








1、结论写前面
论文对LLMs在对各种任务建模时利用异构表格数据的首次全面调查,包括预测、数据合成、问题回答和表格理解。论文深入研究了LLM摄取表格数据所需的基本步骤,包括序列化、表格操作和提示工程。此外,论文系统地比较了每个任务的数据集、方法学、度量标准和模型,强调了在理解、推断和生成表格数据方面的主要挑战和最新进展。论文为特定任务定制了数据集和模型选择的建议,旨在帮助机器学习研究人员和从业者选择使用不同LLMs进行表格数据建模的合适解决方案。此外,论文检查了当前方法的局限性,如易感于幻觉、公平性问题、数据预处理复杂性和结果可解释性挑战。鉴于这些限制,论文讨论了未来研究中值得进一步探讨的方向。
随着LLMs的快速发展和它们令人印象深刻的新兴能力,人们对探索它们在为各种任务建模结构化数据的潜力的新思路和研究的需求不断增长。通过这次全面的审查,论文希望它能为感兴趣的读者提供相关的参考和深刻的视角,使他们具备必要的工具和知识,以有效地应对和解决该领域的当前挑战。
2、背景
大型语言模型(LLMs)是在大量数据上训练的深度学习模型,赋予它们多才多艺的问题解决能力,远远超出了自然语言处理(NLP)任务的范围(Fu&Khot,2022)。最近的研究揭示了LLMs的新兴能力,例如在少样本提示任务上的性能提升(Wei et al.,2022b)。LLMs的卓越性能引起了学术界和工业界的兴趣,人们相信它们可能成为本时代人工通用智能(AGI)的基础(Chang等,2024;Zhao等,2023b;Wei等,2022b)。一个显著的例子是ChatGPT,专为参与人类对话而设计,它表现出理解和生成人类语言文本的能力(Liu等,2023g)。
在LLMs之前,研究人员一直在探索将表格数据与神经网络集成,用于NLP和数据管理任务(Badaro等,2023)。如今,研究人员渴望探讨LLMs在处理各种任务时的能力,例如预测、表格理解、定量推理和数据生成(Hegselmann等,2023;Sui等,2023c;Borisov等,2023a)。表格数据是机器学习(ML)中普遍且重要的数据格式之一,在金融、医学、商业、农业、教育等领域广泛应用,这些领域严重依赖关系数据库(Sahakyan等,2021;Rundo等,2019;Hernandez等,2022;Umer等,2019;Luan&Tsai,2021)。表格数据,通常称为结构化数据,是指按行和列组织的数据,其中每列代表特定的特征。在本节中,论文首先介绍表格数据的特征,然后简要回顾了为这一领域量身定制的传统、深度学习和LLM方法。最后,论文阐述了本文的贡献,并提供了后续章节的布局。
2.1 表格数据的特征
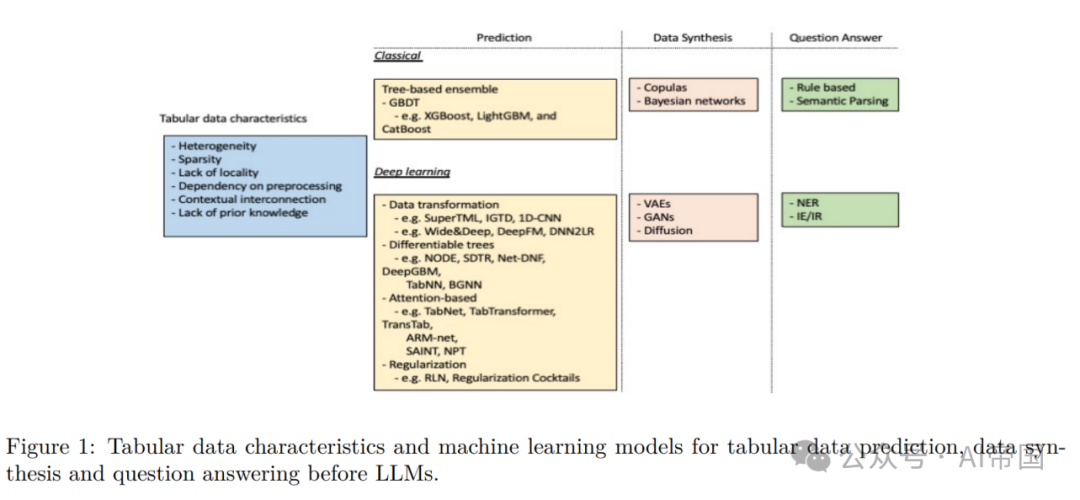
这里讨论表格数据的独特特征和带来的挑战(JQ-:建议在表格数据、表格数据、相关等术语的命名上添加一些澄清):
1.多样性:表格数据可以包含不同类型的特征:分类、数值、二进制和文本。因此,特征可以从密集的数值特征到稀疏或高基数的分类特征(Borisov等,2022)。
2.稀疏性:实际应用,如临床试验、流行病学研究、欺诈检测等,通常涉及到不平衡的类别标签和缺失值,导致训练样本中的长尾分布(Sauber-Cole和Khoshgoftaar,2022)。
3.对预处理的依赖性:在处理表格数据时,数据预处理对特定应用至关重要。对于数值数值,常见的技术包括数据归一化或缩放、分类值编码、缺失值插补和异常值移除。对于分类值,常见的技术包括标签编码或独热编码。不恰当的预处理可能导致信息丢失、稀疏矩阵,并引入多重共线性(例如,使用独热编码)或合成排序(例如,使用有序编码)(Borisov等,2023a)。
4.基于上下文的相互连接:在表格数据中,特征可以相关联。例如,人口统计表中的年龄、教育和饮酒量是相互关联的:年轻时很难获得博士学位,而法定饮酒年龄有一个最低限制。在回归中包含相关的回归变量会导致有偏的系数,因此,模型师必须注意这些复杂性(Liu等,2023d)。
5.无序性:在表格数据中,示例可以进行排序。然而,与与文本和图像数据相反,文本或像素在文本或图像中的位置本质上与之相关,表格示例相对无序。因此,基于位置的方法(例如,空间相关性、妨碍归纳偏见、卷积神经网络(CNN))对于表格数据建模的适用性较差(Borisov等,2022)。
6.缺乏先验知识:在图像或音频数据中,通常存在有关数据的空间或时间结构的先验知识,模型在训练过程中可以利用这些知识。然而,在表格数据中,这样的先验知识通常是缺乏的,使得模型难以理解特征之间的固有关系(Borisov等,2022;2023a)。
2.2 传统与深度学习在表格数据中的应用
传统的基于树的集成方法,如梯度提升决策树(GBDT),仍然是表格数据预测的最新技术(Borisov等,2022; Gorishniy等,2021)。在提升集成方法中,基学习者按顺序学习,以减小先前学习者的错误,直到不再取得显著改进,使其相对于单一学习者更为稳定和准确(Chen&Guestrin,2016)。传统的基于树的模型以其高性能、训练效率高、调整容易和易于解释而闻名。然而,与深度学习模型相比,它们存在一些局限性:
1.基于树的模型对特征工程的敏感性较高,特别是对于分类特征,而深度学习可以在训练期间隐式地学习表示(Goodfellow等,2016)。
2. 基于树的模型不太适用于处理序列数据,例如时间序列,而深度学习模型,如循环神经网络(RNN)和transformers,在处理序列依赖性方面表现出色。
3. 基于树的模型有时在泛化到未见数据方面存在困难,特别是如果训练数据不代表整个分布,而深度学习方法可能对多样化数据集具有更好的泛化能力,因为它们能够学习复杂的表示(Goodfellow等,2016)。
近年来,许多研究探讨了将深度学习用于表格数据建模。这些方法可以大致分为以下几类:
1.数据转换。这些模型要么努力将异构表格输入转换为更适合神经网络的同质数据,如图像,可以在其上应用类似于CNN的机制(SuperTML(Sun等,2019),IGTD(Zhu等,2021b),1D-CNN(Kiranyaz等,2019)),要么关注将特征变换与深度神经网络结合使用(Wide&Deep(Cheng等,2016; Guo&Berkhahn,2016),DeepFM(Guo等,2017),DNN2LR(Liu等,2021))。
2.可微分树。受到集成树性能的启发,这一类方法试图通过平滑决策函数使树可微分(NODE(Popov等,2019),SDTR(Luo等,2021),Net-DNF(Katzir等,2020))。另一类方法将基于树的模型与深度神经网络结合使用,因此可以保持树对处理稀疏分类特征的能力(DeepGBM(Ke等,2019a)),从树中借用先前的结构知识(TabNN(Ke等,2019b)),或通过将结构化数据转换为有向图来利用拓扑信息(BGNN(Ivanov&Prokhorenkova,2021)。
3.基于注意力的方法。这些模型通过注意机制进行特征选择和推理(TabNet(Arik&Pfister,2020),TransTab(Wang&Sun,2022),TabTransformer(Huang等,2020),ARMnet(Cai等,2021)),或者协助样本内信息共享(SAINT(Somepalli等,2021),NPT(Kossen等,2022))。
4.正则化方法。在表格数据中,与图像或文本数据相比,特征的重要性变化较大。因此,这一研究领域试图设计一种优化的动态正则化机制,以调整模型对某些输入的敏感性(例如,RLN(Shavitt&Segal,2018),正则化鸡尾酒(Kadra等,2021)。
尽管在将深度学习应用于表格数据建模方面进行了大量努力,包括XGBoost、LightGBM和CatBoost(Prokhorenkova等,2019)等GBDT算法在大多数数据集中仍然优于深度学习方法,并具有在快速训练时间、高可解释性和易优化性方面的额外优势(Shwartz-Ziv&Armon,2022; Gorishniy等,2021; Grinsztajn等,2022)。然而,在某些情况下,深度学习模型可能在某些方面优于传统方法,例如在面对非常大的数据集或数据主要由分类特征组成的情况下(Borisov等,2022)。
表格数据建模的另一个重要任务是数据合成。合成真实且高质量数据的能力对于模型开发至关重要。当数据稀缺时,数据生成用于增强(Onishi&Meguro,2023),填充缺失值(Jolicoeur-Martineau等,2023)和平衡不平衡数据中的类(Sauber-Cole&Khoshgoftaar,2022)。传统的合成数据生成方法主要基于Copulas(Patki等,2016; Li等,2020)和贝叶斯网络(Zhang等,2017; Madl等,2023),而生成模型的最新进展,如变分自编码器(VAEs)(Ma等,2020; Darabi&Elor,2021; Vardhan&Kok,2020; Liu等,2023d; Xu等,2023b),生成对抗网络(GANs)(Park等,2018; Choi等,2018; Baowaly等,2019; Xu等,2019),扩散(Kotelnikov等,2022; Xu等,2023a; Kim等,2022b; a; Lee等,2023; Zhang等,2023c)和LLMs,开辟了许多新机会。与经典方法(如贝叶斯网络(Xu等,2019))相比,这些深度学习方法在合成数据生成方面表现出更高的性能。
表格问答(QA)是来自表格数据的自然语言研究问题。许多早期的方法对BERT(Devlin等,2019)进行微调,使其成为表格相关任务的表格编码器,例如TAPAS(Herzig等,2020),TABERT(Yin等,2020b),TURL(Deng等,2022a),TUTA(Wang等,2021)和TABBIE(Iida等,2021)。例如,
•TAPAS通过引入额外的嵌入来捕获表格结构,从而扩展了BERT的掩码语言模型目标,以适应结构化数据。它还集成了两个分类层,以促进单元格的选择并预测相应的聚合运算符。
•特定的表格QA任务Text2SQL涉及将自然语言问题转换为结构查询语言(SQL)。早期的研究通过手工制作的特征和语法规则进行语义解析(Pasupat&Liang,2015b)。
•当表格不是来自非数据库表格时,如Web表格、电子表格表格等,语义解析也用于(Jin等,2022)。
•Seq2SQL是一个通过强化学习使用序列到序列深度神经网络来生成WikiSQL任务中查询条件的方法(Zhong等,2017a)。
•一些方法是基于草图的,其中将自然语言问题转换为草图。随后,使用类似于类型导向草图完成和自动修复的编程语言技术,以迭代方式完善初始草图,最终生成最终查询(例如SQLizer(Yaghmazadeh等,2017))。
•另一个例子是SQLNet(Xu等,2017),它使用列注意机制基于依赖图相关的草图合成查询。
•SQLNet的一个衍生物是TYPESQL(Yu等,2018a),它也是一种基于草图的槽填充方法,涉及提取用于填充各自插槽的基本特征。
•与先前的监督式端到端模型不同,TableQuery是一个在自由文本的QA上进行预训练的NL2SQL模型,它消除了将整个数据集加载到内存并序列化数据库的必要性。
2.3 大模型(LLMs)概述
语言模型(LM)是一种概率模型,用于预测单词序列中未来或缺失标记的生成可能性。赵等人(2023b)对LM的发展进行了全面审查,并将其划分为四个不同阶段:第一阶段是统计语言模型(SLM),它学习了来自先前单词的示例序列的单词出现概率(例如N-Gram),基于马尔可夫假设(Saul&Pereira,1997)。尽管通过增加上下文窗口可以实现更准确的预测,但SML受到高维度和高计算需求的限制(Bengio等人,2000)。接下来,神经语言模型(NLM)利用神经网络(例如循环神经网络(RNN))作为概率分类器(Kim等人,2016)。
除了学习单词序列的概率函数之外,NLM的一个关键优势是它们可以学习每个单词的分布式表示(即词嵌入),使相似的单词在嵌入空间中靠近彼此(例如Word2Vec),从而使模型对未在训练数据中出现的序列进行泛化,并有助于缓解维度灾难(Bengio等人,2000)。
后来,与学习静态词嵌入不同,引入了通过在大规模未注释的语料库上进行预训练的上下文感知表示学习,该表示考虑了上下文(例如,ELMo(Peters等人,2018a)),在各种自然语言处理(NLP)任务中显示出显著的性能提升(Wang等人,2022a; Peters等人,2018b)。沿着这一线路,提出了几种其他预训练语言模型(PLM),利用具有自注意机制的变压器架构,包括BERT和GPT2(Ding等人,2023)。
与转移学习密切相关的预训练和微调范式使模型能够在文本语料库上获得一般的句法和语义理解,然后在特定于任务的目标上进行训练以适应各种任务。LM的最终和最近的阶段是大型语言模型(LLMs),将是本文的重点。由于观察到扩大数据和模型规模通常会带来更好的性能,研究人员试图测试更大尺寸的PLM性能的边界,例如文本到文本转移变压器(T5)(Raffel等人,2023),GPT-3(Brown等人,2020)等。有趣的是,一些先进的能力也随之出现。这些大型PLMs(即LLMs)展示了超越传统语言建模的前所未有的强大能力(也称为新兴能力),开始具备解决更一般和复杂任务的能力,这在PLM中是看不到的。正式地,论文如下定义LLM:
定义1(大型语言模型)。由θ参数化的大型语言模型(LLM)M是一个基于变压器的模型,其架构可以是自回归、自编码或编码器-解码器。它已在包含数百万到数万亿令牌的大型语料库上进行训练。LLMs包括预训练模型,并且对于论文的调查,指的是具有至少10亿参数的模型。
LLMs的一些关键新兴能力对于数据理解和建模至关重要,包括上下文学习、遵循指令和多步推理。上下文学习是指设计大型自回归语言模型,该模型在未见任务上生成响应,而不通过梯度更新,仅通过自然语言任务描述和在提示中提供的一些上下文示例进行学习。具有1750亿参数的GPT3模型(Brown等人,2020)展示了在较小模型中看不到的令人印象深刻的上下文学习能力。LLMs还通过仅遵循任务描述的指令(也称为零提示)展示了完成新任务的能力。
一些论文还报告了在各种任务上对LLMs进行微调,这些任务被呈现为指令(Thoppilan等人,2022)。然而,据报道,仅对更大尺寸的模型(Wei等人,2022a; Chung等人,2022)进行指令微调效果最好。对于LLMs来说,解决涉及多个步骤的复杂任务一直是具有挑战性的。通过包含中间推理步骤,提示策略,如链式思考(CoT),已被证明有助于
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1592
1592

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









