转自 http://blog.csdn.net/abcjennifer/article/details/42528569
下面通过一个经典例子来看shared memory作用:矩阵乘法
目的:实现C=A*B,方法:c[i,j] = A[i,:] * B[:,j],
其中矩阵用row-major表示,即c[i,j] = *(c.elements + i*c.width + j)
1. 不用shared memory优化版:
设A为m*t的矩阵;B为t*n的矩阵;
每个线程读取A的一行,B的一列,计算C的对应值;
所以这样需要从global memory中读n次A,m次B。
-
-
- typedef struct {
- int width;
- int height;
- float* elements;
- } Matrix;
-
-
- #define BLOCK_SIZE 16
-
-
- __global__ void MatMulKernel(const Matrix, const Matrix, Matrix);
-
-
-
- void MatMul(const Matrix A, const Matrix B, Matrix C)
- {
-
- Matrix d_A;
- d_A.width = A.width; d_A.height = A.height;
- size_t size = A.width * A.height * sizeof(float);
- cudaMalloc(&d_A.elements, size);
- cudaMemcpy(d_A.elements, A.elements, size,
- cudaMemcpyHostToDevice);
- Matrix d_B;
- d_B.width = B.width; d_B.height = B.height;
- size = B.width * B.height * sizeof(float);
- cudaMalloc(&d_B.elements, size);
- cudaMemcpy(d_B.elements, B.elements, size,
- cudaMemcpyHostToDevice);
-
-
- Matrix d_C;
- d_C.width = C.width; d_C.height = C.height;
- size = C.width * C.height * sizeof(float);
- cudaMalloc(&d_C.elements, size);
-
-
- dim3 dimBlock(BLOCK_SIZE, BLOCK_SIZE);
- dim3 dimGrid(B.width / dimBlock.x, A.height / dimBlock.y);
- MatMulKernel<<<dimGrid, dimBlock>>>(d_A, d_B, d_C);
-
-
- cudaMemcpy(C.elements, Cd.elements, size,
- cudaMemcpyDeviceToHost);
- }
-
-
- cudaFree(d_A.elements);
- cudaFree(d_B.elements);
- cudaFree(d_C.elements);
- }
-
-
- __global__ void MatMulKernel(Matrix A, Matrix B, Matrix C)
- {
-
-
- float Cvalue = 0;
- int row = blockIdx.y * blockDim.y + threadIdx.y;
- int col = blockIdx.x * blockDim.x + threadIdx.x;
- for (int e = 0; e < A.width; ++e)
- Cvalue += A.elements[row * A.width + e]* B.elements[e * B.width + col];
- C.elements[row * C.width + col] = Cvalue;
- }
2. 利用shared memory
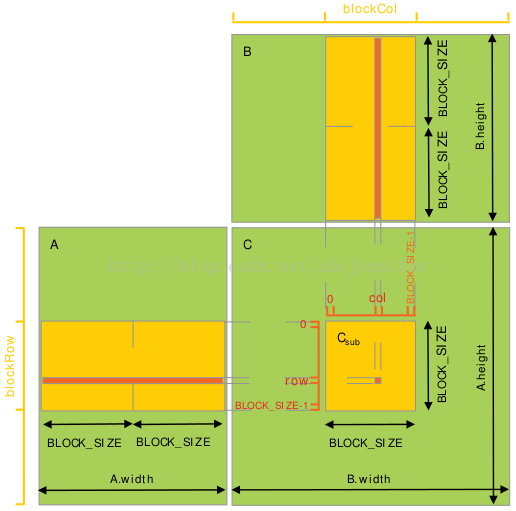
每个thread block负责计算一个子矩阵Csub, 其中每个thread负责计算Csub中的一个元素。如下图所示。为了将fit设备资源,A,B都分割成很多block_size维的方形matrix,Csub将这些方形matrix的乘积求和而得。每次计算一个乘积时,先将两个对应方形矩阵从global memory 载入 shared memory(一个thread负责载入A, B两个sub matrix的元素),然后每个thread计算乘积的一个元素,再由每个thread将这些product加和,存入一个register,最后一次性写入global memory。计算时注意同步,详见代码。
设A为m*t的矩阵;B为t*n的矩阵;
这样呢,A只从global memory读了n/block_size次,B只读了m/block_size次;
Kernel Code:
- __global__ void MatMulKernel(Matrix A, Matrix B, Matrix C)
- {
-
- int blockRow = blockIdx.y;
- int blockCol = blockIdx.x;
-
-
- Matrix Csub = GetSubMatrix(C, blockRow, blockCol);
-
-
-
- float Cvalue = 0;
-
-
- int row = threadIdx.y;
- int col = threadIdx.x;
-
-
-
-
-
-
- for (int m = 0; m < (A.width / BLOCK_SIZE); ++m) {
-
-
- Matrix Asub = GetSubMatrix(A, blockRow, m);
-
- Matrix Bsub = GetSubMatrix(B, m, blockCol);
-
-
- __shared__ float As[BLOCK_SIZE][BLOCK_SIZE];
- __shared__ float Bs[BLOCK_SIZE][BLOCK_SIZE];
-
-
-
- As[row][col] = GetElement(Asub, row, col);
- Bs[row][col] = GetElement(Bsub, row, col);
-
-
-
- __syncthreads();
-
-
- for (int e = 0; e < BLOCK_SIZE; ++e)
- Cvalue += As[row][e] * Bs[e][col];
-
-
-
-
- __syncthreads();
- }
-
-
-
- SetElement(Csub, row, col, Cvalue);
- }
Host Code:
-
- dim3 dimBlock(BLOCK_SIZE, BLOCK_SIZE);
- dim3 dimGrid(B.width / dimBlock.x, A.height / dimBlock.y);
- MatMulKernel<<<dimGrid, dimBlock>>>(d_A, d_B, d_C);























 6030
6030

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









