







- 交叉验证概述
进行模型验证的一个重要目的是要选出一个最合适的模型,对于监督学习而言,我们希望模型对于未知数据的泛化能力强,所以就需要模型验证这一过程来体现不同的模型对于未知数据的表现效果。
最先我们用训练准确度(用全部数据进行训练和测试)来衡量模型的表现,这种方法会导致模型过拟合;为了解决这一问题,我们将所有数据分成训练集和测试集两部分,我们用训练集进行模型训练,得到的模型再用测试集来衡量模型的预测表现能力,这种度量方式叫测试准确度,这种方式可以有效避免过拟合。
测试准确度的一个缺点是其样本准确度是一个高方差估计(high varianceestimate),所以该样本准确度会依赖不同的测试集,其表现效果不尽相同。
- K折交叉验证
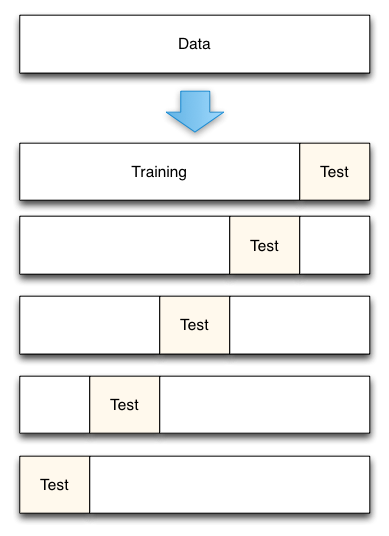
- 将数据集平均分割成K个等份
- 使用1份数据作为测试数据,其余作为训练数据
- 计算测试准确率
- 使用不同的测试集,重复2、3步骤
- 对测试准确率做平均,作为对未知数据预测准确率的估计
- sklearn.model_selection.Kfold
classsklearn.model_selection.KFold(n_splits=3,shuffle=False, random_state=None)
参数:
n_splits : 默认3,最小为2;K折验证的K值
shuffle : 默认False;shuffle会对数据产生随机搅动(洗牌)
random_state :默认None,随机种子
方法:
get_n_splits([X, y, groups]) Returnsthe number of splitting iterations in the cross-validator
split(X[, y, groups]) Generateindices to split data into training and test set.
- 下面代码演示了K-fold交叉验证是如何进行数据分割的
# 25个样本分为5个样本集
fromsklearn.cross_validation import KFold
kf = KFold(25,n_folds=5, shuffle=False)
# 打印出每次训练集和验证集
print '{} {:^61}{}'.format('Iteration', 'Training set observations', 'Testing setobservations')
for iteration, datain enumerate(kf, start=1):
print '{:^9} {} {:^25}'.format(iteration,data[0], data[1])Iteration Training setobservations Testingset observations
1 [ 5 6 7 8 9 10 11 12 13 14 15 16 17 18 1920 21 22 23 24] [0 1 2 3 4]
2 [ 0 1 2 3 4 10 11 12 13 14 15 16 17 18 1920 21 22 23 24] [5 6 7 8 9]
3 [ 0 1 2 3 4 5 6 7 8 9 1516 17 18 19 20 21 22 23 24] [10 11 1213 14]
4 [ 0 1 2 3 4 5 6 7 8 9 1011 12 13 14 20 21 22 23 24] [15 16 1718 19]
5 [ 0 1 2 3 4 5 6 7 8 9 1011 12 13 14 15 16 17 18 19] [20 21 2223 24]
#分出25个数据的五分之一作为测试集,剩下的作为训练集,这里没有对数据进行洗牌,所以按数据的顺序进行选择。训练-测试的组合也为五次。
- sklearn.cross_validation模块
cross validation大概的意思是:对于原始数据我们要将其一部分分为traindata,一部分分为test data。train data用于训练,test data用于测试准确率。在test data上测试的结果叫做validation error。将一个算法作用于一个原始数据,我们不可能只做出随机的划分一次train和testdata,然后得到一个validation error,就作为衡量这个算法好坏的标准。因为这样存在偶然性。我们必须多次的随机的划分train data和test data,分别在其上面算出各自的validation error。这样就有一组validationerror,根据这一组validationerror,就可以较好的准确的衡量算法的好坏。crossvalidation是在数据量有限的情况下的非常好的一个evaluate performance的方法。而对原始数据划分出train data和testdata的方法有很多种,这也就造成了cross validation的方法有很多种。
- 主要函数
sklearn中的cross validation模块,最主要的函数是如下函数:
sklearn.cross_validation.cross_val_score
调用形式是:sklearn.cross_validation.cross_val_score(estimator, X, y=None, scoring=None, cv=None,n_jobs=1, verbose=0, fit_params=None, pre_dispatch='2*n_jobs')
返回值就是对于每次不同的的划分raw data时,在test data上得到的分类的准确率。
- 参数解释:
estimator:是不同的分类器,可以是任何的分类器。比如支持向量机分类器:estimator = svm.SVC(kernel='linear', C=1)
cv:代表不同的cross validation的方法。如果cv是一个int值,并且如果提供了rawtarget参数,那么就代表使用StratifiedKFold分类方式;如果cv是一个int值,并且没有提供rawtarget参数,那么就代表使用KFold分类方式;也可以给定它一个CV迭代策略生成器,指定不同的CV方法。
scoring:默认Nnoe,准确率的算法,可以通过score_func参数指定;如果不指定的话,是用estimator默认自带的准确率算法。
- 几种不同的CV策略生成器
cross_val_score中的参数cv可以接受不同的CV策略生成器作为参数,以此使用不同的CV算法。除了刚刚提到的KFold以及StratifiedKFold这两种对rawdata进行划分的方法之外,还有其他很多种划分方法,这里介绍几种sklearn中的CV策略生成器函数。
- K-fold
最基础的CV算法,也是默认采用的CV策略。主要的参数包括两个,一个是样本数目,一个是k-fold要划分的份数。
fromsklearn.model_selection import KFold
X= np.array([[1, 2], [3, 4], [1, 2], [3, 4]])
y= np.array([1, 2, 3, 4])
kf= KFold(n_splits=2)
kf.get_n_splits(X)#给出K折的折数,输出为2
print(kf)
#输出为:KFold(n_splits=2, random_state=None,shuffle=False)
for train_index, test_index in kf.split(X):
print("TRAIN:",train_index, "TEST:", test_index)
X_train,X_test = X[train_index], X[test_index]
y_train,y_test = y[train_index], y[test_index]
#输出:TRAIN: [2 3] TEST: [0 1]
TRAIN: [0 1] TEST: [2 3]#这里kf.split(X)返回的是X中进行分裂后train和test的索引值,令X中数据集的索引为0,1,2,3;第一次分裂,先选择test,索引为0和1的数据集为test,剩下索引为2和3的数据集为train;第二次分裂,先选择test,索引为2和3的数据集为test,剩下索引为0和1的数据集为train。
- Stratified k-fold
与k-fold类似,将数据集划分成k份,不同点在于,划分的k份中,每一份内各个类别数据的比例和原始数据集中各个类别的比例相同。
classsklearn.model_selection.StratifiedKFold(n_splits=3,shuffle=False, random_state=None)
from sklearn.model_selection importStratifiedKFold
X= np.array([[1, 2], [3, 4], [1, 2], [3, 4]])
y= np.array([0, 0, 1, 1])
skf= StratifiedKFold(n_splits=2)
skf.get_n_splits(X, y)#给出K折的折数,输出为2
print(skf)
#输出为:StratifiedKFold(n_splits=2,random_state=None, shuffle=False)
for train_index, test_index in skf.split(X, y):
print("TRAIN:",train_index, "TEST:", test_index)
X_train,X_test = X[train_index], X[test_index]
y_train,y_test = y[train_index], y[test_index]
#输出:TRAIN: [1 3] TEST: [0 2]
TRAIN: [0 2] TEST: [1 3]- Leave-one-out
每个样本单独作为验证集,其余的N-1个样本作为训练集,所以LOO-CV会得到N个模型,用这N个模型最终的验证集的分类准确率的平均数作为此下LOO-CV分类器的性能指标。参数只有一个,即样本数目。
from sklearn.model_selection import LeaveOneOut
X= [1, 2, 3, 4]
loo= LeaveOneOut()
for train, test in loo.split(X):
print("%s%s" % (train, test))
#结果:[1 2 3] [0]
[0 23] [1]
[0 13] [2]
[0 12] [3]- Leave-P-out
每次从整体样本中去除p条样本作为测试集,如果共有n条样本数据,那么会生成(n p)个训练集/测试集对。和LOO,KFold不同,这种策略中p个样本中会有重叠。
from sklearn.model_selection import LeavePOut
X= np.ones(4)
lpo= LeavePOut(p=2)
for train, test in lpo.split(X):
print("%s%s" % (train, test))
#结果:[2 3] [0 1]
[13] [0 2]
[12] [0 3]
[03] [1 2]
[02] [1 3]
[01] [2 3]- Leave-one-label-out
这种策略划分样本时,会根据第三方提供的整数型样本类标号进行划分。每次划分数据集时,取出某个属于某个类标号的样本作为测试集,剩余的作为训练集。
from sklearn.model_selection import LeaveOneLabelOut
labels = [1,1,2,2]
Lolo=LeaveOneLabelOut(labels)
for train, test in lolo:
print("%s%s" % (train, test))
#结果:[2 3] [0 1]
[01] [2 3]- Leave-P-Label-Out
与Leave-One-Label-Out类似,但这种策略每次取p种类标号的数据作为测试集,其余作为训练集。
from sklearn.model_selection import LeavePLabelOut
labels = [1,1,2,2,3,3]
Lplo=LeaveOneLabelOut(labels,p=2)
for train, test in lplo:
print("%s%s" % (train, test))
#结果:[4 5] [0 1 2 3]
[2 3] [0 1 4 5]
[0 1] [2 3 4 5]















 5998
5998

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









