







Elasticsearch 系列文章
1、介绍lucene的功能以及建立索引、搜索单词、搜索词语和搜索句子四个示例实现
2、Elasticsearch7.6.1基本介绍、2种部署方式及验证、head插件安装、分词器安装及验证
3、Elasticsearch7.6.1信息搜索示例(索引操作、数据操作-添加、删除、导入等、数据搜索及分页)
4、Elasticsearch7.6.1 Java api操作ES(CRUD、两种分页方式、高亮显示)和Elasticsearch SQL详细示例
5、Elasticsearch7.6.1 filebeat介绍及收集kafka日志到es示例
6、Elasticsearch7.6.1、logstash、kibana介绍及综合示例(ELK、grok插件)
7、Elasticsearch7.6.1收集nginx日志及监测指标示例
8、Elasticsearch7.6.1收集mysql慢查询日志及监控
9、Elasticsearch7.6.1 ES与HDFS相互转存数据-ES-Hadoop
文章目录
本文简单的介绍了FileBeat的功能,并以通过filebeat采集kafka日志作为示例进行说明filebeat的使用。
本文依赖es环境好用,其中示例部分需要kafka环境可用且有数据。
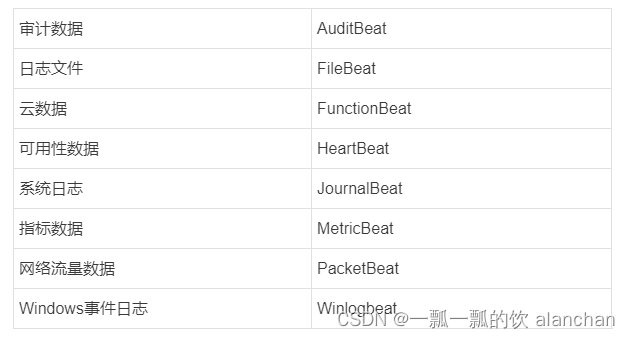
一、Beats
Beats是一个开放源代码的数据发送器。可以把Beats作为一种代理安装在我们的服务器上,这样就可以比较方便地将数据发送到Elasticsearch或者Logstash中。
Elastic Stack提供了多种类型的Beats组件。
Filebeat是本地文件的日志数据采集器。
作为服务器上的代理安装,Filebeat监视日志目录或特定日志文件,tail file,并将它们转发给Elasticsearch或Logstash进行索引、kafka 等。
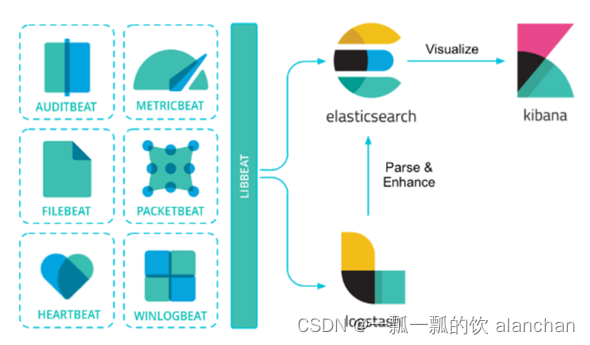
Beats可以直接将数据发送到Elasticsearch或者发送到Logstash,基于Logstash可以进一步地对数据进行处理,然后将处理后的数据存入到Elasticsearch,最后使用Kibana进行数据可视化
1、FileBeat简介
FileBeat专门用于转发和收集日志数据的轻量级采集工具。它可以为作为代理安装在服务器上,FileBeat监视指定路径的日志文件,收集日志数据,并将收集到的日志转发到Elasticsearch或者Logstash。
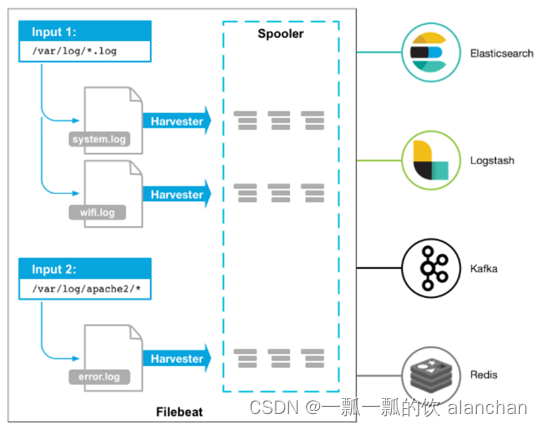
2、FileBeat的工作原理
启动FileBeat时,会启动一个或者多个输入(Input),这些Input监控指定的日志数据位置。FileBeat会针对每一个文件启动一个Harvester(收割机)。Harvester读取每一个文件的日志,将新的日志发送到libbeat,libbeat将数据收集到一起,并将数据发送给输出(Output)。
3、安装FileBeat
安装FileBeat只需要将FileBeat Linux安装包上传到Linux系统,并将压缩包解压到系统就可以了。FileBeat官方下载地址:https://www.elastic.co/cn/downloads/past-releases/filebeat-7-6-1
上传FileBeat安装到Linux,并解压。
tar -xvzf filebeat-7.6.1-linux-x86_64.tar.gz -C /usr/local/bigdata
1)、配置FileBeats
FileBeats配置文件主要分为两个部分。
- inputs
- output
1、 input配置
filebeat.inputs:
- type: log
enabled: true
paths:
-/var/log/*.log #- c:\programdata\elasticsearch\logs\*
在FileBeats中,可以读取一个或多个数据源

2、output配置

默认FileBeat会将日志数据放入到名称为:filebeat-%filebeat版本号%-yyyy.MM.dd 的索引中。
FileBeats中的filebeat.reference.yml包含了FileBeats所有支持的配置选项。
4、使用FileBeat采集Kafka日志到Elasticsearch
采集Kafka服务器日志,在Elasticsearch中快速查询这些日志,定位问题。
需要用FileBeats将日志数据上传到Elasticsearch中
- 要指定FileBeat采集哪些Kafka日志,因为FileBeats中必须知道采集存放在哪儿的日志,才能进行采集。
- 采集到这些数据后,还需要指定FileBeats将采集到的日志输出到Elasticsearch,那么Elasticsearch的地址也必须指定。
1)、配置
cd /usr/local/bigdata/filebeat-7.6.1-linux-x86_64
注意yml文件的格式,即参数后面的空格
touch filebeat_kafka_log.yml
vim filebeat_kafka_log.yml
添加内容
filebeat.inputs:
- type: log
enabled: true
paths:
- /usr/local/bigdata/kafka_2.12-3.0.0/logs/server.log.*
output.elasticsearch:
hosts: ["server1:9200","server2:9200", "server3:9200"]
2)、运行FileBeat
1、启动Elasticsearch
在每个节点上执行以下命令,启动Elasticsearch集群
nohup /usr/local/bigdata/elasticsearch-7.6.1/bin/elasticsearch 2>&1 &
2、运行FileBeat
cd /usr/local/bigdata/filebeat-7.6.1-linux-x86_64
./filebeat -c filebeat_kafka_log.yml -e
3、准备kafka测试数据
由于本机上已经有kafka,直接收集其日志即可
[root@server1 logs]# pwd
/usr/local/bigdata/kafka_2.12-3.0.0/logs
[root@server1 logs]# ll
total 4360
-rw-r--r-- 1 alanchan root 24488 Jan 16 08:51 controller.log
-rw-r--r-- 1 alanchan root 25312 Jan 16 07:56 controller.log.2023-01-16-07
-rw-r--r-- 1 alanchan root 0 Dec 30 10:19 kafka-authorizer.log
-rw-r--r-- 1 alanchan root 0 Dec 30 10:19 kafka-request.log
-rw-r--r-- 1 alanchan root 4352360 Feb 22 05:10 kafkaServer-gc.log.0.current
-rw-r--r-- 1 alanchan root 2049 Jan 26 01:01 log-cleaner.log
-rw-r--r-- 1 alanchan root 2011 Jan 25 06:41 log-cleaner.log.2023-01-25-06
-rw-r--r-- 1 alanchan root 1592 Feb 22 03:08 server.log
-rw-r--r-- 1 alanchan root 9940 Feb 17 01:52 server.log.2023-02-17-01
-rw-r--r-- 1 alanchan root 3207 Feb 17 02:05 server.log.2023-02-17-02
-rw-r--r-- 1 alanchan root 3207 Feb 22 03:10 server.log.2023-02-22-01
-rw-r--r-- 1 alanchan root 219 Feb 17 01:36 state-change.log
-rw-r--r-- 1 alanchan root 219 Jan 18 06:16 state-change.log.2023-01-18-06
-rw-r--r-- 1 alanchan root 7524 Jan 18 07:38 state-change.log.2023-01-18-07
3)、验证
通过head插件,我们可以看到filebeat采集了日志消息,并写入到Elasticsearch集群中。
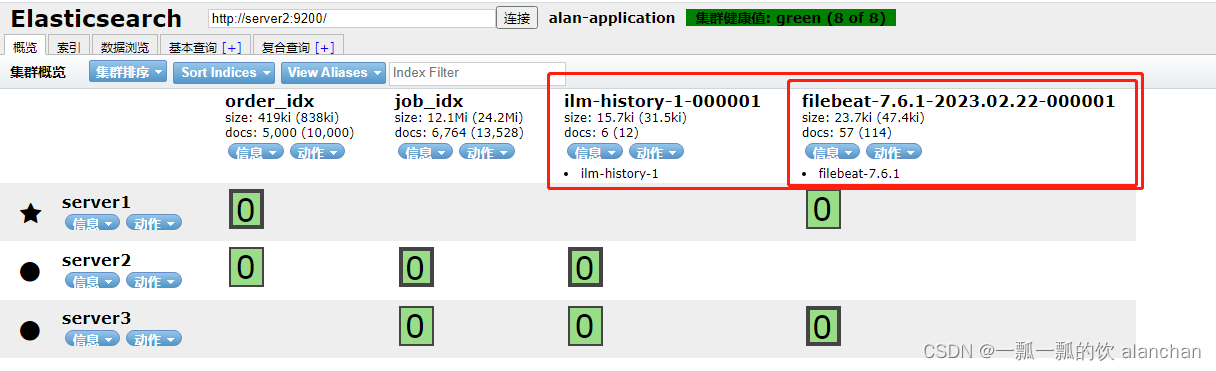
ILM:索引生命周期管理所需的索引
filebeat-7.6.1:在ES中,可以创建索引的别名,可以使用别名来指向一个或多个索引。因为Elasticsearch中的索引创建后是不允许修改的,很多的业务场景下单一索引无法满足需求。别名也有利于ILM所以索引生命周期管理。
索引数据
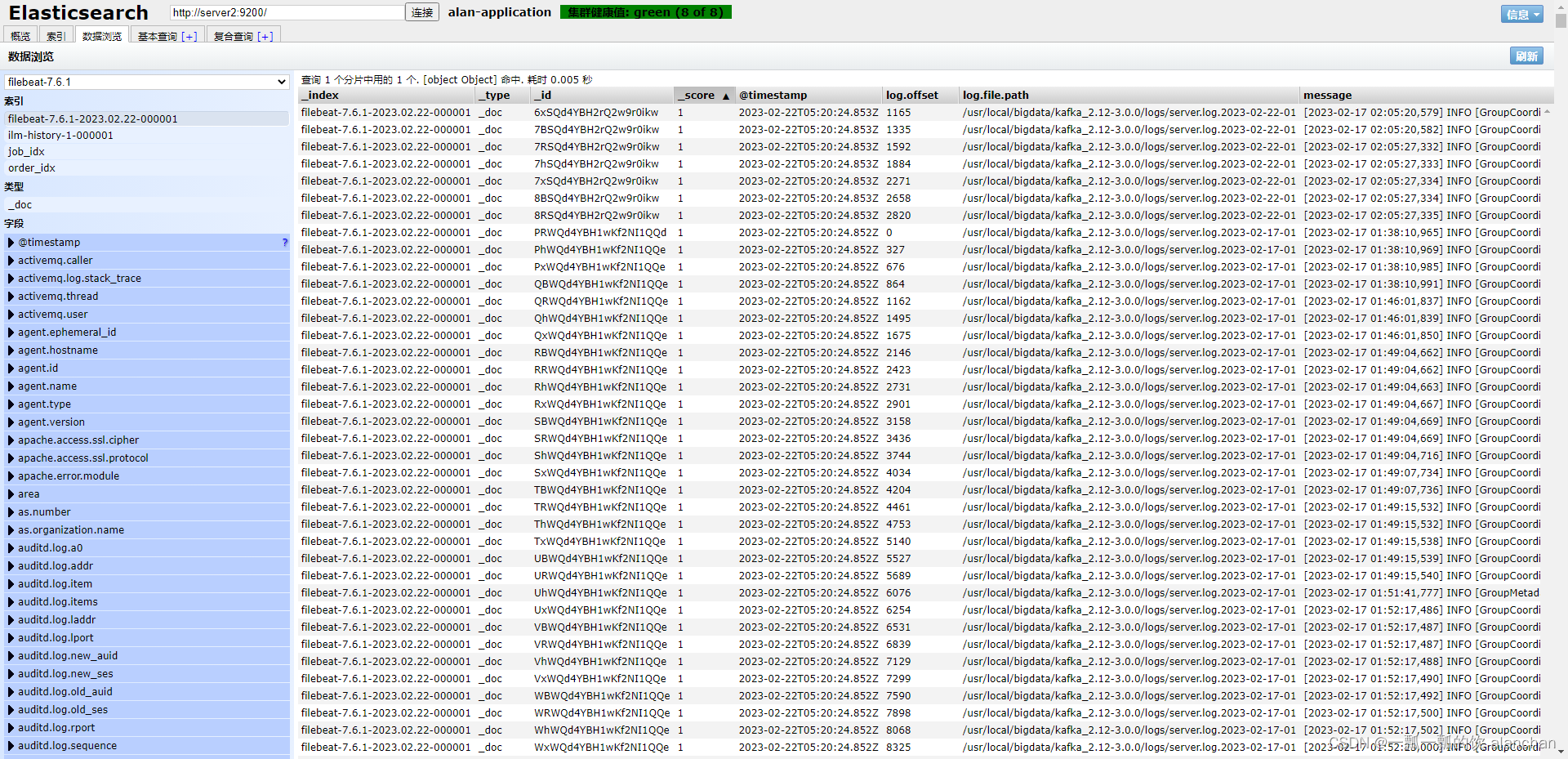
1、查看索引信息
GET /_cat/indices?v
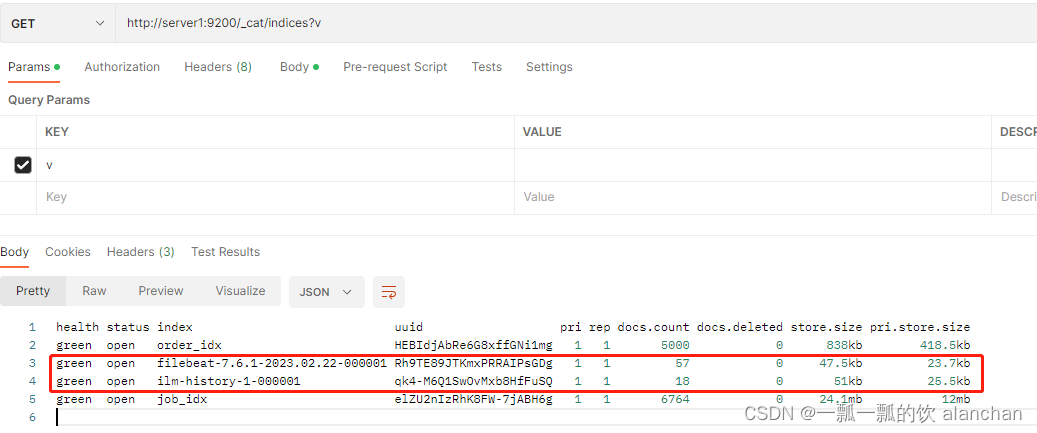
2、查询索引库中的数据
GET /filebeat-7.6.1-2023.02.22-000001/_search
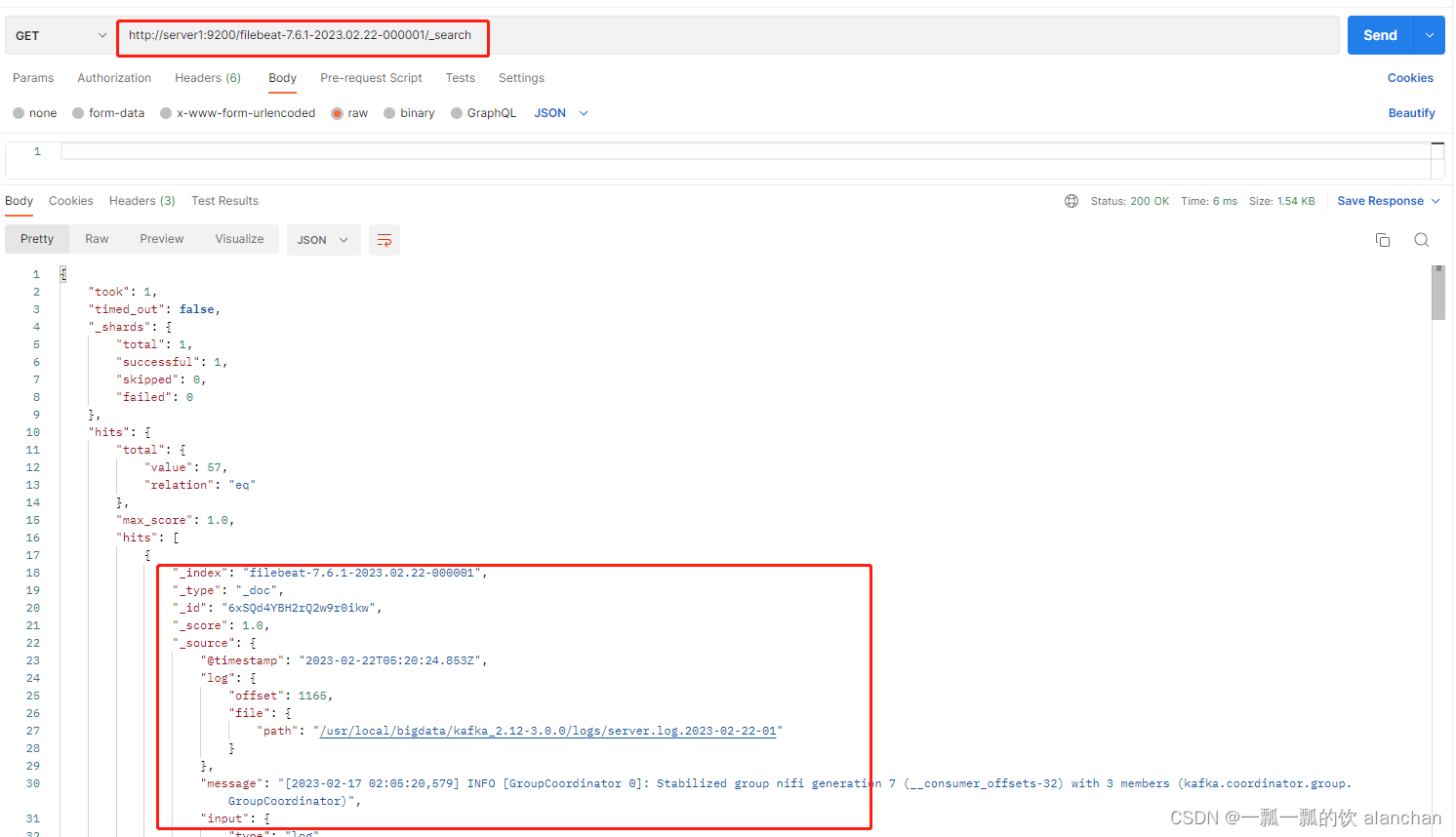
FileBeat自动给我们添加了一些关于日志、采集类型、Host各种字段
3、一个日志涉及到多行问题
在日常日志的处理中,经常会碰到日志中出现异常的情况。类似下面的情况:
[2020-04-3014:00:05,725] WARN [ReplicaFetcher replicaId=0, leaderId=1, fetcherId=0] Errorwhen sending leader epoch request for Map(test_10m-2 ->(currentLeaderEpoch=Optional[161], leaderEpoch=158))(kafka.server.ReplicaFetcherThread)
java.io.IOException:Connection to node2.itcast.cn:9092 (id: 1 rack: null) failed.
atorg.apache.kafka.clients.NetworkClientUtils.awaitReady(NetworkClientUtils.java:71)
atkafka.server.ReplicaFetcherBlockingSend.sendRequest(ReplicaFetcherBlockingSend.scala:102)
at kafka.server.ReplicaFetcherThread.fetchEpochEndOffsets(ReplicaFetcherThread.scala:310)
atkafka.server.AbstractFetcherThread.truncateToEpochEndOffsets(AbstractFetcherThread.scala:208)
atkafka.server.AbstractFetcherThread.maybeTruncate(AbstractFetcherThread.scala:173)
atkafka.server.AbstractFetcherThread.doWork(AbstractFetcherThread.scala:113)
atkafka.utils.ShutdownableThread.run(ShutdownableThread.scala:96)
[2020-04-3014:00:05,725] INFO [ReplicaFetcher replicaId=0, leaderId=1, fetcherId=0] RetryingleaderEpoch request for partition test_10m-2 as the leader reported an error:UNKNOWN_SERVER_ERROR (kafka.server.ReplicaFetcherThread)[2020-04-30
14:00:08,731] WARN [ReplicaFetcher replicaId=0, leaderId=1, fetcherId=0]
Connection to node 1 (node2.itcast.cn/192.168.88.101:9092) could not be
established. Broker may not be available.
(org.apache.kafka.clients.NetworkClient)
在FileBeat中,Harvest是逐行读取日志文件的。但上述的日志会出现一条日志,跨多行的情况。有异常信息时,肯定会出现多行。
每条日志都是有统一格式的开头的,拿Kafka的日志消息来说,[2020-04-30 14:00:05,725]这是一个统一的格式,如果不是以这样的形式开头,说明这一行肯定是属于某一条日志,而不是独立的一条日志。所以,我们可以通过日志的开头来判断某一行是否为新的一条日志。
1)、准备测试数据
在原来的日志基础上增加下面的内容
[2023-02-17 02:05:27,335] WARN [ReplicaFetcher replicaId=0, leaderId=1, fetcherId=0] Errorwhen sending leader epoch request for Map(test_10m-2 ->(currentLeaderEpoch=Optional[161], leaderEpoch=158))(kafka.server.ReplicaFetcherThread)
java.io.IOException:Connection to node2.itcast.cn:9092 (id: 1 rack: null) failed.
atorg.apache.kafka.clients.NetworkClientUtils.awaitReady(NetworkClientUtils.java:71)
atkafka.server.ReplicaFetcherBlockingSend.sendRequest(ReplicaFetcherBlockingSend.scala:102)
at kafka.server.ReplicaFetcherThread.fetchEpochEndOffsets(ReplicaFetcherThread.scala:310)
atkafka.server.AbstractFetcherThread.truncateToEpochEndOffsets(AbstractFetcherThread.scala:208)
atkafka.server.AbstractFetcherThread.maybeTruncate(AbstractFetcherThread.scala:173)
atkafka.server.AbstractFetcherThread.doWork(AbstractFetcherThread.scala:113)
atkafka.utils.ShutdownableThread.run(ShutdownableThread.scala:96)
[2023-02-17 02:05:27,335] INFO [ReplicaFetcher replicaId=0, leaderId=1, fetcherId=0] RetryingleaderEpoch request for partition test_10m-2 as the leader reported an error:UNKNOWN_SERVER_ERROR (kafka.server.ReplicaFetcherThread)[2020-04-30
14:00:08,731] WARN [ReplicaFetcher replicaId=0, leaderId=1, fetcherId=0]
Connection to node 1 (node2.itcast.cn/192.168.88.101:9092) could not be
established. Broker may not be available.
(org.apache.kafka.clients.NetworkClient)
2)、FileBeat多行配置选项
在FileBeat的配置中,专门有一个解决一条日志跨多行问题的配置。主要为以下三个配置
multiline.pattern: ^\[
multiline.negate: false
multiline.match: after
#multiline.pattern表示能够匹配一条日志的模式,默认配置的是以[开头的才认为是一条新的日志。^\[表示匹配以[开头的消息
#multiline.negate:
# 配置为false,正常匹配(默认),表示不需要取反
# 配置为true,表示取反
#multiline.match:表示是否将未匹配到的行追加到上一日志,还是追加到下一个日志。
# The regexp Pattern that has to be matched. Theexample pattern matches all lines starting with [
#multiline.pattern: ^\[
# Definesif the pattern set under pattern should be negated or not. Default is false.
#multiline.negate:false
# Matchcan be set to "after" or "before". It is used to define iflines should be append to a pattern
# that was(not) matched before or after or as long as a pattern is not matched based onnegate.
# Note:After is the equivalent to previous and before is the equivalent to to next inLogstash #multiline.match: after
3)、修改FileBeat的配置文件
filebeat.inputs:
- type: log
enabled: true
paths:
- /usr/local/bigdata/kafka_2.12-3.0.0/logs/server.log.*
multiline.pattern: '^\['
multiline.negate: true
multiline.match: after
output.elasticsearch:
hosts: ["server1:9200","server2:9200", "server3:9200"]
4)、删除「注册表」/data.json
rm –rf /usr/local/bigdata/filebeat-7.6.1-linux-x86_64/data/registry/filebeat/data.json
5)、删除之前创建的索引
delete /filebeat-7.6.1-2023.02.22-000001
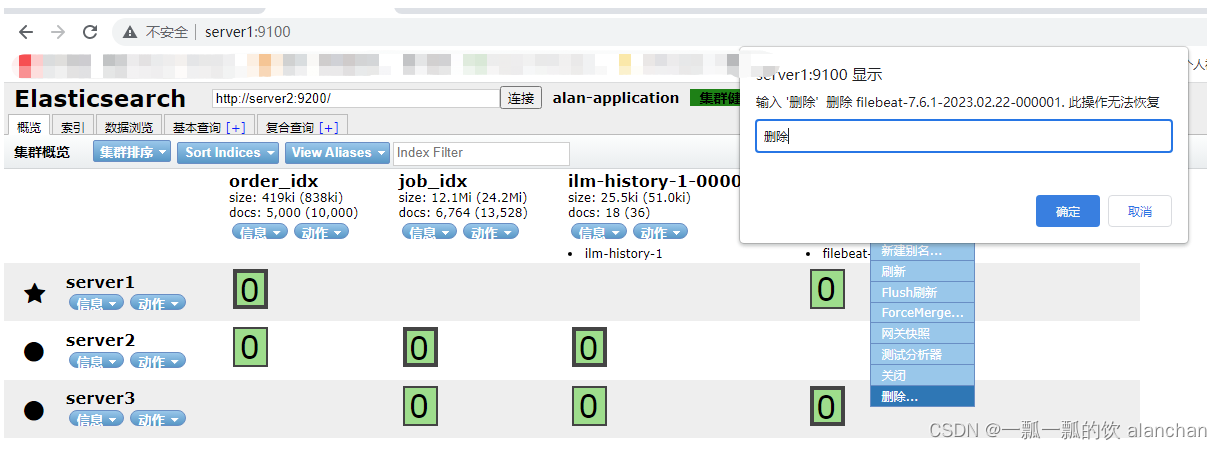
6)、重启filebeat
./filebeat -c filebeat_kafka_log.yml -e
7)、验证数据
{
"_index": "filebeat-7.6.1-2023.02.22-000001",
"_type": "_doc",
"_id": "MBTDd4YBH2rQ2w9rLCpT",
"_version": 1,
"_score": 1,
"_source": {
"@timestamp": "2023-02-22T06:15:26.120Z",
"input": {
"type": "log"
},
"ecs": {
"version": "1.4.0"
},
"host": {
"name": "server1"
},
"agent": {
"id": "72d36c50-e35e-4ac9-b143-83d68cc2b915",
"version": "7.6.1",
"type": "filebeat",
"ephemeral_id": "a95ff5b6-26d6-496d-a74e-11a067dd129e",
"hostname": "server1"
},
"log": {
"offset": 3207,
"file": {
"path": "/usr/local/bigdata/kafka_2.12-3.0.0/logs/server.log.2023-02-22-01"
},
"flags": [
"multiline"
]
},
"message": "[2023-02-17 02:05:27,335] WARN [ReplicaFetcher replicaId=0, leaderId=1, fetcherId=0] Errorwhen sending leader epoch request for Map(test_10m-2 ->(currentLeaderEpoch=Optional[161], leaderEpoch=158))(kafka.server.ReplicaFetcherThread) java.io.IOException:Connection to node2.itcast.cn:9092 (id: 1 rack: null) failed. atorg.apache.kafka.clients.NetworkClientUtils.awaitReady(NetworkClientUtils.java:71) atkafka.server.ReplicaFetcherBlockingSend.sendRequest(ReplicaFetcherBlockingSend.scala:102) at kafka.server.ReplicaFetcherThread.fetchEpochEndOffsets(ReplicaFetcherThread.scala:310) atkafka.server.AbstractFetcherThread.truncateToEpochEndOffsets(AbstractFetcherThread.scala:208) atkafka.server.AbstractFetcherThread.maybeTruncate(AbstractFetcherThread.scala:173) atkafka.server.AbstractFetcherThread.doWork(AbstractFetcherThread.scala:113) atkafka.utils.ShutdownableThread.run(ShutdownableThread.scala:96)"
}
}
5、FileBeat是如何工作的
https://www.elastic.co/cn/downloads/past-releases#filebeat
FileBeat主要由input和harvesters(收割机)组成。这两个组件协同工作,并将数据发送到指定的输出。
1)、input和harvester
1、inputs(输入)
input是负责管理Harvesters和查找所有要读取的文件的组件
如果输入类型是log,input组件会查找磁盘上与路径描述的所有文件,并为每个文件启动一个Harvester,每个输入都独立地运行
2、Harvesters(收割机)
Harvesters负责读取单个文件的内容,它负责打开/关闭文件,并逐行读取每个文件的内容,将读取到的内容发送给输出
每个文件都会启动一个Harvester
Harvester运行时,文件将处于打开状态。如果文件在读取时,被移除或者重命名,FileBeat将继续读取该文件
2)、FileBeats如何保持文件状态
FileBeat保存每个文件的状态,并定时将状态信息保存在磁盘的「注册表」文件中
该状态记录Harvester读取的最后一次偏移量,并确保发送所有的日志数据
如果输出(Elasticsearch或者Logstash)无法访问,FileBeat会记录成功发送的最后一行,并在输出(Elasticsearch或者Logstash)可用时,继续读取文件发送数据
在运行FileBeat时,每个input的状态信息也会保存在内存中,重新启动FileBeat时,会从「注册表」文件中读取数据来重新构建状态。
在/usr/local/bigdata/filebeat-7.6.1-linux-x86_64/data目录中有一个Registry文件夹,里面有一个data.json,该文件中记录了Harvester读取日志的offset。
[{
"source": "/usr/local/bigdata/kafka_2.12-3.0.0/logs/server.log.2023-02-22-01",
"offset": 4593,
"timestamp": "2023-02-22T06:25:46.135669494Z",
"ttl": -1,
"type": "log",
"meta": null,
"FileStateOS": {
"inode": 10880886,
"device": 64768
}
}]
以上,简单的介绍了FileBeat的功能,并以通过filebeat采集kafka日志作为示例进行说明filebeat的使用。















 4487
4487











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











