






目录
Q-learning algorithm: learning the Action Value Function
两天学习Q-learning算法,先看了莫烦的视频,大概了解了算法的流程,但仍然有很多不懂的地方。

网上又看到这篇文章,讲得更通俗易懂点,在此翻译总结一下,以便自己记住。原文章链接: https://medium.freecodecamp.org/diving-deeper-into-reinforcement-learning-with-q-learning-c18d0db58efe
文章纲要
- 什么是Q-Learning
- 怎么用Numpy实现
介绍Q-table
Each Q-table score("Q" for the "quality" of the action)will be the maximum expected future reward that I'll get if I take the action at that state with the best policy given.
那么怎样计算Q table中的每个元素的值呢? 我们将采用Q learning 算法来学习Q-table的每个值。
Q-learning algorithm: learning the Action Value Function
Action Value Function(或“Q-function”)有两个输入:“state”和“action”。其返回在该state下选择该action的expected future reward:
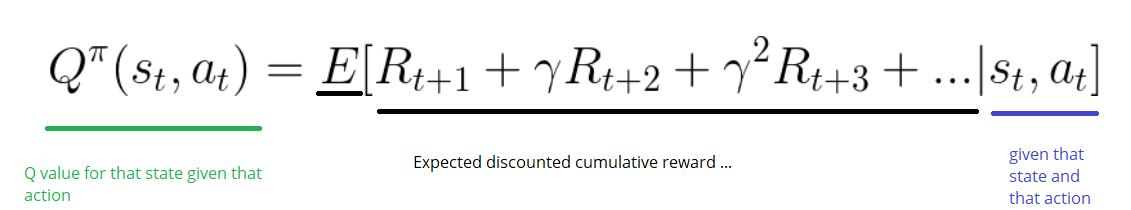
我们可以把这个Q function看做是一个读者,在Q-t
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









