






想知道现在OCR有多么逆天了吗?
经过骨灰级开发大咖的集成与修改,现在逆天了,5分钟的视频40秒左右就可以提取完相应的字幕信息。
当然这都得益于北京文通科技公司开发的视频文字识别系统。
其实北京文通科技公司一直建议用户对视频文件进行截屏识别,这样再大再长的视频处理起来也会很迅速。然后ocr处理一堆堆的图片数据效率是非常高的,如果用户开启的进程数非常多的话,一分钟可以处理上千张的图片,一个小时就可以几万张。
但是很多用户都说了,让他们去截取视频里面的截图,他们没有比较适合的方法。
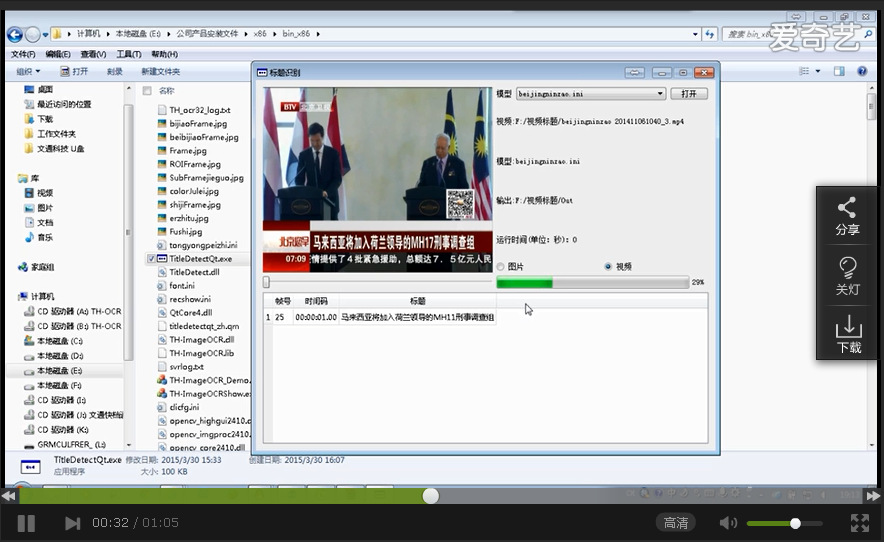
因此,就有技术大咖利用文通视频文字识别系统的开发包制作了这个程序,大家可以看看视频中的演示画面。
请点击查看,有视频有真相!















 2073
2073

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









