







https://www.cnblogs.com/xyjdreamer/p/6509919.html
ITU-T于2002年发布了扩展版本的JPEG-LS的无损数据压缩标准,该版标准使用算术编码替代了baseline版本中的游程编码和Golomb-rice编码。相对而言,采用算术编码可以将压缩性能提升5%~10%。目前,网上可以查到的大部分JPEG-LS讲解均是基于baseline版本的,几乎没有extension版本的相关解析。可能是由于算术编码的专利限制吧,大家都还倾向于使用baseline版本来进行无损数据压缩。
最近由于项目需要,便对着extension标准,希望实现以下该版本的代码,但是在其中遇到了一些无法理解的部分,到时无法将算术编码器和前面的预测部分进行衔接,这里写一篇博文,一方面大概讲以下整体的编码流程,另外一方面,贴出自己的疑惑,还希望高人解答。
首先大概介绍一下整体编码流程,详细可以参考具体的标准。对于标准中新规定的扩展预测部分,本文不作考虑。
1.初始化
初始化主要是对一些变量进行初始化,如计算MAXVAL,RANGE,bpp,qbpp,N[1091],A[1091],B[1091],C[1091]等,这些具体可以参考标准的说明,将变量初始化为规定的值。
另外,还要初始化与熵编码相关的变量,如LPScnt[MAXS],MLcnt[MAXS],MPSvalue[MAXS]。MAXS变量根据如下公式计算:
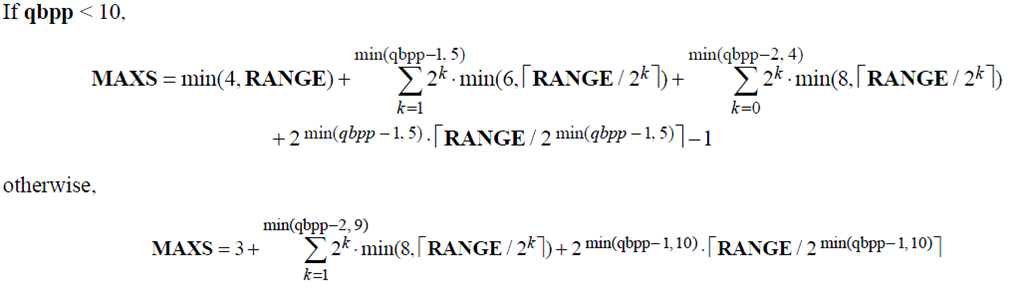
实现代码可参考如下代码:

//计算MAXS
if(qbpp < 10){
int temp1 = 0,temp2 = 0,temp3 = 0,temp4 = 0;
temp1 = MIN(4,RANGE);
for(int k = 1 ; k <= MIN(qbpp-1,5) ; ++k){
int temp = RANGE / (1<<k);
if( ((1<<k) * temp ) < RANGE) ++temp;
temp2 += (2<<k) * (MIN(6,temp));
}
for(int k = 0; k <= MIN(qbpp-2,4) ; ++k){
int temp = RANGE / (1<<k);
if( ((1<<k) * temp ) < RANGE) ++temp;
temp3 += (2<<k) * (MIN(8,temp));
}
int temp = RANGE / ( 1<<(MIN(qbpp-1,5)) );
if(((1<<(MIN(qbpp-1,5))) * temp ) < RANGE) ++temp;
temp4 = (1<<(MIN(qbpp-1,5))) * temp - 1;
MAXS = temp1 + temp2 + temp3 + temp4;
}
else{
int temp1 = 0, temp2 = 0;
for(int k = 1; k <= MIN(qbpp-2,9); ++k){
int temp = RANGE / (1<<k);
if( ((1<<k) * temp ) < RANGE) ++temp;
temp1 += (1<<k)*(MIN(8,temp));
}
int temp = RANGE / (1<<(MIN(qbpp-1,10)));
if((1<<(MIN(qbpp-1,10)) * temp ) < RANGE) ++temp;
temp2 = (1<<(MIN(qbpp-1,10))) * temp;
MAXS = 3 + temp1 + temp2;
}
同时,扩展版本中,参考像素由基本版的4个增加至5个,如下图所示:
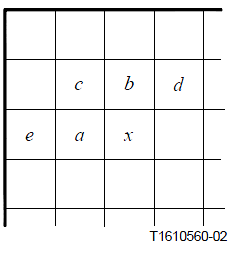
2.局部梯度计算
计算四个梯度值D1,D2,D3,D4。方法如下:
//计算梯度
D1 = Rd - Rb;
D2 = Rb - Rc;
D3 = Rc - Ra;
D4 = Ra - Re;
3.扁平区域计算
在baseline中,该步将判断是否进入游程模式,在扩展版本中,取消了游程编码,所以此步仅仅设置标志位。方法如下:
//扁平区域判断
if( (ABS(D1) <= NEAR) && (ABS(D2) <= NEAR) && (ABS(D3) <= NEAR))
Zerograd = 0;
else
Zerograd = 0;
4.局部梯度量化
该步将根据前面的梯度值,将其量化。量化函数如下:
对D1,D2,D3采用如下量化方法:
int quant_grad(int d, int NEAR, int T1, int T2, int T3)//local gradient quantization
{//T1..T3
int q;
if(d<=-T3) q=-4;
else if(d<=-T2) q=-3;
else if(d<=-T1) q=-2;
else if(d<-NEAR) q=-1;
else if(d<=NEAR) q=0;
else if(d<T1) q=1;
else if(d<T2) q=2;
else if(d<T3) q=3;
else q=4;
return q;
}
其中T1,T2,T3,T4可根据如下代码计算
if(MAXVAL>=128){
factor = (MIN(MAXVAL,4095) + 128) / 256;
T1 = CLAMP(factor*(Basic_T1-2)+2+3*NEAR, NEAR+1, MAXVAL);
T2 = CLAMP(factor*(Basic_T2-3)+3+5*NEAR, T1, MAXVAL);
T3 = CLAMP(factor*(Basic_T3-4)+4+7*NEAR, T2, MAXVAL);
T4 = CLAMP(factor*(Basic_T4-4)+4+3*NEAR, NEAR+1, MAXVAL);
}
else{
factor=256/(MAXVAL+1);
T1 = CLAMP(MAX(2,Basic_T1/factor+3*NEAR), NEAR+1, MAXVAL);
T2 = CLAMP(MAX(3,Basic_T2/factor+5*NEAR), T1, MAXVAL);
T3 = CLAMP(MAX(4,Basic_T3/factor+7*NEAR), T2, MAXVAL);
T4 = CLAMP(MAX(5,Basic_T4/factor+3*NEAR), NEAR+1, MAXVAL);
}
其中,MIN,MAX,CLAMP为宏
#define Basic_T1 3
#define Basic_T2 7
#define Basic_T3 21
#define Basic_T4 5
#define MIN_C -128
#define MAX_C 127
#define CLAMP(i,j,MAXVAL) (((i)>(MAXVAL) || (i)<(j)) ? (j) : (i))
#define MAX(x,y) ((x) > (y) ? (x) : (y))
#define MIN(x,y) ((x) > (y) ? (y) : (x))
#define ABS(x) ((x<0) ? (-x): (x))
对D4采用如下量化方法:
if( D4 <= -T4)
Q4 = -1;
else if(D4 < T4)
Q4 =0;
else
Q4 = 1;
5.梯度融合
融合策略为:
如果(Q1,Q2,Q3)的第一个非零元素为负,则将(Q1,Q2,Q3,Q4)变为(-Q1,-Q2,-Q3,-Q4),同时SIGN被设置为-1.
否则,(Q1,Q2,Q3,Q4)保持不变,且SIGN被设置为+1.
因此融合后应当有{(9x9x9+1)/2}x3=1095个不同的上下文,当时标准规定将(0,0,0,-1),(0,0,0,0),(0,0,0,1)融合到一个上下文中,因此最后有1093个不同的上下文Q。标准规定除了(0,0,0,-1),(0,0,0,0),(0,0,0,1),其他的(Q1,Q2,Q3,Q4)应当为一对一的映射为一个Q,而Q的范围为0~1091。
由于标准中并没有规定(0,0,0,-1),(0,0,0,0),(0,0,0,1)应当映射的Q值为多少,也没有说明其映射的Q能否与其他(Q1,Q2,Q3,Q4)映射的Q相同,所以这里不太好确定(0,0,0,-1),(0,0,0,0),(0,0,0,1)应当映射的Q值为多少。另外,Q的值其实是数组N,A,B,C的索引,而这些数组的大小为1092,比我们理论计算的1093个上下文少了一个。所以,这里姑且将(0,0,0,-1),(0,0,0,0),(0,0,0,1)应当映射的Q值为0.(此方法可能不太合适)
下面给出除了(0,0,0,-1),(0,0,0,0),(0,0,0,1)的其他(Q1,Q2,Q3,Q4)计算其一对一映射Q的方法,Q取值为0-1091。
int merg_grad(int &Sign, int Q1, int Q2, int Q3,int Q4)
{ //输入的Q1~Q3应当已经排除了全为0的情况
int Q;
Sign = 1;
if(Q1 < 0){
Sign = -1;
}
else if((Q1==0)&&(Q2<0)){
Sign = -1;
}
else if((Q1==0)&&(Q2==0)&&(Q3<0)){
Sign = -1;
}
if (Sign == -1){
Q1 = -Q1;
Q2 = -Q2;
Q3 = -Q3;
Q4 = -Q4;
}
if (Q1 == 0) {//合并梯度,标准中只是强调合并的唯一性
if (Q2 == 0) {
//Q3 is 1 to 4, Q4 is -1 to +1
Q = (364 - Q3) + 364 * (Q4 + 1); // fills
}
else { // Q2 is 1 to 4, Q3 is 0 to 4, Q4 is -1 to +1
Q = 324+(Q2-1)*9+(Q3+4) + 364 * (Q4 + 1); // fills
}
}
else { // Q1 is 1 to 4, Q2 is 0 to 4, Q3 is 0 to 4, Q4 is -1 to +1
Q = ((Q1-1)*81+(Q2+4)*9+(Q3+4)) + 364 * (Q4 + 1); // fills
}
return Q;
}
6.带边沿检测的计算预测像素
此步计算预测像素值
int edge_detect(int Ra, int Rb, int Rc)//Edge_detecting predictor
{
int Px;
if(Rc >= MAX(Ra,Rb))
Px = MIN(Ra,Rb);
else{
if(Rc <= MIN(Ra,Rb))
Px = MAX(Ra,Rb);
else Px = Ra + Rb - Rc;
}
return Px;
}
7.预测值修正
此步根据Zerograd的值对预测像素进行修正,Zerograd是平坦与非平坦标识符,参考第3步。
int predict_correct(int Zerograd,int Sign, int Px, int MAXVAL, int C[], int Q)
{
if(Zerograd == 0){
if(Sign==1)
Px += C[Q];
else
Px -= C[Q];
if(Px > MAXVAL)
Px = MAXVAL;
else
if(Px < 0)
Px = 0;
}
return Px;
}
8.计算预测误差
代码如下:
int Error_pred(int Ix, int Px, int Sign)
{
int Errval;
Errval = Ix - Px;
if(Sign == -1)
Errval = -Errval;
return Errval;
}
9.近无损情况下,误差量化及重构值计算
在无损情况下(NEAR==0),重构值Rx = Ix;而在近无损情况下,则要根据如下代码计算计算重构值
//错误量化,重构值计算
if(nearq){ //近无损情况下,对预测误差进行量化,计算重构值
if(Errval > 0)
Errval = (Errval + nearq)/(2 * nearq + 1);
else
Errval = -(nearq - Errval)/(2 * nearq + 1);
if((Zerograd == 0) && (B[Q] > 0))
Rx = Px + Sign * Errval * (2 * nearq + 1);
else
Rx = Px - Sign * Errval * (2 * nearq + 1);
if(Rx < 0)
Rx = 0;
else if(Rx > MAXVAL)
Rx = MAXVAL;
}
else //无损情况下,重构值等于真实值
Rx = Ix;
10.约束预测误差
将误差映射到(ceil(–RANGE/2).. ceil(RANGE/2)–1)范围内
//ModRange()
if(Errval<0)
Errval += RANGE;
if(Errval >= ((RANGE+1)>>1))
Errval -= RANGE;
11.误差映射,映射为非负值
//Error mapping
if(Errval >= 0)
MErrval = 2 * Errval;
else
MErrval = -2 * Errval - 1;
12.利用哥伦布编码树对误差进行二值化
步骤12、13为JPEG-LS相较于baseline版本改变最大的地方,这里首先将预测误差进行二值化,然后再进行算术编码,由于标准对这一部分的讲解并不是很清楚(可能是我水平太次![]() ),对于其中的一些地方一直搞不明白,这里仅仅做一些简单的说明,并贴出自己的疑惑,还望看到的大神可以解答。
),对于其中的一些地方一直搞不明白,这里仅仅做一些简单的说明,并贴出自己的疑惑,还望看到的大神可以解答。
先贴出计算Act的代码
if(Zerograd == 0){
for( k = 0;(N[Q]<<k) < A[Q] + N[Q]/2; k++);
if(qbpp < 10){
if(k > 0)
if( 5 * (N[Q]<<k) > 7 * (A[Q] + N[Q]/2))
Act = 2 * k;
else
Act = 2 * k + 1;
else
Act = 1;
}
else
Act = k + 1;
if(Act > 11) Act = 11;
}
else
Act = 0;
这里首先需要计算Golomb指数k,与baseline中计算Golomb-rice的k值大同小异。
然后利用k值计算了一个活动层级(Activity class)Act的东西。至于这个东西的功能,我目前并不太清楚。根据标准的规定,Act应该是用来构建二进制决策树(binary decision tree)。下面再具体说。
13.对误差进行熵编码
标准有规定了进行熵编码的过程,如下
MErrvalTMP = MErrval;
while(1){
S = GetBinaryContext();
k = GetGolombk(S);
if(MErrvalTMP >= (1<<k)){
ArithmeticEncode(1,S);
MErrvalTMP = MErrvalTMP - (1<<k);
}
else{
ArithmeticEncode(0,S);
while(k--){
S = GetBinaryContext();
ArithmeticEncode(((MErrvalTMP>>k)&1),S);
}
break;
}
}
在介绍此段代码前,我们首先看标准给出的两个例图,分别是qbpp<10和qbpp>10所构建的binary decision tree的树的结构.
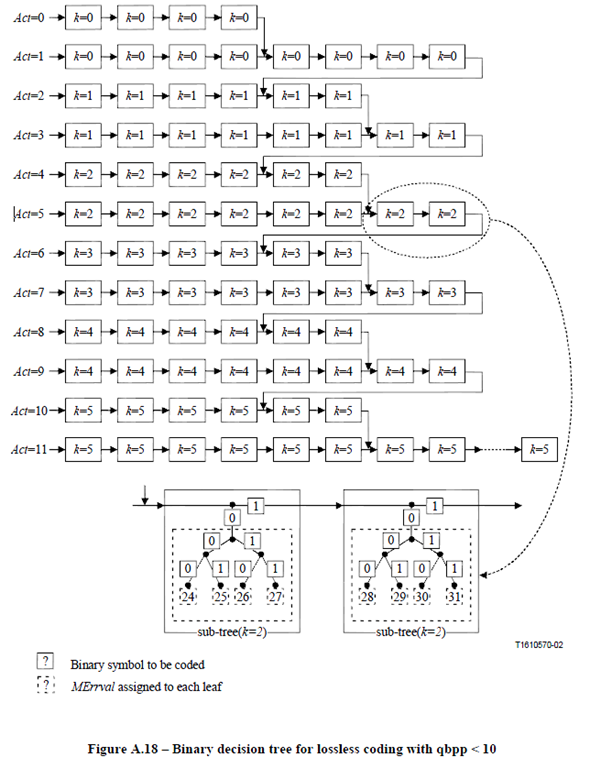

这里,只对qbpp<10的树的结构进行简单介绍,qbpp>10的情况同理.
首先,我们需要知道哥伦布编码的原理。具体的解释可以参考这篇博文
http://www.cnblogs.com/wangguchangqing/p/6297792.html
这里我们仅仅简要介绍一下:
golomb编码将一个非负整数编码为两个部分:所在组的编号 + 分组后剩余的部分
所在组的编号即是待编码数字N与参数m的商,剩余的部分指余数。
q = N / m
r = N % m
对于q使用一元编码,余下部分r使用固定长度的二进制编码。
一元编码即对任意一个非负整数num,其一元编码即num个1后面紧跟一个0
余下部分r的处理根据m的不同略有不同,在JPEG-LS中,m始终是2的幂,所以对余下部分r用log2(m)位表示。
再回过头观察qbpp<10的情况,当Act=5时,k=2,那么对24的编码就表示为111111000。同一层级(Act相同),一个子树指向下一个子树代表一个1,故编码24的子树前面一共有6个子树(24/(2^2)=6),子树内部则表示了具体的余数r。同时,低层级的可以指向高层级的,这里我的理解是,这表示二者表示的是一样的误差。举个例子,当Act=3使,图示中的第八个子树最终指向了Act=4的第四个子树,经过计算,我们可以发现,Act=3的第八个子树所能编码的最大误差为111111101,即7*(2^1)+1=15,而Act=4的第四个子树所能编码的最大误差为111011,即3*(2^2)+3=15。
基本解释了标准中示例树的含义后我们再来看对误差进行熵编码的代码。
函数ArithmeticEncode()即算术编码函数,这里我们暂时不讨论GetBinaryContext()和GetGolombk()函数,如果我们把k当成在整个循环中不改变的话,其实这个循环就是将一个误差转换为哥伦布编码表示的二进制数,然后一个一个送到算术编码器中编码。这里我们暂时不考虑S是如何获取的。
while(1){
if(MErrvalTMP >= (1<<k)){ //求商的过程
ArithmeticEncode(1,S);
MErrvalTMP = MErrvalTMP - (1<<k);
}
else{
ArithmeticEncode(0,S); //添加一个0
while(k--){ //将余数编码
S = GetBinaryContext();
ArithmeticEncode(((MErrvalTMP>>k)&1),S);
}
break;
}
}
但是在这里,如果我们考虑了GetBinaryContext()和GetGolombk()函数,情况可能就变得复杂了。首先,简单说明一下S的含义,标准中将S表示为index of binary context(二进制上下文索引),具体的解释是:Each node of the whole code trees, including both sub-tree separation and in-sub-tree binarization, is referred by its unique index, which is denoted as S. 意思应该是前面所展示的二进制决策树的每一个节点都有一个编号即索引,这个索引就是S。
同时我们再看代码,while循环中,需要通过GetBinaryContext()函数来首先获取S,在通过S来得到k,如果没有理解错误的话,这个k就是我们前面图示里面所表示的k。但是标准同时也说了如何获取k,如下:In the code tree specified here, the parameter k of first some sub-trees are given as k=ëAct/2û if qbpp < 10, otherwise k=max(Act–1, 0). After the first some sub-trees, the kparameter of sub-trees may take larger value, and sub-trees may be merged into the sub-trees of the code trees of higher activity classes.看着意思应该是说k有Act来确定。那么问题就来了,
- Act可以确定k,S也能确定k。S和Act到底是什么关系?
- 按照分析来说,在while循环中k应该不变呀,但是实际标准给出的代码示例却是每一次循环都要重新计算k,那说明k有可能改变。
- GetBinaryContext()函数不需要传递任何参数就能确定S,那究竟是怎么算出来了S呢?
- 另外,在初始化的时候,标准有如下规定:
-
The counters are initialised as LPScnt[S]=2 and MLcnt[S]=4 at binary contexts associated with sub-tree separation, while LPScnt[S]=4 and MLcnt[S]=8 for binary contexts within the sub-trees. Notice that the counters for the decisions on which one symbol never happens are initialized as LPScnt[S]=0 and MLcnt[S]=1.
什么sub-tree separation,什么binary contexts within the sub-trees,翻译都不通。但是可以看出S取不同值时这些变量的初始化值是不同的。S是什么?是树节点的索引。这就出现了问题,在初始化的时候,我们怎么可能知道具体的S所表示的节点是属于sub-tree separation还是属于binary contexts within the sub-trees呢?我想加入我们的树是在编码过程中动态创建的,那么我们是无法准确知道S所表示的节点的分类的。除非树的结构已经固定好了,那么这时标准中所表示的两个binary decision tree是不是表明了树的结构已经固定,必须是这样的,比如当Act=10时,只能有6个子树,当Act=8时,只能有8个子树。
如果是这样的话,我们就可能面临在编码某个误差的时候需要提升层级的情况,举个例子:当Act=5,k=2时,需要编码的误差为40。在while循环的过程中,我们发现act=5最大只能编码的误差是31,那么之后我们便需要将act加一,此时k=3,然后继续在下一层编码呢?这种情况可以解释为什么在while的每次循环中我们都要利用GetBinaryContext()来获取S,并通过S来确定k,应为在编码的过程中,k的值可能改变。
但是,即便这样,还是有说不通的地方,while循环中两次用到了GetBinaryContext()来获取S,第一次求商的时候,而第二次是在对余数进行熵编码的时候使用的,我认为两次的S的计算方法应该是不一样的,第一次我们将S一次累加子树的节点的个数,但第二次就不行了。而且第二次如果要计算S,可能需要用到(MErrvalTMP>>k)&1的值,但这样其实是不行的,因为在解码的时候,我们就是需要用S来回复MErrvalTMP,我们必须在不知道MErrvalTMP的前提下,计算S的值。所以,整个这一部分S这个关键始终无法进行合理解释,导致无法将熵编码器进行衔接。
14.变量更新
if(Zerograd == 0){ if(B[Q]>0) B[Q] = B[Q] - Errval*(2*nearq+1); else B[Q] = B[Q] + Errval*(2*nearq+1); if(Errval<0) A[Q] = A[Q] - 1; A[Q] = A[Q] + ABS(Errval); if(N[Q] == RESET){ A[Q] = A[Q]>>1; if(B[Q] >= 0){ B[Q] = B[Q]>>1; } else{ B[Q] = -((1-B[Q])>>1); } N[Q] = N[Q]>>1; } N[Q] = N[Q]+1; }15.偏移计算
if(Zerograd == 0){ if(2*B[Q] <= -N[Q]){ B[Q] = B[Q] + N[Q]; if(C[Q] > MIN_C) C[Q] = C[Q] - 1; if(2*B[Q] <= -N[Q]) B[Q] = -(N[Q]>>1) + 1; } else if(2*B[Q] > N[Q]){ B[Q] = B[Q] - N[Q]; if(C[Q] < MAX_C) C[Q] = C[Q] + 1; if(2*B[Q] > N[Q]) B[Q] = (N[Q]>>1); }对于,熵编码的具体实现部分,我们下篇博文再说。
分类: 图像压缩


+加关注
0
0
« 上一篇:Tilera平台使用体会
» 下一篇:JPEG-LS extensions标准之熵编码部分















 2134
2134

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









