







 本文介绍了在面对亿级数据量表时,如何手动实现水平分表。首先,理解了Sharding-jdbc的原理,但因其不满足预期功能而放弃使用。接着,通过代码生成创建了144个分表,每个存储500万条数据。然后,利用Mybatis和批处理进行数据迁移,通过用户ID取模确定插入目标表。最后,详细阐述了分表查询的实现方式,包括Mapper接口、XML文件和服务的编写。
本文介绍了在面对亿级数据量表时,如何手动实现水平分表。首先,理解了Sharding-jdbc的原理,但因其不满足预期功能而放弃使用。接着,通过代码生成创建了144个分表,每个存储500万条数据。然后,利用Mybatis和批处理进行数据迁移,通过用户ID取模确定插入目标表。最后,详细阐述了分表查询的实现方式,包括Mapper接口、XML文件和服务的编写。
技术框架
Mybatis
背景
要处理一张亿级数据量的表,它有两个字段,分别为userId和PhoneNumber,两个字段数据都为数字,类型为varchar。而一个userId可以有多个PhoneNumber,因此注定了limit1,1这种语句优化是无效的。
在当前一亿数据量的情况下,一个WHERE查询要花费5分钟,并且加索引也是无效的。
此时想到了分表,并且显而易见的要采取水平分表方案。
可是分表到底要怎么分?在这之前只是听到过,但具体不知道如何实现。
经过建议,知道了可以用sharding-jdbc框架来实现水平分表,水平分库,以及垂直分表,垂直分库,于是前去了解。
Sharding-jdbc的原理
可是对于Shrding-jdbc进行了了解后,这与我设想中的框架功能出现偏差。
偏差主要有以下几点:
第一,我预想中的框架能够自动地把这张亿级数据量表,水平分割成若干个表;然而经过了解后,这个框架并不能对表进行分割,只能在已经分割后的基础上进行分表分库的增删改。
第二,我预想中,该框架的分表查询应该是类似于多核并行的方式对数据库进行查询。然而经过了解后,这个框架实现的机制也只是单核单线程查询,而它的重点在思路。
第三,接上,研究了下Sharding-jdbc分表查询的思路后,发现其实我们自己也能够手写实现,而且并不费力气,那就是Sharding-jdbc是根据一个表字段(传递给Mapper的参数)的某个值的规律去决定更新/查询某张数据表。
这里我给大家发一个Sharding-jdbc的原理介绍图,各位自己参考:



所以你明白了吗?问题并不是出在Sharding-jdbc,而是我对于分表,分库这个概念,一直以为是很高大上的,涉及到并行处理的概念,但是经过阅读了Sharding-jdbc的原理后,才对分表分库的查询有了一定的认识。 就比如上面这张图中的原理,重点在于参数,也就是把参数计算为某个特定的数值,从而根据数值来决定去添加或查询哪张表。
放弃使用ShardingJdbc,手工进行。
所以,我觉得既然了解了原理,那就不用框架了,况且我也仅仅是实现分表需求,我决定自己写代码实现。
水平分表业务实现
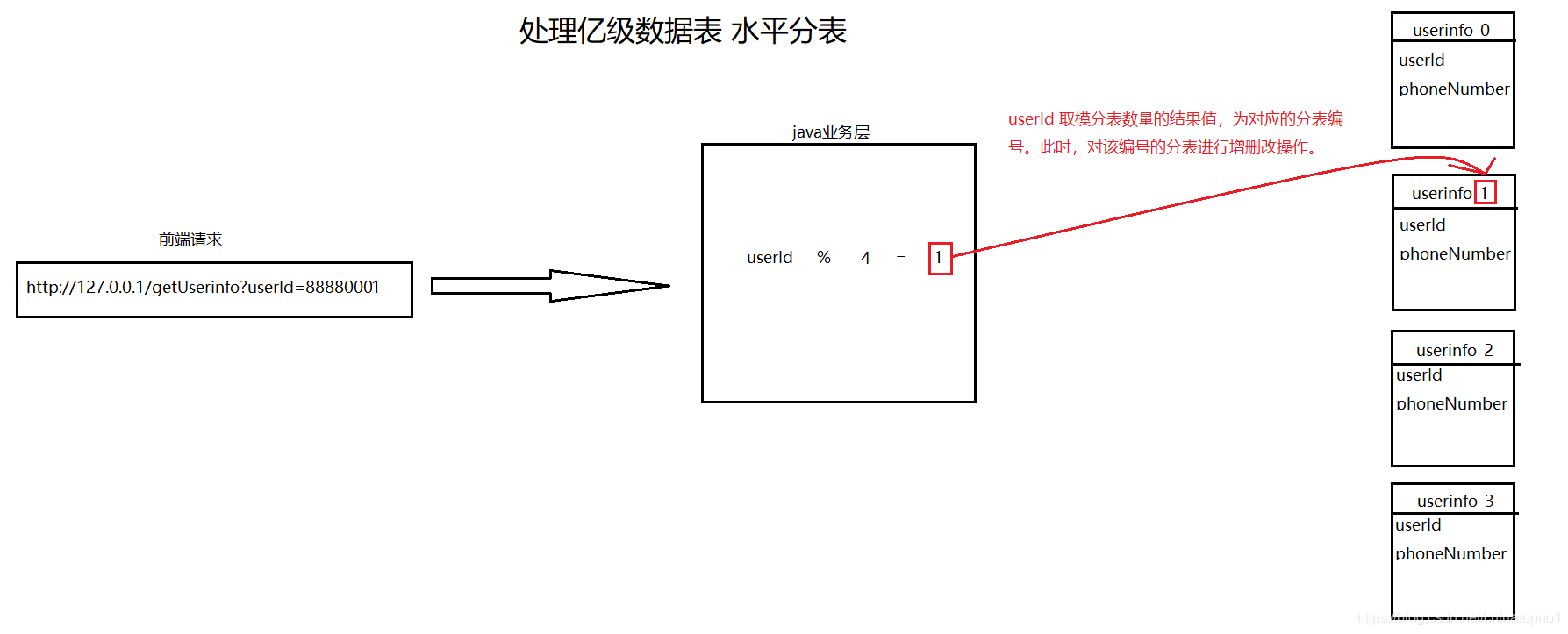
一.水表拆分(创建若干个表)
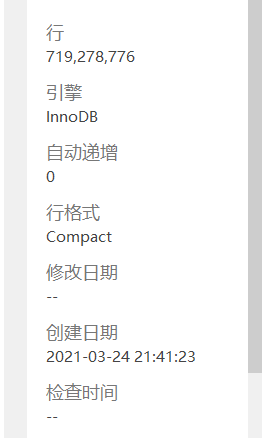
首先我们可以看到,这张表有7亿条数据。那么我想每个表存500万条,这样只有500万条的话,那么查询时速度就会快很多。那么上图的数字除以500万就是接近144了。那么我们就决定创建144张表。
怎么创建呢?当然是手动,不过分表的创建语句还是要靠代码生成。
@Test
void contextLoads() {
for (int i = 0; i < 144; i++) {
String createStr = "CREATE TABLE `userinfo_"+i+"` (\n" +
" `userid` varbinary(12) NULL DEFAULT NULL,\n" +
" `PhoneNumber` varchar(16) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL\n" +
") ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = COMPACT;";
System.out.println(createStr);
}
}
二.实现分表数据迁移业务
首先,我们的亿万级别主表的名字叫做 userinfo,我们为它准备了144个水平分表,分别是从userinfo_0到到userinfo_143。
表结构中,有两个字段。分别为userId和PhoneNumber,两个字段数据都为数字,类型为varchar。
而既然要往若干个表里面添加数据,我们就需要从userinfo表取得数据。
因为打算分散开,为每个表存储500万条,因此借助mybatis和for循环,每次分页查询500万条数据。随后根据userid取模144得出的结果值,来决定添加到哪个表(即:userinfo_#{tableNum})
编辑Mapper接口
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1261
1261

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









