







模型介绍
支持向量机是一种判别模型。在类别划分的时候,我们希望能找到这样一个超平面,这个超平面对训练样本的泛化能力最好,也就是对极端异常值的容忍度最好。那么如何达到这个目的呢?SVM的方法是找到距离这个超平面最近的且分类正确的点,这个点就叫支持向量,让这个点到超平面的距离最远,这样一来,超平面的泛化能力就能达到最优。
模型推导
我们定义超平面为
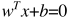 公式1.1
公式1.1
定义训练集中的任意一点X到超平面的距离为
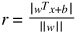 公式1.2
公式1.2
我们令Y的取值为+1和-1,但是要注意,这里有一个限制条件,超平面必须是能把训练集全部分类正确的平面(硬间隔),那么要加一个条件,
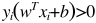 公式1.3
公式1.3
公式1.3的目的是为了让真实值的Y和预测值的Y同号,符号一致则表示分类正确。
由空间几何的知识我们可以得知,W和b成比例的放缩并不会影响到最优化问题的解,也就是公式1.1的取值并不会影响到求解,所以为了方便计算,不妨将其的模取值为1。那么公式1.2和公式1.3就转化为
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 7464
7464











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









