covid/req1";
static String out = "D:/workspace/bigdata-component/hadoop/test/out/covid/descsort";
/**
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
int status = ToolRunner.run(conf, new EachStateDescSortDriver(), args);
System.exit(status);
}
@Override
public int run(String[] args) throws Exception {
Job job = Job.getInstance(getConf(), EachStateDescSortDriver.class.getSimpleName());
job.setJarByClass(EachStateDescSortDriver.class);
job.setMapperClass(EachStateDescSortMapper.class);
job.setReducerClass(EachStateDescSortReducer.class);
// map阶段输出的key-value类型
job.setMapOutputKeyClass(CovidBean.class);
job.setMapOutputValueClass(NullWritable.class);
// reducer阶段输出的key-value类型
job.setOutputKeyClass(CovidBean.class);
job.setOutputValueClass(NullWritable.class);
FileInputFormat.addInputPath(job, new Path(in));
FileSystem fs = FileSystem.get(getConf());
if (fs.exists(new Path(out))) {
fs.delete(new Path(out), true);
}
FileOutputFormat.setOutputPath(job, new Path(out));
return job.waitForCompletion(true) ? 0 : 1;
}
}
4、验证
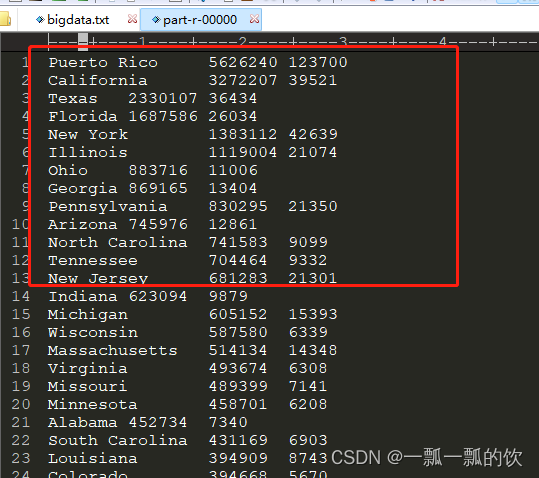
以上,则完成了倒序排序操作。
四、分区
分区个数是由reducer的task数量决定的,即一个task对应一个输出结果。如果希望按照一定规则的输出到不同的文件中,则需要根据一定的分区规则定义task的数量。如果分区规则不适用,则需要自定义分区规则。
1、需求
将美国疫情数据不同州的输出到不同文件中,属于同一个州的各个县输出到同一个结果文件中
2、实现说明
hadoop默认的分区实现
package org.apache.hadoop.mapreduce.lib.partition;
import org.apache.hadoop.classification.InterfaceAudience;
import org.apache.hadoop.classification.InterfaceStability;
import org.apache.hadoop.mapreduce.Partitioner;
/** Partition keys by their {@link Object#hashCode()}. */
@InterfaceAudience.Public
@InterfaceStability.Stable
public class HashPartitioner<K, V> extends Partitioner<K, V> {
/** Use {@link Object#hashCode()} to partition. */
public int getPartition(K key, V value,int numReduceTasks) {
//& Integer.MAX_VALUE 是避免key.hashCode()是负数
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
}
本示例通过自定义分区规则实现该需求。
3、实现
1)、bean
如果仅仅是实现本示例,可以不建立java bean即可完成。即使用上文中的bean即可。
2)、Mapper
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class EachStateResultMapper extends Mapper<LongWritable, Text, Text, Text> {
Text outKey = new Text();
// 数据格式
// 2021-01-28,Autauga,Alabama,01001,5554,69
// 2021-01-28,Baldwin,Alabama,01003,17779,225
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] line = value.toString().split(",");
outKey.set(line[2]);
context.write(outKey, value);
}
}
3)、Reducer
import java.io.IOException;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class EachStateResultReducer extends Reducer<Text, Text, NullWritable, Text> {
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
for (Text value : values) {
context.write(NullWritable.get(), value);
}
}
}
4)、分区
本示例仅仅为示例性的,列出了6个分区,如果超过6个,则会系统自动放入第七个分区。
import java.util.HashMap;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
public class EachStateResultPartition extends Partitioner<Text, Text> {
public static HashMap<String, Integer> stateMap = new HashMap<String, Integer>();
static {
stateMap.put("Alabama", 0);
stateMap.put("Arkansas", 1);
stateMap.put("California", 2);
stateMap.put("Florida", 3);
stateMap.put("Indiana", 4);
stateMap.put("Arizona", 5);
}
@Override
public int getPartition(Text key, Text value, int numPartitions) {
Integer code = stateMap.get(key.toString());
if (code != null) {
return code;
}
return 6;
}
}
5)、Driver
该driver中,明确指定了数据分区class以及reducetask的数量
// 设置数据分区
job.setPartitionerClass(EachStateResultPartition.class);
// 设置reducer的任务数
job.setNumReduceTasks(7);
注意:
数据分区=reducetask数量,程序按照期望的结果输出到不同的结果文件中
数据分区>reducetask数量,程序会出错,不能正常的运行
数据分区<reducetask数量,程序正常运行,但会出现空的结果文件,即结果文件的大小为0
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
/**
* @author alanchan
*/
public class EachStateResultDriver extends Configured implements Tool {
static String in = "D:/workspace/bigdata-component/hadoop/test/in";
static String out = "D:/workspace/bigdata-component/hadoop/test/out/covid/result";
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
int status = ToolRunner.run(conf, new EachStateResultDriver(), args);
System.exit(status);
}
@Override
public int run(String[] args) throws Exception {
Job job = Job.getInstance(getConf(), EachStateResultDriver.class.getSimpleName());
job.setJarByClass(EachStateResultDriver.class);
job.setMapperClass(EachStateResultMapper.class);
job.setReducerClass(EachStateResultReducer.class);
// map阶段输出的key-value类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
// reducer阶段输出的key-value类型
job.setOutputKeyClass(NullWritable.class);
job.setOutputValueClass(Text.class);
// 设置数据分区
job.setPartitionerClass(EachStateResultPartition.class);
// 设置reducer的任务数
job.setNumReduceTasks(7);
FileInputFormat.addInputPath(job, new Path(in));
FileSystem fs = FileSystem.get(getConf());
if (fs.exists(new Path(out))) {
fs.delete(new Path(out), true);
}
FileOutputFormat.setOutputPath(job, new Path(out));
return job.waitForCompletion(true) ? 0 : 1;
}
}
4、验证
按照分区生成结果文件
stateMap.put(“Alabama”, 0);
stateMap.put(“Arkansas”, 1);
stateMap.put(“California”, 2);
stateMap.put(“Florida”, 3);
stateMap.put(“Indiana”, 4);
stateMap.put(“Arizona”, 5);
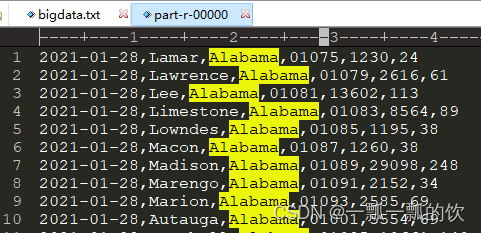
上面的crc文件可以不用管,因为该示例,本人做了其他的例子。
以上,则完成了分区统计示例。
五、分组
- 分组在发生在reduce阶段,决定了同一个reduce中哪些数据将组成一组去调用reduce方法处理
- 默认分组规则是:key相同的就会分为一组(前后两个key直接比较是否相等)
- 在reduce阶段进行分组之前,因为进行了数据排序,因此排序+分组将会使得key一样的数据一定被分到同一组,一组去调用reduce方法处理
1、需求
统计美国2021-01-28,每个州state的确诊案例数最多的县是哪一个。
2、实现说明
- 在map阶段将“州state、县county、县确诊病例cases”通过自定义对象封装,作为key输出
- 重写对象的排序规则,首先根据州的正序排序,如果州相等,按照确诊病例数cases倒序排序,发送到reduce
- 在reduce端利用自定义分组规则,将州state相同的分为一组,然后取第一个即是最大值
- 写类继承 WritableComparator,重写Compare方法。只要Compare方法返回为0,MapReduce框架在分组的时候就会认为前后两个相等,分为一组
- 在job对象中进行设置,让自己的重写分组类生效。job.setGroupingComparatorClass(xxxx.class)
3、实现
1)、bean
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.WritableComparable;
import lombok.Data;
@Data
public class CovidBean implements WritableComparable<CovidBean> {
private String state;
private String country;
private long cases;
private long deaths;
public String toString() {
return this.state + "\t" + this.country + "\t" + this.cases + "\t" + this.deaths;
}
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(this.state);
out.writeUTF(this.country);
out.writeLong(this.cases);
out.writeLong(this.deaths);
}
@Override
public void readFields(DataInput in) throws IOException {
this.state = in.readUTF();
this.country = in.readUTF();
this.cases = in.readLong();
this.deaths = in.readLong();
}
// 排序规则 根据州state正序进行排序 如果州相同 则根据确诊数量cases倒序排序
@Override
public int compareTo(CovidBean o) {
int result = 0;
int i = state.compareTo(o.getState());
if (i > 0) {
result = 1;
} else if (i < 0) {
result = -1;
} else {
// 确诊病例数倒序排序
result = cases > o.getCases() ? -1 : 1;
}
return result;
}
}
2)、Mapper
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
//KEYIN, VALUEIN, KEYOUT, VALUEOUT
public class EachStateGroupingMapper extends Mapper<LongWritable, Text, CovidBean, NullWritable> {
CovidBean outKey = new CovidBean();
// 2021-01-28,Autauga,Alabama,01001,5554,69
// 2021-01-28,Baldwin,Alabama,01003,17779,225
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] line = value.toString().split(",");
outKey.setState(line[2]);
outKey.setCountry(line[1]);
outKey.setCases(Long.parseLong(line[line.length - 2]));
outKey.setDeaths(Long.parseLong(line[line.length - 1]));
context.write(outKey, NullWritable.get());
}
}
3)、Reducer
import java.io.IOException;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Reducer;
//KEYIN, VALUEIN, KEYOUT, VALUEOUT
public class EachStateGroupingReducer extends Reducer<CovidBean, NullWritable, CovidBean, NullWritable> {
protected void reduce(CovidBean key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
context.write(key, NullWritable.get());
}
}
4)、分组
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
public class CovidBeanGroupingComparator extends WritableComparator {
public CovidBeanGroupingComparator() {
super(CovidBean.class, true);
}
public int compare(WritableComparable a, WritableComparable b) {
CovidBean aBean = (CovidBean) a;
CovidBean bBean = (CovidBean) b;
return aBean.getState().compareTo(bBean.getState());
}
}
5)、Driver
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class EachStateGroupingDriver extends Configured implements Tool {
static String in = "D:/workspace/bigdata-component/hadoop/test/in";
static String out = "D:/workspace/bigdata-component/hadoop/test/out/covid/grouping";
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
int status = ToolRunner.run(conf, new EachStateGroupingDriver(), args);
System.exit(status);
}
@Override
public int run(String[] args) throws Exception {
Job job = Job.getInstance(getConf(), EachStateGroupingDriver.class.getSimpleName());
job.setJarByClass(EachStateGroupingDriver.class);
job.setMapperClass(EachStateGroupingMapper.class);
job.setReducerClass(EachStateGroupingReducer.class);
// map阶段输出的key-value类型
job.setMapOutputKeyClass(CovidBean.class);
job.setMapOutputValueClass(NullWritable.class);
// reducer阶段输出的key-value类型
job.setOutputKeyClass(CovidBean.class);
job.setOutputValueClass(NullWritable.class);
//設置分組規則
job.setGroupingComparatorClass(CovidBeanGroupingComparator.class);
FileInputFormat.addInputPath(job, new Path(in));
FileSystem fs = FileSystem.get(getConf());
if (fs.exists(new Path(out))) {
fs.delete(new Path(out), true);
}
FileOutputFormat.setOutputPath(job, new Path(out));
return job.waitForCompletion(true) ? 0 : 1;
}
}
4、验证
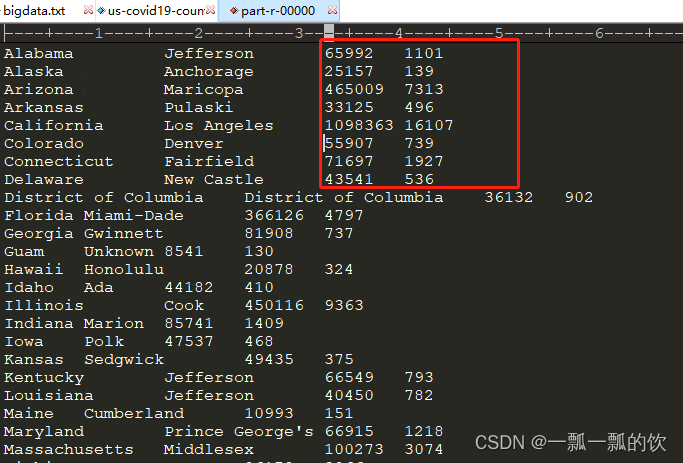
以上完成了分组统计的功能。
六、topN
1、需求
找出美国2021-01-28,每个州state的确诊案例数最多前3个县
2、实现说明
- 在map阶段将“州state、县county、县确诊病例cases”通过自定义对象封装,作为key输出
- 重写对象的排序规则,首先根据州的正序排序,如果州相等,按照确诊病例数cases倒序排序,发送到reduce。
- 在reduce端利用自定义分组规则,将州state相同的分为一组,然后取前N个即是TopN
3、实现
1)、bean
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.WritableComparable;
import lombok.Data;
@Data
public class CovidBean implements WritableComparable<CovidBean> {
private String state;
private String country;
private long cases;
private long deaths;
public String toString() {
return this.state + "\t" + this.country + "\t" + this.cases + "\t" + this.deaths;
}
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(this.state);
out.writeUTF(this.country);
out.writeLong(this.cases);
out.writeLong(this.deaths);
}
@Override
public void readFields(DataInput in) throws IOException {
this.state = in.readUTF();
this.country = in.readUTF();
this.cases = in.readLong();
this.deaths = in.readLong();
}
// 排序规则 根据州state正序进行排序 如果州相同 则根据确诊数量cases倒序排序
@Override
public int compareTo(CovidBean o) {
int result = 0;
int i = state.compareTo(o.getState());
if (i > 0) {
result = 1;
} else if (i < 0) {
result = -1;
} else {
// 确诊病例数倒序排序
result = cases > o.getCases() ? -1 : 1;
}
return result;
}
}
2)、Mapper
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class EachStateTopNMapper extends Mapper<LongWritable, Text, CovidBean, NullWritable> {
CovidBean outKey = new CovidBean();
LongWritable outValue = new LongWritable();
// 2021-01-28,Autauga,Alabama,01001,5554,69
// 2021-01-28,Baldwin,Alabama,01003,17779,225
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] line = value.toString().split(",");
outKey.setState(line[2]);
outKey.setCountry(line[1]);
outKey.setCases(Long.parseLong(line[line.length - 2]));
outKey.setDeaths(Long.parseLong(line[line.length - 1]));
outValue.set(Long.parseLong(line[line.length - 2]));
context.write(outKey, NullWritable.get());
}
}
3)、Reducer
import java.io.IOException;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Reducer;
public class EachStateTopNReducer extends Reducer<CovidBean, NullWritable, CovidBean, NullWritable> {
protected void reduce(CovidBean key, Iterable<NullWritable> values, Context context)
throws IOException, InterruptedException {
int topN = 0;
for (NullWritable value : values) {
if ( topN < 3) { // 输出每个州最多的前3个
context.write(key, NullWritable.get());
topN++;
} else {
return;
}
}
System.out.println("values=" + topN);
}
}
4)、分组
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
public class CovidBeanGroupingComparator extends WritableComparator {
public CovidBeanGroupingComparator() {
super(CovidBean.class, true);
}
public int compare(WritableComparable a, WritableComparable b) {
CovidBean aBean = (CovidBean) a;
CovidBean bBean = (CovidBean) b;
return aBean.getState().compareTo(bBean.getState());
}
}
5)、Driver
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class EachStateTopNDriver extends Configured implements Tool {
static String in = "D:/workspace/bigdata-component/hadoop/test/in";
static String out = "D:/workspace/bigdata-component/hadoop/test/out/covid/topn";
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
int status = ToolRunner.run(conf, new EachStateTopNDriver(), args);
System.exit(status);
}
@Override
public int run(String[] args) throws Exception {
Job job = Job.getInstance(getConf(), EachStateTopNDriver.class.getSimpleName());
job.setJarByClass(EachStateTopNDriver.class);
job.setMapperClass(EachStateTopNMapper.class);
job.setReducerClass(EachStateTopNReducer.class);
// map阶段输出的key-value类型
job.setMapOutputKeyClass(CovidBean.class);
job.setMapOutputValueClass(NullWritable.class);
// reducer阶段输出的key-value类型
job.setOutputKeyClass(CovidBean.class);
job.setOutputValueClass(NullWritable.class);
// 設置分組規則
job.setGroupingComparatorClass(CovidBeanGroupingComparator.class);
FileInputFormat.addInputPath(job, new Path(in));
FileSystem fs = FileSystem.get(getConf());
if (fs.exists(new Path(out))) {
fs.delete(new Path(out), true);
}
FileOutputFormat.setOutputPath(job, new Path(out));
return job.waitForCompletion(true) ? 0 : 1;
}
}
4、验证

至此,完成了MR的基本用法,其中示例中的数据来源于网上。



















 253
253

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











