







hypothesis:
cost function:
goal:
minisize(J)
梯度下降算法:
用来求函数最小值, 此处用来求代价函数J的最小值。
其中,
要同时改变
算法推导:
梯度下降算法事件1:特征缩放
最简单的缩放是:
梯度下降算法实践2:alpha(learning rate)
需要绘制cost function来观察在何处收敛
或者使用设置阈值的方式来判读收敛,但一般图像更能只管的观察
alpha过小,则达到收敛所需要的迭代次数非常高
alpha过大,可能会越过局部最小值导致无法收敛
一般考虑alpha = 0.001, 0.003, 0.01, 0.03, 0.1, 0. 3, 1, 10
特征和多项式回归:
正规方程算法(与梯度下降算法相对应):
原理:
为了寻求最优解,在低维的时候,正规方程组是最直接的方式。因为它要计算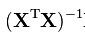

图1
图1中,矩阵X记录了特征值,向量y是实际的数据。要使h(x)与y的偏差最小,将要计算
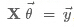
就将问题转化为正规方程组,这种解决方式被称为“inconsistent”,下面给出证明:

更直观的图表解释:
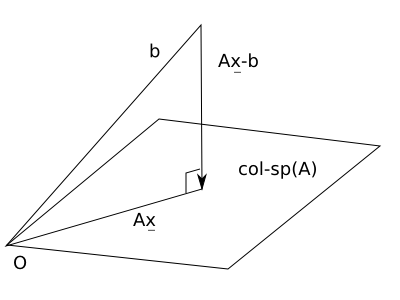
当矩阵A的宽度小于它的高度时, A x = b 的解可用: 满足 A' (A x - b) = 0 的 x 来近似。
A x 的几何意义: 当 x 自由变动, A x 产生 A 的 column space。
A x = b 想要有解, b 必须落在 A x 的 column space 当中。
b 若不落在 A x 的 column space 当中, 只好退而求其次: 至少 b 的 投影projection 必然落在此空间当中 (by definition)。
试图寻找 x 使得 A x - b 的长度 (也就是误差值) 最小。
比较:















 262
262

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









