






视频动作识别是计算机视觉领域的一个重要研究方向,涉及到自动分析视频中的人或物体的动作,并将其分类到特定的类别中。这项技术在视频监控、人机交互、体育分析、医疗康复等多个领域都有广泛的应用。
视频动作识别的技术实现通常包括以下几个关键步骤:
- 预处理:视频帧的处理,如帧提取、大小调整、颜色标准化等,为后续分析做准备。
- 特征提取:使用深度学习模型(如CNN、RNN或Transformer模型)提取视频帧的特征。这些模型可以处理视频的空间信息(帧内的像素排列)和时间信息(帧与帧之间的关系)。
- 分类器设计:设计算法来根据提取的特征对视频中的动作进行分类。这可能包括支持向量机、决策树或深度神经网络等。
- 后处理:包括平滑输出标签、去除噪声等,以提高识别的准确性。
视频动作识别的发展有着重要的实用意义:
- 安全监控:自动检测异常行为,如打斗或其他紧急事件,有助于及时响应可能的安全威胁。
- 交互式娱乐:在视频游戏和虚拟现实中,动作识别可以提供更自然的用户交互方式。
- 体育分析:自动化的动作识别可以帮助教练和运动员分析技术动作,优化训练和比赛策略。
- 医疗康复:在物理治疗和康复中,动作识别技术可以帮助监测病人的康复进度和动作正确性。
综上所述,视频动作识别技术不仅推动了计算机视觉领域的发展,也促进了其在多个实际应用场景中的广泛应用,显著提高了这些领域的效率和智能化水平。

论文作者:Bozheng Li,Mushui Liu,Gaoang Wang,Yunlong Yu
作者单位:Zhejiang University
论文链接:http://arxiv.org/abs/2408.12475v1
内容简介:
1)方向:动作识别
2)应用:视频动作识别
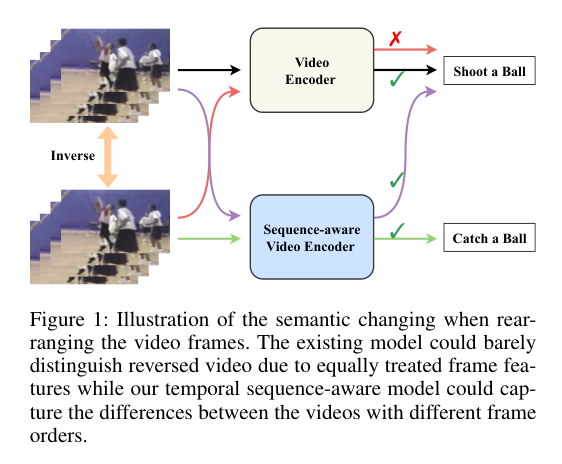
3)背景:现有的动作识别方法通常通过探索所有帧之间的关系来捕捉时间信息,但这些方法在处理时间顺序变化时可能效果不佳。因此,亟需一种能够有效整合空间信息和时间动态的模型,以提高少样本动作识别的表现。
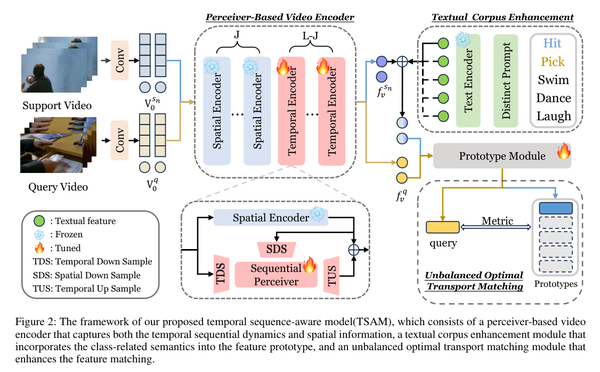
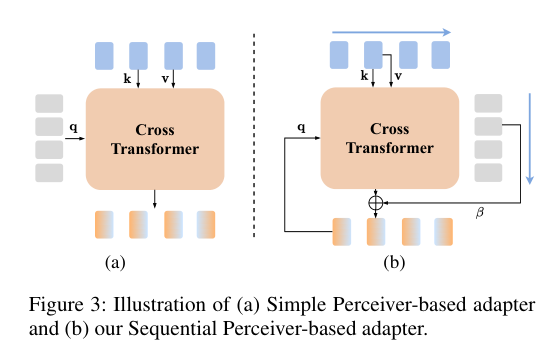
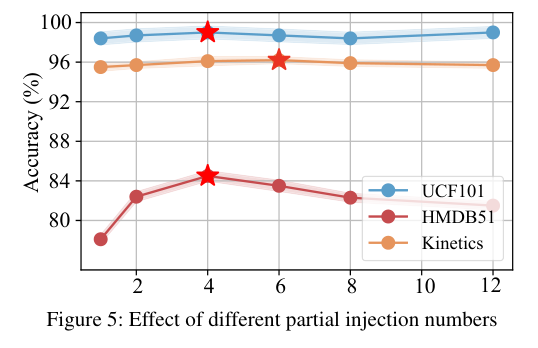
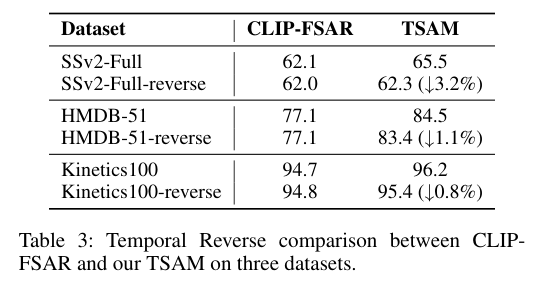
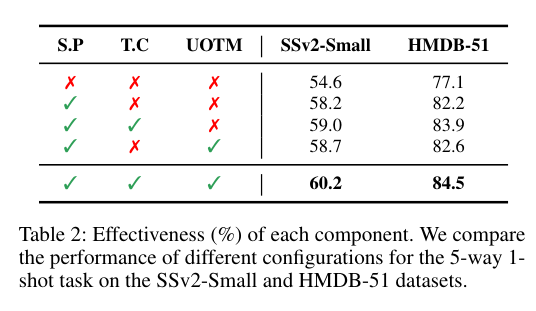
4)方法:本文提出一种新的时序序列感知模型(TSAM),将序列感知适配器引入预训练框架中,以整合空间信息和时序动态。与现有方法不同,该模型通过基于感知器的适配器递归地捕捉时间线上的顺序动态,能够感知顺序变化。为了获取每个类别的区分性表示,研究者还从大型语言模型(LLMs)中扩展了每个类别的文本语料,并通过整合上下文语义信息来丰富视觉原型。此外,作者引入了一种不平衡最优传输策略,用于特征匹配,减轻与类别无关的特征的影响,从而促进更有效的决策。
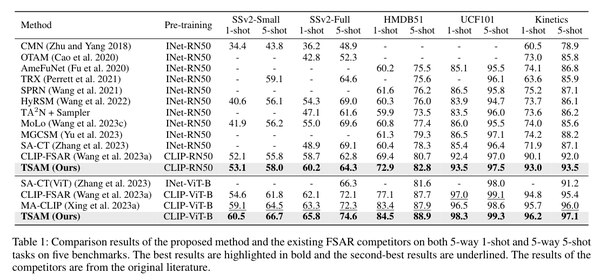
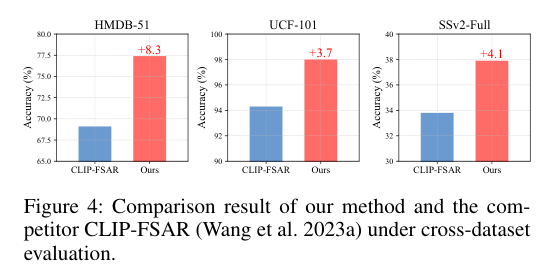
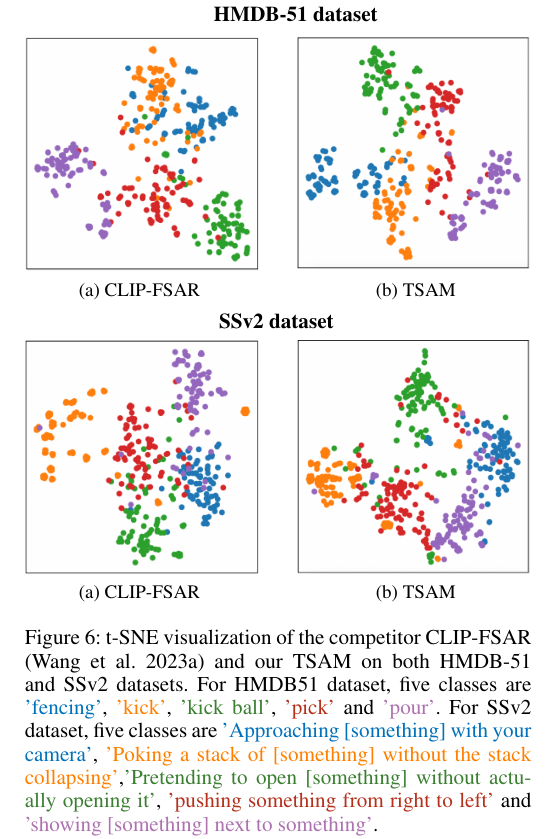
5)结果:实验结果表明,在五个少样本动作识别数据集上,该方法设立了新的基准,相较于第二好的竞品有显著的提升。

















 824
824

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











