







在C语言当中是没有字符串类型的,如: char* p = "hello" ,当中的p是一个char类型的指针,并不是字符串。
String str = "hello";上述的 str 就是一个字符串类型的变量。
我们查看文档,发现String是一个类,而且是被final修饰的类;

说明这类是不能被继承的。
我们还可以这样定义字符串:
String str1 = new String("abcdef");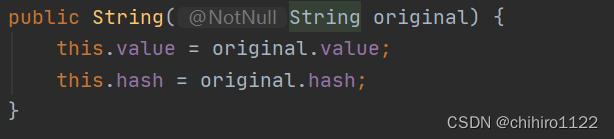
上图是这个String方法的源代码,我们发现,此时我们传入的字符串“ abcdef “ 是传入到String类中的value进行引用的,相当于是value指针指向 ” abcdef “字符串。
我们在使用上述的定义方式的时候,发现报了警告:

意思是,这种定义方式和第一种直接在 + 号后面写字符串是一样的。
我们还可以这样写:
char[] val = {'a','b','c','d','e','f'};
String str3 = new String(val);
System.out.println(str3);//abcdef我们上述定义了一个char类型的数组,这个数组中存储abcdef六个字符,我们在传入val数组,我们发现打印结果是abcdef的字符串。
我们按住ctrl点击此时的String方法,查看源代码:

我们发现,让我们传入char[] 数组 的参数的时候,此时使用的是Arrays中的copyOf这个方法,此时是把value拷贝成一个副本,然后把这个副本的地址传给this.value。我们也可以再次用Ctrl点击这个copyOf方法,查看此时这个方法的源代码:
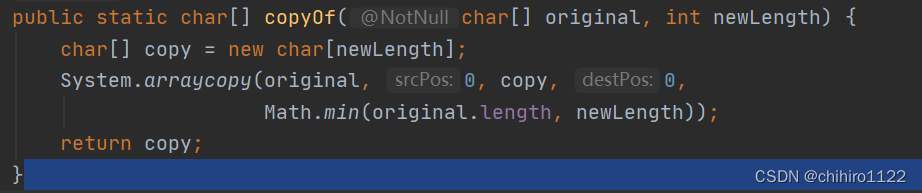
那么上述三种定义数组的方式就是我们平时最常用的三种定义方式,上述的三种方式都是引用。
String str = "hello";对于这个代码,他在内存中是这样存储的:
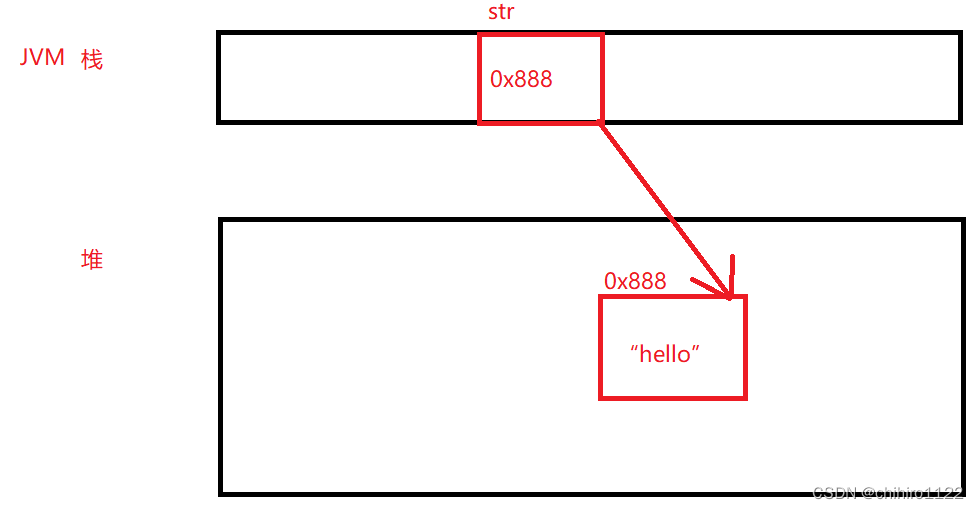
那么我们来看这个例子:
public static void main(String[] args) {
String str1 = "Hello";
String str2 = str1;
str1 = "world";
System.out.println(str2);
System.out.println(str1);
}既然str是引用,是指向字符串的指针,那么我们上述的例子对str1的修改会改变str2当中的内容吗?大那是不会的,下图是打印结果:

发生这个结果的原因是,我们在使用 str1 = "world" 类似的语句的时候,其实不是修改了这个地址中的字符串,而是创建了一个新的字符串,然后让str1 这个指针指向新的地址,这个地址就指向新的字符串。
我们再举一个例子来理解这里的引用:
public static void func1(String str,char[] array)
{
str = "abcdef";
array[0] = 'd';
}
public static void main(String[] args) {
String str1 = "hello";
char[] str2 = {'a'};
System.out.println(str1);//hello
System.out.println(str2[0]);//a
func1(str1,str2);
System.out.println(str1);//hello
System.out.println(str2[0]);//d
}我们发现在函数中,没有对字符串的引用进行修改,但是对char[] 数组中的0号下标位置的数据进行了修改。
此时这些变量在内存中是这样存储的:
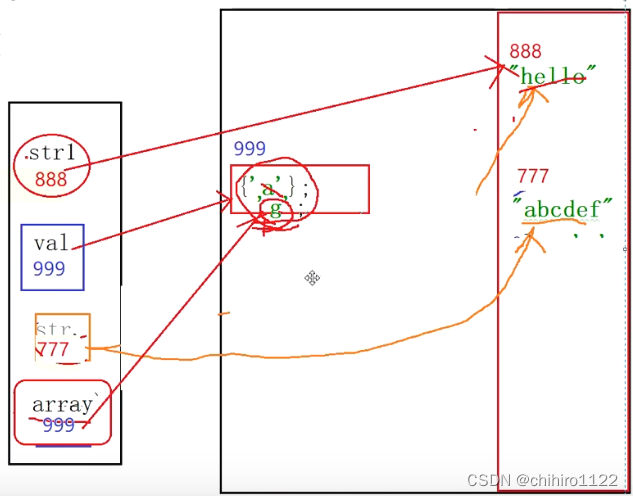
再来看一个例子:
public static void main2(String[] args) {
String str1 = "hello";
String str2 = new String("hello");
String str3 = "hello";
System.out.println(str1 == str2);//false
System.out.println(str1 == str3);//true
}为什么两次的结果不一样呢?
首先来看这个,我们之前说过,字符串变量是引用类型,所谓引用类型存储的是字符串的地址,那么上述的 str1 == str2 对比的是两个变量的地址相不相同,那么很显然是不相同的,所以表达式结果为false。
为什么上述两个变量比较的是地址,因为在 == 两边的变量都是引用类型,不是简单类型。
![]()
那么 str1 和str 3 都是引用类型,那就说明 str1 和 str3 存放的地址是一样的。
造成这个原因,是因为在java中有一个字符串常量池。
那么对于上述的字符串创建,我们来画个图:
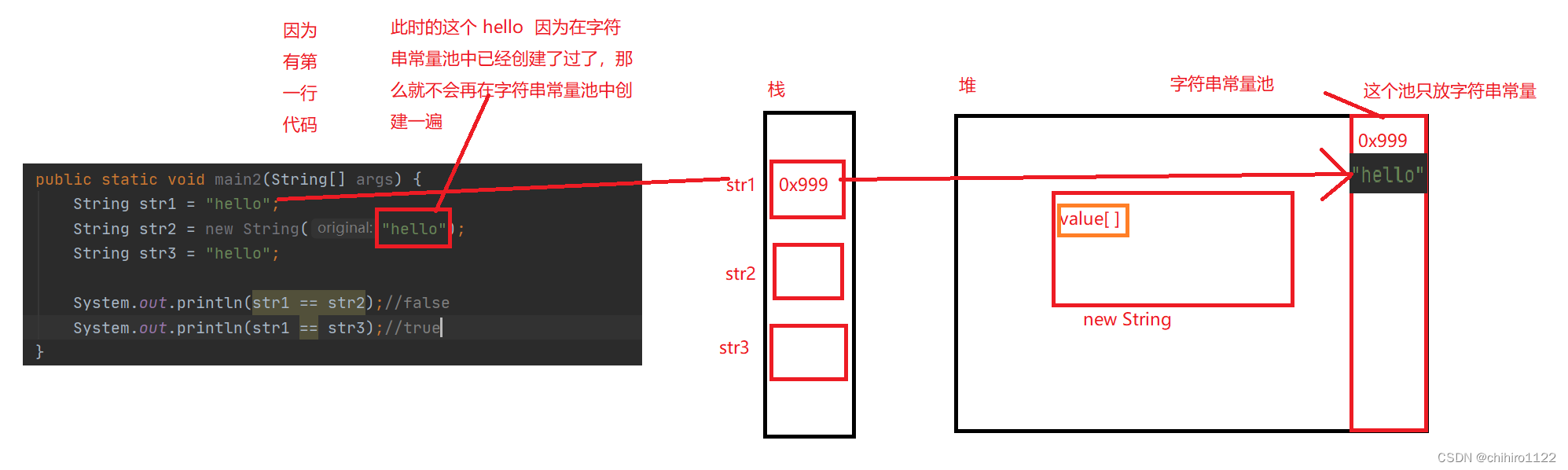
此时因为第二行代码,new了一个对象,那么这个对象就要在堆上开辟空间,而我们之前看过String的源代码,发现这个类中有一个value[ ] 的一个数组:

然后,当我们用new 创建对象来创建一个新的数组的时候,是从original.value,这个地方来获取地址的,那么其实这个original,就是这个字符串来字符串常量池中的地址:
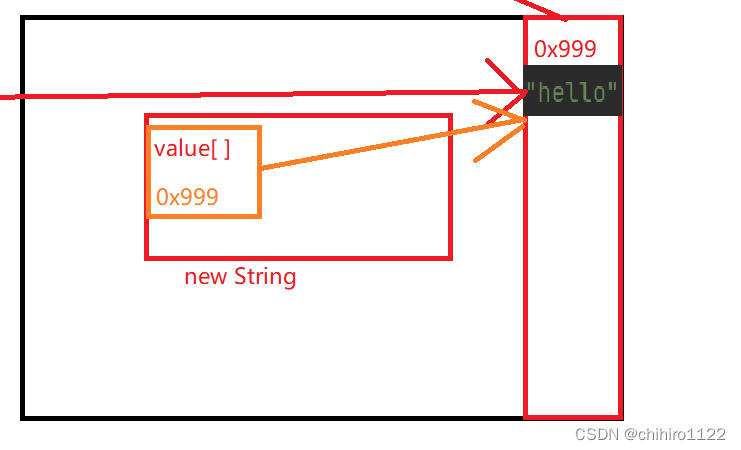
那么此时定义到 str2 时候的内存应该是这个样子的:
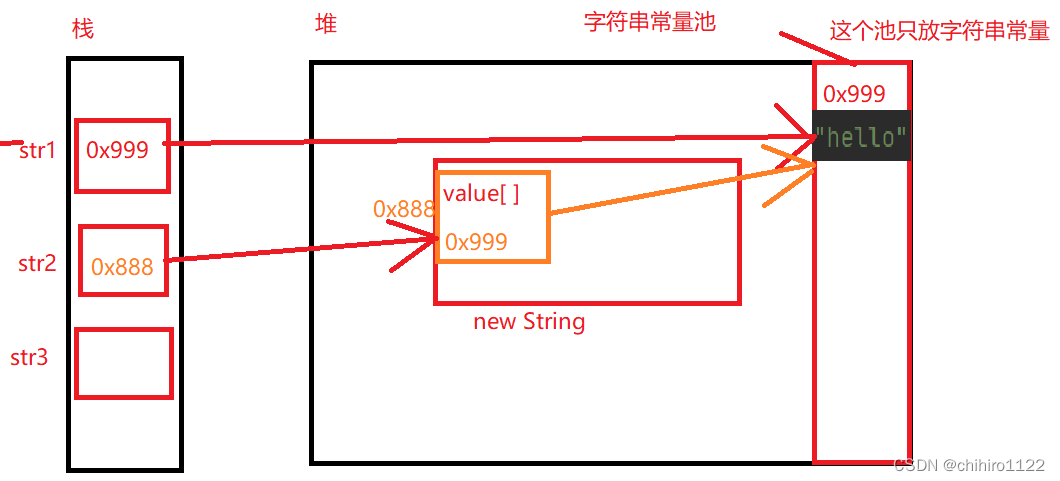
接下来是定义str3 ,那么在str3 的时候,编译器也尝试的在字符串常量池中,创建一个 “hello ” 的字符串常量,但是此时在字符串常量池中已经有了,我只要保证字符创常量池中只有一个相同的常量就行了。
那么此时的图如下:
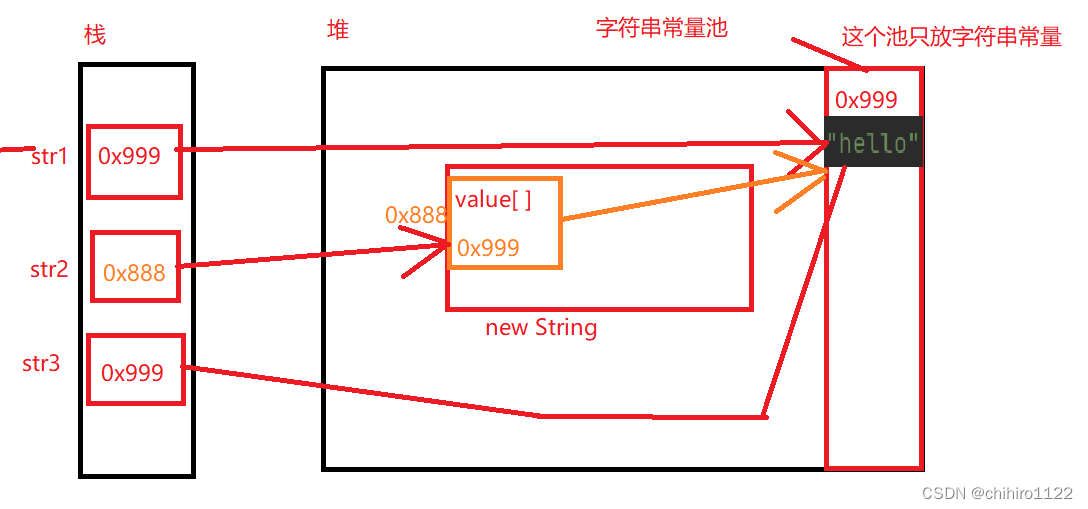
但是,此时我们使用 intern() 这个方法,就可以达到判断字符串相等的目的:
public static void main(String[] args) {
String str1 = "hello";
String str2 = new String("hello").intern();
System.out.println(str1 == str2);//true
}我们可以发现此时,打印出的结果不是false 了而是true。
那么此时这个intern 方法做了什么,我们来画图理解:
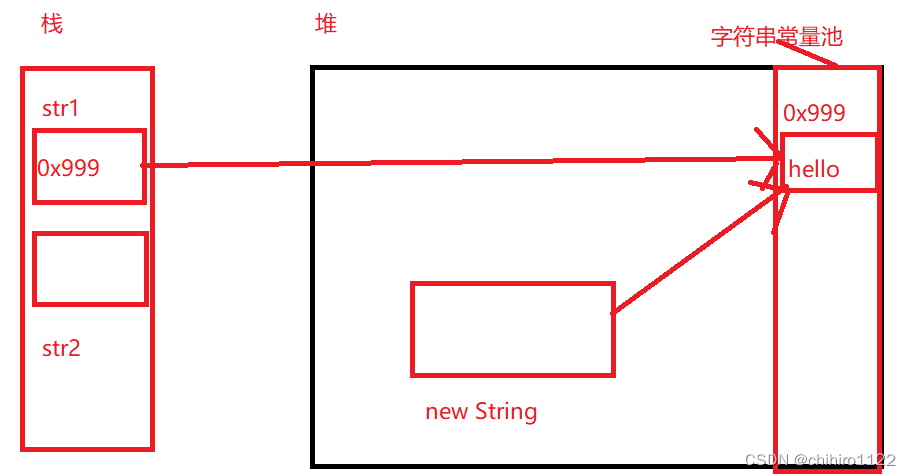
此时呢,在初始化str1 的时候,同样会在 字符串常量池中创建 “hello” 的内存,然后str1 引用类型指向这块内存,然后再初始化 str2 的时候 同样会在堆中创建一个 new String的对象,但是之后因为有一个 intern ()方法,所以变得不一样了。
当我们调用了intern() 方法之后,他就会判断,在字符串常量池中有没有这个字符串,如果有这个字符串,那么就会直接把这个字符串存储的地址,直接返回到str2 中。

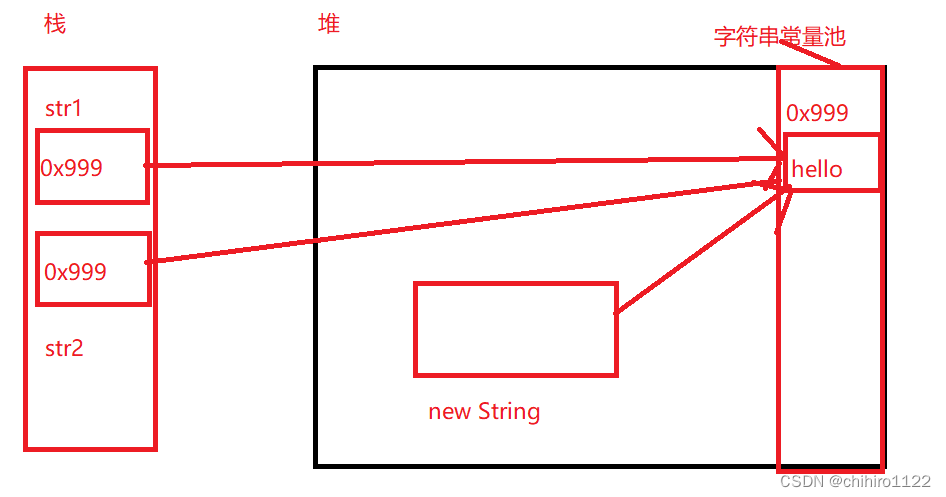
此时str2 中存储的地址就是,字符串常量池中储存 “hello” 的内存地址。
intern():手动入池,从现象上来看。
判断当前的这个字符串在常量池中是否存在?如果存在,把常量池中的引用,赋值给当前的引用类型变量;如果不存在,那么会在常量池生成这个字符串的内存,然后再把这个内存的地址,传给当前引用类型变量存储。
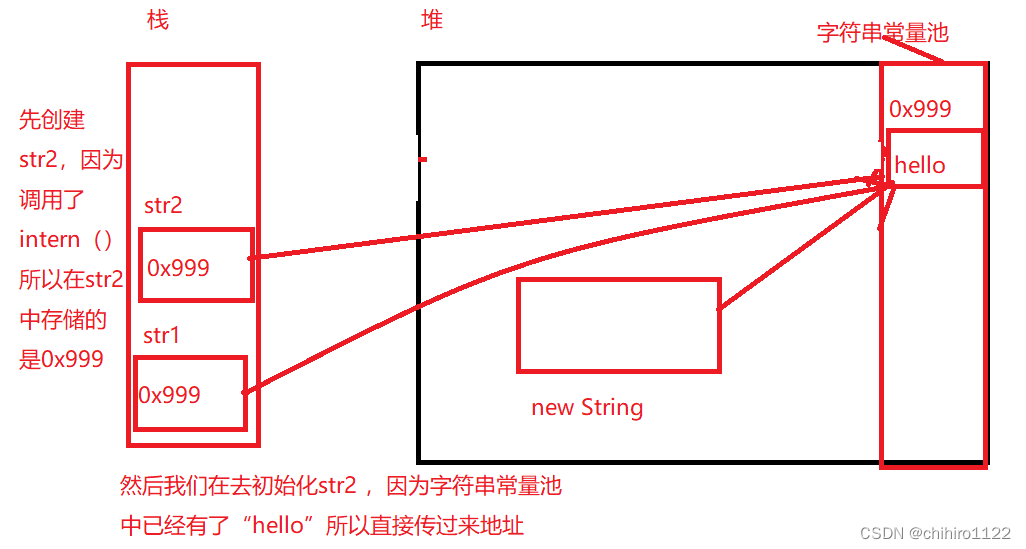
也就说,如下例子,应该还是打印true:
public static void main(String[] args) {
String str2 = new String("hello").intern();
String str1 = "hello";
System.out.println(str1 == str2);//true
}此时的内存存储:
在看如下例子:
public static void main(String[] args) {
String str1= "hello";
String str2 = "hel" + "lo";
String str3 = new String("hel") + "ol";
System.out.println(str1 == str2);//true
System.out.println(str1 == str3);//false
}那么在字符串常量池中,在对str2 进行初始化的时候,并不是"hel" "lo" 两个字符串来在字符串常量池中进行存储的,因为 双引号 括起来的 是常量,而常量有一个特点,在编译时期就已经处理完了,也即是说,上述情况的str2 在编译时期就已经变成 “ hello ” 了。那么接下来我们在想在字符串常量池中去尝试存储 “ hello ” 是不行的,因为我们在定义 str1 的时候就已经存储过 “ hello“ 了。
那么此时我们在执行 str3 的时候又有些许不一样:
因为 在 new 对象中 “hel” 是没有的,所以此时"hel" 会放进字符串常量池中,那么后面的 “ol” 常量也会放入字符串常量池中。
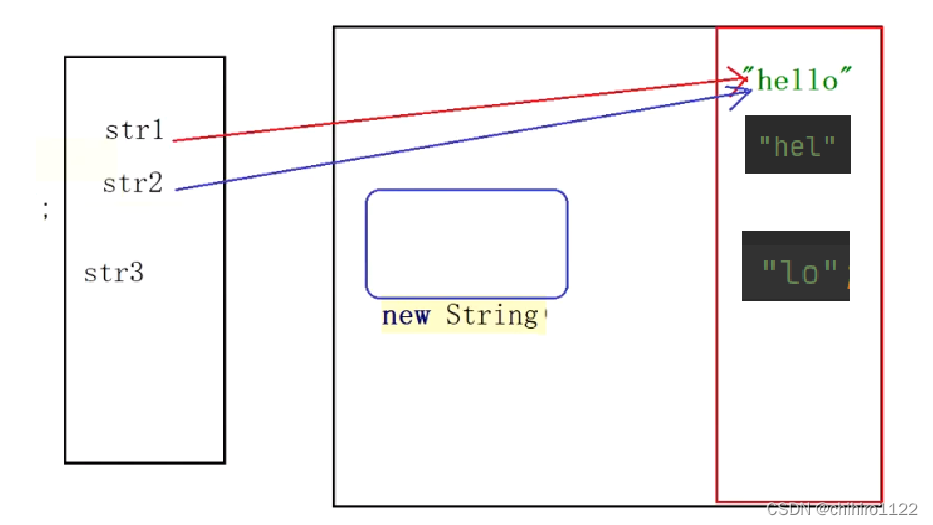
那么接下来就是 对象和 “ol” 常量之间的 + 实现了什么功能呢?
在 + 之后,new String对象和 “ol” 在堆里面会重新生成一个对象,这个对象存储的是拼接之后的结果:“hello”,然后 栈中的str引用,会直接指向这个新的对象,不在指向 new String,如图:
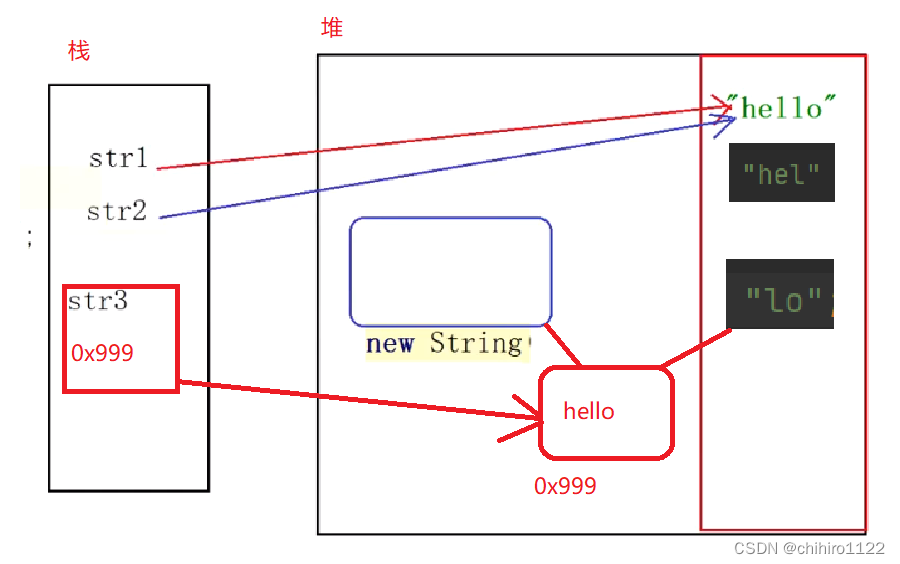
也就是说,以后我们在要想比较两个字符串的内容,那么我们可以用equals方法:
public static void main(String[] args) {
String str1 = "hello";
String str2 = new String("hello");
System.out.println(str1.equals(str2));//true
}这样我们就可以,比较两个字符串是否一样,这个方法返回的是 boolean类型的。
当我们按住 ctrl 点击这个equals方法:
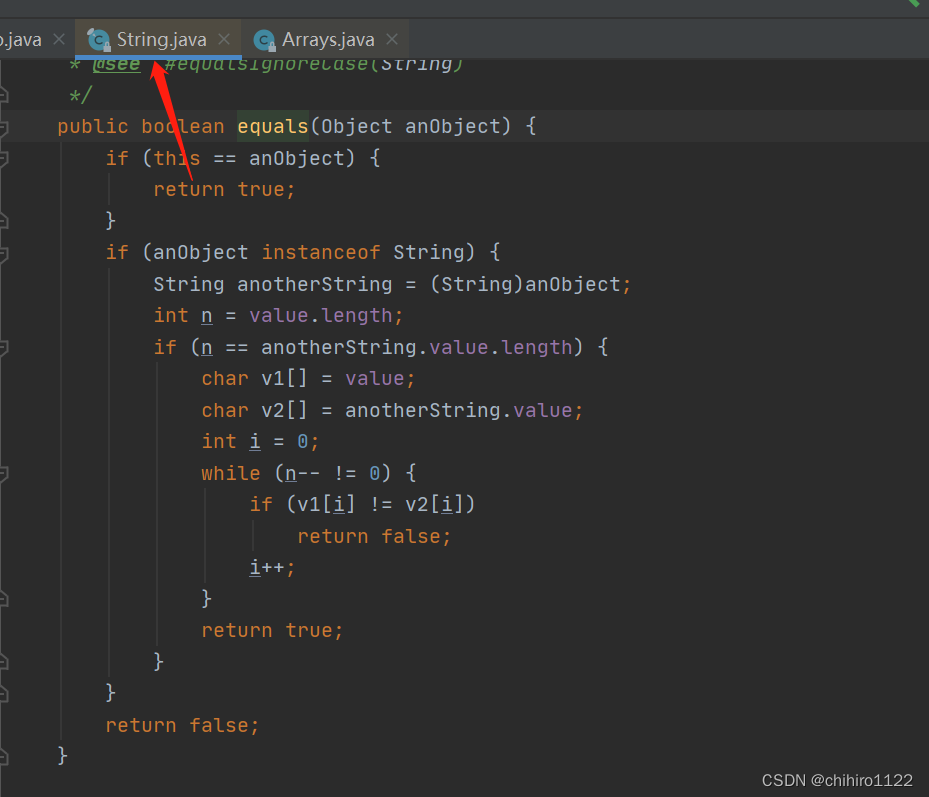
我们发现这个方法原本是在 Object 中的,但是我们打开的确实String 的文件,说明在String是重写了这个equals方法,当我们在打开 Object 文件找到 其中的 equals方法:

我们发现在Object 文件中的equals方法,如果不进行重写,那么 equals 方法默认比较的是引用,是this 当前类中的 进行比较。也就是说,此时比较的是,引用是否相同。
在使用equals 方法的时候需要注意,我们可以比较一个字符串,和null 字符串是否相等,但是,我们不用去使用null的字符串中的equals 方法:
public static void main(String[] args) {
String str1 = "hello";
String str2 = null
System.out.println(str1.equals(null)); // 这个是可以的 结果是 false
System.out.println(str1.equals(str2)); // 这个是可以的 结果是 false
System.out.println(str2.equals(str1));//这个是不行的
}如果我们使用第三个方式的话,就会报错:

那么其实我们直接使用字符串也可以直接使用这个字符串的equals方法:
String str1 = "hello";
System.out.println(str1.equals("hello"));//true但是我们尽可能的不去这样写,我们一般要如上述比较的话,一般用的“hello” 的equals方法:
System.out.println("hello".equals(str1));//true这是因为,有可能str1 这个引用类型,引用的是一个null字符串,那么我们使用上述第一种的方式来使用的话,就会报错。但是我们使用第二种方式就不会报错了。
字符串常量池
字符串常量池,即String Constant Pool,又叫做String Pool,String Table。顾名思义,即用于存放字符串常量的运行时内存结构,其底层实现为一种Hashtable。其中所指的字符串常量,可以是编译期在源码中显式的字符串字面量,也可以是之后在程序运行时创建的字符串String对象。
在JDK1.6及之前,字符串常量池中只会存放具体的String实例,在使用String.intern方法时,若字符串常量池中有满足String.equals方法的String对象,则返回其引用;若字符串常量池中没有相同的String对象,则当前String对象为堆上对象,故在字符串常量池中创建一个相同的String对象,并返回其引用。
在JDK1.7及之后,字符串常量池中不仅可以存放String实例,同时还能存放指向Java堆中某个String实例的引用。在使用String.intern方法时,若字符串常量池中有满足String.equals方法的String对象,则返回其引用,这一点和JDK1.6相同;若字符串常量池中没有相同的String对象,则当前String对象为堆上对象,故在字符串常量池中存放一个指向堆上此String对象的引用,并返回此引用。
(上述转自Java字符串常量池_Arambler的博客-CSDN博客)
那么简单理解:
String类的设计使用了共享设计模式
在JVM底层实际上会自动维护一个对象池(字符串常量池)
- 如果现在采用了直接赋值的模式进行String类的对象实例化操作,那么该实例化对象(字符串内容)将自动保存到这个对象池之中.
- 如果下次继续使用直接赋值的模式声明String类对象,此时对象池之中如若有指定内容,将直接进行引用
- 如若没有,则开辟新的字符串对象而后将其保存在对象池之中以供下次使用
举个例子:
"池"(pool) 是编程中的一种常见的, 重要的提升效率的方式, 我们会在未来的学习中遇到各种 "内存池", "线程池", "数据库连接池" ....
然而池这样的概念不是计算机独有, 也是来自于生活中. 举个栗子:
现实生活中有一种女神, 称为 "绿茶", 在和高富帅谈着对象的同时, 还可能和别的屌丝搞暧昧. 这时候这个屌丝被
称为 "备胎". 那么为啥要有备胎? 因为一旦和高富帅分手了, 就可以立刻找备胎接盘, 这样 效率比较高.
如果这个女神, 同时在和很多个屌丝搞暧昧, 那么这些备胎就称为 备胎池.
也就是说,假设我先有三个字符串引用,都指向了“hello”这个字符串,那么我们不需要在堆上开辟三块空间来存储 三个 “hello” ,我只需要在字符串常量池中创建一个“hello“ 的内存来存储”hello“ ,然后我上述的三个字符串引用都指向这个 ” hello “ 内存就行了,这样就提高了内存的使用效率。
字符串不可变
我们先来看一个例子:
public static void main(String[] args) {
String str1 = "hello";
str1 = str1 + " world";
str1 += "!!!";
System.out.println(str1);//hello world!!!
}上述代码成功实现了字符串的拼接,但是实际在内存中操作可没有这么简单。因为String字符串类型在源代码实现的本质也是使用char[] 数组来实现的,这个类中也没有set 的类似方法来修改这个类中的char[] 数组。也就说 字符串是不可变的。
那么上述的字符串拼接是如何实现的呢?
首先,str1 是一个引用类型的变量,不是常量,那么在第二行代码,str1 = str1 + " world" ;这个代码实现的时候,后面的str1 + “ world”是不会在编译期间进行拼接的,只要 + 两边都是常量的时候才能进行拼接,如: str1 = "hello" + " world";这串代码,后面的 “hello” 和 “ world” 在编译时期就会进行拼接。
那么此时在执行str1 = str1 + " world" ;这个代码的时候,会先在字符串常量池中创建一个 存储” world“的内存,然后再继续拼接,拼接出来的 “hello world”字符串又会在字符串常量池中,再次创建一块空间进行存储,如下图所示:
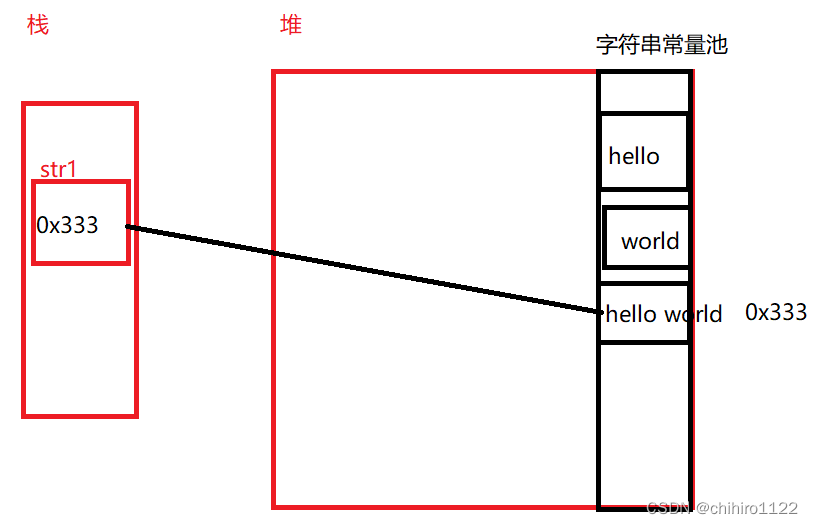
此时的str1 之前是指向hello位置的,现在指向了hello world位置,那么下一行代码也是一样的,会先在字符串常量池中创建“!!!”的内存,然后再和“hello world”进行拼接,然后再在字符串常量池中存储“hello world!!!”这个结果:
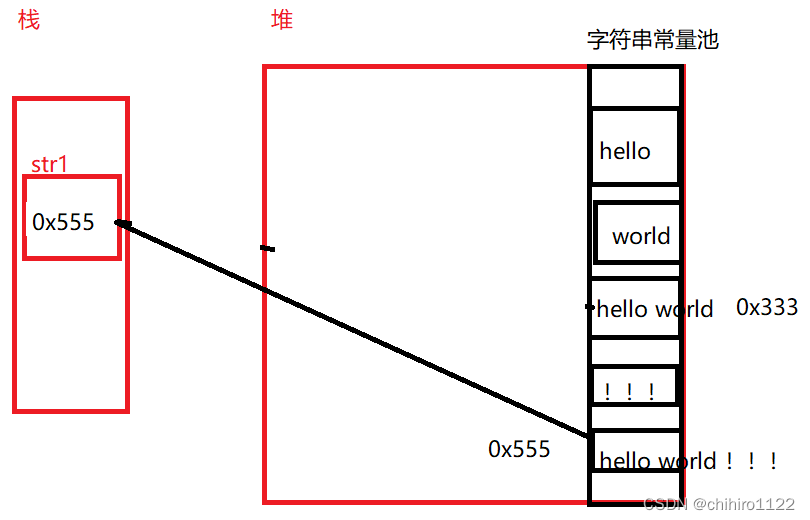
最后用的是最后拼接出来的结果,那么我们发现,如果我们用上述方法进行字符串拼接,会在字符串常量池中创建很多的字符串常量,那么当我们的拼接基数很大的时候,就会使用很多字符串常量池中的内存:
for(int i = 0; i < 10000;i++)
{
str1 += "!";
}此时我让字符串str1 拼接10000次!,那么我们会在字符串常量池中创建很多的 “!”字符串常量。
那么既然字符串不可变,那么我们想要修改字符串该如何进行修改呢?
a)借用原字符串,创建新的字符串:
比如现在,现有字符串 str = "Hello" , 想改成 str = "hello" :
public static void main(String[] args) {
String str = "Hello";
str = "h" + str.substring(1);
System.out.println(str);//hello
}其中的substring(1)方法表示的是,从这个字符串下标为1的位置开始读写,直到把这个字符串读完。
也就是说,此处并不是把“Hello”改为了”hello“,而是在字符串常量池中产生了一个全新的字符串”hello“。
那么此处的修改可以直接对str引用对象好像修改:
str = "hello";此处也是在字符串常量池中创建了一个“hello”字符串常量,然后str引用这个字符串常量的地址。
那么我们上述都是在字符串常量池中创建一个新的字符串常量,然后引用这个新的字符串常量,那么可以不可以直接对“Hello” 进行修改呢?我想直接把“Hello” 改为 “hello” ,那么此时应该这样操作:
利用反射来修改字符串:
我们使用 "反射" 这样的操作可以破坏封装, 访问一个类内部的 private 成员,也就是说,我们使用反射可以在类外访问这个类中的 私有的 方法和成员属性。
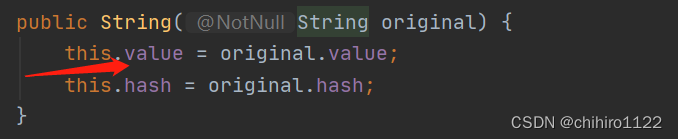
我们查看String的源代码,发现java是用一个 char[] 类型的数组来存储字符串的:
![]()
那么,我们要想修改字符串中的内容,首先就要找到这个存储字符串的数组。
首先我们要创建String的class对象:
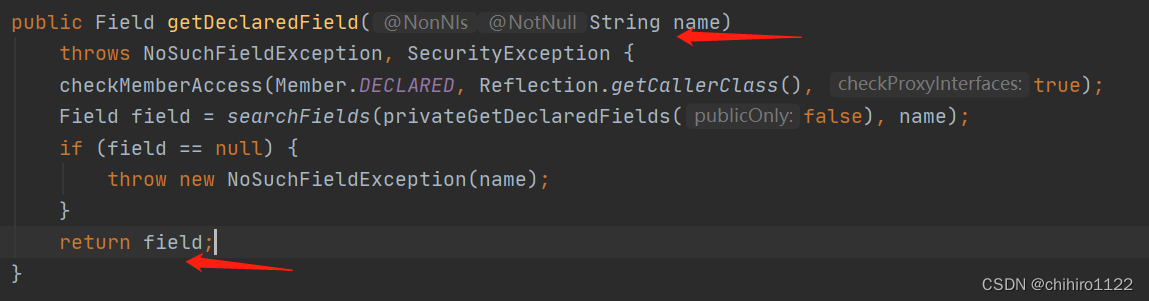
拿到这个对象之后,我们要使用这个对象中的getDeclaredField() 方法,那使用这个方法,之前我们先要导入这个方法的包:
![]()
然后,我们查看这个方法的源代码,发现这个方法是需要返回一个 Field 类型的数的,而且这个方法需要传参,传入的参数就是我们需要拿到String当中的上面字段,那么刚刚我们已经说过了,我们要拿到String中的value字段,那么我们就用“value”的方式传参,并且用一个 Field 的变量接收返回值:

这个函数中的 ”value“ 这个参数是不能随便写的,因为此处的参数表示我要在String这个类中拿到其中的上面字段,上述说过,我要拿到的是value字段内容,所以我们传入的是value的字符串,假设我此时传入的 value2 这个字符串,但是String类中没有这个字段的内容,那么这个方法就拿不到对应的字段内容。
而且我们发现,这个方法在实现的时候是声明了一个异常的: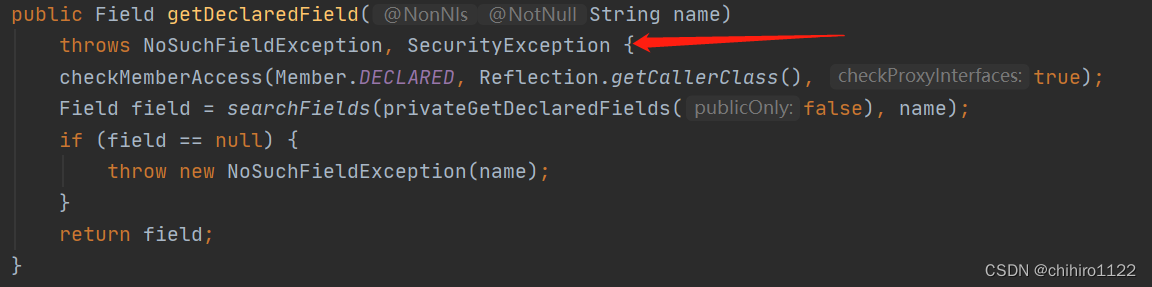
我们可以手动输入,在idea中也可以使用 Alt + Enter ,然后点击Add,就可以自动的申明异常:

因为这个value在String类中是一个私有的属性,那么我们要想修改这个私有属性,就要使用我上述定义的 Field 类型的 field 对象中的 setAccessible()方法来了修改,我们把这个的值设置为true就可以对value进行修改:
![]()
把私有的权限设置为true之后,才能对value进行修改,否则后面反射之后也是不能修改的。
接下来就是拿到这个value中的值,我们利用field对象中get()方法就可以拿到这个value数组的值:

此时他还会抛出异常,那么我们同样使用 Alt + Enter 点击Add来对这个异常进行声明,而且这个方法的返回值是Object类型的,那么我们需要把返回值类型强转为 char[] 类型我们才能用char[] 类对数组进行接收;
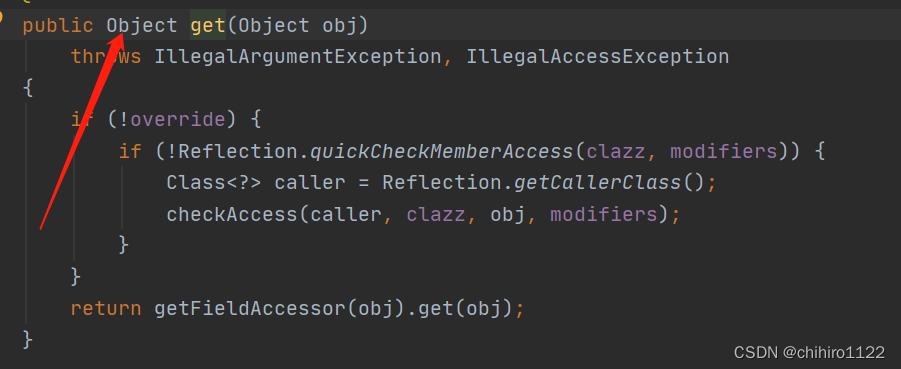
field的get方法的具体实现:
![]()
这样我们就拿到了 value 数组中的内容,保存到了 val数组中,因为数组名是对这个数组的引用,那么我们就可以利用这个val数组对其中的value进行修改:

然后我们打印这个字符串的内容,发现不在是“Hello” ,而是 “gello” ,字符串中0号下标位置的字符已经被修改:

那么我们在使用这个方法的时候就要在类中申明这个异常,接下来是完整的getDeclaredField() 方法使用:
public static void main(String[] args) throws NoSuchFieldException, IllegalAccessException {
//创建一个 “Hello” 字符串
String str = "Hello";
//创建一个 Class 的对象,引用String中的class
Class c1 = String.class;
//拿到String类中 value 字段的内容
Field field = c1.getDeclaredField("value");
//设置 value 的访问属性 为true之后才能进行修改
field.setAccessible(true);
//获取str 中的 value属性
char[] val = (char[])field.get(str);
//修改这个属性的 0 号下标的字符
val[0] = 'g';
//打印这个字符串
System.out.println(str);
}上述就是反射的具体实现,我们发现此时我们把 “Hello” 字符串 修改为了 “gello” ,发现反射确实能修改私有的属性。
反射是面向对象编程的一种重要特性, 有些编程语言也称为 "自省"。
指的是程序运行过程中, 获取/修改某个对象的详细信息(类型信息, 属性信息等), 相当于让一个对象更好的 "认清自己" 。
那么我们之所以使用反射来修改字符串,都是也在java中在,字符串是不可变的,那么,为什么要把字符串设置为不可变呢?这样做有什么好处?
- 方便实现字符串对象池. 如果 String 可变, 那么对象池就需要考虑何时深拷贝字符串的问题了.
- 不可变对象是线程安全的。
- 不可变对象更方便缓存 hash code, 作为 key 时可以更高效的保存到 HashMap 中
首先因为,字符串不可变,当我们创建一个字符串对象的时候,如果此时字符串常量池中已经有了这个字符串,那么就不需要在创建一个字符串对象,可以直接对字符串常量池中的字符串进行引用。
在java中哈希码被频繁的使用,因为字符串是不可变的,那么我字符串就对应这一个唯一的哈希码,那么就不需要每一次创建调用这个字符串的时候都计算一遍哈希码,这样做就提高了性能。
为了安全性,因为String类是被很多类所使用的,那么如果String类中的value不是私有的,那么当我在其他方法或类中修改了其中的值,那么结果是可怕的。
字符,字节和字符串
字符和字符串
字符串内部包含一个字符数组,String类型和 char[] 类型可以相互转换。
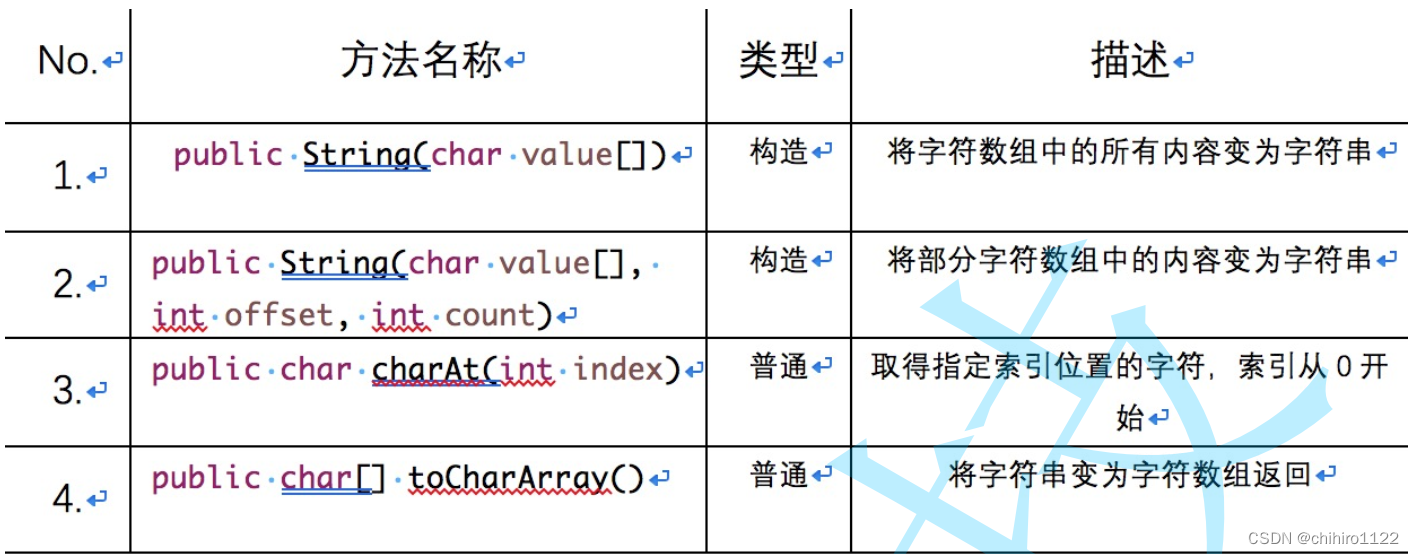
1)相当于之前创建字符串的基本方法,new一个String对象,这个对象存储val字符数组中的内容:
public static void main(String[] args) {
char[] val = {'a','b','c','d','e','f'};
String str = new String(val);
System.out.println(str);//abcdef
}2)offset代表偏移量,就是所哪一个下标位置开始转换,count表示结束位置下标,这两个参数表示的区间是 左闭右闭的( [offset,count] ) :
public static void main(String[] args) {
char[] val = {'a','b','c','d','e','f'};
String str = new String(val,1,4);
System.out.println(str);//bcde
}3) charAt()方法是String类中定义的,那么我们在定义个String对象之后,就可以直接用这个String对象来调用这个方法,这方法中的参数,传入 “1” 就拿到字符串中的 1 下标位置的字符:
public static void main(String[] args) {
String str = "hello";
char ch = str.charAt(1);
System.out.println(ch);//e
}4)将字符串转化成字符数组,并返回,返回值是char[] 类型的:
public static void main(String[] args) {
String str2 = "world";
char[] val = str2.toCharArray();
System.out.println(Arrays.toString(val));//[w, o, r, l, d]
}例子:
判断一个字符串中的字符,是否都是 0 - 9 之间的数字:
public static boolean func(String str)
{
for(int i = 0;i < str.length();i++)
{
char ch = str.charAt(i);
if(ch < '0' || ch > '9')
{
return false;
}
}
return true;
}
public static void main(String[] args) {
String str = "1234a56";
boolean flg = func(str);
System.out.println(flg);
}那么我们上述直接传入一个字符串,然后写一个循环,每一次循环都把这个字符串中的字符给到char类型的ch变量中,然后比较这个字符是否小于 ‘0’ 的ascll码,是否大于‘9’的ascll码,如果满足上述两个条件中的任意一个,就说明这个字符串中不都是0-9的字符,反之都是。
字节和字符串
字节常用于数据传输以及编码转换的处理之中,String 也能方便的和 byte[] 相互转换。

1) 和字符不同的是,字节中的数字,转换为字符串之后,对应位置的字节和字符是靠ascll码来转换的:
public static void main(String[] args) {
byte[] my_byte = {97,98,99,100};
String str = new String(my_byte);
System.out.println(str);//abcd
}我们可以发现,上述打印的不是97,98,99,100,而是abcd。而97,98,99,100就是abcd对应的ascll值。
2)同样的,byte转化为 String的String中也有偏移量,offset代表偏移量,length表示最后一个字符的下标位置,同样也是左闭右闭的:
String str2 = new String(my_byte,1,3);
System.out.println(str2);//bcd3)把字符串转化为byte类型的数组,那么他们的转化也是依据ascll码来转换的,他的返回值是byte[] 类型的:
byte[] val = str.getBytes();
System.out.println(Arrays.toString(val));//[97, 98, 99, 100]这个 getBytes()方法也是有传参的重载方法,但是这个传参的方法已经被弃用了,我们查看文档可以看到:

当我们在idea中使用这个方法的时候,getBytes()方法会被画一条横线,这个代表这个方法已经被弃用了:

我们查看这个带参数的getBytes()方法的源代码,发现在定义getBytes()方法的上面写了@Deprecated的注释,这个注释就代表这个方法已经被弃用了:
4)编码转换处理,把这个字符串转化为对应字符的对于的编码类型:
String str1 = new String("你好");
byte[] byte1 = str1.getBytes("utf8");//[-28, -67, -96, -27, -91, -67]
System.out.println(Arrays.toString(byte1));
byte[] byte2 = str1.getBytes("gbk");//[-60, -29, -70, -61]
System.out.println(Arrays.toString(byte2));我们发现此处打印了对于字符的,对于编码类型的数据。
byte[] 和 char[] 的区别
我们上述实现了字符串转化 字节 和 字符,那么什么时候 byte[] ,什么时候用char[] 类型呢?
当我们在传输二进制数据的时候,如:视频,音频等等 这些数据的时候就用byte[] 类型来进行传输,在网络上的传输也都是一个字节一个字节进行处理的。
如果是处理,传输文本信息的数据的时候,char[] 就比较好用,尤其是在 传输中文的时候,很好用。
字符串的创建操作
字符串比较

1) equals ()方法就是 区分字符大小写的方式,来区分两个字符串是否相等:
public static void main(String[] args) {
String str1 = "abcdef";
String str2 = "ABCDef";
String str3 = "abcdef";
boolean flg = str1.equals(str2);
System.out.println(flg);//false
boolean flg1 = str1.equals(str3);
System.out.println(flg1);//true
}2)有时候我们不想要区分大小写来比较两个字符串是否相等,比如验证码;equalsIanoreCase()方法就是不区分大小写的情况下区别两个字符串是否相等:
public static void main(String[] args) {
String str1 = "abcdef";
String str2 = "ABCDef";
String str3 = "abcdef";
boolean flg = str1.equalsIgnoreCase(str2);
System.out.println(flg);//true
}3)比较两个字符串的大小,我们上述两种方法都只是判断是否相等,但是不能比较谁大谁小。
我们查看String类的源代码,发现String类是实现了Comparable接口的,

那么Comparable接口中有一个comareTo方法,我们可以在实现了Comparable接口的类中,重写其中的comareTo方法,来比较这个类的大小,我们查看源代码,发现在String类中已经重写了这个comareTo方法。
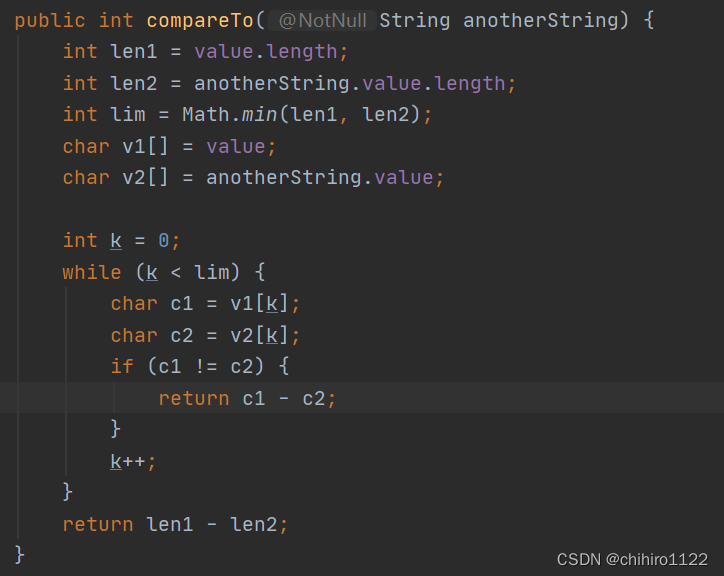
那么String中的comareTo()方法就可以帮助我们来判断两个字符串的大小:
public static void main(String[] args) {
String str1 = "abc";
String str2 = "abcdef";
String str3 = "abcdef";
String str4 = "ABCDEF";
System.out.println(str1.compareTo(str2));//-3
System.out.println(str2.compareTo(str3));//0
System.out.println(str2.compareTo(str4));//32
}也就说,若 str1.comareTo(str2) 这个代码中,str1 比 str2 大,返回一个正数;相等返回0;小返回负数。
字符串替换
使用一个指定的字符串替换掉已有的字符串数据,可用方法如下: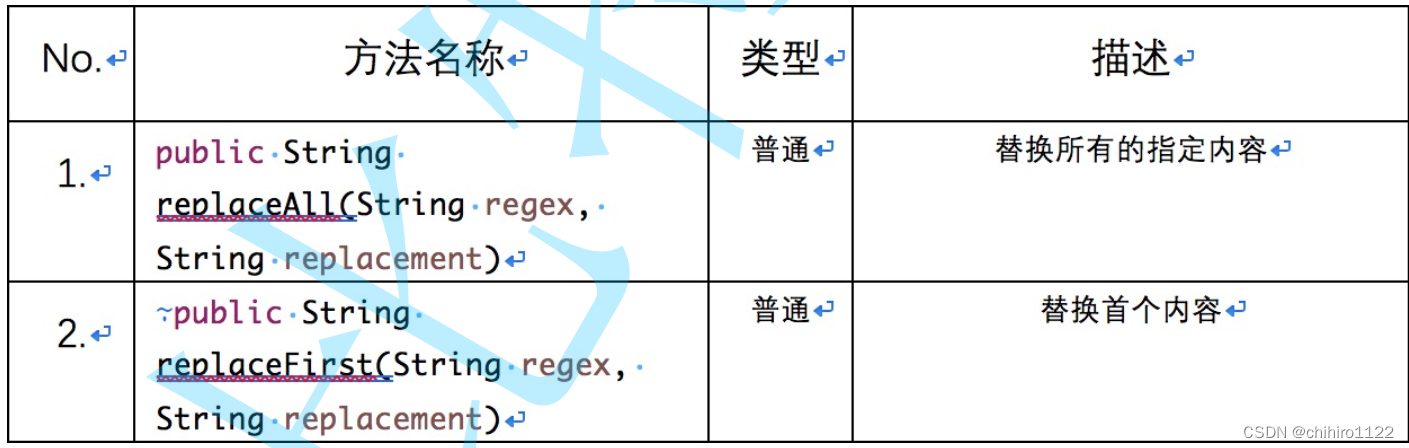
1)对于这个reapalceAll 方法其实我们查看文档,里面有多个reaplace方法:

其中我们发现有一个reaplace方法中传入的参数有一个 CharSequence 类型的数据,这个类型其实是String类中实现的一个接口:
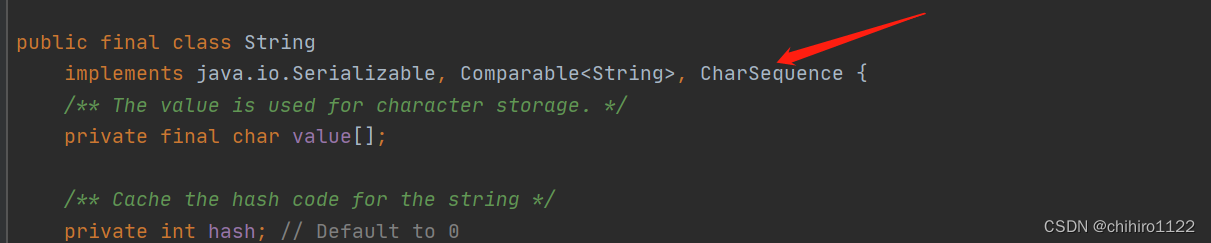
那么既然是String的一个接口,那么我们在传入参数的时候也可以传入String类型的,此时发生了向上转型。
现在我们来使用一下reaplace()方法:
public static void main(String[] args) {
String str = "ababacadae";
String str2 = str.replace('a','p');
System.out.println(str2);//pbpbpcpdpe
}我们上述传入的方法,是吧str中的 ' a ' 字符 修改为 ' p ' 字符了,而且是用一个新的String的类型的引用类型来接收这个reaplace方法的返回值,说明这个reaplace方法不是直接在str字符串上进行修改,而且创建了新的字符串。
我们上述传入的是字符,使用的第一个reaplace方法:
![]()
我们上述说过,reaplace重载的另一个方法可以传入字符串,发生向上转型,那么我们在传入字符串:
public static void main(String[] args) {
String str = "ababacadae";
String str3 = str.replace("ab","cd");
System.out.println(str3);//cdcdacadae
}我们发现此时也修改成功了。
那么,reaplaceAll也是传入的是String类型的参数,那么其实这两种方式实现的效果都是一样的:
public static void main(String[] args) {
String str = "ababacadae";
String str3 = str.replaceAll("ab","cd");
System.out.println(str3);//cdcdacadae
}2)替换首个出现的关键字符:
public static void main(String[] args) {
String str = "ababacadae";
String str3 = str.replaceFirst("ab","cd");
System.out.println(str3);//cdabacadae
}我们发现,只有第一个"ab" 被替换成了 “cd” ,其余的都没有替换。
字符串截取
从一个完整的字符串之中截取出部分内容。可用方法如下:

1)那么 substring 方法有两种:

一个参数的就是从传入参数的下标开始截取到末尾,两个参数的话就是一个左闭右开区间:
public static void main(String[] args) {
String str = "abcdefghijk";
String ret1 = str.substring(1);
String ret2 = str.substring(1,4); // [1,4)
System.out.println(ret1);//bcdefghijk
System.out.println(ret2);//bcd
}字符串查找
在一个完整的字符串中,判断指定内容是否存在,对于查找有一下几种方法:
1)传入的参数是 CharSequence 类型的,String类中实现了 这个 CharSequece 接口,也就意味,这里可以传入String类型的参数,发生向上转型。
找到了返回true,找不到返回false。

public static void main(String[] args) {
String str = "abcdabcdabcde";
boolean flg = str.contains("ab");
System.out.println(flg);//true
boolean flg2 = str.contains("yuyu");
System.out.println(flg2);//false
}2)indexOf 方法,传入的是一个String类型的参数,返回的是一个int类型的值,从头开始找,如果查到了就返回这个位置的开始索引,只查找第一个指定的子字符串,如果找不到就返回-1:
public static void main(String[] args) {
String str = "qwedabcdrfgde";
int index = str.indexOf("abc");
System.out.println(index);//4
int index1 = str.indexOf("hhh");
System.out.println(index1);//-1
}我们发现上述,返回了 4 ,4 就是 “qwedabcdrgde” 这个字符串中,下标为 4 的位置,就是 abc这个子字符串来字符串中的其实位置。
3)上述的 indexOf 方法 只传入了 一个String类型的参数,这个方法还可以多传入一个索引值,表示的是,从这个索引的位置开始查找,返回值还是一样的:
public static void main(String[] args) {
String str = "qwedabcdrfgde";
int index2 = str.indexOf("abc",3);
System.out.println(index2);//4
int index3 = str.indexOf("abc",7);
System.out.println(index3);//-1
}我们发现我们在 3 位置开始寻找就可以找到, 而在 7 这个位置之后就找不到了。
4)lastIndexOf()方法,是从后往前查找子字符串内容,也就是说,如果在字符串中有两个相同的字符串,那么他返回的是最后一个子字符串的索引,我们对比之前的indexOf()方法来看:
public static void main(String[] args) {
String str = "aaabcccabcbb";
int index2 = str.indexOf("abc");
System.out.println(index2);//2
int index = str.lastIndexOf("abc");
System.out.println(index);//7
}发现其中有两个 “abc” 子字符串,而两个函数返回的下标都不一样。
5)同样,lastIndexOf() 方法也可以指定位置,从后往前找,和之前的indexOf()一样,在后面多传一个参数表示,从这个索引位置开始从后往前找:
public static void main(String[] args) {
String str = "aaabcccabcbb";
int index = str.lastIndexOf("abc");
System.out.println(index);//7
int index1 = str.lastIndexOf("abc", 2);
System.out.println(index1);//2
int index2 = str.lastIndexOf("abc", 5);
System.out.println(index1);//2
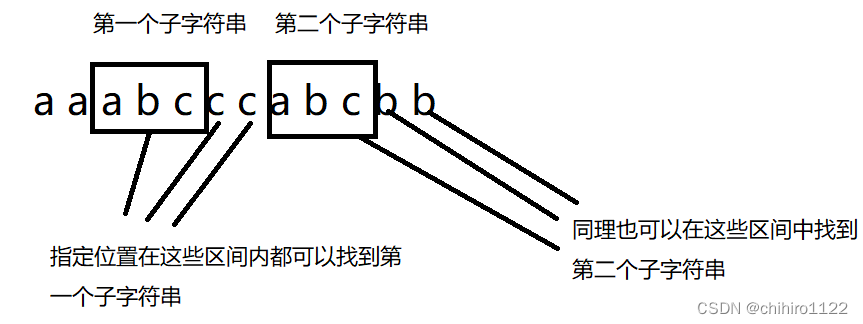
}根据上述例子我们发现,第一个 “abc” 子字符串的位置是在字符串的 2 下标位置开始的,但是上述我们指定位置,无论是从 2 下标还是 5 下标,结果都是 2 ,也就说都返回的是第一个 “abc” 字符串的开始索引,那么这个函数是怎么来寻找的呢?
int index3 = str.lastIndexOf("abc",1);
System.out.println(index3);//-1因为第一个 “abc” 子字符串的位置 是 [2,4],那么我们从 1 下标位置开始从后往前找,发现就找不到了,也就说,这个方法是从 指定 索引 位置开始从后往前找的,但是如果这个指定的索引位置是在指定子字符串区间之内的,那么这个函数都可以找到这个子字符串,如下图所示:
6)startsWith()方法,判断一个字符串中是否以指定字符串开头:
public static void main(String[] args) {
String str = "ababababab";
String str2 = "bbbbbbb";
boolean flg = str.startsWith("ab");
boolean flg1 = str2.startsWith("ab");
System.out.println(flg);//true
System.out.println(flg1);//fasle
}7)startsWith()方法的重载,多了一个偏移量,所谓偏移量就是,字符串中字符的位置相对于其实位置差多少距离:
String str1 = "aabbccddeeff";
boolean flg2 = str1.startsWith("aa",2);
System.out.println(flg2);//false如这个例子,偏移量为2 的位置就在 字符串中下标为 2的位置,那么下标为2位置开始,开头的不是aa,而是bb,此时我们把指定子字符串改为 bb 就返回的是true:
String str1 = "aabbccddeeff";
boolean flg2 = str1.startsWith("bb",2);//false
System.out.println(flg2);//true8)endsWith()方法,判断字符串是不是以指定字符串进行结尾的:
public static void main(String[] args) {
String str = "aabbccddeeff";
boolean flg1 = str.endsWith("ff");
boolean flg2 = str.endsWith("aa");
System.out.println(flg1);//true
System.out.println(flg2);//false
}我们查看文档,发现endsWith() 方法没有 偏移量的重载方法,只有这一种,只能判断字符串的末尾是否是指定子字符串。
字符串的拆分
可以将一个完整的字符串按照指定的分隔符划分为若干个子字符串。
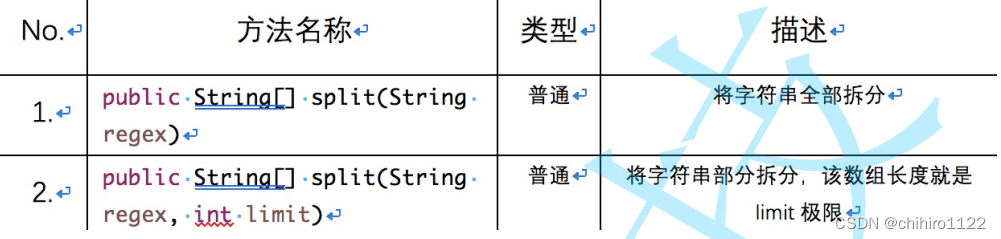
1)使用 split()方法,将字符串,以指定的子字符串来进行拆分,他的返回值是一个字符串类型的数组,那么我们需要用一个字符串类型的数组来接收这个方法的返回值:
public static void main(String[] args) {
String str = "aa bb cc dd ee ff";
String[] val = str.split(" ");
System.out.println(Arrays.toString(val));//[aa, bb, cc, dd, ee, ff]
}我们打印这个数组中的内容,发现字符串已经被以 空格 进行拆分到数组中去了。
当我们上面字符串都不给,那么split()方法会把全部字符给拆分:
String str1 = "198.22.33.1";
String[] val2 = str1.split("");
System.out.println(Arrays.toString(val2));//[1, 9, 8, ., 2, 2, ., 3, 3, ., 1]如果给的子字符串在字符串中没有的话,那么将不会拆分,直接返回这个字符串:
String str1 = "198.22.33.1";
String[] val2 = str1.split(" ");
System.out.println(Arrays.toString(val2));//[198.22.33.1]但是我们使用split()方法的时候需要注意的是:
String str1 = "198.22.33.1";
String[] val2 = str1.split(".");
System.out.println(Arrays.toString(val2));//[]我们发现,我们想以 " . " 这个字符来进行分割,但是结果没有打印任何字符,说明这个字符串中是空的。
为什么此处的 “ . ” 不能进行分割呢?我们查看源代码:

发现,上述这些字符,都在后面拼接了一个 " \\ ",java中有些特殊的字符,那么这些字符是不能识别的,在c中我们是用一个 " \ " 来进行识别,这里的这个 " \ " 叫做转义字符,比如要识别一个 " . " 那么就要在 这个 " . " 这个字符之前加上一个" \ ":
\.但是在Java中我们使用转义字符去转义的时候,他又不认识 这里的 " \ " 是什么意思了,那么我们就再加一个 " \ " 去识别这个 " \ " 。
如果我们要想使用这些字符来进行分割的话,就要在这些字符之前加上 " \\ " :
String str1 = "198.22.33.1";
String[] val2 = str1.split("\\.");
System.out.println(Arrays.toString(val2));//[198, 22, 33, 1]此时的字符串就以 " . " 进行分割了。
再看下面这个例子:

我们想写一个这样的字符串,按照上述的写法是不行的,我们发现上述在Idea中颜色已经变化,说明此处22 3 1 都已经被转义了。
那么我们要想实现上述的字符串,要在 " \ " 之前再加一个" \ " 来进行转义:
![]()
那么我们要拿 " / " 来进行分割,那么spilt中的参数应该这样写:
String str3 = "198\\22\\33\\1";
String[] val1 = str3.split("\\\\");
System.out.println(Arrays.toString(val1));//[198, 22, 33, 1]也就说,我们现在不能拿 " \ " 来进行分割,要拿 " \\ " 来进行分割,那么我们要想识别这个 " \\ " ,就要在之前再加 " \\ " 来识别这个 " \\ "。
那么我们再来举一个例子,假设我们现在像用 “ - ” 和 “ # ” 两个字符来分割 " java-split#bit " 这个字符串,那么如果我们直接传入 ”-#“ 是不行的:
public static void main(String[] args) {
String str = "java-split#bit";
String[] val = str.split("-#");
System.out.println(Arrays.toString(val));//[java-split#bit]
}我们发现此处打印的val数组还是原来的字符串内容,那么如果我们想要一下子用两个字符串来分割一个字符串,那么我们在传参的时候要用 " | " 来把两个需要字符隔开:
public static void main(String[] args) {
String str = "java-split#bit";
String[] val = str.split("|-|#");
System.out.println(Arrays.toString(val));//[j, a, v, a, -, s, p, l, i, t, #, b, i, t]
}但是我们发现还是失败了,split 方法把全部的字符都分割了。
我们在使用 " | " 来一次分割使用多个字符来分割的时候,要在字符串开头加一个 空格 :
public static void main(String[] args) {
String str = "java-split#bit";
String[] val = str.split(" |-|#");
System.out.println(Arrays.toString(val));//[java, split, bit]
}虽然可以一次 使用多个 字符来进行一次分割,但是我们一般不建议这样做,如果想用两个字符来进行分割,那么我们一般使用的方法是,分割两次。
多次分割:
String str = "name=zhangsan&age=18";
String[] val = str.split("&");对于这例子,我们先用 “ & ” 进行分割,分割为两个字符串,存储在val数组中,那么val数组中的0号下标就是 "name=zhangsan&age=18" 这个字符串, 1号下标就是 "age=18" 这个字符串。
这个时候,我们使用 foreach 来访问这个数组,然后对这个数组中的这两个字符串,以 “ = ” 字符来进行分割,然后在每一次分割之后,都在这一层for循环中,使用foreach打印分割出来的字符串:
for(String s1:val)
{
String[] str1 = s1.split("=");
for (String s2:str1)
{
System.out.println(s2);
}
}完整代码:
public static void main(String[] args) {
String str = "name=zhangsan&age=18";
String[] val = str.split("&");
//此时 val 数组中是这样存储的:
// [name=zhangsan] [age=18]
//下标 0 1
for(String s1:val)
{
String[] str1 = s1.split("=");
for (String s2:str1)
{
System.out.println(s2);
}
}
//name
//zhangsan
//age
//18
}我们来做一个例子:
借用字符串库函数实现无冗余地接收两个字符串,然后把他们拼接起来,
示例:
输入:name age nihao
输出:nameagenihao 我们直接使用 split()方法,用空格进行分割,存储到val数组中,然后用foreach把val数组中每一个字符串拼接起来就行了。
public static String func(String str)
{
String[] val = str.split(" ");
String string1 = "";
for(String s1: val)
{
string1 += s1;
}
return string1;
}
public static void main(String[] args) {
System.out.println("请输入你要合并的字符串:");
Scanner scanner = new Scanner(System.in);
String string = scanner.nextLine();
String ret = func(string);
System.out.println(ret);
}那么上述只输入了一行数据,那么当我们要输入多行数据的时候,那么上述代码可以这样写:
public static void main(String[] args) {
System.out.println("请输入你要合并的字符串:");
Scanner scanner = new Scanner(System.in);
while(scanner.hasNext())
{
String string = scanner.nextLine();
String ret = func(string);
System.out.println(ret);
}
}我们这样写就可以一次写入多行数据了,按住 ctrl + D就可以停止循环了。
其他操作方法

1)两边的空格都去掉,中间不管有几个区间的空格,都保留:
public static void main(String[] args) {
String str = " abc def ghijk ";
String ret = str.trim();
System.out.println(ret);//abc def ghijk
}2)toUpperCase()将字符串都转变为大写的,此方法相当toUpperCase(Locale.getDefault()) 。这个函数会把修改之后的字符串以一个返回值返回,返回值是String类型的:
public static void main(String[] args) {
String str = "abcdef";
String str1 = str.toUpperCase();
System.out.println(str1);//ABCDEF
}3)toLowerCase()将字符串都转变为小写,也是把修改之后的字符串以一个返回值返回,返回值是String类型的:
public static void main(String[] args) {
String str = "ABCDEF";
String str1 = str.toLowerCase();
System.out.println(str1);//abcdef
}5)字符串的连接,相当于字符串的拼接,不会入字符串常量池,也是把连接的字符串以String类型返回值的形式返回:
String str2 = "abc";
String str3 = "def";
String str4 = str2.concat(str3);
System.out.println(str4);//abcdef不过这个方法现在很少用到了
6)求字符串的长度,把长度通过返回值形式返回:
public static void main(String[] args) {
String str = "abcdef";
int lengths = str.length();
System.out.println(lengths);//6
}那么此处求字符串长度的length方法和求数组长度的length方法有什么区别呢?
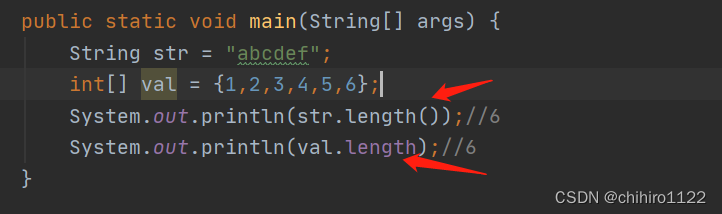
我们发现,两个length方法在调用的时候,字符串的length后面有一个 () ,而数组的length没有使用()。
那么我们发现,两行代码在idea中,数组的length是紫色的,而字符串的length是无色的,在idea中紫色的一般代表的是属性,那么也就说,数组中的length是一个属性,而字符串中的length是一个方法。
7)isEmpty()判断一个字符串是否是空的,为空返回true,不是空返回false,此处的空不是null,而是长度为0,的字符串:
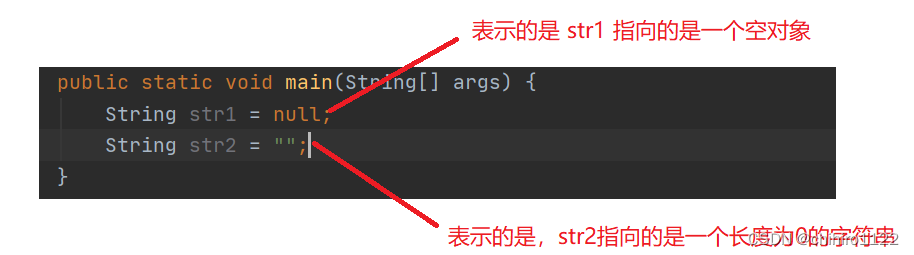
public static void main(String[] args) {
String str1 = null;
boolean bool1 = str1.isEmpty();
} 
我们发现此时报错了。
public static void main(String[] args) {
String str2 = "";
String str3 = "abcdef";
boolean bool2 = str2.isEmpty();
System.out.println(bool2);//true
boolean bool3 = str3.isEmpty();
System.out.println(bool3);//false
}例子:
字符串的逆序,假设输入 “abcd” ,那么输出 “dcba” 。
那么我们使用两个指针,一个指向字符串的头(begin),一个指向字符串的尾(end),然后首先交换位置两个指针指向的字符,然后begin++,end--。知道两个指针相遇,就代表这个字符串已经交换完毕了。
我们可以用split进行分割,然后用一个字符串把数组中的内容进行拼接:
public static String reverse(String str,int begin ,int end)
{
String[] val = str.split("");
String tmp = "";
while(begin < end)
{
tmp = val[begin];
val[begin] = val[end];
val[end] = tmp;
begin++;
end--;
}
String string1 = "";
for(String s1:val)
{
string1 += s1;
}
return string1;
}
public static void main(String[] args) {
String str = "abcdef";
String ret = reverse(str,0,str.length() - 1);
System.out.println(ret);//fedcba
}也可以把这个字符串转化为字符数组,然后进行操作:
public static String reverse2(String str,int begin ,int end) {
char[] value = str.toCharArray();
while(begin < end)
{
char tmp = value[begin];
value[begin] = value[end];
value[end] = tmp;
begin++;
end--;
}
return String.copyValueOf(value);
}
public static void main(String[] args) {
String str = "abcdef";
String ret = reverse2(str,0,str.length() - 1);
System.out.println(ret);//fedcba
}例题二:
给定一个字符数组char和一个整数size,请把这个大小为size的左半区间,整体挪到右半区间,右半区间整体挪到左半区间。
示例:
输入:
3
abcdefg输出:
defgabc思想:先将前size个字符逆置,然后将后半部分逆置,最后在将整个字符串逆置。
逆置函数之前我们已经写过了,那么我们直接调用这个函数就行了:
public static String reverse2(String str,int begin ,int end) {
char[] value = str.toCharArray();
while(begin < end)
{
char tmp = value[begin];
value[begin] = value[end];
value[end] = tmp;
begin++;
end--;
}
return String.copyValueOf(value);
}
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
System.out.println("请输入size:");
int size = scanner.nextInt();
System.out.println("请输入字符串:");
String str = scanner.next();
if(str == null || size <= 0 || size >= str.length())
{
System.out.println("输入格式错误");
}
System.out.println(str);//abcdefg
String str1 = reverse2(str,0,size - 1);
String str2 = reverse2(str1,size,str.length() - 1);
String str3 = reverse2(str2,0,str.length() - 1);
System.out.println(str3);//defgabc
}















 1973
1973











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











