






前言
在MyBatis中,映射器是一个强大的工具,也是一个核心工具,所有的操作都离不开映射器。MyBatis是针对映射器构造的SQL构建的轻量级框架,通过映射器,我们可以将查询结果映射成一个JavaBean返回给调用者。通过映射器我们可以完成对数据的增、删、改、查操作,其中难点在于结果集映射缓存。接下来我们进行详细介绍
1.映射器主要元素
首先通过一张表格来展示映射器的基本元素:
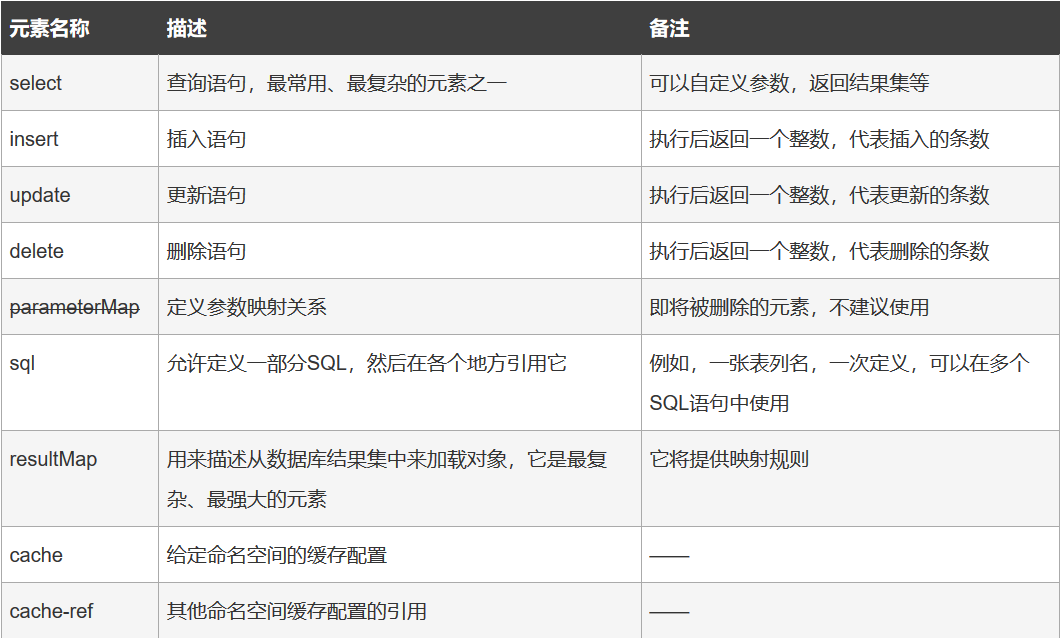
1.1 select元素
select元素是我们常用的SQL语言,我们通过它从数据库里面读取数据,select通过如下元素的配置实现其强大的功能:

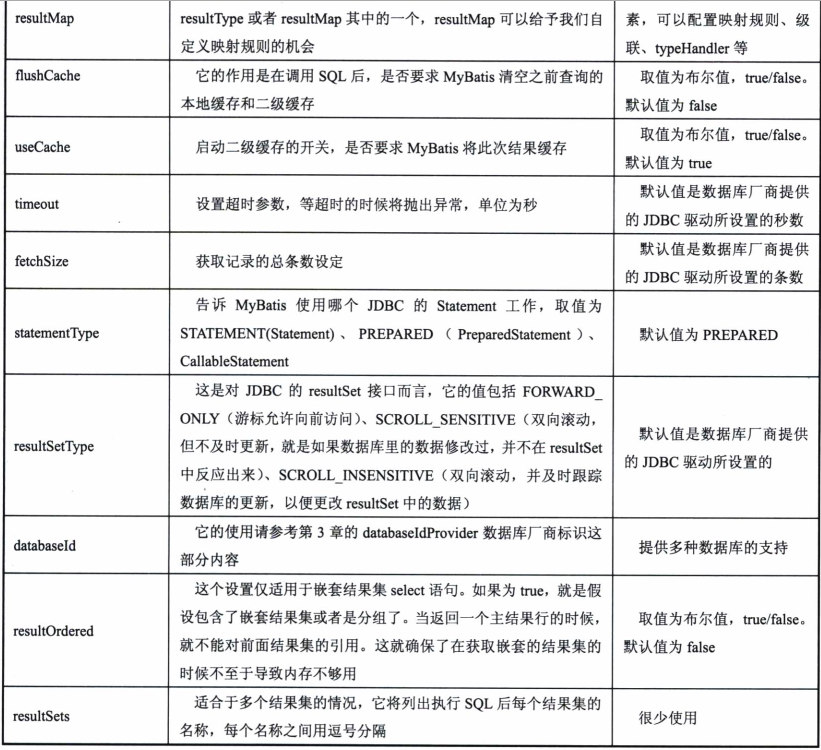
上面的表格列出了所有的配置,我们可以根据需求应用不同的配置,接下来将介绍关键的配置
一个简单的实例
mapper.xml中的配置
<select id="countFirstName" parameterType="string"
resultType="int">
select count(1) from t_user where user_name like
concat(#{firstName},'%')
</select>接口如下:
public int countFirstName(String firstname);分析:
a、id标识了这条SQL,同时id与方法名相同
b、parameterType定义传入的参数类型
c、resultType 定义返回值类型
自动映射
想要完成自动必须满足如下要求
①开启自动映射
开启映射可以在setting中设置autoMappingBehavior属性值,包含3个值:
a、NONE,取消自动映射。
b、PARTIAL,只会自动映射,没有定义嵌套结果集映射的结果集(默认)。
c、FULL,会自动映射任何复杂的结果集(无论是否嵌套),这将会使性能下降
②SQL列名和JavaBean的属性一致,查询结果会自动回填到相应的字段中
存在一个问题:往往SQL中列的命名是以下划线分隔,如:ROLE_NAME,而Java中采用驼峰的方式命名,如:roleName,这样就给一一对应关系造成麻烦。
解决方法:
a、在查询的时候使用列的别名的方式。

b、在setting中设置mapUnderscoreToCameCase为true。
传递多个参数的方法
在我们用select语句查询数据的时候,大多时候都需要多个参数,上面我们了解了传递一个参数的方法,接下来我们介绍传递多个参数的方法,传递多个参数一共有3种方法。
第一种:使用Map传递参数
实现原理:就是将多个参数封装在Map集中,然后传给调用的接口,相应的parameterType的值也设置为map
接口
public List<Role> findRolesByMap(Map<String, Object> parameterMap);Mapper.xml文件
<select id="findRolesByMap" parameterType="map"
resultType="role">
select id,role_name as roleName,note from t_role where
role_name like
concat('%',#{roleName},'%') and note like
concat('%',#{note},'%')
</select>传递参数
RoleMapper roleMapper = sqlSession.getMapper(RoleMapper.class);
Map<String, Object> parameterMap = new HashMap<>();
parameterMap.put("roleName", "1");
parameterMap.put("note", "1");
List<Role> roles = roleMapper.findRolesByMap(parameterMap);弊端:因为Map需要键值对应,造成业务关联性不强,需要深入程序看代码,造成可读性降低。
第二种:使用注解方式传递参数
应用@Param注解来实现想要的功能
接口:
public List<Role> findRolesByAnnotation(@Param("roleName") String roleName, @Param("note") String note);Mapper.xml文件
<select id="findRolesByAnnotation" resultType="role">
select
id,role_name as roleName,note from t_role where
role_name like
concat('%',#{roleName},'%') and note like
concat('%',#{note},'%')
</select>问题:相对第一种方法,可读性大大提高,但是如果参数过多,会造成代码复杂,从而可读性仍然不高。
第三种:使用JavaBean传递参数
定义参数JavaBean
public class RoleParams {
private String roleName;
private String note;
public String getRoleName() {
return roleName;
}
public void setRoleName(String roleName) {
this.roleName = roleName;
}
public String getNote() {
return note;
}
public void setNote(String note) {
this.note = note;
}
}接口
public List<Role> findRolesByBean(RoleParams roleParam);Mapper.xml文件
<select id="findRolesByBean"
parameterType="com.hys.mybatis.example3.pojo.RoleParams"
resultType="role">
select
id,role_name as roleName,note from t_role where
role_name like
concat('%',#{roleName},'%') and note like
concat('%',#{note},'%')
</select>调用
RoleMapper roleMapper = sqlSession.getMapper(RoleMapper.class);
RoleParams roleParams = new RoleParams();
roleParams.setRoleName("1");
roleParams.setNote("1");
List<Role> roles = roleMapper.findRolesByBean(roleParams); 在开发过程中,要根据实际情况合理运用,第一种方法由于可读性太低不建议使用,当参数较少的时候使用第二种方法,当参数较多的时候使用第三种方法,还可以混合使用。
1.2 insert元素
执行插入操作,应用时也需要相应的配置,具体配置方法如下
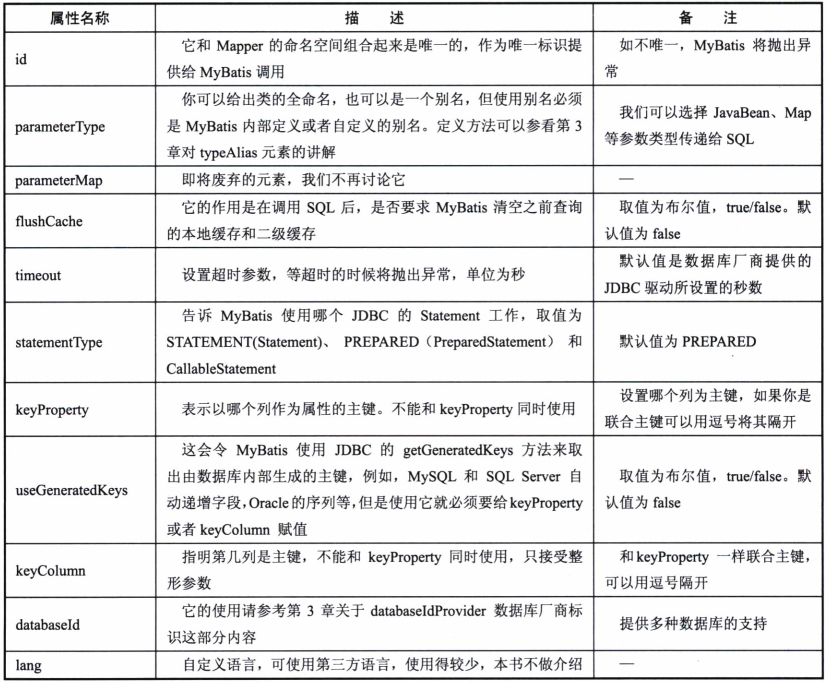
示例代码
<insert id="insertRole" parameterType="role">
insert into
t_role(role_name,note) values(#{roleName},#{note})
</insert>主键回填和自定义
主键回填:主键有可能是自增字段,如MySQL中的auto_increment,在插入后我们往往需要获得主键,我们可以通过如下方法获得。
JDBC中的Statement对象在执行插入的SQL后,可以通过getGeneratedKeys方法获得数据库生成的主键(需要数据库驱动支持),这样便能达到获取主键的功能。在insert语句中有一个开关属性useGeneratedKeys,用来控制是否打开这个功能,它的默为false。当打开了这个开关,还要配置其属性keyProperty或keyColumn,告诉系统把生成的主键放入哪个属性中,如果存在多个主键,就要用逗号(,)将它们隔开。
示例:
<insert id="insertRole" parameterType="role"
useGeneratedKeys="true" keyProperty="id">
insert into
t_role(role_name,note)
values(#{roleName},#{note})
</insert>我们传入role对象无序设置id值,MyBatis用数据库设置进行处理,当插入完成后,它会回填JavaBean的id值。
自定义主键
有时候主键可能依赖于某些规则,比如取消角色表(t_role)的id的递增规则,而将其规则修改为:
当角色表记录为空时,id设置为1。当角色表记录不为空时,id设置为当前id加3。
MyBatis对这样的场景也提供了支持,它主要依赖于selectKey元素进行支持,它允许自定义键值的生成规则。映射XML如下:
<insert id="insertRole" parameterType="role">
<selectKey keyProperty="id" resultType="long" order="BEFORE">
select
if (max(id)=null,1,max(id)+3) from t_role
</selectKey>
insert into
t_role(id,role_name,note)
values(#{id},#{roleName},#{note})
</insert>上述代码定义了selectKey元素,它的keyProperty指定了采用哪个属性作为POJO的主键。resultType告诉MyBatis将返回一个long型的结果集,而order设置为BEFORE,说明它将于当前定义的SQL前执行。
1.3 update元素和delete元素
因为update元素和delete元素比较简单,所以把它们放在一起论述。它们和insert的属性差不多,执行完也会返回一个整数,用以标识该SQL语句影响了数据库的记录行数。映射XML如下:
<update id="updateRole" parameterType="role">
update t_role set
role_name=#{roleName},note=#{note} where id=#{id}
</update>
<delete id="deleteRole" parameterType="long">
delete from t_role where
id=#{id}
</delete>最后MyBatis会返回一个整数,标识对应的SQL执行后会影响了多少条数据库表里的记录。至于参数可以参考select元素的参数规则,在MyBatis中它们的规则是通用的。
1.4 sql元素
作用:当我们编写大量的重复sql语句的时候,为了提高代码可读性和降低重复率,我们可以把这些代码提取出来,放在sql元素中。这样在其他SQL语句中就可以引用这段代码。
实例一(普通的sql代码块)
<resultMap type="role" id="roleMap">
<id property="id" column="id" />
<result property="roleName" column="role_name" />
<result property="note" column="note" />
</resultMap>
<sql id="roleCols">
id,role_name,note
</sql>
<select id="getRole" parameterType="long" resultMap="roleMap">
select
<include refid="roleCols" />
from t_role where id=#{id}
</select>实例二(可以传递参数的sql代码块)
<sql id="roleCols">
${alias}.id,${alias}.role_name,${alias}.note
</sql>
<select id="getRole" parameterType="long" resultMap="roleMap">
select
<include refid="roleCols">
<property name="alias" value="r" />
</include>
from t_role r where id=#{id}
</select>sql代码块中也可以引入其他的代码块,同样适用<include refid=""></include>
1.5 引入参数
注:定义参数属性的时候,MyBatis不允许换行。
参数配置
#{age,javaType=int ,jdbcType=NUMERIC}
#{age,javaType=int ,jdbcType=NUMERIC,typeHandler=MyTypeHandler}
#{price,javaType=double,jdbcType=NUMERIC,numericScale=2}存储过程
存储过程包含三种参数,输入参数(IN),输出参数(OUT),输入输出参数(INOUT),在MyBatis中通过指定mode属性来确定是哪一种参数,model属性有3个选项:IN,OUT,INOUT。当返回的是一个游标的时候(JdbcType=CURSOR),我们需要设置resultMap将存储过程的参数映射到对应的类型,MyBatis通过设置的resultMap自动为我们设置映射结果。其中javaType是可选的,不指定MyBatis会自动检测。
#{role,mode=OUT,jdbcType=CURSOR,javaType=ResultSet,resultMap=roleResultMap}传入的参数可能是结构体,需要指定语句类型的名称
![]()
#{}和${}的区别
#{}表示一个占位符号,通过#{}可以实现preparedStatement向占位符中设置值,自动进行java类型和jdbc类型转换,#{}可以有效防止sql注入。 #{}可以接收简单类型值或pojo属性值。 如果parameterType传输单个简单类型值,#{}括号中可以是value或其它名称。
${}表示拼接sql串,通过${}可以将parameterType 传入的内容拼接在sql中且不进行jdbc类型转换, ${}可以接收简单类型值或pojo属性值,如果parameterType传输单个简单类型值,${}括号中只能是value。
1.6 resultMap结果集映射
前面我们了解了简单的结果映射resultType,但是要映射复杂的结果集的时候就需要用到resultMap,resultMap是用在mapper.xml文件中的
resultMap的作用是定义映射规则、级联的更新、定制类型转化器等。resultMap定义的主要是一个结果集的映射关系,也就是SQL到Java Bean的映射关系定义,它也支持级联等特性。只是MyBatis现有的版本只支持resultMap查询,不支持更新或者保存,更不必说级联的更新、删除和修改了。
基本框架
<resultMap>
<constructor>
<idArg />
<arg />
</constructor>
<id />
<result />
<association />
<collection />
<discriminator>
<case />
</discriminator>
</resultMap>resultMap结果映射集的配置项如上所示,接下来我们将进行一一介绍
constructor元素
作用:用于配置构造方法,当一个POJO不存在没有参数的构造器时,就要用它来配置
代码:
<resultMap ...>
<constructor>
<idArg column="id" javaType="int" />
<arg column="role_name" javaType="string" />
</constructor>
<!-- do something... -->
</resultMap>代码中idArg定义了主键是哪个属性,arg定义普通的属性。
id和result元素
作用:id表示哪个列是主键,允许有多个主键,多个主键称为联合主键,result是配置POJO到SQL列名的映射关系
id和result元素共有的属性:
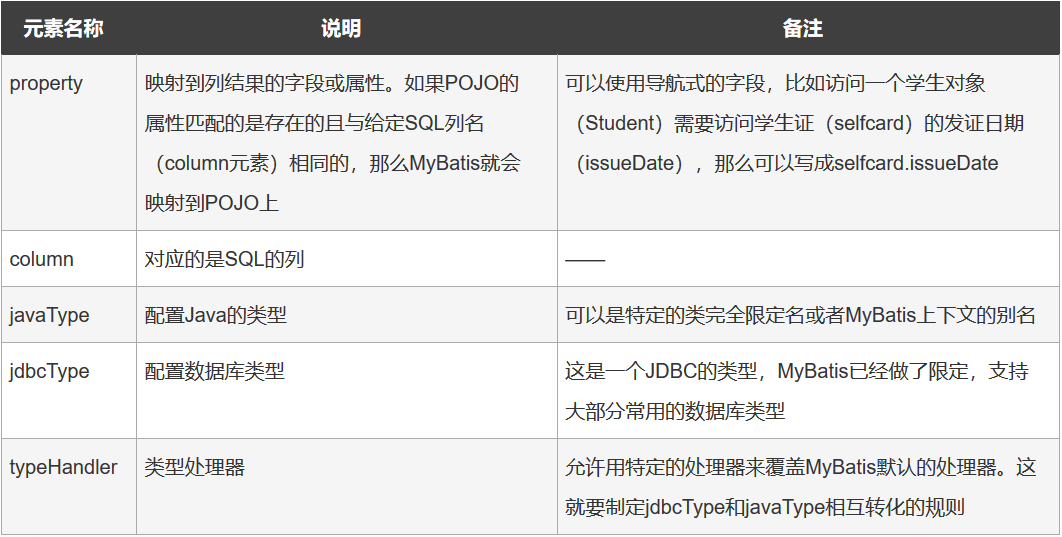
结果集存储方法
第一种:使用map存储结果集
a、通过@MapKey指定Map的key,这个key一般为SQL的一个列名通常为主键
@MapKey("id")
Map<Long, UserInfo> getUserInfoMap();
@MapKey("id")
Map<Long, Map<String,Object>> getUserValueMap();b、映射文件
<select id="getUserValueMap" resultType="map" >
select id,username,sex from user_info
from user_info
</select><resultMap id="UserResultMap" type="com.xixicat.domain.UserInfo">
<result property="id" column="id" />
<result property="username" column="username" />
<result property="sex" column="sex" />
</resultMap>
<select id="getUserInfoMap" resultMap="UserResultMap">
select id,username,sex from user_info
</select>注:第一段配置文件的结果,map的value也是一个map,value中是key为列名,value为具体数据的map。第二段配置文件的结果是java对象。上面两种方法都可以得到多条查询结果,但是,第一种得到的map中value是map,第二种得到的map中value是java对象。
map原则上可以匹配所有结果集,但用map存储结果集的缺点是造成可读性下降。
第二种:使用POJO存储结果集
步骤如下:
a、映射文件中配置resultMap
<resultMap id="UserResultMap" type="com.xixicat.domain.UserInfo">
<result property="id" column="id" />
<result property="username" column="username" />
<result property="sex" column="sex" />
</resultMap>b、映射文件中配置相应的操作
<select id="getUserInfoMap" resultMap="UserResultMap">
select id,username,sex from user_info
</select>在配置中还有三个元素,association,colleciation,discriminatior这三个元素分别代表一对一级联、多对多级联、鉴别器级联,由于级联知识点相对复杂,我们在下一节单独介绍。
1.7 级联
通俗的讲级联就是一个POJO里包含一个或者一组POJO,比如一个学生有一个学生证(一对一级联),我们可以在学生信息类中添加一个学生证类对象属性,在查询的时候要根据学生ID查询学生证信息,还有一种情况是学生和选课的关系,一个学生可以选多门课程(一对多级联)。 在MyBatis中还有一种被称为鉴别器的级联,它是一种可以选择具体实现类的级联,比如要查找雇员及其体检表的信息,但是雇员有性别之分,而根据性别的不同,其体检表的项目也会不一样,比如男性体检表可能有前列腺的项目,而女性体检表可能有子宫的项目,那么体检表就应该分为男性和女性两种,从而根据雇员性别区分关联。
级联不是必须的,级联的好处是获取关联数据十分便捷,但是级联过多会增加系统的复杂度(比如查询学生信息,会同时加载学生证信息等,多一层级联就多一条SQL语句),同时降低系统的性能,此增彼减,所以当级联的层级超过3层时,就不要考虑使用级联了,因为这样会造成多个对象的关联,导致系统的耦合、复杂和难以维护。在现实的使用过程中,要根据实际情况判断是否需要使用级联。
级联的分类
a、一对一级联
b、一对多级联
c、鉴别器级联
由于多对多级联相对复杂,而且可以被一对多级联替换,所以MyBatis没有多对多级联
接下来我们将介绍三种级联的代码实现,我们以学生信息为例,一个学生有一张学生证,一个学生可以选多门课程,一门课程对应一张成绩单,根据性别不同拥有不同的体检报告。
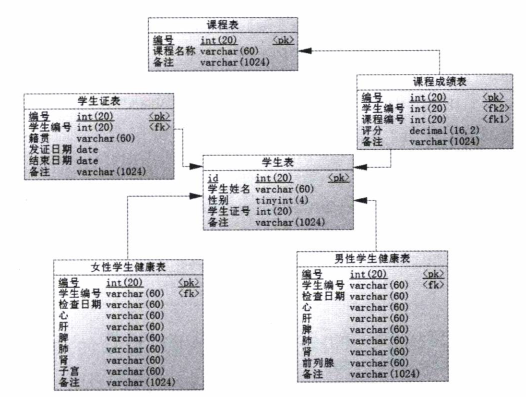
配置文件
<mapper namespace="com.learn.chapter4.mapper.StudentMapper">
<resultMap id="studentMap" type="com.learn.chapter4.po.StudentBean">
<id property="id" column="id"/>
<result propert="cnname" column="cnname"/>
<result propert="sex" column="sex" jdbcType="INTEGER" javaType="com.learn.chapter4.enums.SexEnum"
typeHandler="com.learn.chapter4.typehandler.SexTypeHandler"/>
<result propert="note" column="note"/>
<association property="studentSelfcard" column="id"
select="com.learn.chapter4.mapper.StudentSelfcardMapper.findStudentsSelfcardByStudentId"/>
<collection property="studentLectureList" column="id"
select="com.learn.chapter4.mapper.StudentLectureMapper.findStudentLectureByStuId"/>
<discriminator javaType="int" column="sex">
<case value="1" resultMap="maleStudentMap"/>
<case value="2" resultMap="femaleStudentMap"/>
</discriminator>
</resultMap>
<select id="getStudent" parameterType="int" resultMap="studentMap">
select id,cnname,sex,note from t_student where id = #{id}
</select>
<resultMap id="maleStudentMap" type="com.learn.chapter4.po.MaleStudentBean" extends="studentMap">
<collection property="studentHealthMaleList" select="com.learn.
chapter4.mapper.StudentHealthMaleMapper.findStudentHealthMaleByStuId" columns="id"/>
</resultMap>
<resultMap id="femaleStudentMap" type="com.learn.chapter4.po.FemaleStudentBean" extends="studentMap">
<collection property="studentHealthMaleList" select="com.learn.
chapter4.mapper.StudentHealthMaleMapper.findStudentHealthFemaleByStuId" columns="id"/>
</resultMap>
</mapper>
文件解析:
association:select指的是要使用哪个具体的SQL去查询,点位方式是mapper文件的命名空间+SQL的ID,这样便可以指向对应Mapper的SQL,MyBatis就会通过对应的SQL将数据查询回来。column代表SQL的列,用作参数传递给select属性制定的SQL,如果是多个参数,则需要用逗号隔开。
collection:property属性指定将结果集存储在哪里,select指定的查询将返回的结果集存入。
discriminator:column属性指定用哪个字段进行鉴别,case相当于switch语句中的case,根据sex的值选择相应的resultMap。
extends属性指定当前resultMap继承哪个resultMap,这个继承和类的继承一样,可以加入新的配置。
注:这个文件中只写了核心的级联配置,级联操作所涉及的配置文件并没有给出(如:StudentSelfcardMapper.xml),这些文件是最基础的映射文件,在这里不进行一一给出。
级联带来的问题
a、当级联层数过多的时候,造成复杂度过高,不利于维护,同时级联往往会获取所有的数据,这样会增加执行的SQL语句,导致性能降低。
b、N+1问题,有N个关联,比如Student表关联了很多表,当我们取出一个student对象,所有的信息都会被取出,导致性能下降。
为了解决这样的问题,MyBatis给出了延迟加载功能。
延迟加载
当我们读取数据的时候,只读取当前需要的信息,级联的信息只有当我们需要的时候才读取。
配置级联的两个全局参数lazyLoadingEnabled和aggressiveLazyLoading,这两个参数是在setting中设置。
lazyLoadingEnabled:全局开启或关闭延迟加载
aggressiveLazyLoading:是否开启层级加载

层级加载:级联有可能延伸多层,如果开启层级加载,当加载某一个层级中的一个对象的时候,这个层级中所有的对象都会被加载;如果关闭层级加载,访问那个对象就加载那个对象,不会加载别的对象。
问题:如果使用严格的延迟加载,按需求加载对象,同样会带来一个问题。当我们需要某个对象立即加载的时候这种设置就非常的不灵活。如在加载学生信息的同时立即加载学生成绩信息。
解决方法:MyBatis提供了fetchType属性,我们可以在局部设置延迟加载,弥补上面的不灵活。 fetchType可加在在级联元素(association、collection,注意,discriminator没有这个属性可配置)中 ,覆盖全局设置。
fechType属性
有两个属性值:
a、eager,立即加载
b、lazy,延迟加载
实例:
<association property="studentSelfcard" column="id" fetchType="lazy"
select="com.learn.chapter4.mapper.StudentSelfcardMapper.findStudentsSelfcardByStudentId"/>
<collection property="studentLectureList" column="id" fetchType="eager"
select="com.learn.chapter4.mapper.StudentLectureMapper.findStudentLectureByStuId"/>
还存在另外一种级联,用一条SQL查询所有信息,这种SQL语句复杂,需要根据实际情况选择。这种方式没有N+1的问题。

ofType:定义collection里面的泛型是什么Java类型。
1.8缓存
将常用的数据存放在内存中,提高整个系统的性能。缓存的关键是存储内容访问的命中率。缓存分为系统缓存和自定义缓存,系统缓存分为一级缓存和二级缓存,自定义缓存可以应用目前主流的缓存服务器,如:MongonDB、Redis、Ehcache等。
系统缓存
一级缓存(默认开启)
作用域:只相对于同一个SqlSession而言。
二级缓存
作用域:在SqlSessionFactory层面上能够提供给各个SqlSession对象共享。
开启条件:返回的POJO必须是可序列化的,即要求实现Serializable接口,否则会抛出异常。
开启方法:<cache/>
默认配置
a、映射语句文件中的所有select语句将会被缓存。
b、映射语句中的所有insert、update、delete语句会刷新缓存。
c、缓存会使用默认的Least Recently Used(LRU,最近最少使用的)算法来回收。
d、根据时间表,比如No Flush Interval,(CNFI,没有刷新间隔),缓存不会以任何时间顺序来刷新。
e、缓存会存储列表集合或对象(无论查询方法返回什么)的1024个引用。
f、缓存会被视为是read/write(可读/可写)的缓存,意味着对象检索不是共享的,而且可以安全的被调用者修改,不干扰其他调用者或线程所做的潜在修改。
更改配置

属性
①eviction:缓存回收策略
a、LRU:最近最少使用的
b、FIFO:先进先出
c、SOFT:软引用,移除基于垃圾回收器状态和软引用规则的对象
d、WEAK:弱引用,更积极的移除基于垃圾回收器转台和弱引用规则的对象。
②flushInterval:刷新间隔时间,单位为毫秒。
③size:引用数目,一个正整数,代表缓最对可以存储多少个对象,不宜过大。
④readOnly:只读,意味着缓存数据只能读取而不能修改,默认是false。
自定义缓存
我们可以自己定制缓存。如实现Redis缓存。需要实现org.apache.ibatis.cache.Cache
用如下代码配置
<cache type="缓存实现类的全名称">
<property name="host" value="localhost"/>
</cache>配置SQL层面上的缓存规则:userCache和flushCache分别是是否使用缓存和插入后是否刷新缓存。

总结
我们已经完整的介绍了映射器的配置,其中的重点是resultMap的配置,级联的使用,和缓存的配置,通过学习我们了解了MyBatis强大的功能。















 2907
2907











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









