






在深度学习的路上,从头开始了解一下各项技术。本人是DL小白,连续记录我自己看的一些东西,大家可以互相交流。
本文参考:https://blog.csdn.net/u014688145/article/details/53046765?locationNum=7&fps=1
https://blog.csdn.net/qq_27292549/article/details/79128964
https://blog.csdn.net/yifeng4321/article/details/54572536
https://blog.csdn.net/xmu_jupiter/article/details/47281211
话者确认中信道和时长失配补偿研究_胡群威
以及实验室同学的PPT,感谢!
这篇文章算是对GMM-UBM系统框架的后续处理,默认大家已经熟悉了GMM-UBM模型,如果没有的话,可以参考我之前的文章:https://blog.csdn.net/weixin_38206214/article/details/81084456
一、前言
在上篇文章中,已经大致的阐述了GMM-UBM系统框架。但是在实际应用中,由于说话人语音中说话人信息和各种干扰信息掺杂在一起,不同的采集设备的信道之间也具有差异性,会使我们收集到的语音中掺杂信道干扰信息。这种干扰信息会引起说话人信息的扰动。传统的GMM-UBM方法,没有办法克服这一问题,导致系统性能不稳定。
在GMM-UBM模型里,每个目标说话人都可以用GMM模型来描述。因为从UBM模型自适应到每个说话人的GMM模型时,只改变均值,对于权重和协方差不做任何调整,所以说话人的信息大部分都蕴含在GMM的均值里面。GMM均值矢量中,除了绝大部分的说话人信息之外,也包含了信道信息。联合因子分析(Joint Factor Analysis, JFA)可以对说话人差异和信道差异分别建模,从而可以很好的对信道差异进行补偿,提高系统表现。但由于JFA需要大量不同通道的训练语料,获取困难,并且计算复杂,所以难以投入实际使用。由Dehak提出的,基于I-Vector因子分析技术,提出了全新的解决方法。JFA方法是对说话人差异空间以与信道差异空间分别建模,而基于I-Vector的方法是对全局差异进行建模,将其二者作为一个整体进行建模,这样处理放宽了对训练语料的限制,并且计算简单,性能也相当。
由于I-Vector矢量中不仅包含说话人差异信息,同时也存在信道差异信息,不光需要去除I-Vector矢量中的信道干扰,同时还需要信道补偿技术来消除信道干扰。
关于信道补偿算法会在明天的文章中发出,发出之后会贴上链接。
在I-Vector的计算中,涉及到隐马尔可夫模型和Baum-Welch算法,这部分会在之后有空补上,大家可以先参考博客:
https://blog.csdn.net/u014688145/article/details/53046765?locationNum=7&fps=1
二、均值超矢量
均值超矢量(supervector)是GMM-UBM模型的最终结果。在GMM-UBM框架下,说话人模型是从UBM模型自适应得到的,过程中只改变了均值的大小,因此说话人之间的区别信息都蕴含在GMM的均值矢量中。将说话人GMM模型的每个高斯成分的均值堆叠起来,形成一个高维的超矢量,即为均值超矢量。假设语音声学特征参数的纬度为P,GMM的混合度为M(M个高斯成分),那么这个GMM的均值超矢量的维度为MP。均值超矢量生成过程如下图:
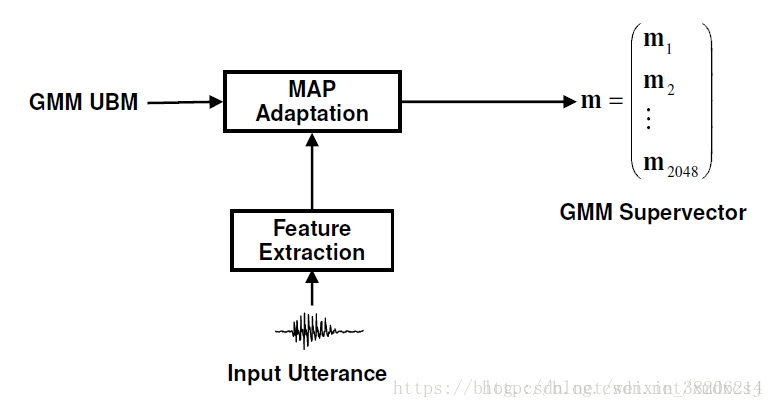
由于均值超矢量的维度非常高,一般情况都会高达上万维,会有一定程度的冗余信息存在,为此我们需要使用因子分析对其进行降维,提取具有区分性的特征。
三、因子分析的简介
信息冗余是高维数据分析常见的问题,使用因子分析方法,可以将一些信息重叠和复杂的关系变量简化为较少的足够描述原有观测信息的几个因子,是一种数据降维的统计方法。本文介绍JFA和I-vector都为因子分析方法。
设P维的观察矢量x可以用n个因子组合得到,它们之间的关系k
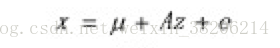
其中,μ为观测矢量x的均值,即E[x] = μ (期望);
矢量z为不可观测的变量,称为隐藏因子;
矩阵A为因子荷载矩阵;
矢量e为误差矢量。
可以理解为,因子分析法认为高维数据样本实际上是由低维数据样本经过线性变化,叠加误差扰动生成的。
另一个版本的因子分析概念


这个版本与第一个版本的公式相同,只是更详细的介绍了因子分析构成原理,从数学的角度而言,更容易看懂。
四、联合因子分析(JFA)
在传统的基于GMM-UBM的识别系统中,由于训练环境和测试环境的失配问题,会导致系统性能不稳定。联合因子分析(Joint Factor Analysis,JFA)认为,说话人的GMM模型的差异信息,是由说话人差异和信道差异这两个不可观测的部分组成的,公式如下:
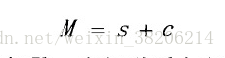
其中,s为说话人相关的超矢量,表示说话人之间的差异;
c为信道相关的超矢量,表示同一个说话人不同语音段的差异;
M为GMM均值超矢量,表述为说话人相关部分s和信道相关部分c的叠加。
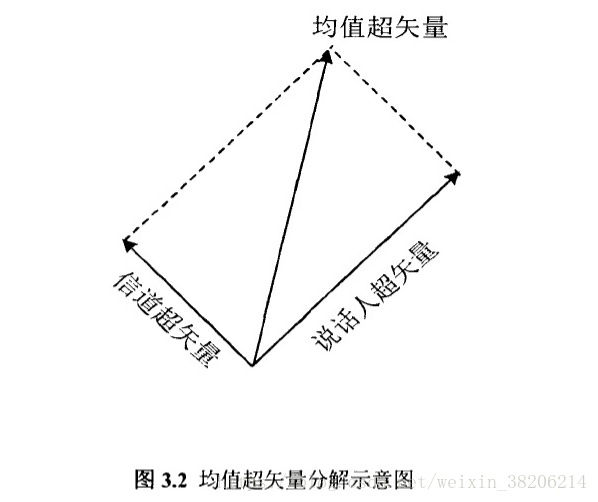
如上图所示,联合因子分析实际上是用GMM超矢量空间的子空间对说话人差异以及信道差异进行建模,从而便可以去除信道的干扰,得到对说话人身份更精确的描述。
JFA定义公式如下:
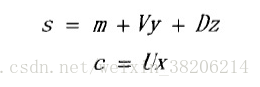
其中,s为说话人相关的超矢量,表示说话人之间的差异;
m为与说话人以及信道无关的均值超矢量;
V为低秩的本征音矩阵;
y为说话人相关因子;
D为对角的残差矩阵;
z为残差因子;
c为信道相关的超矢量,表示同一个说话人不同语音段的差异;
U为本征信道矩阵;
x为与特定说话人的某一段语音相关的因子。
这里的超参数集合{V,D,U}即为需要评估的模型参数。
有了上面的定义公式,我们可以将均值超矢量重新改写为如下形式:
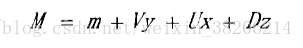
为了得到JFA模型的超参数,我们可以使用EM算法训练出UBM模型,使用UBM模型提取Baum-Welch统计量。具体的计算可以参考论文:话者确认中信道和时长失配补偿研究_胡群威
五、I-Vector矢量
JFA(联合因子分析)方法的思想是使用GMM超矢量空间的子空间对说话人差异和信道差异分别建模,从而可以方便的分类出信道干扰。然而,Dehak注意到,在JFA模型中,信道因子中也会携带部分说话人的信息,在进行补偿时,会损失一部分说话人信息。所以Dehak提出了全局差异空间模型,将说话人差异和信道差异作为一个整体进行建模。这种方法改善了JFA对训练语料的要求,和计算复杂度高的问题,同时性能也与JFA相当,逐渐流行起来。
给定说话人的一段语音,与之对应的高斯均值超矢量可以定义为如下:
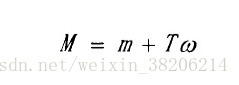
其中,M为给定语音的高斯均值超矢量;
m为通用背景模型(UBM)的高斯均值超矢量,该超矢量与具体说话人以及信道无关;
T为全局差异空间矩阵,低秩;
w为全局差异空间因子,它的后验均值,即为I-Vector矢量,它先验地服从标准正态分布。
相对于JFA而言,I-Vector的计算量大大降低,可以应对大规模数据,同时因为I-Vector本身具有不错的跨信道能力和PLDA信道补偿法的引入,I-Vector对信道的鲁棒性也比JFA更好。
六、I-Vector的矩阵估计过程
在给定的公式(如下)中,M和m是我们可以计算的出的,而全局差异空间矩阵(T)和全局差异空间因子(w)是我们需要估计的,接下来为大家介绍以下这两个参数的估计方法。
1、全局差异空间矩阵T的估计
全局差异空间矩阵(T)认为所有给定的数据都来自不同的说话人,即使是一个说话人的多段语音也同样认为是来自不同人。
估计步骤如下:
计算每个说话人对应的Baum-Welch统计量
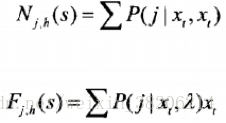
在后续计算中需要用到的Baum-Welch的一阶中心统计量
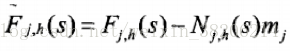
为了方便计算,可以将统计量扩展为矩阵形式:
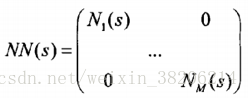
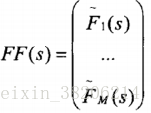
通过上式计算每一段语音的Baum-Welch统计量,使用EM算法迭代进行T矩阵的训练:
1> 训练之前,先对T矩阵进行随机初始化;
2> E步骤:计算说话人因子的方差和均值
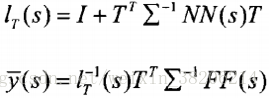
3> M步骤:进行最大似然值重新估计
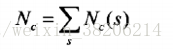
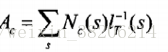
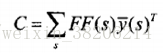
并对所有语音,更新模型参数矩阵T
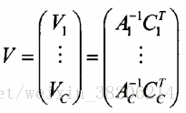
4> 按照上述算法步骤,不断重复2>,3>步骤,循环迭代,直到达到终止条件,最后得到最终的模型参数,即为全局差异空间矩阵T,一般迭代次数在10次左右。
2、全局差异空间因子w的估计
I-Vector矢量定义为全局差异空间因子w的极大后验点估计,也就是隐藏因子w的后验均值。我们在估计获得全局差异空间矩阵T后,对给定的说话人的一句话,先提取零阶、一阶Baum-Welch统计量(在T矩阵估计中已提取),即可计算I-Vector的估计值,公式如下:
![]()
如果目标说话人的语音有h条,通过上述公式可以获得h条I-Vector矢量,一般情况下I-Vector的维度在400-600之间。该矢量可以代表说话人的身份,具有较强的区分性,而且维度相对较低,可以大幅减少计算量。
总结而言:
JFA因子分析是对于GMM-UBM系统框架,在信道干扰方面提出的一个解决方案,通过分别建模并信道补偿的方法,消除信道的干扰。而I-Vector是对JFA因子分析训练语料要求高,计算复杂的一个解决方案,在整体建模的情况下,使用UBM+对应语音的特定因子的方式,对每一段语音进行补偿。
本人的一些理解,说的不一定对,大家可以跳过:
在声纹识别的进化史中,可以看到前辈们是通过一个又一个的解决方案,把声纹识别这个难题解决掉。从GMM的语料不够,提出UBM;在GMM-UBM中,又发现了信道干扰,于是提出JFA;在JFA的计算复杂和语料不够的情况下,提出了I-Vector。让我真实的看到了声纹识别的进步是多么的曲折艰难,也看到了前辈们的努力和汗水。话不多说,大家一起加油吧!

















 7406
7406

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









