









KETTLE中的组件都试过了不能解析公司财务提供数据文件。按照网络爬虫思路利用htmlparser包解决了表格解析问题。
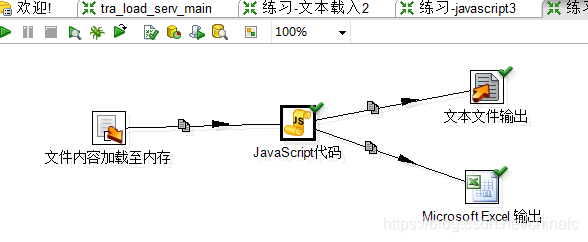

JAVASCRIPT脚本如下:
/***解析HTML信息表格***/
trans_Status = SKIP_TRANSFORMATION;
var Parser= org.htmlparser.Parser;
var TagNameFilter = org.htmlparser.filters.TagNameFilter;
var HasAttributeFilter = org.htmlparser.filters.HasAttributeFilter;
var AndFilter = org.htmlparser.filters.AndFilter;
var NodeList = org.htmlparser.util.NodeList;
//从上级获取html数据流
var parser = new Parser(FileContent); //FileContent为输入参数
var index = getInputRowMeta().size();
var filterTable = new AndFilter(new TagNameFilter("table"),new HasAttributeFilter("id","excel_table"));
var filterTr = new TagNameFilter("tr");
var filterTd = new TagNameFilter("td");
//取得表格NodeList
var tables = parser.parse(filterTable);
for( j=0;j<tables.size();j++){
//取得行NodeList
var rows =tables.elementAt(j).getChildren();
rows.keepAllNodesThatMatch(filterTr);
for ( i = 0; i < rows.size(); i++) {
var cells =rows.elementAt(i).getChildren();
cells.keepAllNodesThatMatch(filterTd);
//输出行处理
var row = createRowCopy(getOutputRowMeta().size());
row[0]="";//输入行信息清空,不然每行都显示原文内容
for (k=0;k<cells.size();k++){
row[index+k] = cells.elementAt(k).toPlainTextString();
}
//输出行
putRow(row);
}
}















 711
711











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









