






1、Python由模块构成,一个模块对应一个源文件
2、模块由语句组成,运行时,按照模块中的语句的顺序执行
3、始终保持ctrl+s
4、代码的缩进:用空格代表缩进,四个空格表示一个缩进,或用tab键
5、使用注释: 单行注释: # 多行注释: ‘’‘ ’‘’
6、行连接符: \
7、Python中一切皆对象,每个对象由标识,类型,value组成
对象的本质就是:一个内存块,拥有特定的值
 id(3),3的内存地址,type(3) 3的类型;a是变量,3是对象,a是通过ID去找3的;
id(3),3的内存地址,type(3) 3的类型;a是变量,3是对象,a是通过ID去找3的;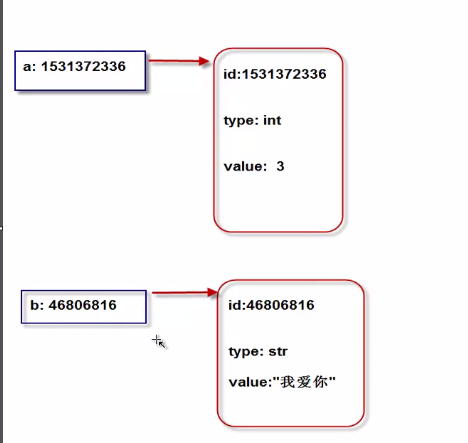
8、引用
变量通过地址引用了对象
对象位于堆内存,变量位于栈内存
Python是动态类型对象,不需要显示声明类型
Python是强类型语言,每个对象都有数据类型,只支持相关的操作
9、标识符
用户变量,函数,类,模块等的名称,标识符有如下规则:
区分大小写
第一个字符必须是字母,下划线,后面的是字母,数字,下划线
不能使用关键字 if,while等,查看关键字:
以双下划线开头和结尾的名称通常有特殊含义,尽量避免

10、变量的声明
变量名=表达式
删除变量和垃圾回收:
a=123
del a
如果对象不被引用,就会进行垃圾的回收
11、链式赋值
用于同一个对象赋值给多个变量
x=y=123,相当于:x=123;y=123
12、系列解包赋值给对应相同个数的变量
a,b,c=4,5,6 相当于:a=4;b=5,c=6
使用系列解包赋值实现变量交换
a,b=1,2
a,b=b,a
print (a,b)
13、常量
python不支持常量
MAX_SPEED=120
14、内置数据类型
整型:整数
运算符:+,-,*,/【浮点数除法】,//【整数除法】,%【取余】,**【幂】
浮点型:小数
布尔型:true,false
字符串型:由字符组成的序列
使用divmod(13,3)函数同时得到商和余数
15、整数
10进制
二进制:0,1 0b
八进制:0 1 2,3,4,5,6,7 0o
十六进制:0,1,2,3,4,5,6,7,8,9,a,b,c,d,e,f 0x
16、使用int()实现类型转换
浮点数直接舍去小数部分
布尔值True转为1,False转为0
字符串符合整数格式,则直接转成对应的整数
17、自动转型
整数和浮点数混合运算时,表达式结果自动转型为浮点数,2+8.0=10.0
18、浮点数
float()
round(value)可以返回四舍五入的值
19、增强型赋值运算符
+= 
-=
*=
/=
//=
**=
%=
+=中间不能加空格
20、布尔值
True 1
False 0
比较运算符:
==,!=,>,<,>=,<=
逻辑运算符:
or (逻辑或): x or y x为true,则返回true
x为false,则返回y
and(逻辑与): x and y x为true,则返回y的值
x为false,则返回false
not(逻辑非): not x x为true,则返回false
x为false,则返回true
21、同一运算符
用于比较两个对象的存储单元,实际比较的是对象的地址
is 判断两个标识符是不是引用同一个对象
is not 引用不同的对象
Python对较小的整数对象进行缓存,范围为【-5,256】缓存起来
在文件中的范围为【-5,任意正整数】缓存起来
is比较两个对象的id值是否相等,是否指向同一个内存地址
==比较的是两个对象的内容是否相等,值是否相等
is运算符比==效率高,在变量和None进行比较时,应该使用is
22、字符串
字符串:字符序列,不可变
python3中直接支持unicode
可以通过单引号或双引号创建字符串
连续的三个单引号或三个双引号,可以创建多行字符串
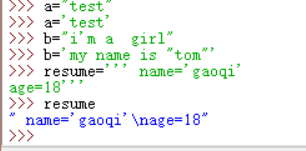
空字符串和len()函数
空字符串不包含任何字符且长度为0,len()用于计算字符串含有多少个字符
c=""

23、转义字符
可以使用"\+特殊字符"

字符串拼接: "aa"+"bb" 或者 “aa”“bb”
字符串的复制:a='aa'*3
不换行打印:通过参数 end=“任意字符串”。实现末尾添加任何内容,print("aa",end=“”)

从键盘中获取:

24、str()实现数字转型字符串
replace()实现字符串替换
a="abc"
a=a.replace(“c”,"d")
print (a)
a为abd
25、字符串的切片
slice操作【起始偏移量:终止偏移量:步长】包头不包尾
>>> a[:] #提取整个字符串
'abcdefghijk'
>>> a[1:] # 从start索引开始到结尾
'bcdefghijk'
>>> a[:3] #从头开始至到 end-1
'abc'
>>> a[1:3] #从start到end-1
'bc'
>>> a[1:5:2] #从start到 end-1,步长是step
'bd'
>>> a[-3:] #倒数第三个
'ijk'
>>> a[-3:-2] # 倒数第三个到倒数第2个
'i'
>>> a[::-1] # 步长为负,从右到左反向提取
'kjihgfedcba'
>>> b="to be or not to be" #反向输出
>>> b[::-1]
'eb ot ton ro eb ot'
>>> c="sxsxsxsx" #取出所有的"s"
>>> c[::2]
'ssss'
26、split()分割和join()合并
>>> a="to be or not to be"
>>> a.split()
['to', 'be', 'or', 'not', 'to', 'be']
>>> a.split("to") #以to进行分割
['', ' be or not ', ' be']
>>> a=['ss','sdds','sdewe']
>>> "".join(a)
'sssddssdewe'
>>> ".".join(a)
'ss.sdds.sdewe'
>>> "+".join(a)
'ss+sdds+sdewe'
27、字符串的比较
字符串驻留机制:仅保存一份相同且不可变字符串的方法,不同的值被存放在字符串驻留池中
符合标识符规则,会启用字符串驻留机制
成员操作符:in、not in 关键字,判断某个字符,字符串是否存在于字符串中
>>> a="abcd"
>>> "sdjsdj" in a
False
>>> "a" in a
True
>>> a="我是一名工作人员,收到货的时候是时候是的hiID是到掉导航打打死打手待打算打算打算"
>>> len(a) #字符串长度
78
>>> a.startswitch("我是") #以指定字符串开头
>>> a.rfind("是") #最后一次出现指定字符串的位置
44
>>> a.startswith("我") #以指定字符串开头
True
>>> a.endswith("打算") #以指定字符串结尾
True
>>> a.count("的") #指定字符串出现了几次
2
>>> a.isalnum() #所有字符全是字母或数字
False
去除收尾信息
strip()去除字符串首尾指定信息
>>> "*shkds*sdjk*".strip("*")
'shkds*sdjk'
>>> "*dsj*sdj*".lstrip("*")
'dsj*sdj*'
>>> "*dsj*dsj*".rstrip("*")
'*dsj*dsj'
>>> " dsds ".strip()
'dsds'
>>> a="dsdQQQ"
>>> a.capitalize() # 产生新的字符串,首字母大写
'Dsdqqq'
>>> a.title() #产生新的字符串,每个单词都首字母大写
'Dsdqqq'
>>> a.upper #产生新的字符串,所有字符全转成大写
<built-in method upper of str object at 0x03EA43C0>
>>> a.upper()
'DSDQQQ'
>>> a.lower() # 产生新的字符串,所有字符全转成小写
'dsdqqq'
>>> a.swapcase() #产生新的字符串,所有字母大小写转换
'DSDqqq'
>>>
格式:

其他方法:
>>> a.isalnum() #是否为字母或数字
True
>>> a.isalpha() #检测字符串是否只由字母组成,包括汉字
True
>>> a.isdigit() #检测字符串是否只由数字组成
False
>>> a.isspace() #检测是否为空白符
False
>>> a.isupper() #是否为大写字母
False
>>> a.islower() #是否为小写字母
True
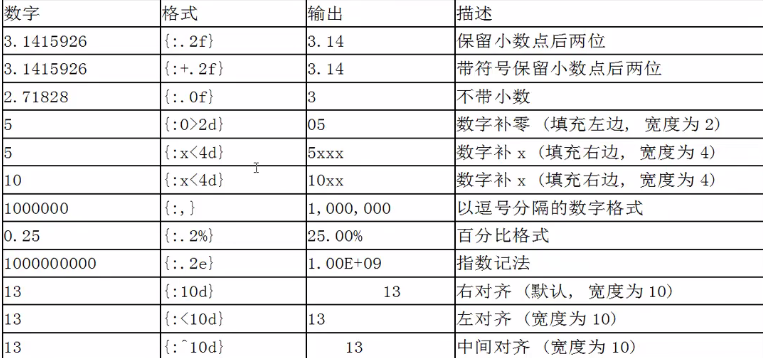
28、字符串的格式化
通过{索引}/{参数名},直接映射参数值,实现对字符串的格式化
>>> a="my name is {name},age is{age}"
>>> a.format(name='zuq',age=12)
'my name is zuq,age is12'
29、可变字符串
io.StringIO(s)
s.seek(3)
s.write("ew")
s.getvalue()
30、序列
列表,存储任何数目,任意数据类型的数据集合
列表大小可变,随时可增加或缩小
一个字符串是一个字符序列,一个列表是任何元素的序列
列表的创建:
a=[] #创建一个空列表
a=list() #创建一个空的列表对象
a=list("sdjksd,sdjsd")
list(a)
通过range()创建整数列表【start,end,step】
>>> range(10)
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> list(range(10))
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> list(range(0,10,1))
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> list(range(1,10,3))
[1, 4, 7]
#encoding=utf-8 for i in range(10): i=i*2 print i a=[1,2,3,"ss"] print a b=list("dsjkds") print list(b)
31、列表元素的增加和删除
# -*- coding=utf-8 -*- a=[20,40] # 创建一个列表 print id(a) a.append(80) #在列表最后增加一个元素 print a print id(a.append(80)) #extend()将目标列表的所有元素添加到未列表的尾部,属于原地操作,不创建新的列表 a.extend([100]) #两个列表进行整合时,推荐使用这个 print a print id(a.extend([100])) a.insert(2,200) #可以将指定的元素插入到列表对象的任意指定位置,迎避免使用 print a print id(a.insert(2,200)) #乘法的扩展 a=['a',"b"] print a*3
# -*- coding=utf-8 -*- #del()删除指定位置的元素 a=[10,20,30] del a[1] print a #pop()删除并返回指定位置的元素,如果未指定位置,默认是最后一个位置的元素 a=[10,20,30,40,50] b=a.pop() print b print a c=a.pop(1) print c print a #remove()删除首次出现的指定元素,若不存在,则该元素跑出异常 a=['aa','bb','cc','dd'] a.remove('aa') print a
#-*- coding=utf-8 -*- #通过索引直接访问元素 a=[10,20,30,40,50,30,203] print a[2] #index()可以获取指定元素首次出现的索引位置,index(value,start,end) print a.index(40) #count()获得指定元素在列表中出现的次数 print a.count(30) #len()返回列表的长度 print len(a) #成员资格的判断,用in 来判断,返回ture,表示存在,返回false表示不存在 print 10 in a print 3393 in a
排序
# -*- coding=utf-8 -*- #排序 ,原列表中进行排序 a=[50,30,60,230] a.sort() #默认升序排列 print a a.sort(reverse=True) #降序排列 print a import random random.shuffle(a) #打乱顺序 print a
#max 最大值,min最小值 print max(a) print min(a) print sum(a)
32、二维列表
# -*- coding=utf-8 -*- #二维列表 a=[['a',1],['b',2],['c',3]] print a[0][1]
在打印语句的末尾添加逗号,可以使输出的内容不换行
# -*- coding=utf-8 -*- a=[["a",1],["b",2],["c",3],["d",4]] #定义一个二维列表 for m in range(4): for n in range(2): print (a[m][n]), #在末尾加逗号,可以使输出的内容不换行 print ("") #打印完一行换行
33、元组 tuple
元组属于不可变序列,不能修改元组中的元素,因此元组没有增加元素,修改元素,删除元素的相关的方法
元组支持如下操作:索引访问,切片操作,连接操作,成员关系操作,比较运算操作,计数
元组的创建:a=(10,20,30)或者 a=tuple("wewwe"),tuple(a)
如果元组只有一个元素时,则必须在后面加逗号,a=(10,)
元组的元素访问和计数:
a=(1,2,3,4,5)
a[0] #a[0]的值为1
#zip,将说个列表对应位置的元素组合成为元组,并返回zip对象 a=[1,2,3] b=[23,333,3333] c=zip(a,b) print list(c)
元组的访问和处理速度比列表快
34、字典
是键值对的无序可变序列
键是任意不可变数据,键不可重复,值可以是任意的数据,并且不可重复
创建字典:
a={"name":"zyq","age":19}
a['name'] #值为zyq
a=dict(name='zyq',age=19)
字典的访问:
通过健去访问值,指定健不存在时,会报错:
>>> a={"name":"zyq","age":19,"job":"pro"}
>>> a["name"]
'zyq'
>>> a['sds']
Traceback (most recent call last):
File "<pyshell#26>", line 1, in <module>
a['sds']
KeyError: 'sds'
通过get()方法获得值,指定健不存在时,返回None:
>>> a.get("name")
'zyq'
>>> a.get("ew")
列出所有的键值对:a.items():
>>> a.items()
[('job', 'pro'), ('age', 19), ('name', 'zyq')]
列出所有的键: a.keys():
>>> a.keys()
['job', 'age', 'name']
列出所有的值:a.values():
>>> a.values()
['pro', 19, 'zyq']
键值对的个数:len()
>>> len(a)
3
检测一个键是否在字典中,in
>>> "name" in a
True
35、字典元素的添加,修改和删除
添加:给字典新增“键值对”,如果键已经存在,会覆盖旧的值,如果没有,则新增键
>> a['address']='beijin'
>>> a
{'job': 'pro', 'age': 19, 'name': 'zyq', 'address': 'beijin'}
修改:使用update()将新字典中所有键值对全部添加到旧字典对象上,如果有key重复,则覆盖
>>> a={"name":"zyq","age":19}
>>> b={"name":"zyq1","sex":"gril"}
>>> a.update(b)
>>> a
{'age': 19, 'name': 'zyq1', 'sex': 'gril'}
删除:del(a[''name']) # 字典中元素的删除
>>> del(a['address'])
>>> a
{'job': 'pro', 'age': 19, 'name': 'zyq1'}
>>> b=a.pop('age') #删除指定键值对,并返回对应的值对象
>>> b
19
>>> a.clear() #删除所有的键值对
>>> a
{}
36、序列解包:默认对键进行操作,如果需要对值进行解包,用.values(),如果需要对键值对进行操作,用items()
>>> s={"name":"zyq","age":18,"job":"teacher"}
>>> a,b,c=s
>>> a
'job'
>>> b
'age'
>>> c
'name'
>>> e,d,f=s.values()
>>> e
'teacher'
>>> d
18
>>> f
'zyq'
>>> h,i,j=s.items()
>>> h
('job', 'teacher')
>>> i
('age', 18)
>>> j
('name', 'zyq')
37、字典
# -*- coding=utf-8 -*- r1={"name":"zyq","age":"18","salary":"30000","city":"beijing"} r2={"name":"zyq1","age":"19","salary":"20000","city":"shanghai"} r3={"name":"zyq2","age":"20","salary":"10000","city":"guangzhou"} tb=[r1,r2,r3] #获得第二行的人的薪资 print (tb[1].get("salary")) #打印表中所有的薪资 for i in range(len(tb)): print (tb[i].get("salary")) #打印表的所有的数据 for i in range(len(tb)): print (tb[i].get("name"),tb[i].get("age"),tb[i].get("salary"),tb[i].get("city"))
38、字典的核心底层原理
字典对象的核心是散列表,是一个稀疏数组,数组的每个单元叫bucket,一个bucket有两部分,一个键一个值
通过偏移量来读取指定的bucket
39、集合
集合是无序可变的,元素不能重复,
集合的创建:
>>> a={3,5,7}
>>> a
set([3, 5, 7])
集合的添加:
>>> a.add(9)
>>> a
set([9, 3, 5, 7])
集合的删除:
>>> a.remove(9)
>>> a
set([3, 5, 7])
清空集合:
>>> a.clear()
>>> a
set([])
集合的交集,并集,差集:
>>> a={1,3}
>>> b={2,4.3}
>>> a|b
set([1, 2, 3, 4.3])
>>> b={2,4,3}
>>> a|b
set([1, 2, 3, 4])
>>> a&b
set([3])
>>> a.difference(b)
set([1])
40、控制语句
选择结构:
单分支,双分支,多分支
单分支:
if 条件表达式:
语句、语句块
# -*- coding=utf-8 -*-
a=input("请输入一个数字:")
if int(a)<10:
print a
条件表达式:
条件表达式的值为False的情况如下:
False,0,0.0,空值none,空序列对象,空range对象,空迭代对象
其他情况均为true
b=[]
if b:
print "空的列表是false"
else:
print b
if not b:
print "不是空列表"
c=True
if c:
print c
d="12"
if d:
print d
e=1
if e:
print e
if 0<e<2:
print e
条件表达式中,不能有赋值操作符“=”
#if 3<c and (c=20): 赋值操作符不能出现在条件表达式中
双分支:
if 条件表达式:
语句1
else:
语句2
# -*- coding=utf-8 -*- a=input("请输入一个数字:") if a>10: print "a是一个大于10的数字" else: print "a是一个小于10的数字"
三元条件运算符:
用来在某些简单双分支赋值情况,格式如下:
条件为真时的值 if(条件表达式) else 条件为假时的值
#测试三元条件运算符
print a if a<10 else "a是大于等于10的数字"
多分支选择结构:
if 条件表达式1:
语句1
elif 条件表达式n:
语句n
[else:
语句n+1]
多分支结构,几个分支之间是有逻辑关系的,不能随意颠倒顺序
# -*- coding=utf-8 -*- #已知点的坐标(x,y)。判断其所在的象限 x=input("请输入x的坐标") y=input("请输入y的坐标") if (x==0 and y==0): print "原点" elif(x==0): print "Y轴" elif(y==0): print "X轴" elif(x>0 and y>0): print "第一象限" elif(x<0 and y>0): print "第二象限" elif(x<0 and y<0): print "第三象限" else: print "第四象限"
41、选择结构的嵌套
注意控制好不同级别代码块的缩进量:
# -*- coding=utf-8 -*- score=input("请输入0-100之间的数字:") grade="" if score>100 or score<0: score=input("输入错误,请输入0-100之间的数字:") else: if score>=90: grade='A' elif score>=80: grade='B' elif score>=70: grade='C' elif score>=60: grade="D" else: grade='E' print grade
42、循环结构
用来重复执行一条或多条语句, 如果符合条件,则反复执行循环体里的语句,在每次执行完后都会判断一次条件是否为True,如果为 True则重复执行循环体里的语句
while循环:
# -*- coding=utf-8 -*- num=0 while num<=10: print num num+=1 #计算1-100之间的累加和 num1=0 sum1=0 while num1<=100: sum1=sum1+num1 num1+=1 print ("1-100之间的累加和是:",sum1)
43、for循环
for循环通常用于可迭代对象的遍历,格式如下:
for 遍历 in 可迭代对象:
循环体语句
# -*- coding=utf-8 -*- #for 循环 for i in (20,30,40): print i
可迭代对象:
# -*- coding=utf-8 -*- #for 循环 for i in (20,30,40): print i for x in (10,20,30): print x*30 for x in "abcde": print x d={'name':"zyq","age":"18","job":"程序员"} for x in d: print x for x in d.keys(): print x
#range对象是一个迭代对象 for x in range(10): print x #计算1-100的累加和 sum_all=0 sum_even=0 sum_odd=0 for num in range(101): sum_all=sum_all+num if num%2==0:sum_even+=num else:sum_odd+=num print ("1-100的偶数和是:",sum_even) print ("1-100的奇数和是:",sum_odd) print ("1-100的和是:",sum_all) print "*****************************************"
44、嵌套循环
一个循环体内可以嵌入另一个循环,称为嵌套循环或者多重循环
输出:
0 0 0 0 0
1 1 1 1 1
2 2 2 2 2
3 3 3 3 3
4 4 4 4 4
# -*- coding=utf-8 -*- for x in range(5): for y in range(5): print(x), #逗号表示不换行 print ("")
9*9乘法表:
# -*- coding=utf-8 -*- # 打印9*9乘法表 for x in range(1,10): for y in range(1,x+1): print x, print "*", print y, print "=", print x*y, print ("")
用列表和字典存储下表信息,并打印出表中工资高于15000的数据
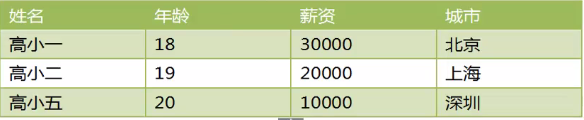
r1={"name":"zyq","age":20,"salary":30000,"city":"bj"}
r2={"name":"zyq1","age":21,"salary":20000,"city":"gz"}
r3={"name":"zyq2","age":22,"salary":10000,"city":"sh"}
tb=[r1,r2,r3]
for i in tb:
if i.get('salary')>15000:
print i
45、break,continue
break语句可用于while和for循环,用来结束整个循环,当有嵌套循环时,只能跳出最近一层的循环
# -*- coding=utf-8 -*- #测试break while True: a=input("请输入一个字符(输入1时退出):") if a==1: print ("循环结束,退出循环") break else: print a
continue用于结束本次循环,继续下次循环,多个循环嵌套时,continue也是应用于最近的一层循环
# -*- coding=utf-8 -*- #continue 结束本次循环 #计算员工薪资的数量,薪资明细,以及平均薪资 empnum=0 salary_mixi=[] salarySum=0 while True: salary = input("请输入员工的薪资,输入1结束:") if salary==1: print "录入结束,退出" break if salary<0: continue empnum+=1 salary_mixi.append(salary) salarySum+=salary print empnum print salary_mixi print salarySum/empnum
46、else语句
while,for循环可以附带一个else语句,如果没有被break语句结束,则会执行else语句,
while 条件表达式:
循环体
else:
语句块
47、循环代码的优化
尽量减少循环内部不必要的计算
嵌套循环中,尽量减少内层循环的计算,尽可能向外提
局部变量查询较快,尽量使用局部变量
连接多个字符串,用join(),不使用+
列表进行元素插入和删除,尽量在列表尾部操作
48、zip()并行迭代
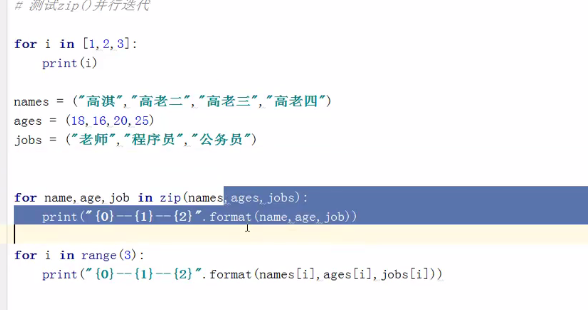
49、推导式创建序列
列表推导式:
# -*- coding=utf-8 -*- #列表推导式 y=[x*2 for x in range(1,50) if x%2==0] print y
字典推导式:
字典的推导式生成字典对象,格式:
{key:value for 表达式 in 可迭代对象}
#字典推导式
my_text='i love you,i love text,i love zyq'
char_count={c:my_text.count(c)for c in my_text}
print char_count
#集合推导式
b={x for x in range(1,100) if x%9==0}
print b
生成器推导式
一个生成器只能运行一次
#生成器推到式,生成元组 gnt=(x for x in range(1,100) if x%9==0) #print tuple(gnt) for x in gnt: print x
# -*- coding=utf-8 -*-
import turtle
my_color=('red','black','green','pink')
t=turtle.Pen()
t.width(5)
#t.speed(5)
for i in range(5):
t.penup()
t.goto(0,-i*10)
t.pendown()
t.color(my_color[i%len(my_color)])
t.circle(15+i*10)
turtle.done()
50、函数function
可重用的程序代码块
python函数的分类
内置函数:str(),list()
标准库函数:import
第三方库函数:
用户自定义函数:
格式:
def 函数名(参数列表):
函数体
# -*- coding=utf-8 -*-
#测试函数的定义和调用
def name():
print"test"
name()
执行def时,会创建一个函数对象,并绑定到函数名变量上
圆括号是形参列表
return 返回值
# -*- coding=utf-8 -*- def printMax(a,b):
'''用于比较两个数的大小,打印较大的值'''
if a>b:
print (a,"较大值")
else:
print (b,"较大值")
printMax(10,20)
printMax(30,20)
返回值的详解:
如果函数体中包含return语句,则结束函数执行并返回值
如果函数体中不包含return语句,则返回None值
要返回多个返回值,使用列表,元组,字典,集合将多个值存起来即可
# -*- coding=utf-8 -*-
#测试返回值的基本用法
def add(a,b):
return a+b
def add1():
print "a"
return # 两个作用:返回值,结束函数执行,所以print"b"语句不会执行
print "b"
def add2(x,y,z):
return [x*10,y*10,z*10]
c=add(30,40)
print c
add1()
d=add2(1,2,3)
print
函数也是对象
51、变量的作用域,全局变量,局部变量
全局变量:
1、在函数和类定义之外声明的变量
2、全局变量降低了函数的通用性和可读性
3、全局变量一般做常量使用
4、函数内要改变全局变量的值,使用 global声明一下
局部变量:
在函数体中声明的变量
局部变量的引用比全局变量快,优先考虑使用
如果局部变量和全局变量同名,只使用同名的局部变量
调用的时候启用一个
# -*- coding=utf-8 -*- a=3 #全局变量 def quanju(): b=4 #局部变量 print b global a # 如果要在函数内改变全局变量的值,增加global关键字声明 a=100 print a quanju() print a
栈帧stack frame ,调完后就销毁
输出局部变量和全局变量
print (locals()) # 打印输出的局部变量 print (globals()) #打印输出的全局变量
局部变量的速度要比全局变量快
# -*- coding=utf-8
import math
import time
def jisuan():
start=time.time()
for i in range(100000):
math.sqrt(30) #全局变量
end=time.time()
print (end-start)
def jisuan1():
b=math.sqrt #局部变量
start=time.time()
for i in range(100000):
b(30)
end=time.time()
print (end-start)
jisuan()
jisuan1()
局部变量的时间是:0.0269999504089
全局变量的时间是:0.055999994278
52、参数的传递
传递可变对象的引用
传递阐述是可变对象,可变对象为列表,子弹,自定义的其他可变对象等,实际传递的还是对象的引用,在函数体中不创建新的对象拷贝,而是可以直接修改所传递的 对象
# -*- coding=utf-8 #测试参数的传递 #传递可变对象 a=[10,20] print id(a) print a def kebian(m): print id(m) # b和m是同一个对象 m.append(30) #由于m是可变对象,不创建对象拷贝,直接修改这个对象 print id(m) kebian(a) print a
传递不可变对象
不可变对象:int ,float,字符串,元组,布尔值,实际传递的还是对象的引用,在赋值操作时,由于不可变对象无法修改,系统会创建一个新对象
# -*- coding=utf-8 -*- # author=zyq a=100 def f1(n): print n #传递进来的是a对象的地址 print id(n) n=n+200 #由于a是不可变对象,因此创建新的对象n print n #n已经变成了新的对象 print id(n) f1(a) print a print id(a)
53、浅拷贝copy和深拷贝deepcopy
浅拷贝:不拷贝对象的内容,只拷贝对象的引用
深拷贝:会连子对象的内存也全部拷贝一份,对子对象的修改不会影响源对象
# -*- coding=utf-8 -*-
# author=zyq
import copy
def qiancopy():
'''测试浅拷贝'''
a=[10,20,[5,6]]
b=copy.copy(a)
print a
print b
b.append(30)
b[2].append(7)
print "浅拷贝"
print a
print b
def shencopy():
'''测试深拷贝'''
a=[10,20,[5,6]]
b=copy.deepcopy(a)
print a
print b
b.append(30)
b[2].append(7)
print "浅拷贝"
print a
print b
qiancopy()
print "++++++++++++++++++++++++"
shencopy()
 浅拷贝
浅拷贝
 深拷贝
深拷贝
54、参数的几种类型
位置参数:函数调用时,参数个数要匹配
默认值参数:默认值参数必须位于普通位置参数后面
命名参数:按照形参的名称传递参数
# -*- coding=utf-8 -*-
# author=zyq
#测试参数的类型,位置参数,默认值参数,命名参数
def canshu(a,b,c,d):
print a,b,c,d
canshu(1,2,3,4) # 位置参数,参数个数不匹配,会报错
def canshu1(a,b,c=10,d=20):
print a,b,c,d
canshu1(1,2) #默认值参数,默认值参数必须位于其他参数的后面
def canshu1(a,b,c,d):
print a,b,c,d
canshu1(a=10,c=20,d=30,b=1) #命名参数。按照形参名称进行匹配
55、参数的类型--可变参数--强制命名参数
可变参数:一个星号,将多个参数收集到一个“元组”对象中
两个星号,将多个参数收集到一个“字典”对象中
# -*- coding=utf-8 -*-
# author=zyq
#测试可变参数处理,一个星号,将多个参数收集到一个“元组”对象中
def f1(a,b,*c):
print a,b,c
f1(1,2,2,3)
#测试可变参数处理,两个星号,将多个参数收集到一个“字典”对象中
def f2(a,b,**c):
print a,b,c
f2(1,2,name='zyq',age=18)
输出结果:
1 2 (2, 3)
1 2 {'age': 18, 'name': 'zyq'}
强制命名参数:在带星号的“可变参数”后面增加新的参数,必须是“强制命名参数”
56、lambda表达式和匿名函数
可以用来声明匿名函数,表示式的计算结果就是函数的返回值
语法:
lambda arg1,arg2,arg3..:表达式
# -*- coding=utf-8 -*- # author=zyq #lambda表达式 f=lambda a,b,c:a+b+c print f(1,2,3) g=[lambda a:a*2,lambda b:b*3,lambda c:c*4] print g[0](1),g[1](2),g[2](3)
输出结果:
6
2 6 12
57、eval函数
将字符串str当成有效的表达式来求值并返回计算结果
语法:eval(source,globals,locals)
source:一个python表达式或函数返回的代码对象
globals:必须是dict
locals:任意映射对象
# -*- coding=utf-8 -*- # author=zyq #测试eval函数 a=10 b=20 c=eval("a+b") print c dict1=dict(a=100,b=200) d=eval("a+b",dict1) print d
58、递归函数
自己调用自己的函数,在函数体内部直接或间接的自己调用自己
每个递归函数必须包含两个部分:
终止条件:表示递归什么时候结束,一般用于返回值,不再调用自己
递归步骤,把第N步的值和第n-1步相关联
# -*- coding=utf-8 -*-
# author=zyq
def f(n):
print n
if n==0:
print "over"
else:
f(n-1)
print "test01",n
f(5)
# -*- coding=utf-8 -*-
# author=zyq
#实现阶乘的递归
def f(n):
if n==1:
return 1
else:
return n*f(n-1)
d=f(5)
print d
59、嵌套函数,也叫内部函数
在函数内部定义的函数
封装,闭包,减少重复代码
# -*- coding=utf-8 -*-
# author=zyq
#嵌套函数
def f1():
print "f1 running"
def f2():
print "f2 running"
f2()
f1()
def printname(isChinese,name,familyName):
def innner_print(a,b):
print a,b
if isChinese:
innner_print(familyName,name)
else:
innner_print(name,familyName)
printname(True,"小气","高")
printname(False,"qaz","zyq")
60、在内部函数中修改外部函数的局部变量,用nonlocal
# -*- coding=utf-8 -*-
# author=zyq
#测试nonlocal,在内部函数中修改外部函数的局部变量,用nonlocal
# nolocal a = 20 声明外部函数的局部变量
def f1():
b=20
def f2():
nonlocal b
print b
b=30
f2()
print b
f1()
61、LEGB规则
# -*- coding=utf-8 -*-
# author=zyq
#测试LEGB 规则
#在查找名称时,是按照LEGB规则查找的,local,enclosed,global,built in
#str="global"
def outer():
#str = "outer"
def inner():
#str="inner"
print str
inner()
outer()
62、面向对象编程oop
面向对象编程将数据和操作数据相关的方法封装到对象中
面向对象,从问题中找名词,面向过程,从问题中找动词
对象的进化:简单数据---数组---结构体---对象
63、类的定义,类和对象的关系
类将行为和状态打包在一起
# author=zyq
#定义类
#类名一般首字母大写,多个单词采用驼峰原则
class Student:
#定义属性,self指的是当前对象本身,self必须是第一个参数
#定义构造方法
def __init__(self,name,score):
self.name=name
self.score=score
#定义打印分数的方法
def say_score(self):
print self.name
print self.score
s1=Student("gaoqi",18) #调用构造方法
s1.say_score()
64、构造函数__init__()
s1=Student("gaoqi",18)
分两步:创建对象__new__()
初始化创建好的对象__init__()
要点:
名称固定,必须为:__init__(),无返回值
第一个参数规定,必须是self, self指的就是刚刚创建好的实例对象
构造函数通常用来初始化实例对象的实例属性
通过类名来调用构造函数,调用后,将创建好的对象返回给相应的变量
65、实例的属性
从属于实例对象的属性
在__init__()方法中通过如下的代码进行定义:
self.实例属性名=初始值
在本类的其他实例方法中,也是通过self进行访问:
self.实例属性名
创建对象后,通过实例对象访问
obj01=类名()
obj01.实例属性名=值 #给已有属性赋值,也可以新加属性
66、实例方法
从属于实例对象的方法:
def 方法名(self,形参列表):
函数体
调用格式:对象.方法名(实参)
# -*- coding=utf-8 -*-
# author=zyq
#定义类
#类名一般首字母大写,多个单词采用驼峰原则
class Student:
#定义属性,self指的是当前对象本身,self必须是第一个参数
#定义构造方法
def __init__(self,name,score):
self.name=name
self.score=score
#定义打印分数的方法
def say_score(self):
print self.name
print self.score
s1=Student("gaoqi",18) #调用构造方法
s1.say_score()
#给对象新加的属性
s1.age=30
s1.salary=3000
print s1.salary
print s1.age
Student.say_score(s1)
s2=Student("2",32)
print dir(s1) #对象的所有属性和方法
#print s1.__dict__() 对象的属性字典
print isinstance(s1,Student) #判断对象是不是指定类型
#pass 空语句
67、类对象
# -*- coding=utf-8 -*-
# author=zyq
class Student():
pass
print type(Student)
print id(Student)
Stu2=Student #把类对象的地址给了Stu2
s1=Stu2() #调用构造函数
print s1
68、类属性和方法
类属性从属于类对象的属性,可以被所有实例调用
·
# -*- coding=utf-8 -*-
# author=zyq
class Student:
company="SXT" #类属性
count=0 #类属性
#定义构造函数
def __init__(self,name,score):
self.name=name #实例属性
self.score=score #实例属性
Student.count+=1
#定义实例方法
def say_score(self):
print Student.company
print self.score
s1=Student("zyq",100) # 创建实例对象,并调用构造函数
s1.say_score() # 调用实例方法
s2=Student("zy",80)
print Student.count
69、类方法
类方法从属于类对象的方法,用过装饰器@classmethod来定义
#类方法 @classmethod def f(cls): pass
cls必须有,cls指的是类对象本身
调用:类名.类方法名,不需要给cls传值
静态方法与类对象无关的方法
#静态方法 @staticmethod def f1(): pass
类方法和静态方法中,不能调用实例属性和方法
# -*- coding=utf-8 -*-
# author=zyq
class Student: #定义student类
company='SXT' #类属性
def __init__(self,name,score): #构造方法
self.name=name # 实例属性
self.score=score
def say_score(self): # 定义实例方法
print self.name
print self.score
@classmethod
def f1(cls): #定义类方法
#print cls.name 类方法中不能调用实例属性和方法
#print cls.score
print cls.company
#cls.say_score()
cls.f2()
@staticmethod
def f2(): #定义静态方法
print Student.company
s1=Student("zyq",100)
s1.say_score()
Student.f1()
Student.f2()
70、__del__()析构方法实现对象销毁时所需的操作
对象在什么情况下会被销毁?当对象没有被引用(引用计数为0)时,由垃圾回收器调用方法
# -*- coding=utf-8 -*-
# author=zyq
#测试析构方法
class Person:
def __del__(self):
print self
p1=Person()
P2=Person()
del P2
print "程序结束"
71、__call__()方法和可调用对象
class Salary:
def __call__(self, salary):
print "-----------------"
yearSalary=salary*12
daySalary=salary//22.5
hourSalary=daySalary//8
return dict(yearSalary=yearSalary,monthSalary=salary,daySalary=daySalary,hourSalary=hourSalary)
s1=Salary()
#s()直接调用call方法
print s1(20000)
定义了__call__方法的对象,称为可调用对象,即改对象可以像函数一样被调用
72、方法没有重载
python中没有方法的重载,定义多个同名方法,只有最后一个有效
# -*- coding=utf-8 -*-
# author=zyq
#python中,方法没有重载,定义多个同名的方法时,只有最后一个有效
class Student():
def print_name(self,name): #已被同名的方法覆盖
print name
def print_name(self,name,age):
print name
print age
s=Student()
s.print_name("zyq",20)
方法的动态性:
# -*- coding=utf-8 -*-
# author=zyq
#方法也是对象,函数也是对象,一切皆对象
class Person:
def work(se-lf):
print "work work!!"
def work1(s):
print"work1,work1!!"
Person.work2 = work1;
p=Person()
p.work()
p.work2()
72、私有属性和私有方法实现封装
两个下划线开头的属性是私有的
类内部可以访问
类外部不能直接访问
类外部可以通过_类名__私有属性或方法名
# -*- coding=utf-8 -*-
# author=zyq
#测试私有属性
class Employee:
def __init__(self,name,age):
self.name=name
self.__age=age #定义私有属性
#def __work
e=Employee("zyq",20)
print e.name
print e._Employee__age #访问私有变量,python3
私有方法:
# -*- coding=utf-8 -*-
# author=zyq
#测试私有属性
#调用私有属性或方法时,用._类名__私有属性或私有方法名
class Employee:
__company='SXT'
def __init__(self,name,age):
self.name=name
self.__age=age #定义私有属性
def __work(self): #私有方法
print"好好工作!!"
print("nianling:{0}".format(self.__age))
e=Employee("zyq",20)
print e.name
print e._Employee__age #访问私有变量
e._Employee__work() #调用私有方法
print Employee._Employee__company #调用私有的类属性
73、@property装饰器_get和set方法
# -*- coding=utf-8 -*-
# author=zyq
#测试利用get,set方法获取和修改工资
class Employee:
def __init__(self,name,salary):
self.__name=name
self.__salary=salary
def get_sarlary(self):
return self.__salary
def set_salary(self,salary):
if 1000<salary<30000:
self.__salary=salary
else:
print "录入错误"
e=Employee("zyq",2000)
print e.get_sarlary()
e.set_salary(3000)
print e.get_sarlary()
@property修饰符
# -*- coding=utf-8 -*-
# author=zyq
#测试@property装饰器
class Employee:
def __init__(self,name,salary): #定义构造方法
self.__name=name #定义私有属性
self.__salary=salary
@property
def salary(self):
return self.__salary
@salary.setter
def salary(self,salary):
if 1000<salary<30000:
self.__salary=salary
else:
print "录入错误"
e=Employee("zyq",2000)
print e.salary
e.salary=3000
print e.salary
74、面向对象的三大特征
封装,继承,多态
继承:是代码复用的重要手段,父类或基类,子类或派生类
支持多重继承,一个子类可以继承多个父类
class 子类类名(父类1,父类2.。。。)
如果在类定义中没有指定父类,则默认父类为object类,也就是说object是所有类的父类,里面定义了一些所有类公有的默认实现
定义子类时,必须在其构造函数中调用父类的构造函数 父类名.__init__()
子类在继承父类时,私有的属性和方法不能直接使用,用._类名__属性名
# -*- coding=utf-8 -*- # author=zyq #测试继承的基本使用 class Person(object): def __init__(self,name,age): self.name=name self.__age=age def say_age(self): print "age!!!!!" #student继承person类 class Student(Person): def __init__(self,name,age,score): Person.__init__(self,name,age) #子类继承父类的构造方法 self.score=score print Student.mro() s=Student("zyq",20,80) s.say_age() print s._Person__age
方法的重写:
成员继承:子类继承了父类除构造方法之外的所有成员
方法重写:子类可以重新定义父类中的方法,这样就会覆盖父类的方法,称为“重写”
# -*- coding=utf-8 -*- # author=zyq #测试方法的重写 class Person(object): def __init__(self,name,age): self.name=name self.__age=age def say_name(self): print ("他的姓名是:{0}".format(self.name)) class Student(Person): #重写了父类的方法 def say_name(self): print ("这个学生的姓名是:{0}".format(self.name)) s=Student("zyq",20) s.say_name()
运行结果:这个学生的姓名是:zyq
75、object类,是所有类的基类
print Student.mro() #输出类的继承层次结构
dir(o) #查看指定对象所有的属性
重写__str__()方法,用于返回一个对于对象的描述
# -*- coding=utf-8 -*- # author=zyq #测试重写object的__str__()方法 class Person(object): def __init__(self,name): self.name=name #重写了object的__str__()方法,返回对对象的描述 def __str__(self): return "名字是:{0}".format(self.name) p=Person("zyq") print p
运行结果:名字是:zyq
76、多重继承
Python支持多重继承,一个子类可以有多个直接父类
77、mro,如果父类中有相同名字的方法,在子类没有指定父类名称时,解释器将从左到右顺序搜索
# -*- coding=utf-8 -*- # author=zyq #测试mro()方法 class Person(object): def say(self): print "person" class Student(Person): def say(self): print "student" class Worker(Student,Person): def say_worker(self): print"worker" w=Worker() w.say() #解释器会从左到右的方式寻找,此时会执行Student类中say()方法 print Worker.mro() #打印类的层次结构
78、super()获得父类的定义
# -*- coding=utf-8 -*-
# author=zyq
#super方法获取父类的定义,而不是父类的对象
class Person:
def say(self):
print "Person",self
class Student(Person):
def say(self):
# Person.say(self)
super().say()
print "Student",self
s=Student()
s.say()
Python2中的写法
# -*- coding=utf-8 -*- # author=zyq #super方法获取父类的定义,而不是父类的对象 class Person(object): def say(self): print "Person",self class Student(Person): def say(self): # Person.say(self) super(Student,self).say() # python2中的写法 # super().say() #python3中的写法 print "Student",self s=Student() s.say()
79、多态
同一个方法调用由于对象不同,可能会产生不同的行为
多态是方法的多态,属性没有多态
# -*- coding=utf-8 -*- # author=zyq #测试多态的方法 class Man(object): def eat(self): print"吃饭了!!" class Chinese(Man): def eat(self): print("中国人用筷子吃饭") class Enlish(Man): def eat(self): print ("英国人用叉子吃饭") class Indian(Man): def eat(self): print "印度人用右手吃饭" def manEat(m): if isinstance(m,Man): #用来判断一个变量是否是相应的类型,还可以判断一个对象是否是一个类的实例的函数 m.eat() else: print"不能吃饭" manEat(Chinese()) manEat(Enlish())
80、特殊方法和运算符重载
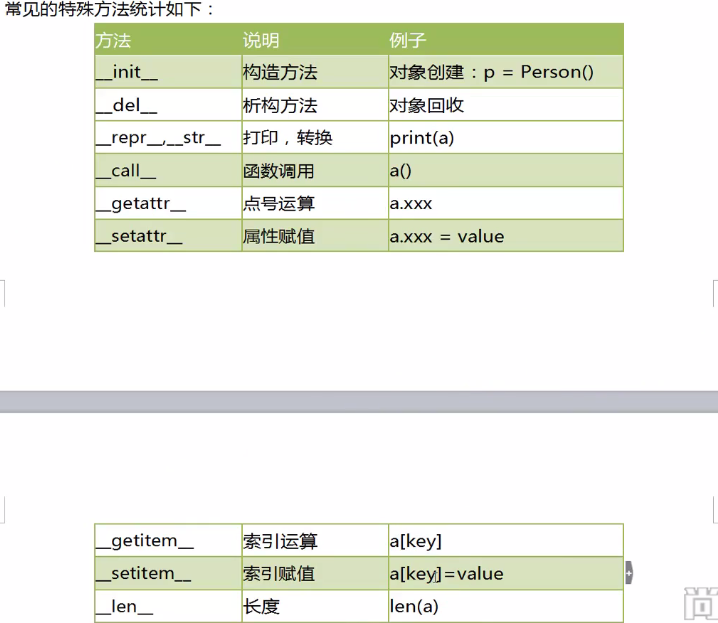
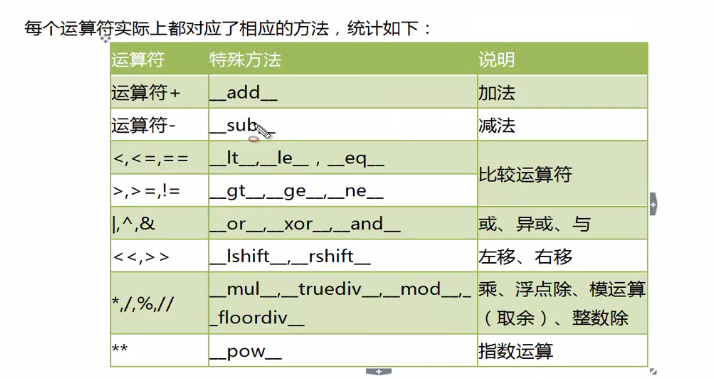
# -*- coding=utf-8 -*- # author=zyq #运算符的重载 class Person(object): def __init__(self,name): self.name=name def __add__(self, other): if isinstance(other,Person): return "{0}---{1}".format(self.name,other.name) else: print"不同类型不能相加" p1=Person("zyq") p2=Person("zy") print p1+p2
特殊属性:
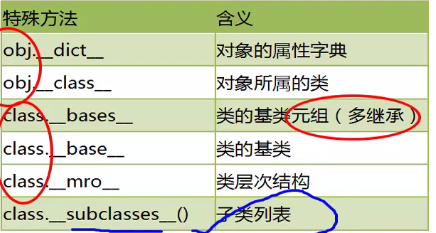
print dir(p1) #获取对象的属性 print p1.__class__ #获取对象所属的类 print p1.__dict__ #获取对象的属性字典 print Person.__bases__ #获取类的基类 print Person.__mro__ #获取类的层次结构 print Person.__subclasses__() #获取类的子类列表
81、组合
# -*- coding=utf-8 -*-
# author=zyq
#使用组合进行代码复用
class A1:
def say_a1(self):
print "a1,a1!!"
class B1:
def __init__(self,a):
self.a=a
a1=A1()
b1=B1(a1)
b1.a.say_a1()
82、工厂模式,单例模式
工厂模式实现了创建者和调用者的分离,使用专门的工厂类将选择实现类,创建对象进行统一管理和控制
# -*- coding=utf-8 -*-
# author=zyq
class CarFactory:
def create_car(self,brand):
if brand=='奔驰':
return Benz()
elif brand=='宝马':
return BMW()
elif brand=='比亚迪':
return BYD()
else:
return "未知品牌"
class Benz:
print "宝马"
class BMW:
pass
class BYD:
pass
factory=CarFactory()
c1=factory.create_car("奔驰")
print c1
c2=factory.create_car("weew")
print c2
单例模式:
确保一个类只有一个实例对象,并且提供一个访问该实例的全局访问点
重写new方法和构造方法
# -*- coding=utf-8 -*-
# author=zyq
class Person:
print "测试"
print Person.__doc__ #类的帮助信息
输出结果:
测试
None
# -*- coding=utf-8 -*-
# author=zyq
class Person:
print "测试"
print Person.__doc__ #类的帮助信息
class Employee:
empCount=0 #定义类变量
def __init__(self,name,salary): #构造函数,self代表类的实例,代表当前对象的地址
self.name=name
self.salary=salary
Employee.empCount+=1
def displayCount(self): #实例方法
print "员工数量是:{0}".format(Employee.empCount)
def displayEmployee(self):
print "员工的姓名是:{0},薪资是:{1}".format(self.name,self.salary)
e=Employee("zyq",3000) #创建实例对象,第一个对象
e1=Employee('zy',4000)#创建实例对象,第二个对象
e.displayCount()
e.displayEmployee()
e1.displayCount()
e1.displayEmployee() #访问方法
print e.name #访问属性、
print Employee.empCount #访问类变量
e.name='zyq1' #修改name的属性为zyq1
print e.name
e.age=20 #添加一个不存在的属性
print e.age
del e.age #删除一个属性
#print e.age
#使用以下函数的方式访问属性
print "函数访问属性"
print hasattr(e,'name') #检查是否存在一个属性,如果存在,则返回true
setattr(e,'name','zyq2') #设置一个属性的值
print getattr(e,'name') # 访问对象的属性
delattr(e,'name') #删除对象的属性
e.name='zyq'
print Employee.__dict__ #返回类的属性
print Employee.__name__ #返回类的名字
print Employee.__module__ #返回类所在的模块
print Employee.__mro__ #返回类的层次结构
print Employee.__bases__ #返回类的所有父类构成元素
# -*- coding=utf-8 -*-
# author=zyq
#测试继承,重写,多态
class Parent: #定义父类
parentAttr=100 #定义类变量
def __init__(self,age): #定义构造函数
self.__age=age #定义私有属性
print "调用父类构造函数"
def parentMethod(self): #调用实例的方法
print "调用父类方法"
print self.__age
def setAttr(self,attr):
Parent.parentAttr=attr
def getAttr(self):
print Parent.parentAttr
def showInfo(self):
print "显示父类的信息",self
class Child(Parent): #定义子类,继承父类
def childMethod(self):
print "调用子类的方法"
#重写父类的方法
def showInfo(self):
print "显示子类的信息", self
c=Child(20) #实例化子类
c.childMethod() #调用子类的方法
c.setAttr(200) #调用父类的方法
c.getAttr() #调用父类的方法
c.parentMethod() #d调用父类的方法
c.showInfo()
print "访问私有变量"
print c._Parent__age #访问私有变量
#isinstance()布尔函数判断一个类是另一个类的子类或者子孙类
#issubclass() 布尔函数,判断对象是类的实例对象或者是一个子类的实例对象,则返回true
print isinstance(c,Parent)
print issubclass(Child,Parent)
83、模块(module)是一个python文件,以.py结尾
模块定义好之后,利用import语句来引入模块,已经导入的模块会保存在sys.modules字典中
import module1...
使用时,用modul1.函数名
一个模块只会被导入一次,不管你执行了多少次import
from...import语句:从模块中导入一个指定的部分到命名空间中,from modname import name1...
当你导入一个模块,python解释器对模块位置的搜索顺序是:
当前目录
如果不在当前目录,则搜索在shell变量pythonpath下的每个目录
如果找不到,会查看默认路径
import support as s #为模块起别名
import os,sys #导入多个模块
模块应该一个一个的导入,先后顺序是内置模块,第三方模块,自定义模块
内置模块:安装好python环境置灰,直接使用import导入的就是内置模块,在安装目录的Lib文件夹下
第三方模块:引用的第三方的模块,比如
自定义模块:自己定义的模块
常用模块:re模块,collections模块,tim模块,random模块,sys模块,序列化模块
# -*- coding=utf-8 -*-
# author=zyq
import re #导入re模块,正则表达式
import collections #内建的集合模块
import random #产生伪随机数的模块
import os #调用系统命令的模块
import sys #
ret=re.findall("ev","eva evgon yuane") #返回所有满足条件的结果,放在列表里
print ret
ret=re.search("ev","gon yuanev").group() # 会在字符串内查找模式匹配,直到找到第一个匹配,然后返回一个包含匹配信息的对象
#该对象可以通过调用group()方法得到匹配的字符串
print ret
#ret=re.match("ev","gon yuanev").group() #同search,在字符串开始处进行匹配
#print ret
ret=re.split("e","eva evgon yuan")#按e进行分割,得到"","va","vgon","yuan","" ['', 'va ', 'vgon yuan']
print ret
ret=re.split("ev","eva evgon yuan")#先按e进行分割,再按v进行分割
print ret
ret=re.sub("\d","H","eva3evgon4yuane4",2)#将数字替换为H,参数2表示只替换2个
print ret
ret=re.subn("\d","H","eva3evgon4yuane4") #将数字替换为H,一共替换了多少次,返回元组
print ret
obj=re.compile("\d{3}")#将正则表达式编译为一个正则表达式对象,规则要匹配的是3个数字
ret=obj.search("abc1238999wsd").group()
print ret
ret=re.finditer("\d","weew12") #返回一个迭代对象,每迭代一次,返回一个匹配的对象
print ret
print next(ret).group() #返回结果为1
print next(ret).group()
ret = re.findall('www.(baidu|oldboy).com', 'www.oldboy.com')
print(ret) # ['oldboy'] 这是因为findall会优先把匹配结果组里内容返回,如果想要匹配结果,取消权限即可
ret = re.findall('www.(?:baidu|oldboy).com', 'www.oldboy.com')
print(ret) # ['www.oldboy.com']
ret=re.split("\d+","eva3egon4yuan")
print(ret) #结果 : ['eva', 'egon', 'yuan']
ret=re.split("(\d+)","eva3egon4yuan")
print(ret) #结果 : ['eva', '3', 'egon', '4', 'yuan']
#在匹配部分加上()之后所切出的结果是不同的,
#没有()的没有保留所匹配的项,但是有()的却能够保留了匹配的项,
#这个在某些需要保留匹配部分的使用过程是非常重要的。
# -*- coding=utf-8 -*-
# author=zyq
import time
print time.time() #获取当前时间,时间戳的形式
#表示时间的三种形式,时间戳,元组,格式化的时间字符串
print time.strftime("%Y-%m-%d %X") #获取本地相应的时间
print time.strftime("%Y-%m-%d %x") #获取本地相应的日期
print time.strftime("%Y-%m-%d") #获取年月日
print time.strftime("%Y-%m-%d %H-%M-%S") #获取本地相应的年月日,时分秒
print time.strftime("%a") #获取本地简化的星期名称
print time.strftime("%A") #获取本地完整的星期名称
print time.strftime("%b") #获取本地简化的月份
print time.strftime("%B") #获取本地完整的月份
print time.strftime("%c") #获取本地相应的日期和时间
print time.strftime("%j") #获取一年中第多少天
print time.strftime("%U") #获取一年的星期数
print time.strftime("%Z") #获取市区的名称
print time.localtime()# 将一个时间戳转换为当期时区的struct_time
print time.gmtime(1500000000) #UTC时间,与英国伦敦时间一致
print time.localtime(1500000000) #当地时间
print time.asctime(time.localtime(1500000000))
print time.asctime() #返回当前时间的格式化串
print time.ctime() #返回当期时间的格式化串
print time.ctime(1500000000)
# -*- coding=utf-8 -*- # author=zyq import random print random.random() #随机生成0-1的小数 print random.randint(1,5) #随机生成大于等于1小于等于5的整数 print random.randrange(1,5,2) # 随机生成大于1小于5的奇数 print random.choice([1,2,[4,5]]) #随机选择一个返回 item=[2,4,6,8] random.shuffle(item) print item #打乱顺序返回 #生成随机的验证码 def v_code(): code="" for i in range(5): num=random.randint(0,9) #生成0-9之间的整数 alf_upper=chr(random.randint(65,90)) #生成65-90之间的整数,转化成字母 alf_lower = chr(random.randint(97, 122))#生成97-122之间的整数,转化成字母 add=random.choice([num,alf_upper,alf_lower]) #从字母数字中随机选一个 code="".join([code,str(add)]) return code print(v_code())















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









