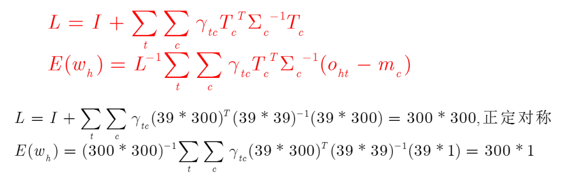1. i-vector的由来
基于因子分析理论,句子h的超向量可以描述成
其中为ubm模型的均值超向量,
即为i-vector。
2. i-vector的计算
2.1 T矩阵的估计
为句子h的观察特征,可以对应于上面的
,依据上式进行如下分布假设:
服从正态分布N(0,I)
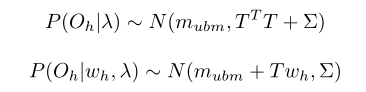
基于最大似然准则估计T矩阵,利用到EM算法
EM:先初始化T,估计出,再依据
估计T,反复迭代
2.2 i-vector计算公式
1. i-vector的由来
基于因子分析理论,句子h的超向量可以描述成
其中为ubm模型的均值超向量,
即为i-vector。
2. i-vector的计算
2.1 T矩阵的估计
为句子h的观察特征,可以对应于上面的
,依据上式进行如下分布假设:
服从正态分布N(0,I)
基于最大似然准则估计T矩阵,利用到EM算法
EM:先初始化T,估计出,再依据
估计T,反复迭代
2.2 i-vector计算公式
 4023
4023











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言