









推荐系统整体各方向
排序模型: FM -> DeepWide -> DCN -> LHUC -> DIN -> SIM
序列建模: GWEN->DIN->DIEN->DSIN->MIMN->SIM->。从无用户行为输入,到提取多峰兴趣,再到短期行为特征,最后长短期兴趣提取。
损失函数: pointwise -> pairwise -> listwise
召回: 离散空间 & 语义空间
多目标: MMOE -> ESMM -> PLE
去偏: 偏差分类 -> 去偏方法
多样化:MMR 多样性算法 -> MMR 多样性算法
评估指标:AUC -> GAUC
冷启动: Rule based、Content based、基于知识图谱的推荐、迁移学习、聚类
E&E:
推荐系统模型演进
Factorized Machine(FM)
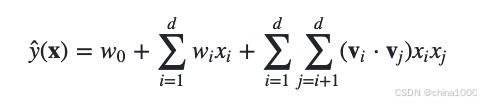
Factorized Machine(FFM)
在FM中的特征 与其他特征的交叉时,特征 使用的都是同一个隐向量 。而FFM将特征按照事先的规则分为多个场(Field),特征属于某个特定的场F。
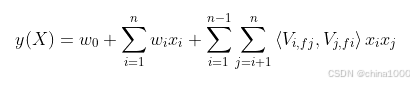
空间复杂度:如果隐向量的长度为 k,那么FFM的二次参数有 nfk 个,远多于FM模型的 nk 个。
时间复杂度:FM复杂度是 O(kn),FFM 复杂度是 O(kn2)
各种网络结构
Deep&Wide
-
Wide部分:主要用于记忆。它通过线性模型的方式,直接学习历史数据中的高频模式和特征组合,具有较强的记忆能力。Wide部分通常使用FTRL优化器,适用于大规模稀疏特征12。
-
Deep部分:主要用于泛化。它通过深度神经网络学习低维稠密向量,能够发现新的特征组合和模式,具有较强的泛化能力。Deep部分通常使用AdaGrad优化器12。
优化器选择
-
Wide部分使用FTRL优化器:FTRL优化器适用于大规模稀疏特征,并且带有L1正则化,有助于模型的稀疏性和特征选择12。
-
Deep部分使用AdaGrad优化器:AdaGrad优化器适用于处理连续特征和稠密特征,能够有效地进行参数更新。
DeepFM
对比Deep&wide,wide侧使用 FM。
DCN
在DCN中针对Wide&Deep模型的Wide侧提出了Cross网络,通过Cross网络学习到更多的交叉特征,提升整个模型的特征表达能力。
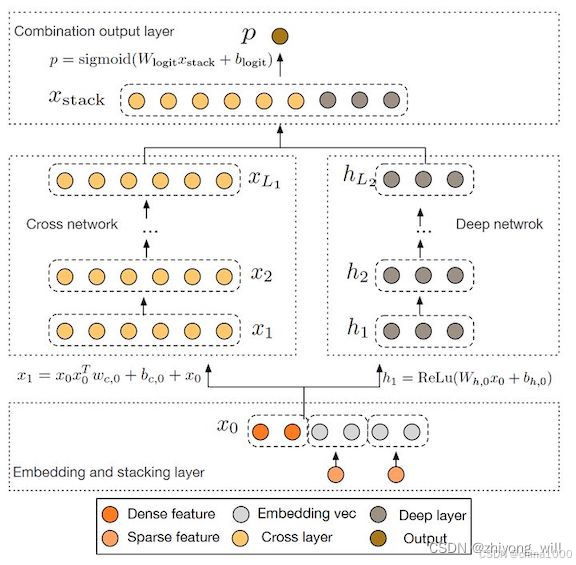
LHUC网络结构(PPNet)
工业界有效,但只用于精排
LHUC来自于语音识别
快手将LHUC用于推荐精排,称为PPNet
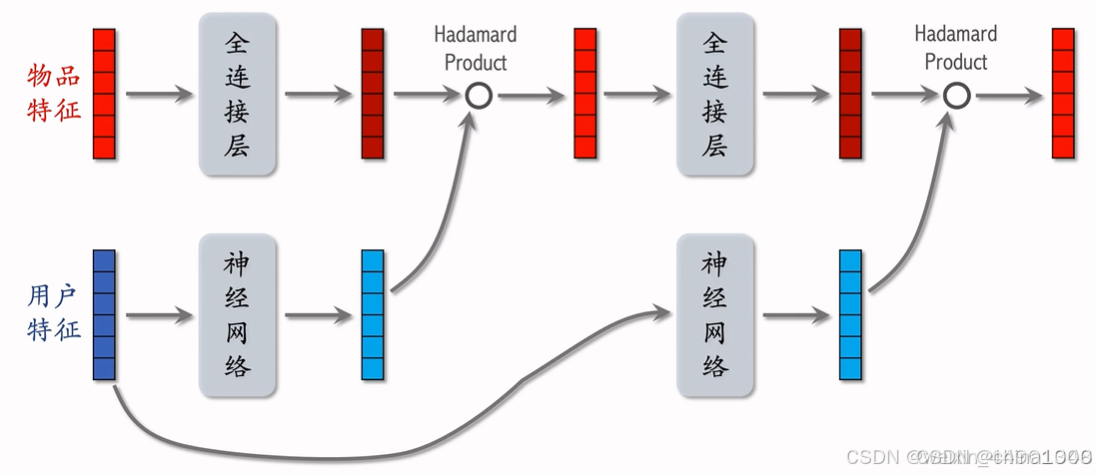
SENet & Bilinear 交叉
用户行为序列
用户行为序列:用户最近交互过的n个物品,LastN召回的双塔,粗排的三塔,精排模型都可以用lastN对指标有比较大的收益
Embedding&MLP(GwEN)
Embedding&MLP又称 GwEN(group-wise embedding network),在DIN中作为基线模型。采用Embedding&MLP范式,将大规模稀疏id类特征表示为低维稠密向量,拼接为emb层后输入DNN
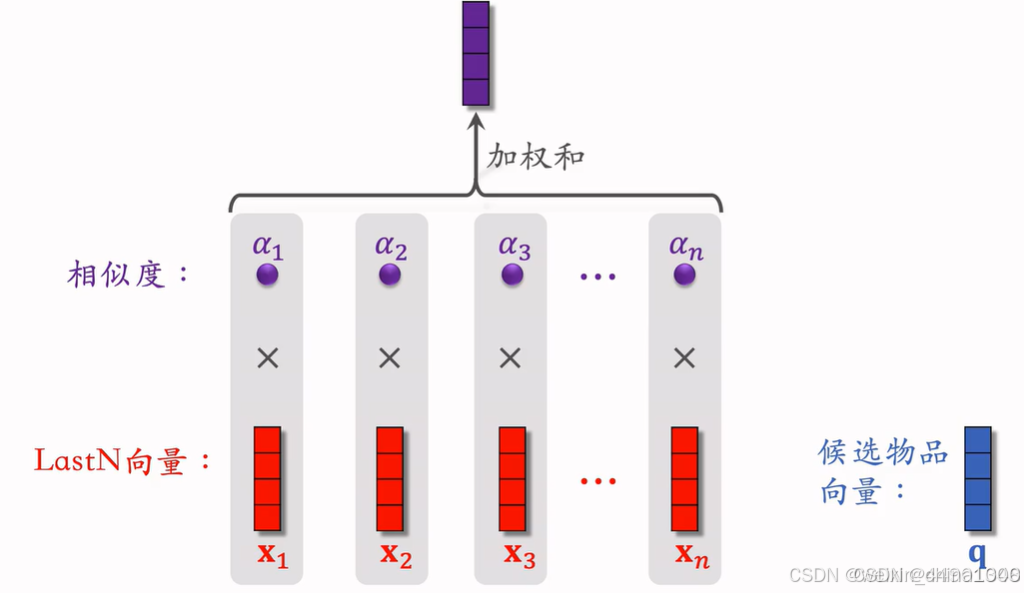
DIN模型(注意力机制)
DIN流程:
- 对于某候选物品。计算它和LastN物品相似度
- 相似度为权重,求LastN物品向量加权和,得到一个向量
- 向量作为一种用户特征,输入排序模型
- 本质是注意力机制
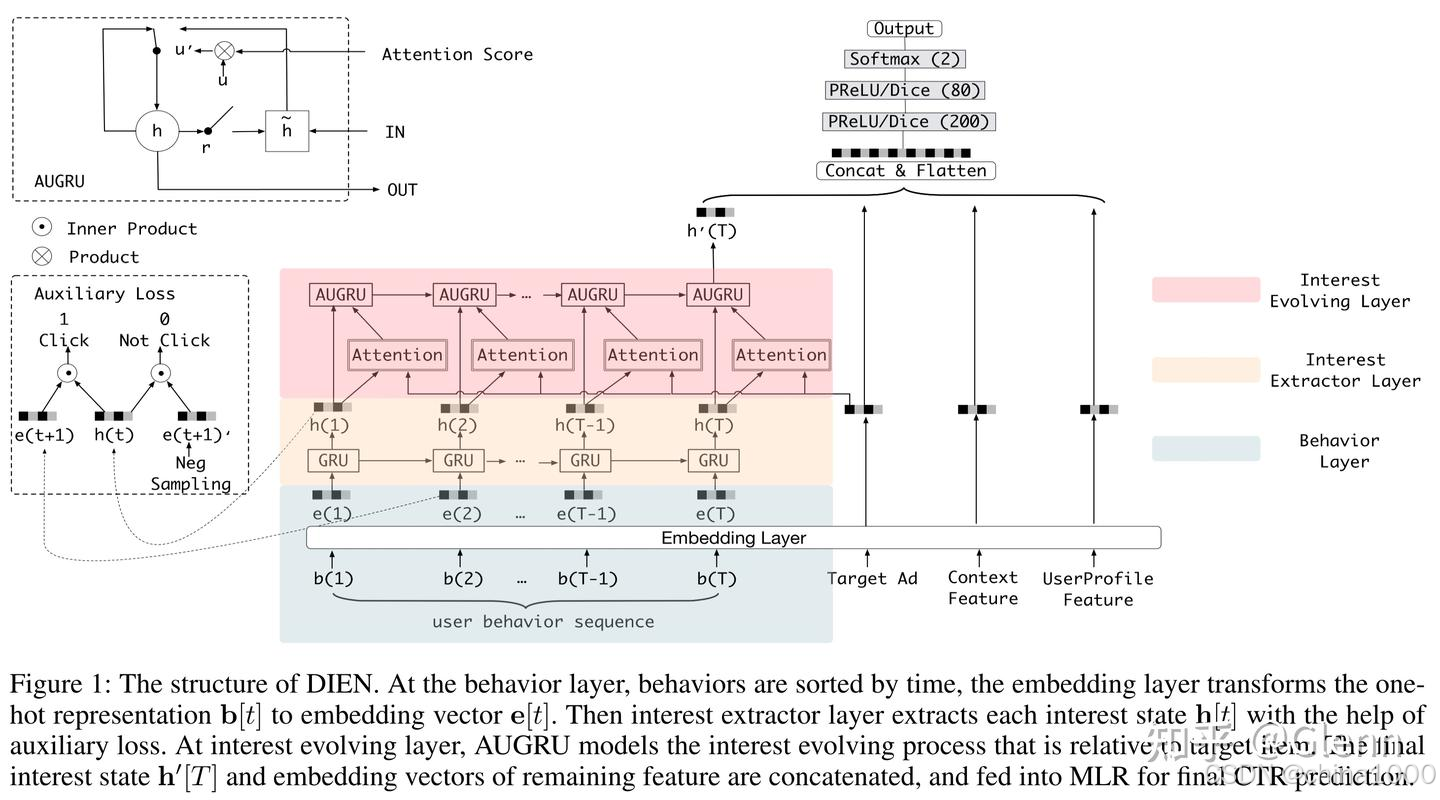
DIEN模型
针对DIN没有考虑行为先后关系、兴趣变化过程的问题,盖坤团队继续优化模型结构,引入GRU提取行为序列中的信息,并结合DIN中目标AD与行为节点计算权重的模式(Attention),提出AUGRU进一步挖掘兴趣变化中的信息。提出了兴趣提取层 和 兴趣演进层。
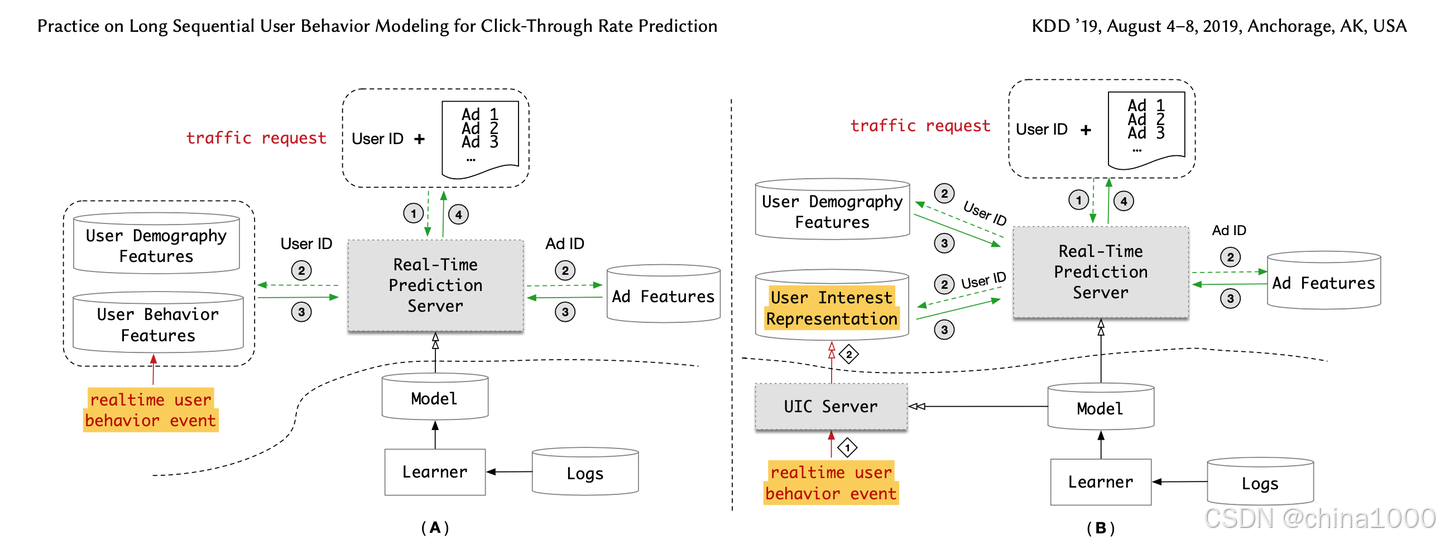
MIMN
模型效果和用户行为序列长度正相关。通过工程和算法的联合优化,解决超长用户行为序列对线上服务的计算和存储压力
DSIN
DIEN直接将14天的行为无差别的拼接,没有考虑session的概念,但是用户的行为,在不同的Session中有明显差异。针对这一现象,作者将行为划分为多个session,并提出兴趣抽取、兴趣交互(序列)、兴趣激活层3部分
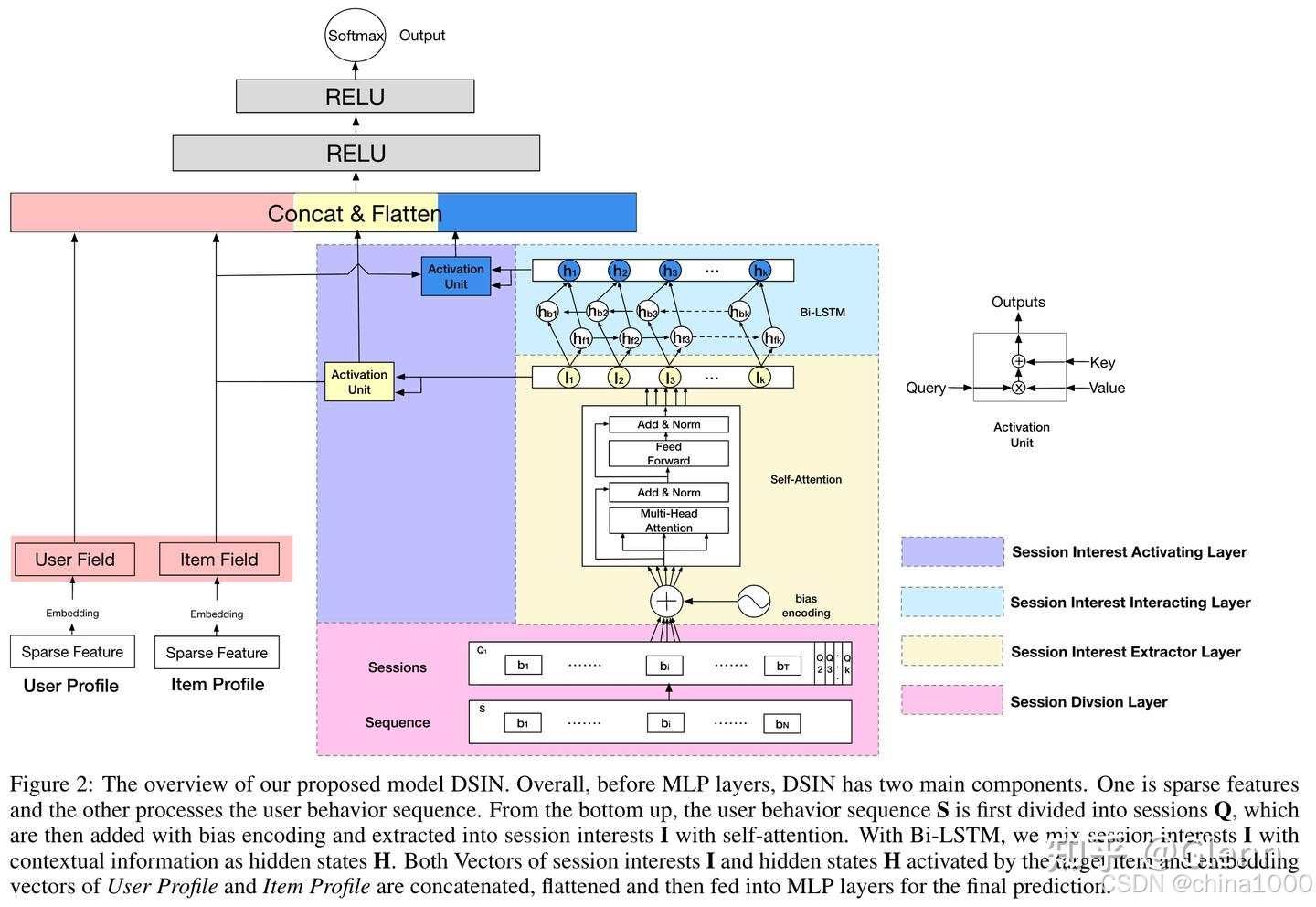
BST
创新点:将Transformer成功引入推荐系统。DIN模型只考虑历史行为与候选物品的关系,而BST由于使用Transformer,不仅可以学习到历史行为与候选物品的关系,而且能学习到历史行为物品之间的关系
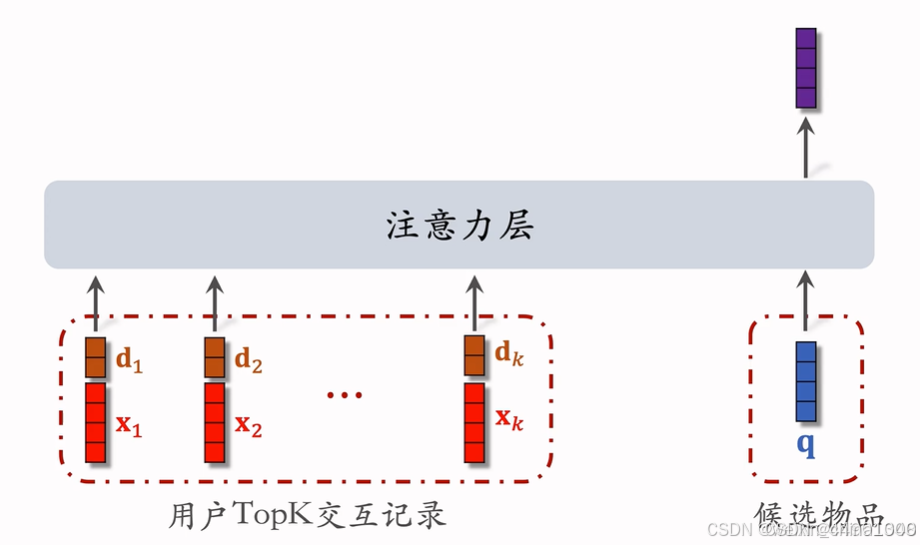
SIM模型(长序列模型)
DIN模型缺点:
注意力层计算量正比与n(用户行为序列长度)
只能记录最近几百个物品
关注短期兴趣,遗忘长期兴趣
改进DIN: 快速排除掉与候选物品无关得到LastN物品
SIM模型优点:
保留用户长期行为记录,n大小为几千
对于每个候选物品,在用户LastN记录中快速查找,得到k个物品
LastN变为TopK,计算量减小
推荐系统召回方法
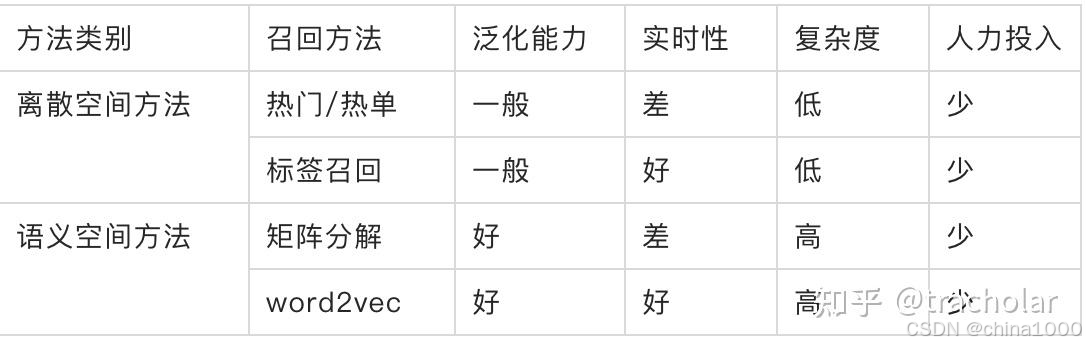
离散空间
热门、热单、LBS、user&poi 召回
语义空间
DSSM双塔模型
缺点:上文提到的DSSM采用词袋模型(BOW),因此丧失了语序信息和上下文信息。另一方面,DSSM采用弱监督、端到端的模型,预测结果不可控。
Item-to-Item
推荐系统多目标
用户行为路径,业务多目标。
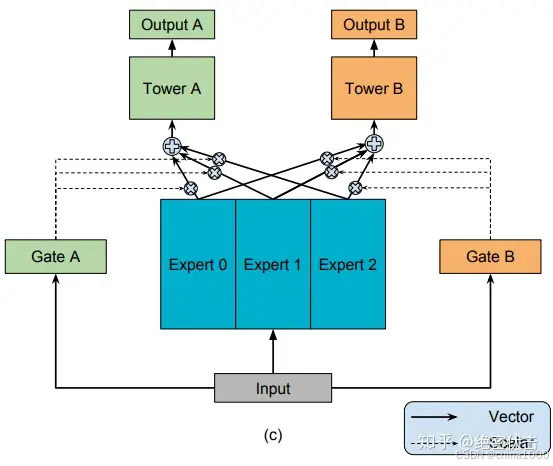
MMOE
MMOE(Multi-gate Mixture-of-Experts)是在MOE的基础上,使用了多个门控网络,
个任就对应 k个门控网络。
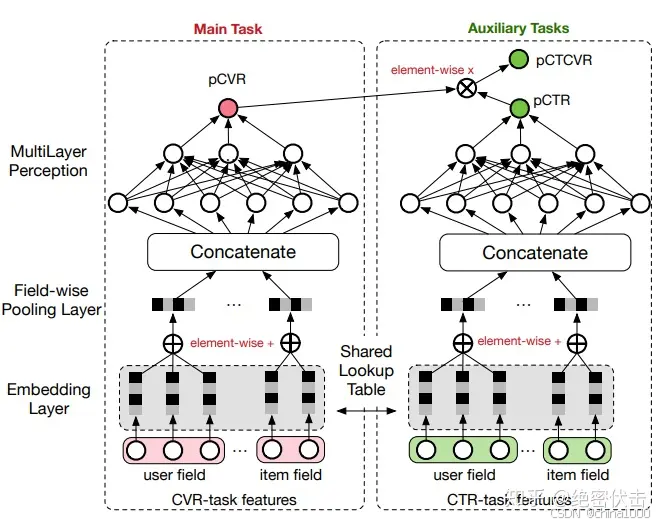
ESMM
ESMM针对 CVR训练的下单数据较少,而点击数据较为丰富的原因。同时学习 pctcvr 和 pctr。
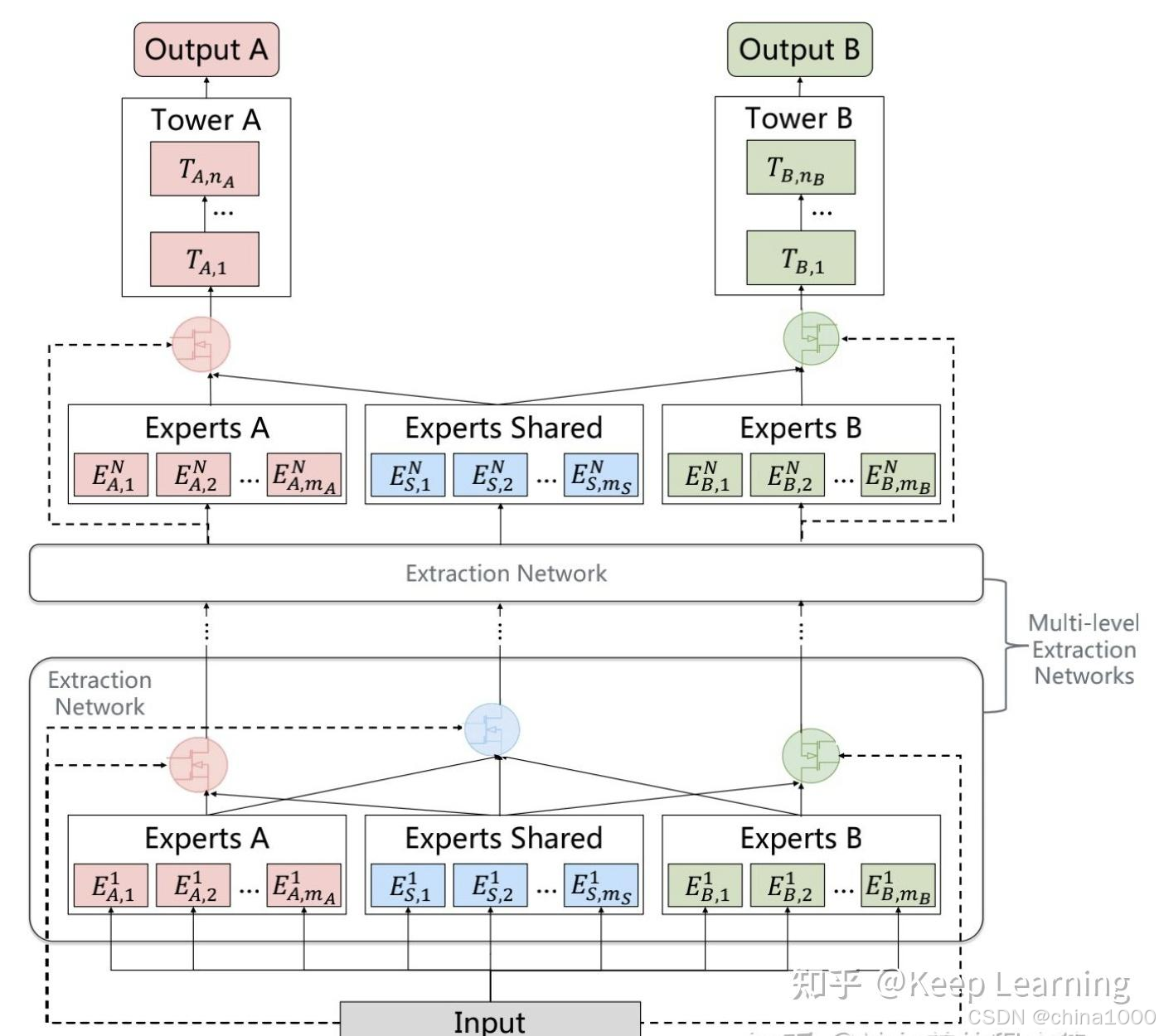
PLE
- MMOE中所有的Expert是被所有任务所共享的,这可能无法捕捉到任务之间更复杂的关系,从而给部分任务带来一定的噪声
- 不同的Expert之间没有交互,联合优化的效果有所折扣
PLE针对上面第一个问题,每个任务有独立的Expert,同时保留了共享的Expert
- Single-Task: 对每个任务单独模型训练
- Hard Parameter Sharing
- Asymmetric Sharing
- Cross-Stitch
- Sluice Network
- Customized Sharing
- MMOE
- ML-MMOE
- CGC
- PLE
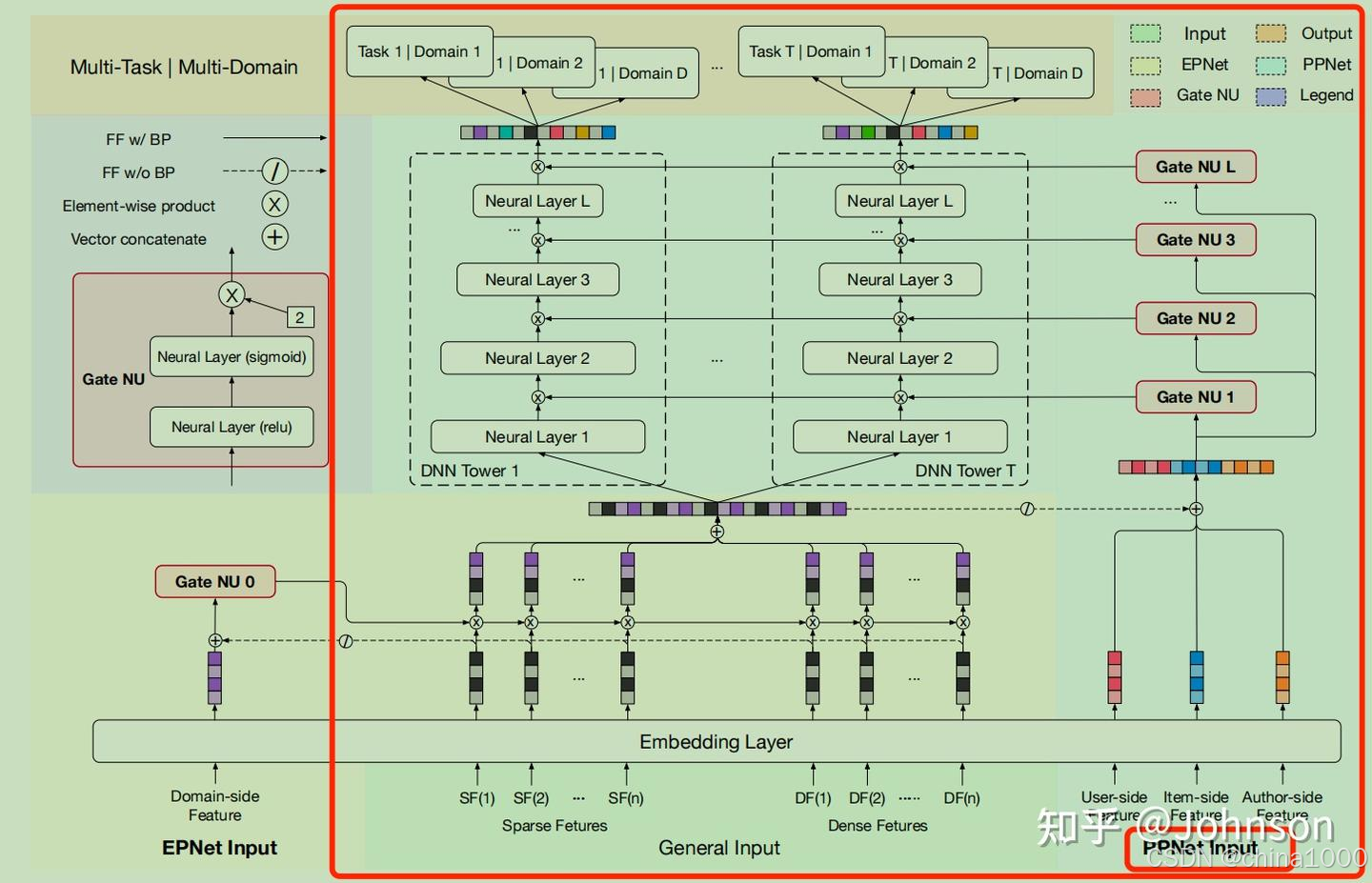
PPNet
PPNet全称Parameter Personalized Network,相较于PLE/MOE中Expert粗粒度Gate机制,PPNet通过Gate NU和DNN参数做叉乘,实现了更多更细粒度的隐式分布建模。
Expert机制中,粗粒度Expert数限定了建模的数据分布的数量;PPNet,将Gate从权重标量细化为多组参数权重向量,参与主网络建模,从而可以建模更多更细的数据分布。
推荐系统去偏
常见去偏方法有 样本调权、 模型(正则化、对抗学习、因果图、因果模型)等。
偏差分类
1. Selection Bias
2. Conformity Bias
3. Exposure Bias
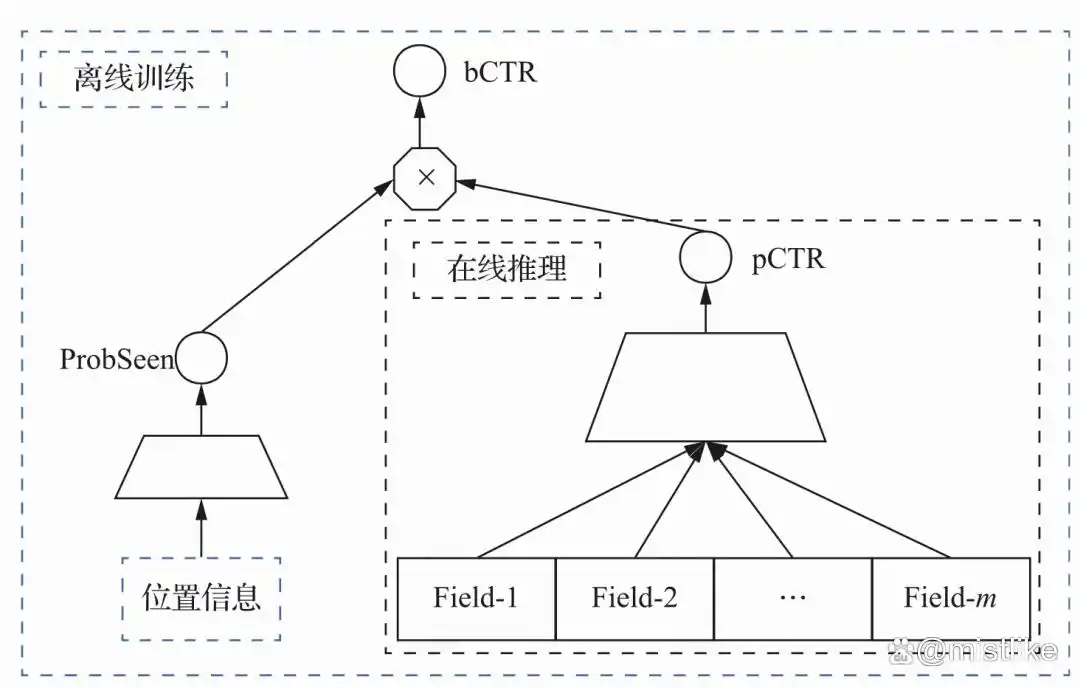
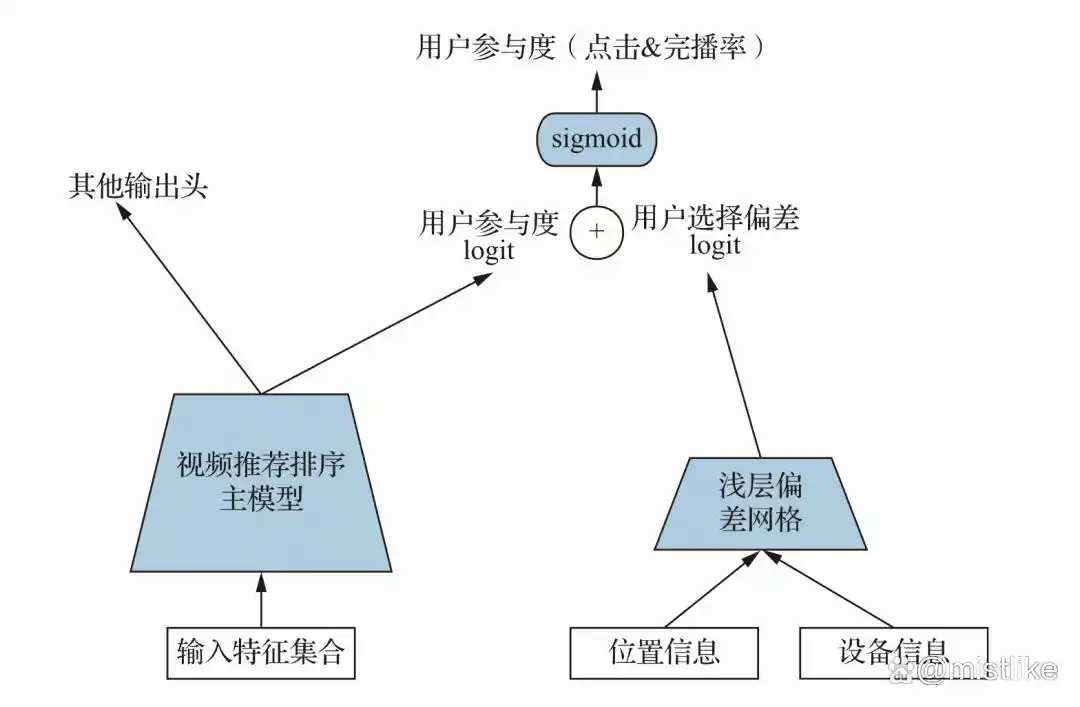
4. Position Bias
a. 把位置当做特征,预估时取0。
b. 建模商品被看到的概率。PAL 模型 华为发表在 RecSys2019
c. 建模位置和设备的浅层网络。
5. Popularity Bias
a. 正则化约束 在损失函数中添加物品流行度惩罚项:
b. 构建对抗网络分离用户偏好与流行度特征,生成去偏的隐向量
6. Unfairness
7. Feedback Loop Amplifies Biases
8. Inductive Bias
去偏方法
推荐系统多样化方法
MMR 多样性方法
多样性需求
- 精排给n个候选物品打分,融合之后的分数reward
- i,j物品之间相似度为sim(i, j)
- 从n个物品中选出k个,既有高精排分数,也有多样性
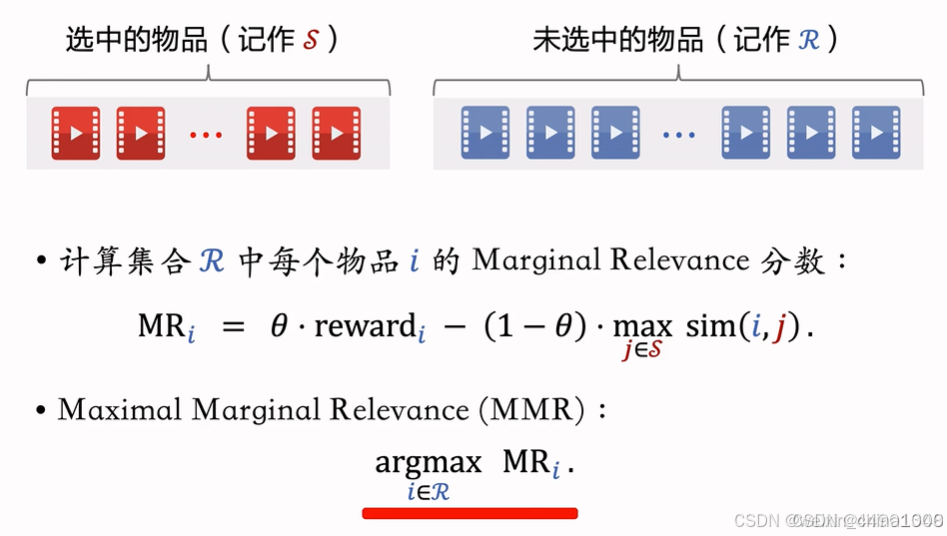
DPP 多样性算法
行列式点过程(DPP)是一种概率模型,最初用于描述粒子物理学中的某些现象,如费米子的分布。它通过行列式的数学构造来捕捉集合中元素之间的负相关性,即当两个元素非常相似时,它们同时出现在同一集合中的概率会降低。这种特性使得DPP非常适合应用于推荐系统中,以确保推荐结果既具有高度的相关性又不会过度集中于某一类内容。
这里,L A L_ALA是矩阵L LL中仅保留行和列对应于子集A AA部分后的子矩阵;I II是单位矩阵。该公式表明,如果A AA中包含过于相似的元素,则det ( L A ) \det(L_A)det(LA)将较小,从而减少这些元素共同出现的概率。
推荐系统评估指标
ROC曲线
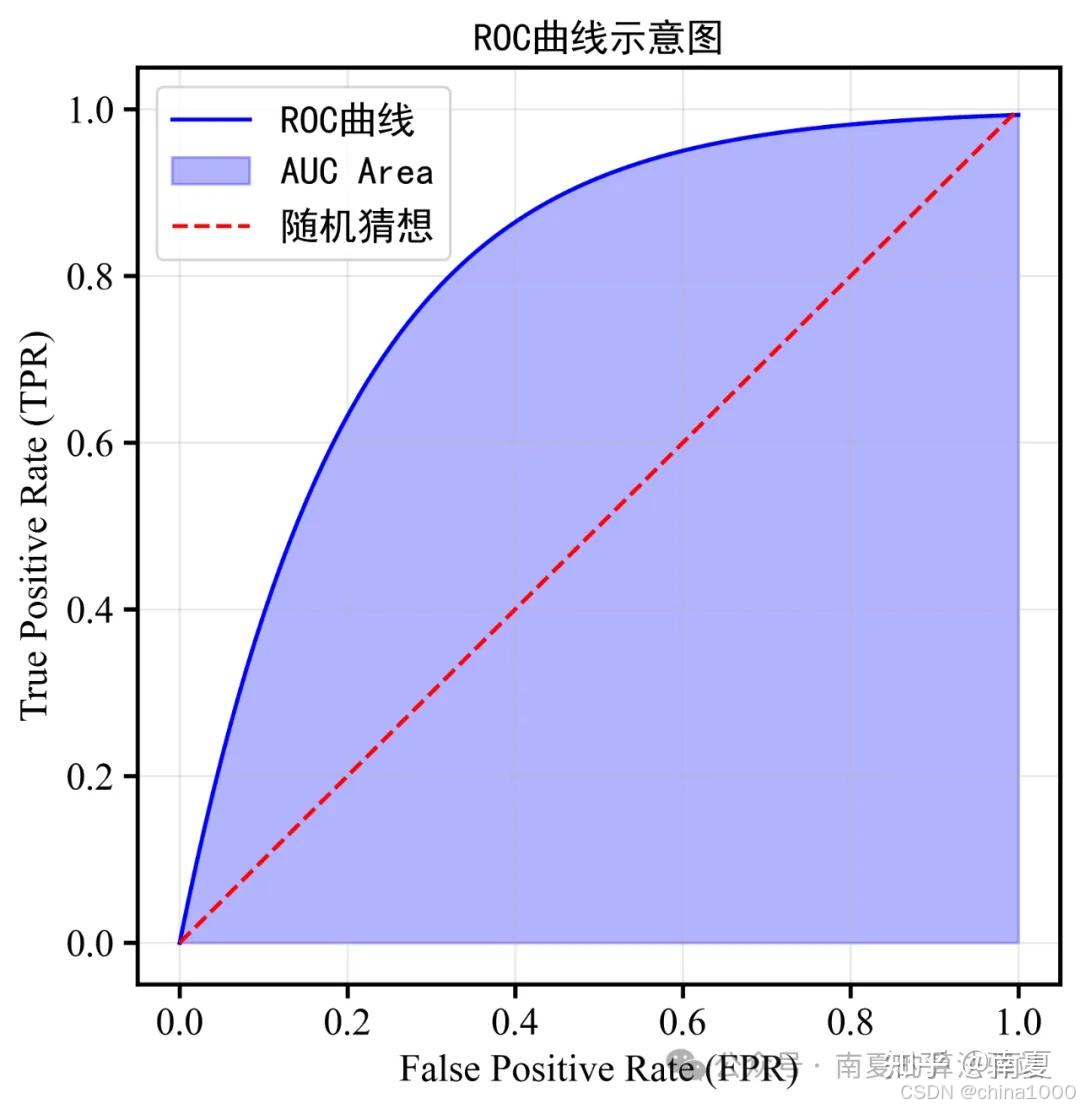
AUC
1. AUC衡量的是模型对整体样本的排序能力强弱。特别是在“类别不平衡”和“样本重要性差异”等场景下存在一些局限性。
2. AUC的计算没有考虑到正负样本重要性的差异,正样本可能具有更高的成本和风险
3.
GAUC
AUC衡量的是模型对整体样本的排序能力强弱。特别是在“类别不平衡”和“样本重要性差异”等场景下存在一些局限性。
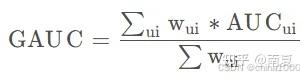
推荐系统冷启动
物品冷启动指的是如何对新发布的物品做分发 UGC物品冷启动(用户上传的物品)
新笔记冷启动
新笔记缺少和用户交互,导致推荐难度大、效果差
扶持新发布、低曝光的物品,能增强作者发布意愿
优化冷启的目标:精准推荐:克服冷启苦难,把新物品推荐给用户,不引起反感
激励发布:流量向低曝光物品倾斜,激励作者发布
挖掘高潜:通过初期小流量试探,找到高质量笔记,流量倾斜
冷启动优化点:优化全链路(包括召回和排序)
流量调控(流量怎么在新老物品中分配)
冷启动问题的常见解决方案
-
基于内容的推荐:
-
对于新用户:利用用户的注册信息(如年龄、性别、地理位置)或初始行为(如首次点击)进行推荐。
-
对于新物品:利用物品的属性信息(如类别、标签、描述文本)进行推荐。
-
-
混合推荐:
-
结合协同过滤和基于内容的方法,利用少量历史数据和内容信息进行推荐。
-
-
基于规则的推荐:
-
对于新用户,推荐热门物品或基于用户画像的默认推荐。
-
对于新物品,推荐给可能感兴趣的用户群体(如相似兴趣的用户)。
-
-
迁移学习:
-
利用其他领域的数据或模型,迁移到冷启动场景中。
-
简单的召回通道
冷启物品的特性
自带图片文字地点等
算法或人工标注的标签
没有用户点击、点赞等信息
没有笔记ID emb
冷启动难点
缺少用户交互,没学好笔记ID emb,导致双塔模型效果不好(召回、排序)
缺少用户交互,导致itemCF不适用
聚类召回
内容相似度模型
双塔模型(改造后)
ID emb的改进
改进方案1:新笔记使用 default emb物品塔做ID emb,让所有新笔记共享一个ID Default emb:共享ID对于的emb 向量到下次模型训练的时候,新笔记才有自己的ID emb向量
改进方案2:利用相似笔记的emb向量查找topk内容最相似的高曝笔记把k个笔记emb向量平均得到新笔记的emb
- 多个召回池,让新笔记用更多曝光机会
- 1小时新笔记、6小时新笔记、24小时新笔记、30天笔记
- 共享同一个双塔模型,多个召回池不增加训练代价
类目、关键词召回
- 感兴趣的类目:美食、科技数码、电影。。。
- 感兴趣的关键词:纽约、职场、搞笑。。。
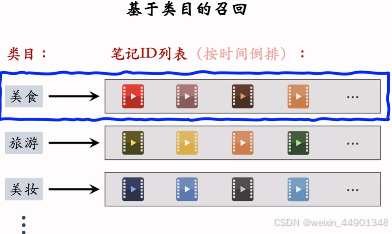
特殊人群
- 构造特殊内容池,用于特殊用户的召回
流量调控
推荐结果中强插新笔记,比较老的做法了最新笔记排序分数做提权(boost)在粗排、重排缓解,给新笔记提权
优点:容易实现。投入产出好
缺点:
曝光量对提权系数敏感很难精确控制曝光量,容易过渡曝光和不充分曝光通过提权,对新笔记做保量保量:不论笔记质量,保证24小时一定曝光
提权
降权
动态提权保留
参考文档:
2. 推荐系统(8)—— 多目标优化应用总结_1 - 深度机器学习 - 博客园
3. https://www.zhihu.com/question/425243050/answer/2439880386
4. https://zhuanlan.zhihu.com/p/660466655
6. https://zhuanlan.zhihu.com/p/493252610
7. 推荐系统简介之用户行为序列建模 https://zhuanlan.zhihu.com/p/667646402
8. 推荐系统技术演进趋势:从召回到排序再到重排
https://zhuanlan.zhihu.com/p/100019681
9. 推荐系统偏差专题
https://zhuanlan.zhihu.com/p/613111042
10. 再度梳理偏差问题 & 推荐系统去偏最新研究进展
https://zhuanlan.zhihu.com/p/444776856
11. 改进推荐系统的一些想法(新业务的推荐算法 新手保护期)

















 1472
1472

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









