









还是从Memcached.c文件的main函数开始,逐步分析Memcached的实现
if (!sanitycheck()) {
return EX_OSERR;
}static bool sanitycheck(void) {
/* One of our biggest problems is old and bogus libevents */
const char *ever = event_get_version(); //获取libevent的版本
if (ever != NULL) {
if (strncmp(ever, "1.", 2) == 0) {
/* Require at least 1.3 (that's still a couple of years old) */
if ((ever[2] == '1' || ever[2] == '2') && !isdigit(ever[3])) {
fprintf(stderr, "You are using libevent %s.\nPlease upgrade to"
" a more recent version (1.3 or newer)\n", 说明至少是1.3版本以上
event_get_version());
return false;
}
}
}
return true;
}
/* handle SIGINT and SIGTERM */
signal(SIGINT, sig_handler); //Ctrl + C产生的信号
signal(SIGTERM, sig_handler); //kill命令产生的信号
/* init settings */
settings_init(); //默认初始化static void settings_init(void) {
settings.use_cas = true;
settings.access = 0700;
settings.port = 11211; //端口号
settings.udpport = 11211;
/* By default this string should be NULL for getaddrinfo() */
settings.inter = NULL;
settings.maxbytes = 64 * 1024 * 1024; /* default is 64MB */ 默认分配最大64M内存
settings.maxconns = 1024; /* to limit connections-related memory to about 5MB */
settings.verbose = 0; //信息打印
settings.oldest_live = 0;
settings.oldest_cas = 0; /* supplements accuracy of oldest_live */
settings.evict_to_free = 1; /* push old items out of cache when memory runs out */
settings.socketpath = NULL; /* by default, not using a unix socket */
settings.factor = 1.25; //slab分配增长因子
settings.chunk_size = 48; /* space for a modest key and value */
settings.num_threads = 4; /* N workers */
settings.num_threads_per_udp = 0;
settings.prefix_delimiter = ':';
settings.detail_enabled = 0;
settings.reqs_per_event = 20;
settings.backlog = 1024;
settings.binding_protocol = negotiating_prot;
settings.item_size_max = 1024 * 1024; /* The famous 1MB upper limit. */
settings.maxconns_fast = false;
settings.lru_crawler = false;
settings.lru_crawler_sleep = 100;
settings.lru_crawler_tocrawl = 0;
settings.lru_maintainer_thread = false;
settings.hot_lru_pct = 32;
settings.warm_lru_pct = 32;
settings.expirezero_does_not_evict = false;
settings.hashpower_init = 0;
settings.slab_reassign = false;
settings.slab_automove = 0;
settings.shutdown_command = false;
settings.tail_repair_time = TAIL_REPAIR_TIME_DEFAULT;
settings.flush_enabled = true;
settings.crawls_persleep = 1000;
}
/* Run regardless of initializing it later */
init_lru_crawler();
init_lru_maintainer(); /* set stderr non-buffering (for running under, say, daemontools) */
setbuf(stderr, NULL);if (hash_init(hash_type) != 0) {
fprintf(stderr, "Failed to initialize hash_algorithm!\n");
exit(EX_USAGE);
}
main_base = event_init(); //主线程base初始化
/* initialize other stuff */
stats_init(); //用于统计的结构的初始化
assoc_init(settings.hashpower_init); //Memcached的hash表初始化,默认256个
conn_init(); //用于连接结构体的初始化
slabs_init(settings.maxbytes, settings.factor, preallocate); //slab内存分配(默认分配64M空间<span style="font-family: Arial, Helvetica, sans-serif; font-size: 12px;">)</span>static void conn_init(void) {
/* We're unlikely to see an FD much higher than maxconns. */
int next_fd = dup(1);
int headroom = 10; /* account for extra unexpected open FDs */
struct rlimit rl;
max_fds = settings.maxconns + headroom + next_fd; //设置最大文件描述符
/* But if possible, get the actual highest FD we can possibly ever see. */
if (getrlimit(RLIMIT_NOFILE, &rl) == 0) {
max_fds = rl.rlim_max; //由系统获取最大值
} else {
fprintf(stderr, "Failed to query maximum file descriptor; "
"falling back to maxconns\n");
}
close(next_fd);
if ((conns = calloc(max_fds, sizeof(conn *))) == NULL) { //分配资源
fprintf(stderr, "Failed to allocate connection structures\n");
/* This is unrecoverable so bail out early. */
exit(1);
}
}
Memcached的内存分配模型:
Memcached默认分配64M内存,有slabclass链表组成,每个slabclass又有多个slab,每个slab默认是1M的内存分配,每个slab又由逐渐增大的chunck内存空间组成,增长空间由增长因子来计算获取,比如第一个chunck是100byte,factor默认为1.25,则第二个chunck为125bytes,依次分配填充内存空间,避免内存的浪费。
slabclass_t结构体:
typedef struct {
unsigned int size; /* sizes of items */小于这个大小的item存入此slabclass中 item就是要存储的实际数据,组织的set命令的数据,每个item会放到合适的一个chunck中
unsigned int perslab; /* how many items per slab */ 存储多少个item了
void *slots; /* list of item ptrs */ 回收空闲item链表
unsigned int sl_curr; /* total free items in list */ 记录有所多少的items空间没有使用
unsigned int slabs; /* how many slabs were allocated for this class */ 分配了多少个slab
void **slab_list; /* array of slab pointers */ 指向slab链表地址
unsigned int list_size; /* size of prev array */slab链表的大小,1个slab就是1M,2个slab就是2M内存空间
unsigned int killing; /* index+1 of dying slab, or zero if none */
size_t requested; /* The number of requested bytes */
} slabclass_t;
static slabclass_t slabclass[MAX_NUMBER_OF_SLAB_CLASSES]; 64个slabclassslabclass 是由 chunk size 确定的, 同一个 slabclass 内的 chunk 大小都一样, 每一个 slabclass 要负责管理
一些内存, 初始时, 系统为每个 slabclass 分配一个 slab, 一个 slab 就是一个内存块, 其大小等于 1M. 然后每个
slabclass 再把 slab 切分成一个个 chunk, 算一下, 一个 slab 可以切分得到 1M/chunk_size 个chunk.
a)slab、chunk
slab是一块内存空间,默认大小为1M,而memcached会把一个slab分割成一个个chunk,比如说1M的slab分成两个0.5M的chunk,所以说slab和chunk其实都是代表实质的内存空间,chunk只是把slab分割后的更小的单元而已。
slab就相当于作业本中的“页”,而chunk则是把一页画成一个个格子中的“格”。
b)item
item是我们要保存的数据,例如php代码:$memcached->set(“name”,”abc”,30);代表我们把一个key为name,value为abc的键值对保存在内存中30秒,那么上述中的”name”, “abc”, 30这些数据实质都是我们要memcached保存下来的数据, memcached会把这些数据打包成一个item,这个item其实是memcached中的一个结构体(当然结构远不止上面提到的三个字段这么简单),把打包好的item保存起来,完成工作。而item保存在哪里?其实就是上面提到的”chunk”,一个item保存在一个chunk中。
chunk是实质的内存空间,item是要保存的东西,所以关系是:item是往chunk中塞的。

/**
* Determines the chunk sizes and initializes the slab class descriptors
* accordingly.
*/
void slabs_init(const size_t limit, const double factor, const bool prealloc) {
int i = POWER_SMALLEST - 1;
unsigned int size = sizeof(item) + settings.chunk_size;
mem_limit = limit; 默认分配大小
if (prealloc) {
/* Allocate everything in a big chunk with malloc */
mem_base = malloc(mem_limit);
if (mem_base != NULL) {
mem_current = mem_base;
mem_avail = mem_limit;
} else {
fprintf(stderr, "Warning: Failed to allocate requested memory in"
" one large chunk.\nWill allocate in smaller chunks\n");
}
}
memset(slabclass, 0, sizeof(slabclass));
while (++i < MAX_NUMBER_OF_SLAB_CLASSES-1 && size <= settings.item_size_max / factor) {
/* Make sure items are always n-byte aligned */
if (size % CHUNK_ALIGN_BYTES) 内存对齐
size += CHUNK_ALIGN_BYTES - (size % CHUNK_ALIGN_BYTES);
slabclass[i].size = size; 标识item大小
slabclass[i].perslab = settings.item_size_max / slabclass[i].size; //默认1M空间可一个存储多少items
size *= factor; 作为下一个slabclass的size大小
if (settings.verbose > 1) {
fprintf(stderr, "slab class %3d: chunk size %9u perslab %7u\n",
i, slabclass[i].size, slabclass[i].perslab);
}
}
power_largest = i;
slabclass[power_largest].size = settings.item_size_max; 最后剩余一个全部分配出去
slabclass[power_largest].perslab = 1;
if (settings.verbose > 1) {
fprintf(stderr, "slab class %3d: chunk size %9u perslab %7u\n",
i, slabclass[i].size, slabclass[i].perslab);
}
/* for the test suite: faking of how much we've already malloc'd */
{
char *t_initial_malloc = getenv("T_MEMD_INITIAL_MALLOC");
if (t_initial_malloc) {
mem_malloced = (size_t)atol(t_initial_malloc);
}
}
if (prealloc) {
slabs_preallocate(power_largest);
}
}
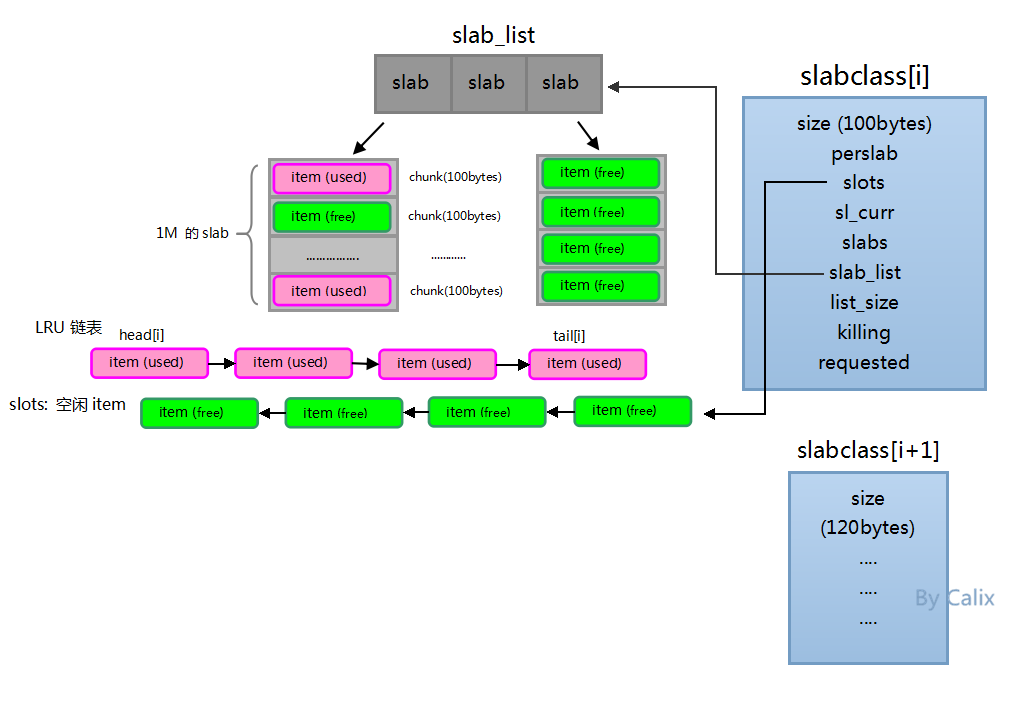
使用内存保存数据总会有满的情况,满就得淘汰,而memcached中的淘汰机制是LRU(最近最少使用算法 ),所以每个slabclass都保存着一个LRU队列,而head[i]和tail[i]则就是id为i的slabclass LRU队列的头部和尾部,尾部的item是最应该淘汰的项,也就是最近最少使用的项。
3)下面结合下面的结构图对memcached内存分配的模型进行解说:
a)初始化slabclass数组,每个元素slabclass[i]都是不同size的slabclass。
b)每开辟一个新的slab,都会根据所在的slabclass的size来分割chunk,分割完chunk之后,把chunk空间初始化成一个个free item,并插入到slot链表中。
c)我们每使用一个free item都会从slot链表中删除掉并插入到LRU链表相应的位置。
d)每当一个used item被访问的时候都会更新它在LRU链表中的位置,以保证LRU链表从尾到头淘汰的权重是由高到低的。
e)会有另一个叫“item爬虫”的线程(以后会讲到)慢慢地从LRU链表中去爬,把过期的item淘汰掉然后重新插入到slot链表中(但这种方式并不实时,并不会一过期就回收)。
f)当我们要进行内存分配时,例如一个SET命令,它的一般步骤是:
计算出要保存的数据的大小,然后选择相应的slabclass进入下面处理:
首先,从相应的slabclass LRU链表的尾部开始,尝试找几次(默认是5次),看看有没有过期的item(虽然有item爬虫线程在帮忙查找,但这里分配的时候,程序还是会尝试一下自己找,自己临时充当牛爬虫的角色),如果有就利用这个过期的item空间。
如果没找到过期的,则尝试去slot链表中拿空闲的free item。
如果slot链表中没有空闲的free item了,尝试申请内存,开辟一块新的slab,开辟成功后,slot链表就又有可用的free item了。
如果开不了新的slab那说明内存都已经满了,用完了,只能淘汰,所以用LRU链表尾部找出一个item淘汰之,并作为free item返回。
其他内存处理函数可以参考:http://blog.csdn.net/yxnyxnyxnyxnyxn/article/details/7869900















 630
630

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









