






交叉特征
Factorized Machine (FM)
线性模型

只用到特征加权和,没有用到特征交叉
二阶交叉特征

d很大的时候模型参数太多,也容易overfitting
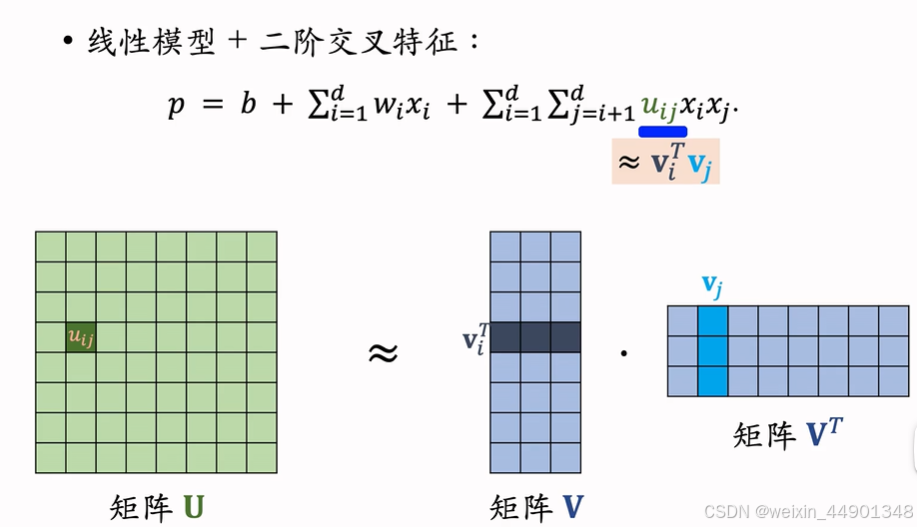
用矩阵V和VT的点乘代替Uij 矩阵,减少参数数量,变为 d*k (V矩阵大小,k超参)
Factorized Machine总结
- FM是线性模型的替代物,线性回归、逻辑回归都可以用FM
- FM使用二阶交叉特征,表达能力比线性更强
- 矩阵自相乘代替二阶交叉权重数量,从O(dd) 将为O(dk)
- 目前推荐系统中不太常用
深度交叉网络(DCN)
交叉层(Cross Layer)
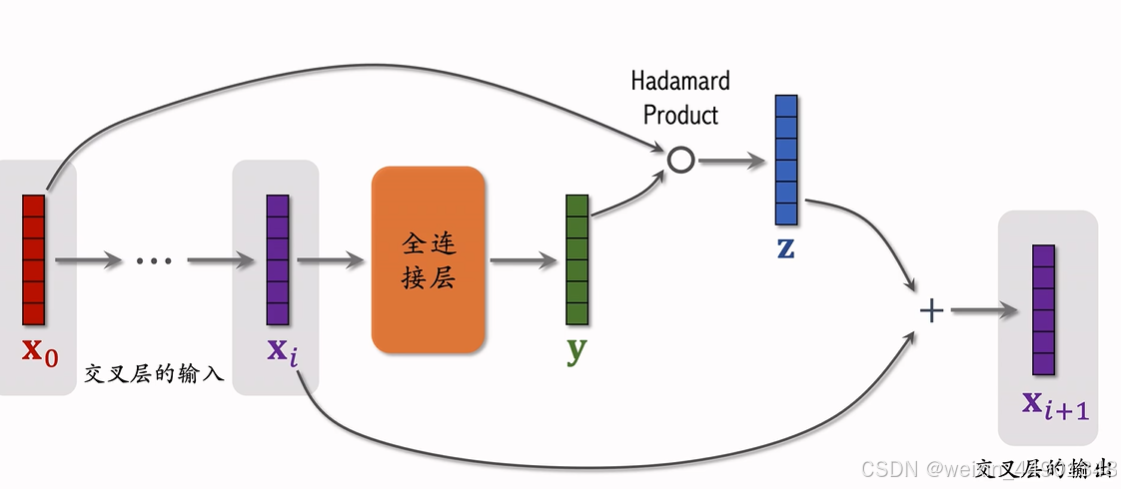
- Hadamard Product:向量逐元素相乘
- 交叉层只有全连接层有参数
- 类似与resnet的残差多了个x0的乘入
- 下面是具体公式:
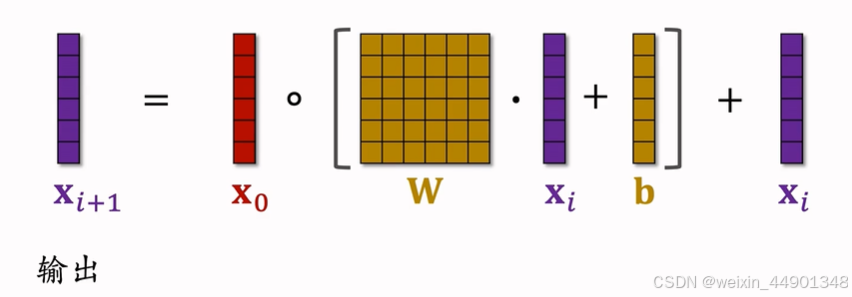
交叉网络(Cross Network)
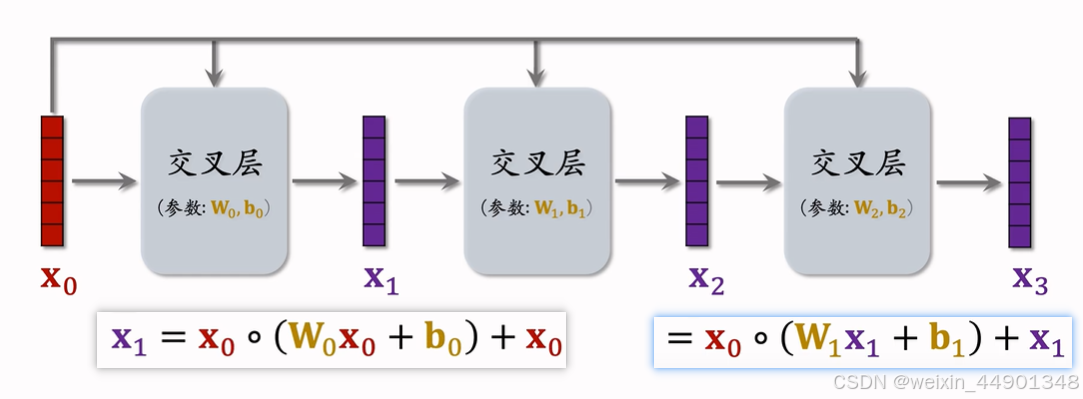
几个交叉层的连接,x0在每一层输入
深度交叉网络(Deep & Cross Network)
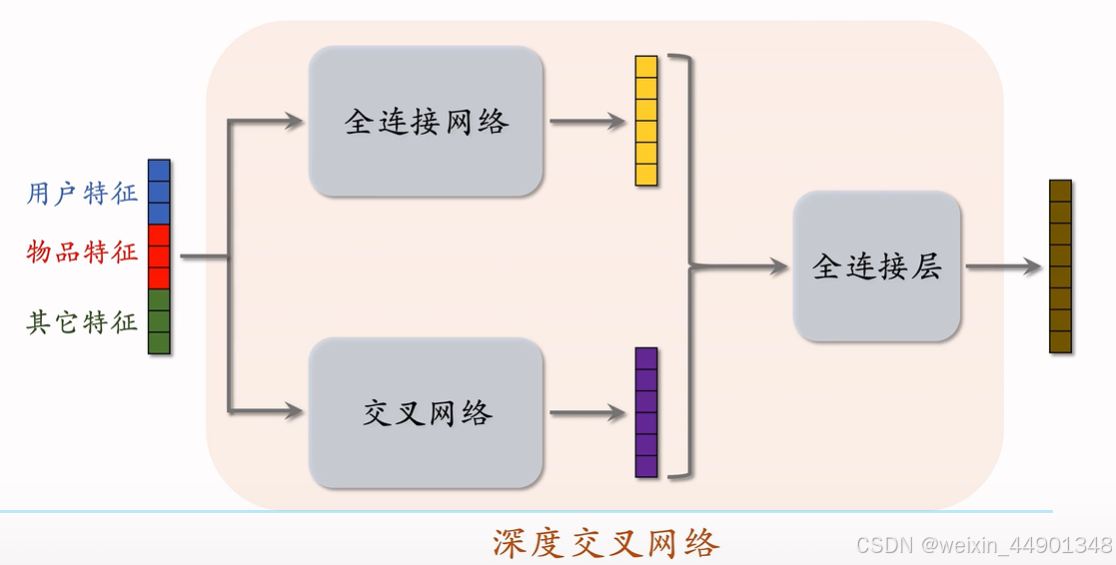
- DCN比全连接网络更好,工业界普通接受
- DCN可以用于召回、排序
- 双塔的用户/物品塔都可以是DCN
- 多目标排序中sharebotten 和 mmoe中的专家网络都可以是DCN
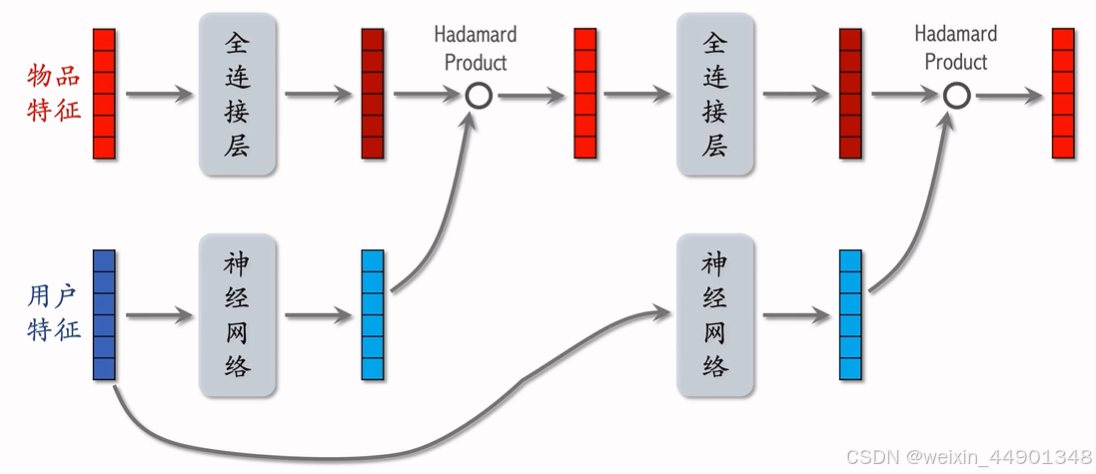
LHUC网络结构(PPNet)
工业界有效,但只用于精排
LHUC来自于语音识别
快手将LHUC用于推荐精排,称为PPNet
语音识别中的LHUC
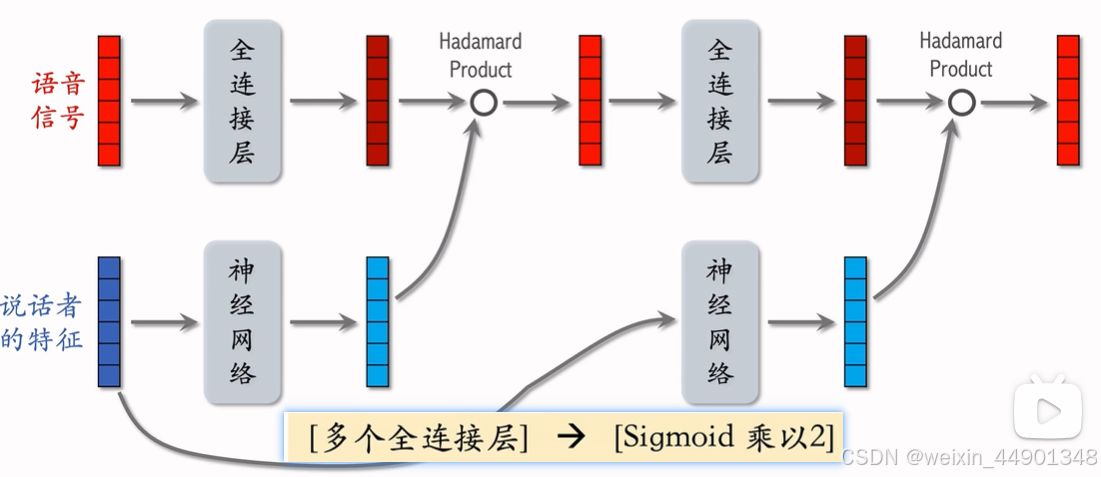
- sigmoid * 2输出0-2的特征,乘上语音信号,对语音信号有特征选择作用,放大某些特征,缩小某些特征,实现个性化
- 下面是用于排序模型的结构:
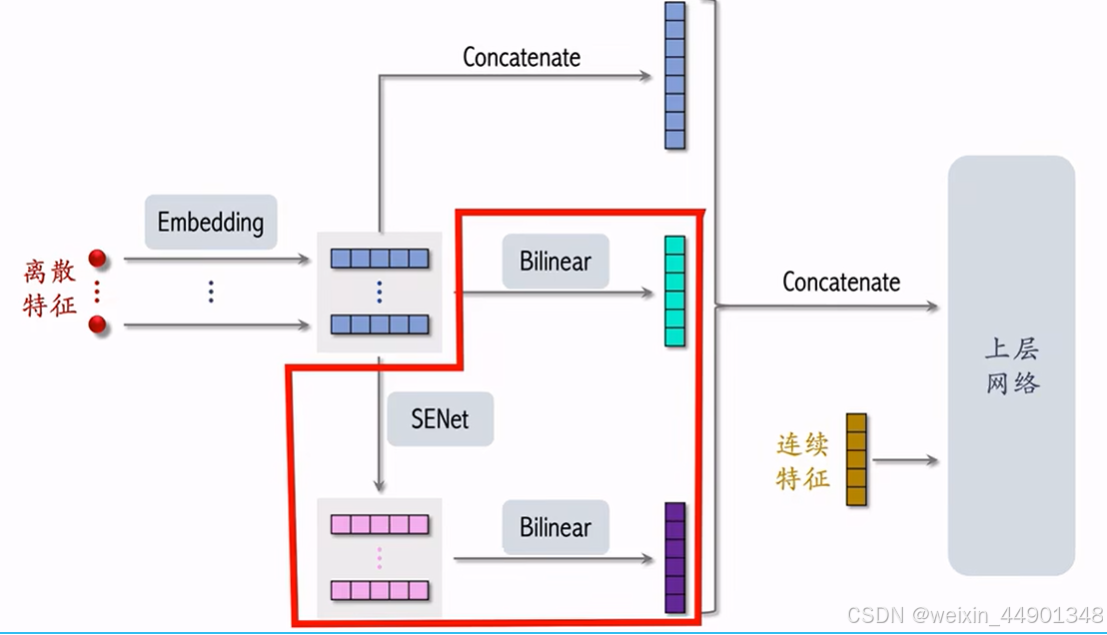
SENet & Bilinear 交叉
SENet
- 网络结构:
- m个特征输入,代表m个离散特征
- AvgPool 操作,得到mx1,每个元素对应一个离散特征
- 全连接+relu 压缩,得到m/r X 1
- 再用全连接+sigmod恢复到mx1,值域0-1
- 逐行乘输入得到输出
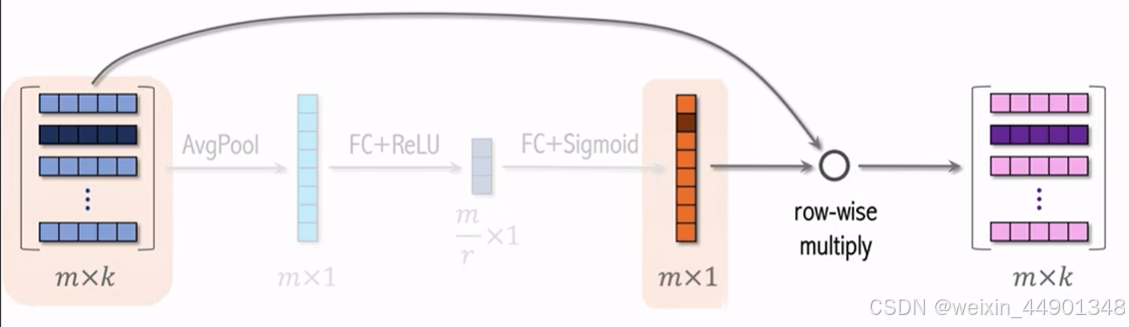
- SENet对离散特征做field-wise加权
- field:一个离散特征算一个field,得到一个权重
Field特征间交叉
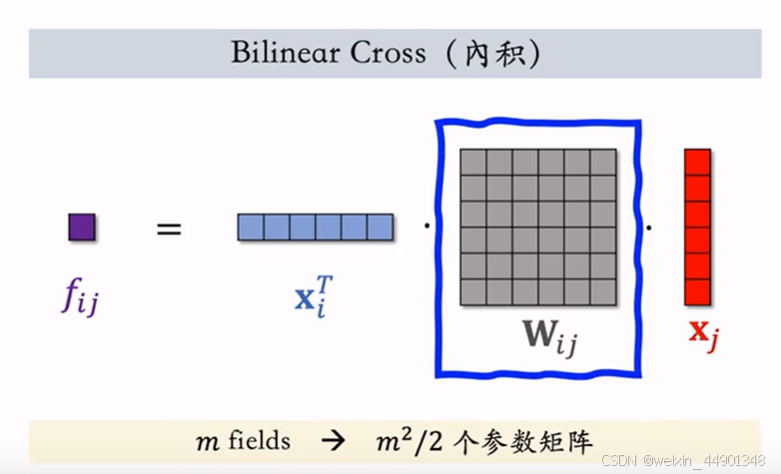
- 普通的特征交叉:
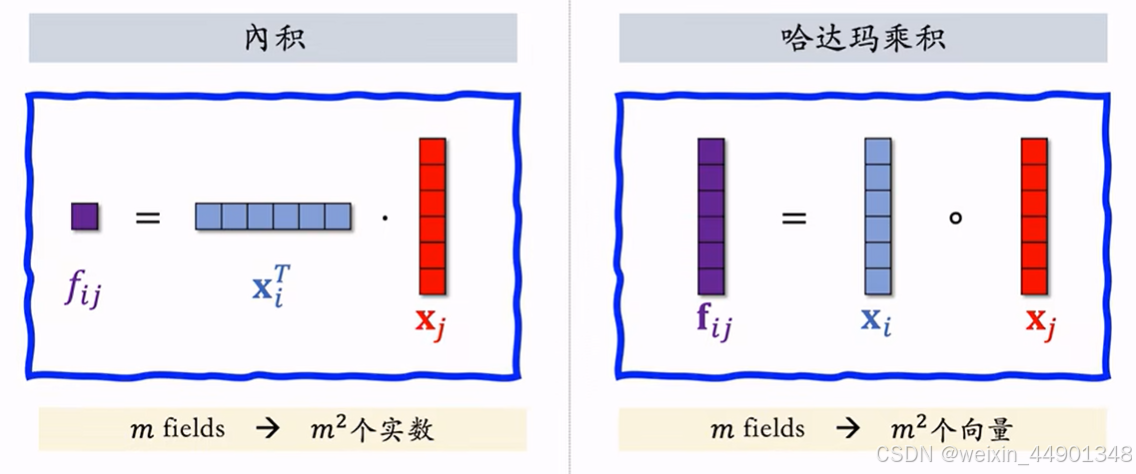
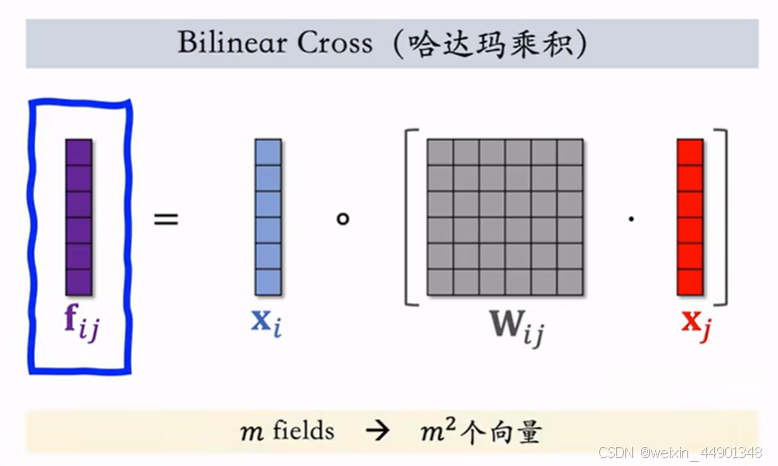
这两种交叉都需要特征维度一致 - Bilinear特征交叉
不需要特征维度一致
很多特征之间交叉意义不大,而且计算复杂,需要人工指定一些特征进行特征交叉
FiBiNet(结合senet 和 Bilinead交叉)
用户行为序列
用户行为序列建模
用户行为序列:用户最近交互过的n个物品,LastN
召回的双塔,粗排的三塔,精排模型都可以用lastN
对指标有比较大的收益
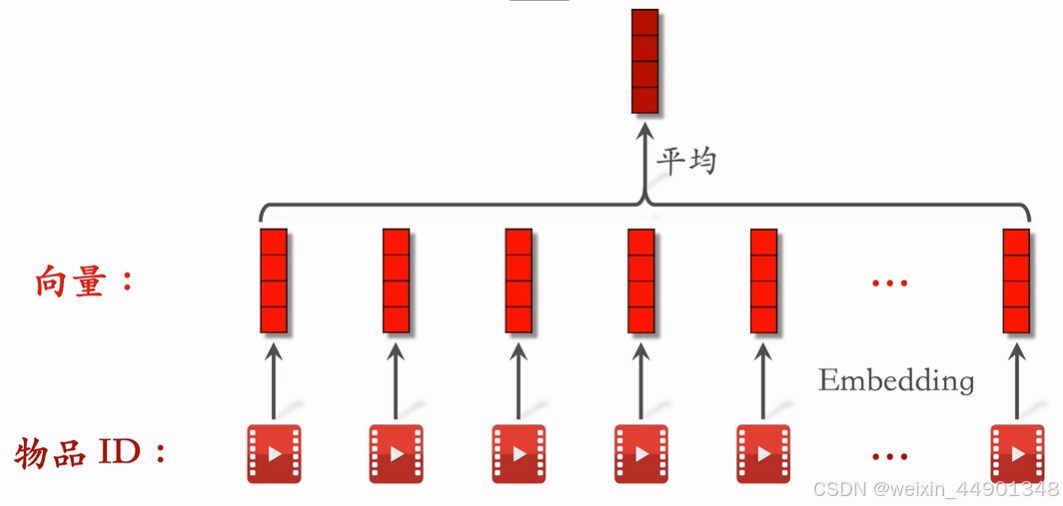
- LastN:用户最近的n次交互(点击、点赞等)的物品id
- 对LastN物品ID做emb,得到n个向量
- 对n个向量取平均(常用做法),作为用户的一种特征(用户统计特征),也可以做atten,效果更好,但是运算量更大
- 适用于召回双塔、粗排三塔、精排模型
小红书实践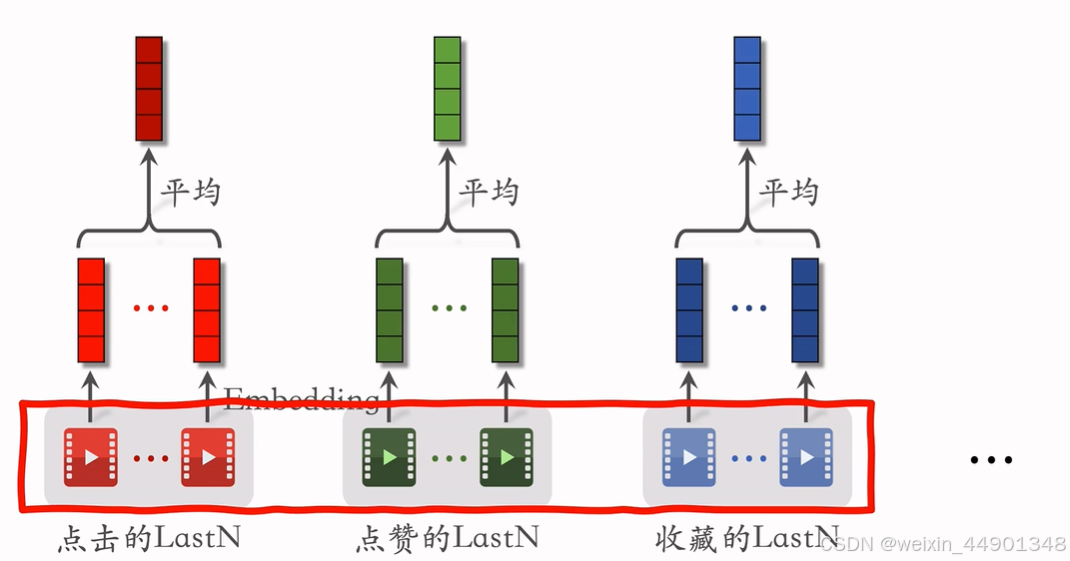
除了物品id,还会对更多的物品特征建模
DIN模型(注意力机制)
DIN用加权平均代替平均,即注意力机制
权重:候选物品(排序模型输入的候选物品)与用户LastN物品的相似度
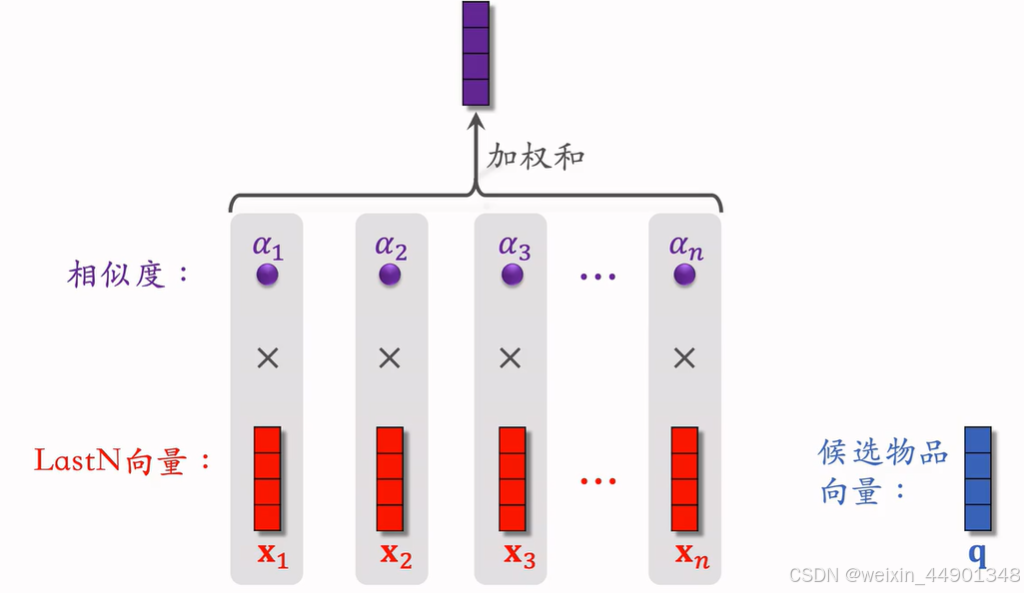
DIN流程:
- 对于某候选物品。计算它和LastN物品相似度
- 相似度为权重,求LastN物品向量加权和,得到一个向量
- 向量作为一种用户特征,输入排序模型
- 本质是注意力机制
对比简单平均 和 注意力机制
- 简单平均和注意力机制都适用于精排模型
- 简单平均适用于双塔(召回)、三塔模型(粗排)
- 简单平均只需要LastN,属于用户本身特征
- 注意力不适用双塔、三塔
- 注意力需要用到LastN+候选物品
SIM模型(长序列模型)
DIN模型缺点:
- 注意力层计算量正比与n(用户行为序列长度)
- 只能记录最近几百个物品
- 关注短期兴趣,遗忘长期兴趣
改进DIN: 快速排除掉与候选物品无关得到LastN物品
SIM模型优点:
- 保留用户长期行为记录,n大小为几千
- 对于每个候选物品,在用户LastN记录中快速查找,得到k个物品
- LastN变为TopK,计算量减小
SIM模型流程:
- 查找:
- 方法一:Hard Search
- 根据候选物品的类目,保留LastN物品中类目相同的
- 简单,快速,无需训练
- 方法二:Soft Search
- 物品做哦emb,变为向量
- 候选物品向量为query,做k最近邻查找,保留LastN中最接近的k个
- 效果显著更好,实现更复杂
- 方法一:Hard Search
- 注意力机制:
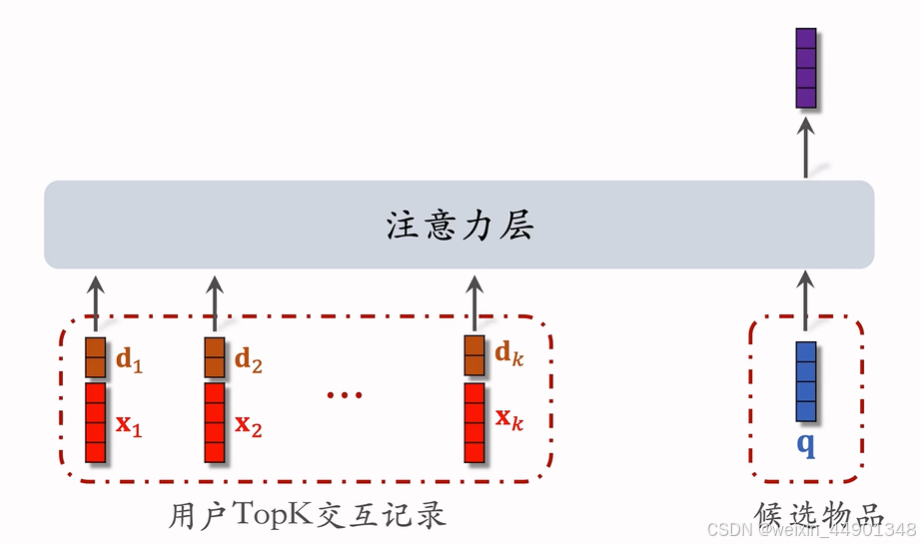
- 注意力层和DIN一致
- LastN变为TopK
- 使用时间信息 (因为SIM序列长,记录长期行为,时间越远,重要性越低)
- 用户和某个LastN物品交互时刻距今为 t
- 对t做离散化,再emb,得到向量d
- 向量d和物品特征x 做cat,表征一个LastN物品
重排
物品相似度
相似度度量
-
基于物品属性标签
- 类目、品牌、关键词等,需要手动调参得到最终相似度

- 类目、品牌、关键词等,需要手动调参得到最终相似度
-
基于物品向量表征
- 用召回的双塔模型学到的物品向量(效果不好)
- 双塔的热门现象严重,处理不好冷门和新物品
- 基于内容(图文)的向量表征(效果好)
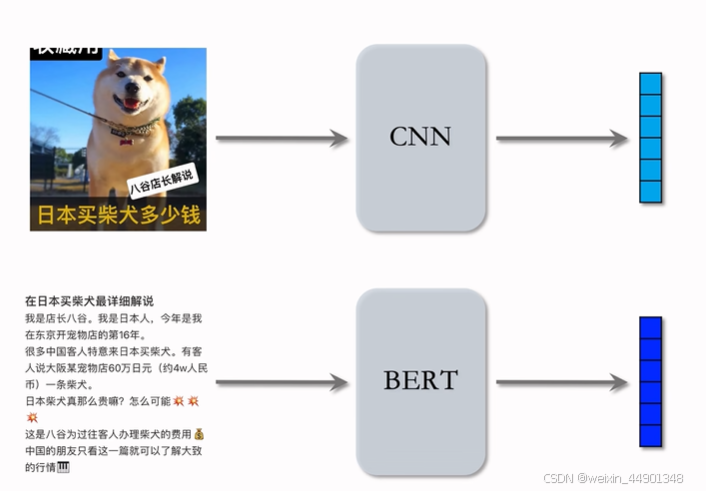
- Clip是公认最有效的预训练方法
- 思想:对于图片-文本二元组,预测图文是否匹配
- 无需标注
- 在一个batch的二元组中有m对正样本,有m(m-1)个负样本
- 用召回的双塔模型学到的物品向量(效果不好)
推荐系统链路中多样性的位置
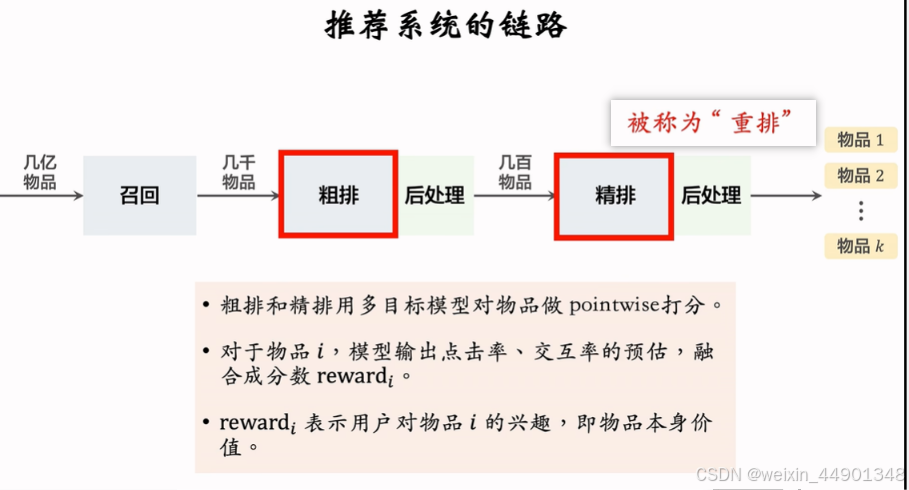
精排的后处理一般就是重排
MMR 多样性算法(Maximal Marginal Relevance)
多样性需求
- 精排给n个候选物品打分,融合之后的分数reward
- i,j物品之间相似度为sim(i, j)
- 从n个物品中选出k个,既有高精排分数,也有多样性
MMR 多样性算法
从未选中物品李选出mmr分数最高的放到选中集合
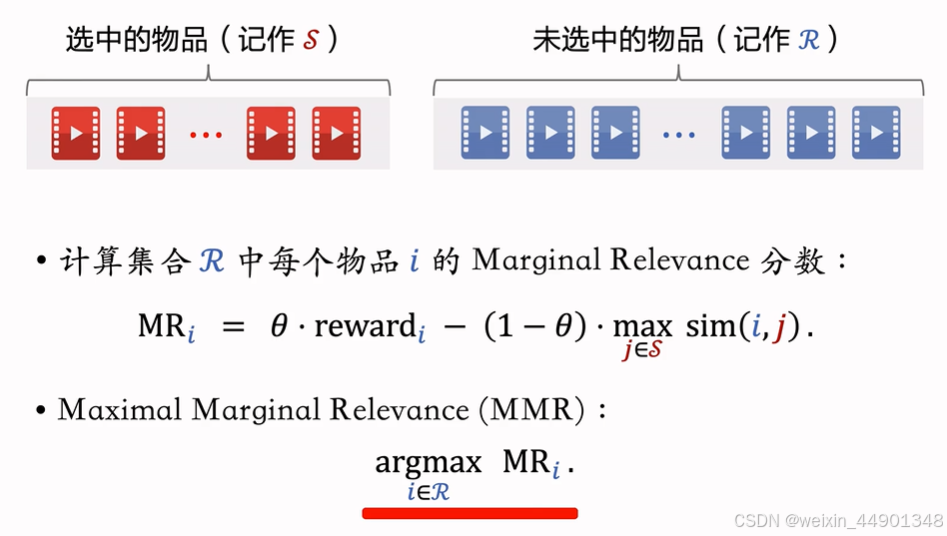
选中物品集合S越大会越难在R中找物品
- 因为sim取值为1,S很大是,mmr分数总约为1,mmr算法失效
- 解决方案:设置滑动窗口W(比如最近选中的10个物品),用W代替MMR公式中的S
- 因为相近物品多样性要求高,远的物品多样性要求低
- 一般业界都会用
重排的业务规则(业务规则约束的多样性算法,做策略)
- 最多连续出现k篇某种笔记
- 某k篇笔记最多出现1篇某种笔记
- 前t篇笔记最多出现k篇某种笔记
业务规则优先级大于多样性算法
在满足规则的前提下最大化MMR
- 每一轮先用规则排除未选集合R钟的部分物品得到子集R`
- MMR计算公式用子集R`
DPP 多样性算法
业界公认的最好多样性算法
DPP的数学基础

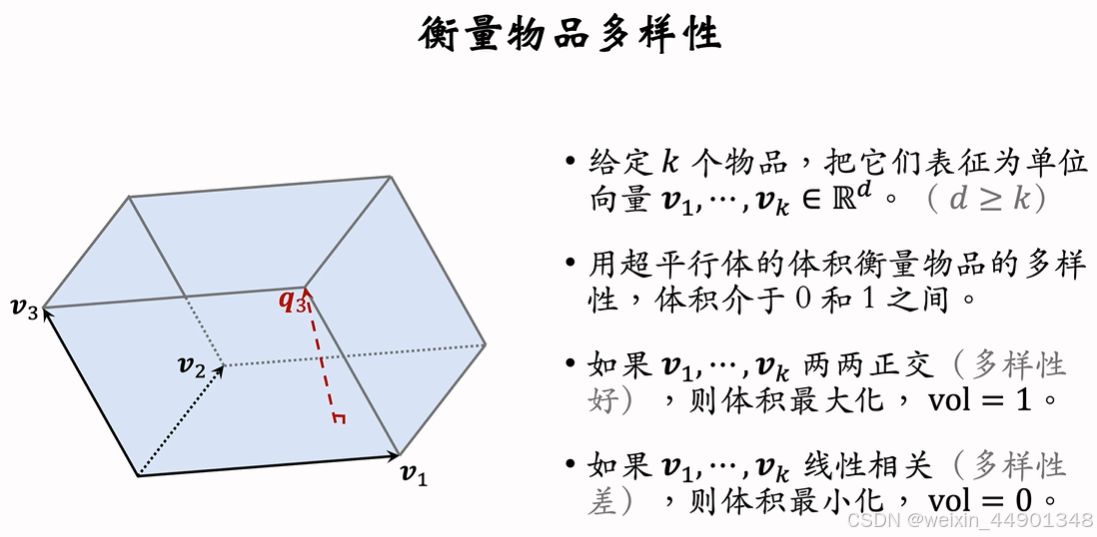
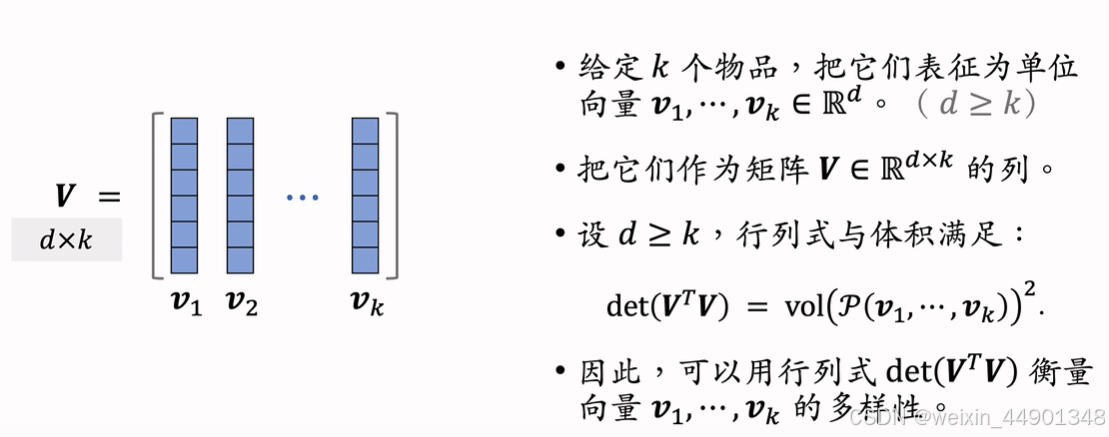
行列式值最大化,超平行体体积越大,多样性越好
DPP算法


求解DPP
-
暴力算法

主要时间复杂在A行列式的计算
总时间复杂度:O( n 2 ∗ d + n ∗ k 4 n^2*d+n*k^4 n2∗d+n∗k4) -
Hulu 快速算法


DPP扩展
- 用滑动窗口,行列式用滑动窗口W集合计算
- 规则约束,在规则过滤的集合R`中贪心找下一个物品
物品冷启动
物品冷启动指的是如何对新发布的物品做分发
UGC物品冷启动(用户上传的物品)
新笔记冷启动
- 新笔记缺少和用户交互,导致推荐难度大、效果差
- 扶持新发布、低曝光的物品,能增强作者发布意愿
优化冷启的目标:
- 精准推荐:克服冷启苦难,把新物品推荐给用户,不引起反感
- 激励发布:流量向低曝光物品倾斜,激励作者发布
- 挖掘高潜:通过初期小流量试探,找到高质量笔记,流量倾斜
冷启动优化点:
- 优化全链路(包括召回和排序)
- 流量调控(流量怎么在新老物品中分配)
评价指标
作者侧指标:
- 发布渗透率 = 当日发布人数 / 日活人数
- 人均发布量 = 当日发布笔记数 / 日活人数
作者侧指标反应作者发布积极性
冷启的重要优化目标是促进发布,增大内容池
新笔记获得曝光越多,首次曝光和交互出现越早,作者发布积极性越高
用户侧指标:
- 新笔记指标:
- 新笔记的点击率、交互率
- 分别考察高曝光、低曝光新笔记
- 高曝光:比如>1000次曝光
- 低曝光:比如<1000次曝光
- 大盘指标:消费时长、日活、月活
- 扶植低曝光会让作者侧指标变好,用户侧大盘指标变差
- 尽量不降低大盘指标
内容侧指标:
- 高热笔记占比:
- 高热笔记:前30天活得1000+点击
- 高热笔记占比越高,说明冷启动挖掘优质笔记能力越强
简单的召回通道
冷启物品的特性
- 自带图片文字地点等
- 算法或人工标注的标签
- 没有用户点击、点赞等信息
- 没有笔记ID emb
冷启动难点
- 缺少用户交互,没学好笔记ID emb,导致双塔模型效果不好(召回、排序)
- 缺少用户交互,导致itemCF不适用
双塔模型(改造后)
- ID emb的改进
- 改进方案1:新笔记使用 default emb
- 物品塔做ID emb,让所有新笔记共享一个ID
- Default emb:共享ID对于的emb 向量
- 到下次模型训练的时候,新笔记才有自己的ID emb向量
- 改进方案2:利用相似笔记的emb向量
- 查找topk内容最相似的高曝笔记
- 把k个笔记emb向量平均得到新笔记的emb
- 改进方案1:新笔记使用 default emb
- 多个召回池,让新笔记用更多曝光机会
- 1小时新笔记、6小时新笔记、24小时新笔记、30天笔记
- 共享同一个双塔模型,多个召回池不增加训练代价
类目、关键词召回
- 感兴趣的类目:美食、科技数码、电影。。。
- 感兴趣的关键词:纽约、职场、搞笑。。。
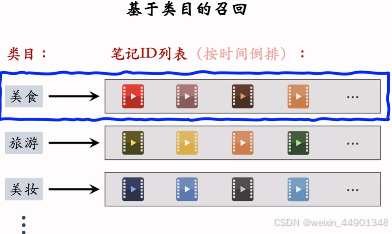
- 缺点:
- 只对刚刚发布的新笔记有效
- 弱个性化,不够精准
聚类召回
基本思想
- 用户喜欢一个笔记,就会喜欢内容类似的笔记
- 预训练一个神经网络,基于笔记的类目和图文内容,把笔记映射到向量
- 笔记向量做聚类,划分为1000cluster,记录每个cluster的中心方向(k-means聚类,用余弦相似度)
聚类索引
- 一篇新笔记发布,用神经网络映射到特征向量
- 从1000向量(对应1000个cluster)中找到最相似向量,作为新笔记的cluster
- 索引:cluster -> 笔记ID列表(时间倒排)
线上召回
- 给定用户ID,找到LastN笔记列表,把这些笔记作为种子笔记
- 每篇种子笔记映射到向量,寻找最相似的cluster
- 把每个cluster笔记列表中,取回最新的m篇笔记
- 最多取回mn篇笔记
和聚类召回缺点类似,只对新笔记有效,发布时间长就不行了
内容相似度模型
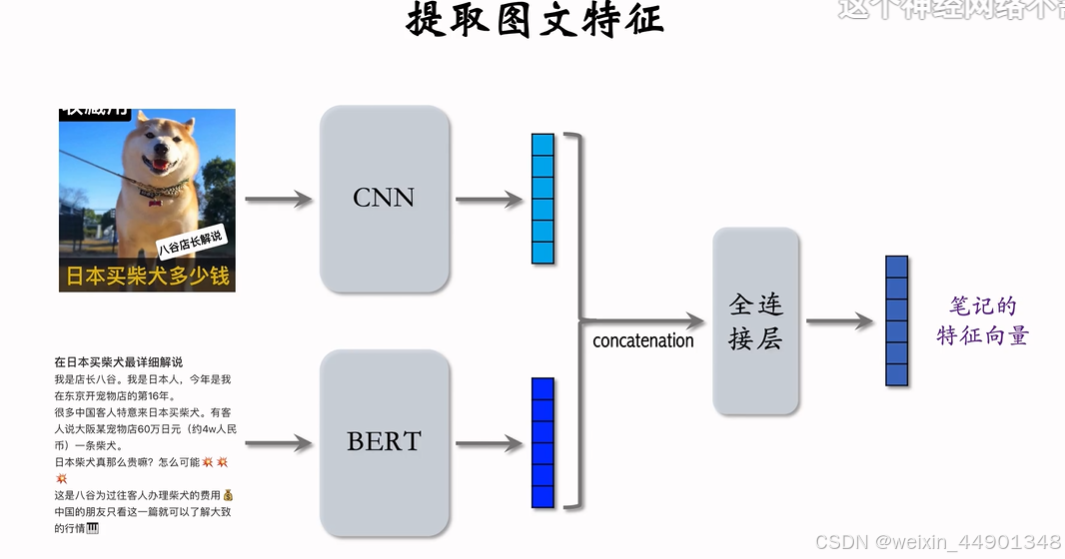
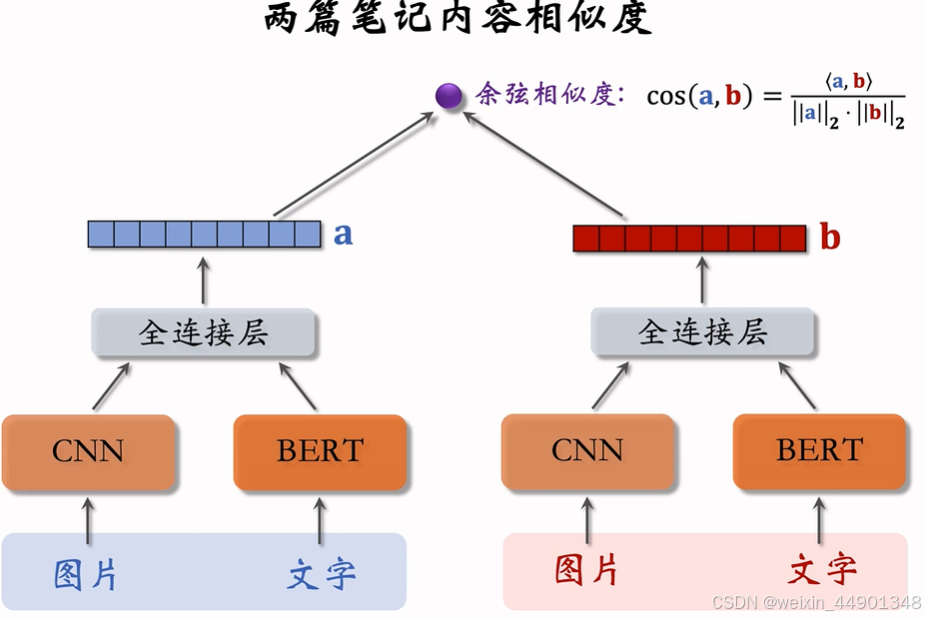
- 只有全连接层需要全量学习
模型训练
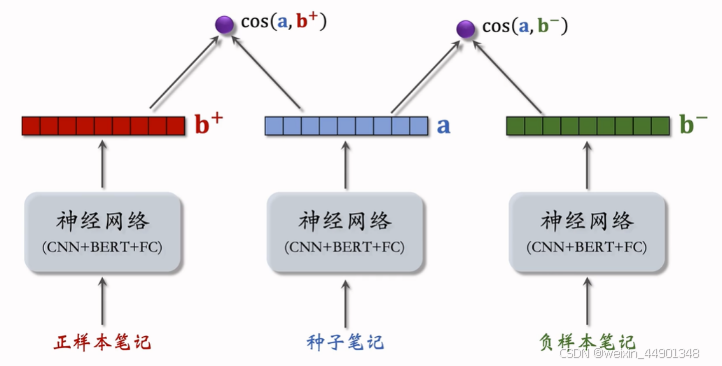
- 正样本选取

- 负样本选取

Look-Alike 召回
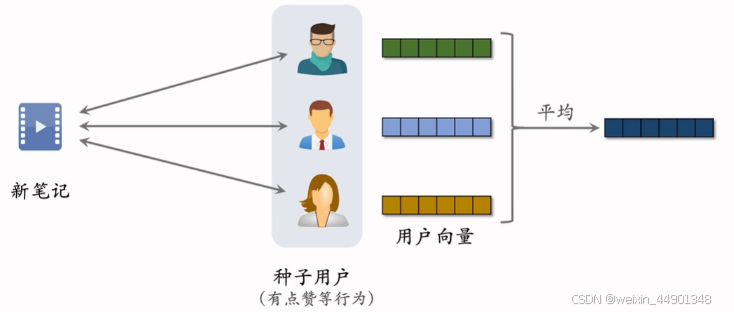
- 新笔记曝光给用户,用户中交互笔记的为种子笔记
- 种子用户向量可以用双塔模型用户塔的向量
- 平均后的向量作为新笔记的特征向量
- 近线更新向量
- 每当用用户交互物品,更新笔记的特征向量
- 用户特征在新笔记向量中查找,用户和种子用户相似
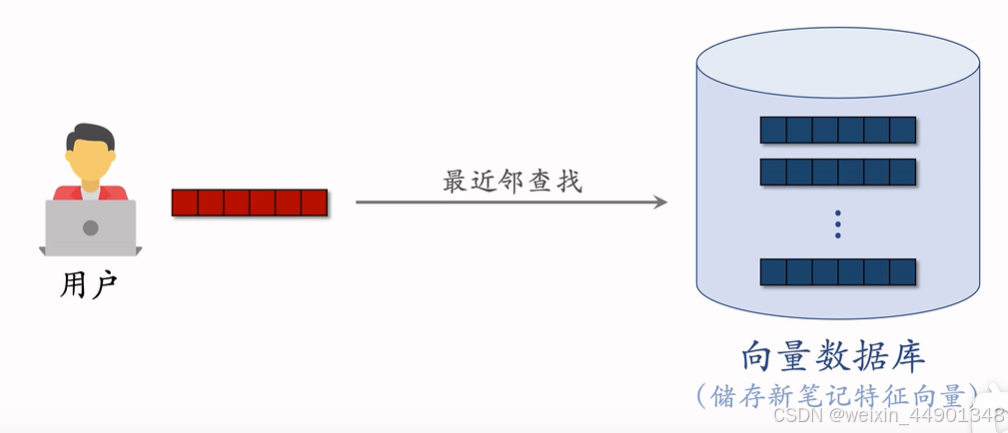
流量调控

流量调控技术的发展
- 推荐结果中强插新笔记,比较老的做法了
- 最新笔记排序分数做提权(boost)
- 在粗排、重排缓解,给新笔记提权
- 优点:容易实现。投入产出好
- 缺点:
- 曝光量对提权系数敏感
- 很难精确控制曝光量,容易过渡曝光和不充分曝光
- 通过提权,对新笔记做保量
- 保量:不论笔记质量,保证24小时一定曝光
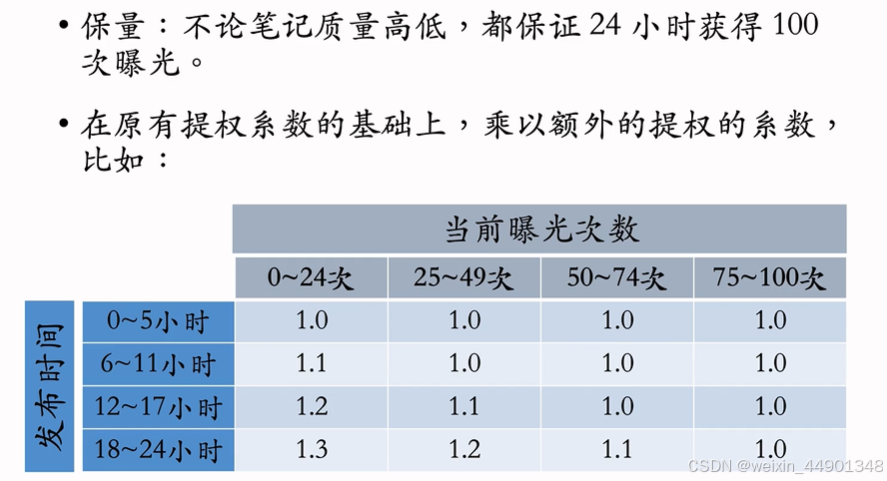
- 动态提权保留

- 保量:不论笔记质量,保证24小时一定曝光
- 保量难点

- 差异化保量

冷启动的AB测试
作者侧实验:方案一

- 缺点:
- 新笔记之间会抢流量

- 新笔记和老笔记会抢流量

- 新笔记之间会抢流量
作者侧实验:方案二
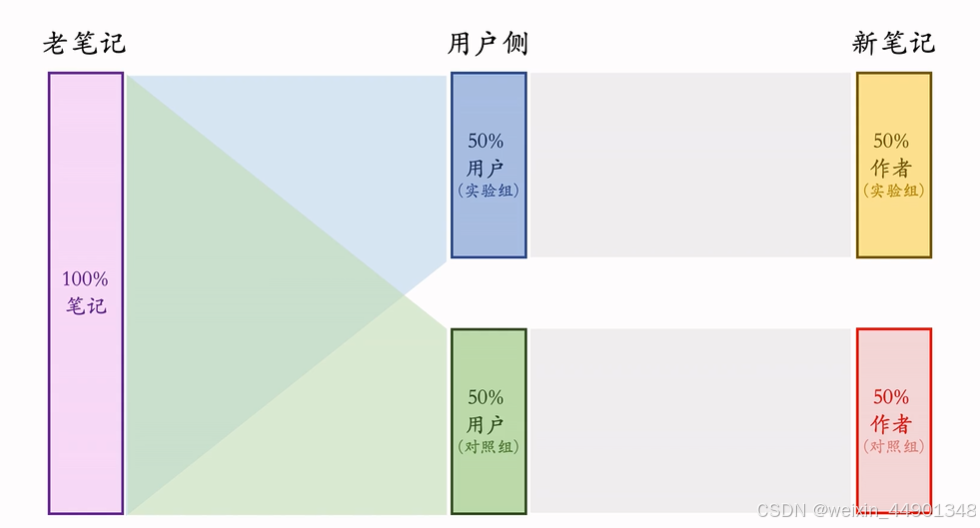

作者侧实验:方案三

内容池少一半,严重损害用户体验,不太可行
总结

涨指标方法
概述
推荐系统的评价指标
- 日活用户数(DAU)和留存是最核心的指标
- 工业最常用LT7和LT30衡量留存
- 某用户今天(t0)登录了app,蔚来7天(t0-t6)中有4天登录app,那么用户今天(t0)的LT7等于4
- LT增长通常译为用户体验提升(除非lLT增长且DAU下降)
- 其他核心指标:用户使用时长、总阅读数、总曝光数。这些指标重要性低于DAU和留存
- 对于UGC平台,发布量和发布渗透率也是核心指标
涨指标的方法
- 改进召回模型,添加新的召回模型
- 改进粗排和精排模型。
- 提升召回、粗排、精排中的多样性。
- 特殊对待新用户、低活用户等特殊人群。
- 利用关注、转发、评论这三种交互行为来提升指标。
召回
召回模型 & 召回通道
- 推荐系统有几十条召回通道,它们的召回总量是固定的。总量越大,指标越好,粗排计算量越大
- 双塔模型和item-to-item(I2I)是最重要的两类召回模型,占据召回的大部分配额
- 很多小众模型,占据配额很少。召回总量不变下,添加莫伊谢召回模型可以提升核心指标
- 有很多内容池,比如30天无哦,24小时物品,6小时物品,新用户优质内容池,分人群内容池。
- 同一个模型可以用于多个内容池,得到多条召回通道
双塔模型
- 优化正样本、负样本

- 改进神经网络结构
- basline:用户塔、物品塔分别是全连接网络,各输出一个向量,分别用于用户、物品的表征
- 改进:用户塔、物品塔分别用DCN代替全连接
- 改进:在用户塔中使用用户行为序列(LastN)
- 改进:使用多向量模型代替单向量模型(baselin中的双塔也叫单向模型)
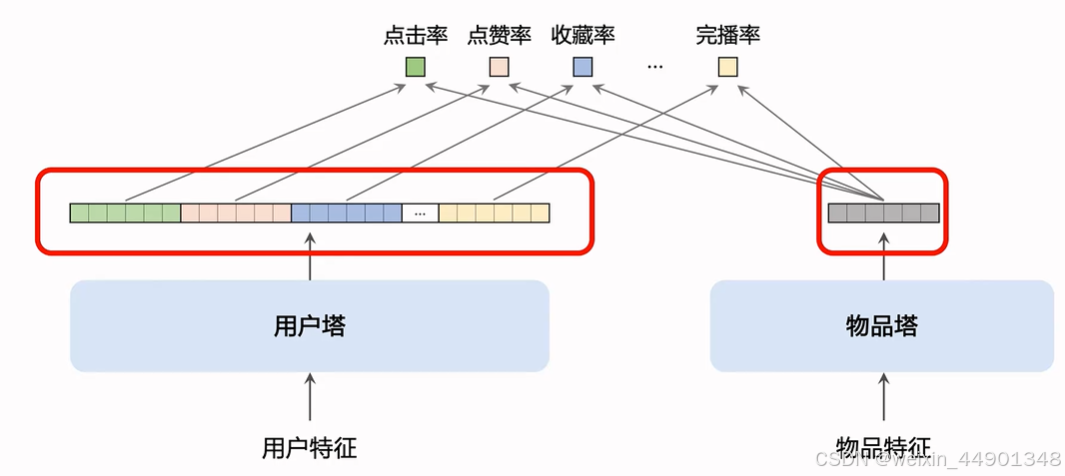
多个向量表征用户
- 改进模型训练方法
- Basline:做二分类,让模型学会区分正样本和负样本
- 改进:结合二分类、batch内负样本(对batch内负采样,需要纠偏)
- 改进:使用自监督学习方法,让冷门物品的emb学习更好
Item-to-Item(I2I)

方法2:基于物品向量表征,计算向量相似度(双塔模型,图神经网络均可计算物品向量表征)
小众的召回模型
- 类似I2I的模型


排序 (粗排和精排)
精排模型的改进
- 精排模型baseline
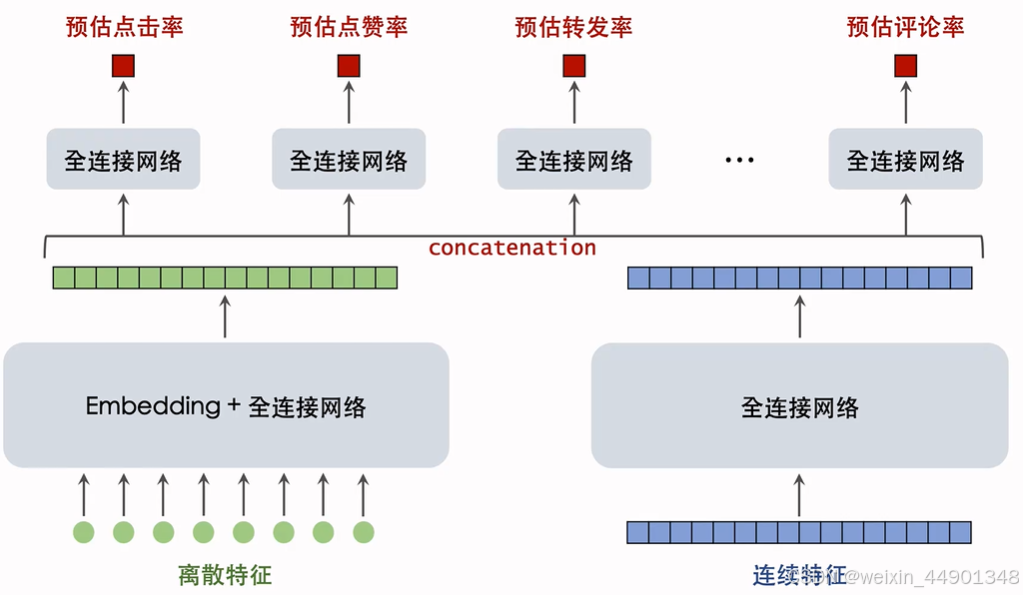
- 精排模型的基座:把原始特征映射为向量
- 离散特征:
- 经过emb得到数值向量
- 数值向量拼接得到几千维向量
- 拼接向量经过全连接层得到输出向量,几百维度
- 连续特征:输入几百维度向量,输出几百维度向量
- 这两个全连接网络一般都不会很大,cpu的话就一两层,gpu会大一点3-6层
- 离散连续向量cat之后得到一个向量
- 离散特征:
- 多目标预估:输入后续全连接网络进行多目标预测,一般这些全连接层两层
- 精排基座的改进:
- 改进1:基座加深,计算量更大,预测更准(emb已经占用很大计算的基础上)
- 改进2:做自动的特征交叉,比如bilinear和LHUC
- 改进3:特征工程,比如添加统计特征、多模态内容特征
- 多目标预估改进:
- 改进1:增加新的预估目标,并把预估目标加入融合公式
- 改进2:MMoE、PLE等结构可能有效,但往往无效
- 改进3:纠正position bias 可能有效,也可能无效
粗排模型的改进
粗排的打分量大于精排10倍,因此粗排模型必须够快
- 粗排模型结构
- 简单模型:多向量双塔模型,同时预估点击率等多个目标
- 复杂模型:三塔模型效果好,但工程实现难度较大
- 粗精排一致性建模
- 蒸馏精排模型训练粗排,让粗排与精排更一致
- 方法1:pointwise蒸馏
- y是用户真实行为,设p是精排的预估
- 用(y+p)/ 2作为粗排拟合的目标
- 方法2:pairwise 或 listwise 蒸馏
- 给定k个物品,按照精排预估做排序
- 做learing to rank(LTR),让粗排拟合物品的序(而非值)
- LTR通常用pairwise logistic loss
- 优点:粗精排一致性建模可以提升核心指标
- 缺点:如果精排出bug,精排预估值有偏差,会污染粗排模型的训练,而且不容易被察觉
- 用户行为序列建模
用户行为序列建模
- Basline:
- 最简单是对物品向量取平均,作为一种用户特征
- DIN使用注意力机制,对物品做加权平均
- 工业界目前用SIM方向。先用类目等属性筛选物品,然后用din对物品向量做加权平均
- 改进1:增加序列长度,增加序列长度,让预测更准确,但是会增加计算成本和推理时间
- 改进2筛选方法,比如用类目、物品向量表征聚类
- 离线用多模态神经网络(Bert、Clip等)提取物品内容特征,将物品表征为向量
- 离线将物品向量聚类为1000类,每个物品都有一个聚类序号
- 线上排序时,LastN有n=1e6物品,某候选物品序号为70,对n个物品做筛选,只保留聚类序号为70的物品。n个物品只有集权个被保留
- 同时好几种筛选方法,取筛选结果的并集
- 改进3:对用户行为序列中物品使用物品ID以外的一些特征
在线学习
- 全量更新 vs 增量更新
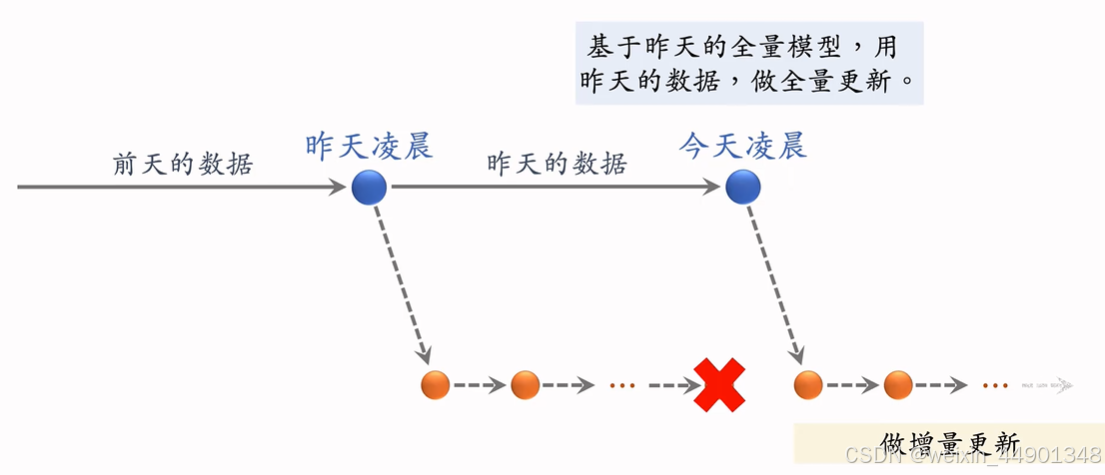
- 在线学习的资源消耗
- 增量更新提升很大,但是资源消耗也大
- 既需要在凌晨做全量更新,也需要全体不间断做增量更新
- 在线学习对指标提升大,但是会制约模型开发迭代效率。一般有一个较好的模型再上在线学习
老汤模型

- 问题1:如何快速判断新模型结构优于老模型

- 问题2:如何快速追平线上老模型

多样性
排序的多样性
- 精排多样性

- 粗排多样性

召回多样性
- 双塔模型:
- 添加噪声

- 抽样用户行为序列

- U2I2I:抽样用户行为序列

探索流量

特殊人群
为什么要特殊针对特殊人群

涨指标方法
- 构造特殊内容池,用于特殊用户的召回
- 个性化不好,要保证内容质量好
- 针对人群特点构造内容池(喜欢漂亮的用户,构造评论内容池)
- 如何构造特殊内容池


方法2工业界在用,但是不算成熟 - 特殊内容池的召回
- 通常使用双塔模型做召回

- 额外的训练代价

- 额外推理代价

- 通常使用双塔模型做召回
- 使用特殊排序策略,保护特殊用户
- 排除低质量物品

- 差异化融分公式

- 使用特殊排序模型,消除模型预估的偏差

- 方法1:大模型+小模型

- 方法2:融合多个experts。类似MMoE

- 方法3:大模型预估之后,用小模型做校准

交互行为
用户的交互行为

关注
- 关注量对留存的价值
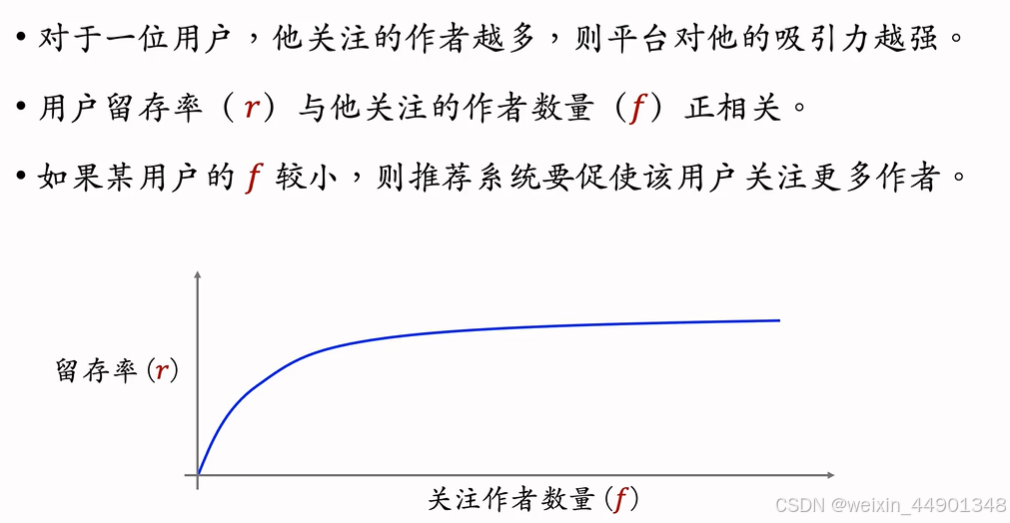
- 利用关注关系提升用户留存


- 粉丝数对促发布的价值

- 排序策略帮助低粉新作者涨粉

- 隐式关注关系

转发
- 促转发(分享回流)

- KOL建模


- 促转发策略


评论
- 评论促发布

- 评论的其他价值


















 8493
8493

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









