







上一篇文章:跟乐乐学ES!(二)ElasticSearch基础。
下一篇文章:跟乐乐学ES!(四) java中ElasticSearch客户端的使用。
批量操作
有些增删改查操作是可以进行批量操作的,以此来达到节省网络请求的目的。
对于批量操作的请求格式,是由action和request body 这两种Json来组合完成的。
格式如下:
{ action: { metadata }}
{ request body }
{ action: { metadata }}
{ request body }
关于action和request body的格式和意义,直接发上述的格式文本大家可能看不懂,那么我以批量添加的json截图为例子,便于理解,截图如下:

准备数据

批量查询
url后面加上 ‘_mget’
POST方式:localhost:9200/索引名/类型名/_mget
例如:
{
"ids":["1","2","3"]
}
解释:
批量查询类型中id为’1’和’2’的文档。
结果:
{
"docs": [
{
"_index": "userinfo",
"_type": "us",
"_id": "1",
"_version": 3,
"_seq_no": 4,
"_primary_term": 1,
"found": true,
"_source": {
"query": {
"match": {
"phonenumber": 150
}
},
"address": "南京",
"name": "张三",
"phonenumber": "13000000001",
"softid": "9999",
"age": 23
}
},
{
"_index": "userinfo",
"_type": "us",
"_id": "2",
"_version": 1,
"_seq_no": 1,
"_primary_term": 1,
"found": true,
"_source": {
"softid": 9998,
"name": "李四",
"phonenumber": 15000000000,
"age": 18,
"address": "南京"
}
},
{
"_index": "userinfo",
"_type": "us",
"_id": "3",
"found": false
}
]
}
值得注意的是,id为3的文档并不存在,因此在第三列的结果中found的值为false。
所以当你批量查询的目标中,存在一个不存在的文档,es会响应相应的json数据来告诉你。
批量插入 _bulk
批量插入的action有三种,分别为Update/Create/Index
三者的区别可以参考这里:https://blog.csdn.net/xiaoyu_BD/article/details/81914567
post方式: localhost:9200/索引/类型/_bulk
OR.create方式插入
json请求体:

{"create":{"_index":"userinfo","_type":"us","_id":"5"}} # 将地址为滨松,姓名为三好炎男的文档,创建到'userinfo'索引的'us'类型中,id为5.
{"address":"滨松","name":"三好炎男","phonenumber":"08026073443","softid":"9996","age":17}
{"create":{"_index":"userinfo","_type":"us","_id":"6"}}
{"address":"洛阳","name":"乐乐","phonenumber":"13000000002","softid":"9995","age":24}
{"create":{"_index":"userinfo","_type":"us","_id":"7"}}
{"address":"北京","name":"孔德明","phonenumber":"13000000003","softid":"9994","age":20}
注意:最后一行必须为换行符空出来的一行,不然es无法识别。
结果:
{
"took": 99,
"errors": false,
"items": [
{
"create": {
"_index": "userinfo",
"_type": "us",
"_id": "5",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 5,
"_primary_term": 2,
"status": 201
}
},
{
"create": {
"_index": "userinfo",
"_type": "us",
"_id": "6",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 6,
"_primary_term": 2,
"status": 201
}
},
{
"create": {
"_index": "userinfo",
"_type": "us",
"_id": "7",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 7,
"_primary_term": 2,
"status": 201
}
}
]
}

OR.index方式插入
json请求体:
# 127.0.0.1:9200/mytest/_doc/_bulk
{"index":{"_index":"mytest","_type":"_doc"}}
{"address":"洛阳","age":24,"name":"乐乐","regtime":"2021-04-20","sex":true,"userid":1}
{"index":{"_index":"mytest","_type":"_doc"}}
{"address":"南京","age":18,"name":"张三","regtime":"2021-01-30","sex":true,"userid":2}
{"index":{"_index":"mytest","_type":"_doc"}}
{"address":"北京","age":21,"name":"李桂花","regtime":"2020-12-02","sex":false,"userid":3}
{"index":{"_index":"mytest","_type":"_doc"}}
{"address":"郑州","age":19,"name":"王翠英","regtime":"2021-03-21","sex":false,"userid":4}
{"index":{"_index":"mytest","_type":"_doc"}}
{"address":"北京","age":22,"name":"李斌","regtime":"2020-08-12","userid":5}
注意:最后一行必须为换行符空出来的一行,不然es无法识别。
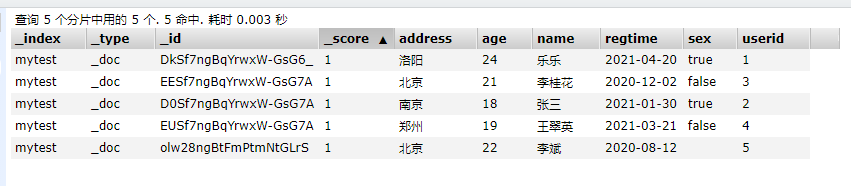
批量删除
此处的话,需要将’create‘改为delete,即可实现批量删除。
post方式: localhost:9200/索引/类型/_bulk
json请求体示例:

{"delete":{"_index":"userinfo","_type":"us","_id":"5"}}
{"delete":{"_index":"userinfo","_type":"us","_id":"6"}}
{"delete":{"_index":"userinfo","_type":"us","_id":"7"}}
注意:批量删除时,同样需要最后一行为换行符。
结果:
{
"took": 44,
"errors": false,
"items": [
{
"delete": {
"_index": "userinfo",
"_type": "us",
"_id": "5",
"_version": 2,
"result": "deleted",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 8,
"_primary_term": 2,
"status": 200
}
},
{
"delete": {
"_index": "userinfo",
"_type": "us",
"_id": "6",
"_version": 2,
"result": "deleted",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 9,
"_primary_term": 2,
"status": 200
}
},
{
"delete": {
"_index": "userinfo",
"_type": "us",
"_id": "7",
"_version": 2,
"result": "deleted",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 10,
"_primary_term": 2,
"status": 200
}
}
]
}

分页查询
在ElasticSearch中,分页查询用size和from两个参数来表示。对应着sql中的limit。
get方式: localhost:9200/索引/类型/_search?size=每页显示条数&from=从第几个开始
size代表每页显示多少个。
from代表跳过几条文档再开始查找,起始值为0。
例如:
127.0.0.1:9200/userinfo/us/_search?size=3&from=0
结果:
{
"took": 10,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 3,
"relation": "eq"
},
"max_score": 1.0,
"hits": [
{
"_index": "userinfo",
"_type": "us",
"_id": "JMHW53gBu0CFfFx2dazM",
"_score": 1.0,
"_source": {
"softid": 9997,
"name": "王五",
"phonenumber": 15000000001,
"age": 20,
"address": "北京"
}
},
{
"_index": "userinfo",
"_type": "us",
"_id": "2",
"_score": 1.0,
"_source": {
"softid": 9998,
"name": "李四",
"phonenumber": 15000000000,
"age": 18,
"address": "南京"
}
},
{
"_index": "userinfo",
"_type": "us",
"_id": "1",
"_score": 1.0,
"_source": {
"query": {
"match": {
"phonenumber": 150
}
},
"address": "南京",
"name": "张三",
"phonenumber": "13000000001",
"softid": "9999",
"age": 23
}
}
]
}
}
深度分页的注意事项。

应该当心分页太深或者一次请求太多的结果。结果在返回前会被排序。但是记住一个搜索请求常常涉及多个分
片。每个分片生成自己排好序的结果,它们接着需要集中起来排序以确保整体排序正确。
为了理解为什么深度分页是有问题的,让我们假设在一个有5个主分片的索引中搜索。当我们请求结果的第一
页(结果1到10)时,
每个分片产生自己最顶端10个结果然后返回它们给请求节点(requesting node),它再排序这所有的50个结果以选出顶端的10个结果。
现在假设我们请求第1000页,需要显示的结果为1001行到1010行的文档。
那么和请求前面10个结果时一样,这时会相应的、每个分片都必须产生顶端的1010个结果,然后请求节点排序这5050个结果并丢弃5040个!
所以在分布式系统中,排序结果的花费随着分页的深入而成倍增长。
这也是为什么网络搜索引擎中任何语句不能返回多于1000个结果的原因。
换而言之,我们在分页查询时,每页的查询数量(size)不应该太多。
结构化查询
准备数据

固定请求格式:
post方式:localhost:9200/索引名/类型名/_search
term查询(精准匹配)
term 主要用于精确匹配哪些值,比如数字,日期,布尔值或 not_analyzed 的字符串(未经分析的文本数据类型)
post方式:localhost:9200/索引名/类型名/_search
127.0.0.1:9200/mytest/_doc/_search
示例:
{
"query":{
"term":{
"name":"乐乐"
}
}
}
结果:
{
"took": 10,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.6931471,
"hits": [
{
"_index": "mytest",
"_type": "_doc",
"_id": "DkSf7ngBqYrwxW-GsG6_",
"_score": 0.6931471,
"_source": {
"address": "洛阳",
"age": 24,
"name": "乐乐",
"regtime": "2021-04-20",
"sex": true,
"userid": 1
}
}
]
}
}
terms查询(多个值精确匹配)
terms是term的加强版。term只可以对一个字段进行指定单个值来匹配,而terms可以对一个字段指定多个值来匹配。
如果指定的多个值当中,有的值并不能匹配到某行文档,那将只会响应匹配到的那些结果。
示例:
{
"query":{
"terms":{
"age":[18,19,22] # 年龄为22的用户并不存在
}
}
}
结果:
{
"took": 13,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1.0,
"hits": [
{
"_index": "mytest",
"_type": "_doc",
"_id": "D0Sf7ngBqYrwxW-GsG7A",
"_score": 1.0,
"_source": {
"address": "南京",
"age": 18,
"name": "张三",
"regtime": "2021-01-30",
"sex": true,
"userid": 2
}
},
{
"_index": "mytest",
"_type": "_doc",
"_id": "EUSf7ngBqYrwxW-GsG7A",
"_score": 1.0,
"_source": {
"address": "郑州",
"age": 19,
"name": "王翠英",
"regtime": "2021-03-21",
"sex": false,
"userid": 4
}
}
]
}
}
range查询(范围查询)
用于查询范围,当字段的数据类型为数字时,多配合’lt(小于)'和’gt(大于)'来指定。
范围操作符有:
gt 大于
gte 大于等于
lt 小于
lte 小于等于
示例:
{
"query":{
"range":{ # 声明为范围查询
"age":{ # 查询字段age
"gt":20,# 大于
"lt":24 # 小于
}
}
}
}
结果:
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1.0,
"hits": [
{
"_index": "mytest",
"_type": "_doc",
"_id": "EESf7ngBqYrwxW-GsG7A",
"_score": 1.0,
"_source": {
"address": "北京",
"age": 21,
"name": "李桂花",
"regtime": "2020-12-02",
"sex": false,
"userid": 3
}
}
]
}
}
exists非空查询(is not Null)
用于筛选一个类型中,某个字段不为空的所有文档。
相当于sql语法中的 is not Null;
json请求体:
# post:127.0.0.1:9200/mytest/_doc/_search
{
"query":{
"exists":{
"field":"sex" #请求查询,'_doc'类型中,'sex'字段值不为空的文档。
}
}
}
这个exists就相当于以下sql语句:
select * from _doc where sex is not null;
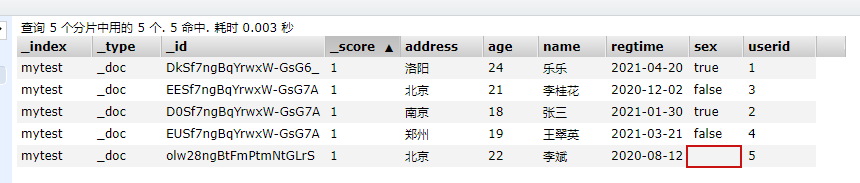
图中我们可以看到,姓名为‘李斌’的这一栏没有写上性别。所以下面的响应结果中就不存在这条文档。
{
"took": 17,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 4,
"relation": "eq"
},
"max_score": 1.0,
"hits": [
{
"_index": "mytest",
"_type": "_doc",
"_id": "DkSf7ngBqYrwxW-GsG6_",
"_score": 1.0,
"_source": {
"address": "洛阳",
"age": 24,
"name": "乐乐",
"regtime": "2021-04-20",
"sex": true,
"userid": 1
}
},
{
"_index": "mytest",
"_type": "_doc",
"_id": "EESf7ngBqYrwxW-GsG7A",
"_score": 1.0,
"_source": {
"address": "北京",
"age": 21,
"name": "李桂花",
"regtime": "2020-12-02",
"sex": false,
"userid": 3
}
},
{
"_index": "mytest",
"_type": "_doc",
"_id": "D0Sf7ngBqYrwxW-GsG7A",
"_score": 1.0,
"_source": {
"address": "南京",
"age": 18,
"name": "张三",
"regtime": "2021-01-30",
"sex": true,
"userid": 2
}
},
{
"_index": "mytest",
"_type": "_doc",
"_id": "EUSf7ngBqYrwxW-GsG7A",
"_score": 1.0,
"_source": {
"address": "郑州",
"age": 19,
"name": "王翠英",
"regtime": "2021-03-21",
"sex": false,
"userid": 4
}
}
]
}
}
match(标准查询)
match是ElasticSearch中一种标准查询,诸如精确查询,模糊查询,全文本(String,text这样的)查询等场景几乎都需要用到它。
只是,如果你使用 match 查询一个全文本字段,它会在真正查询之前用分析器先分析 match 一下查询字符。
例如:
{
"query":{
"match":{
"address":"张三"
}
}
}
如果用match下指定了一个确切值,在遇到数字、日期、布尔值或者 not_analyzed的字符串时,它将为你搜索你给定的值。
例如:
{
"query":{
"match":{
"sex":true
}
}
}
{
"query":{
"match":{
"age":18
}
}
}
过滤查询
使用过滤查询
post方式:localhost:9200/索引名/类型名/_search
过滤查询要比其它查询的效率要高。
match,term,range等可以用在过滤查询之中。
# post:127.0.0.1:9200/mytest/_doc/_search
{
"query":{
"bool":{ # 定义条件
"filter":{ # 声明使用过滤查询
"match":{ # 查询方式
"address":"北京"
}
}
}
}
}
结果:
{
"took": 9,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 0.0,
"hits": [
{
"_index": "mytest",
"_type": "_doc",
"_id": "EESf7ngBqYrwxW-GsG7A",
"_score": 0.0,
"_source": {
"address": "北京",
"age": 21,
"name": "李桂花",
"regtime": "2020-12-02",
"sex": false,
"userid": 3
}
},
{
"_index": "mytest",
"_type": "_doc",
"_id": "olw28ngBtFmPtmNtGLrS",
"_score": 0.0,
"_source": {
"address": "北京",
"age": 22,
"name": "李斌",
"regtime": "2020-08-12",
"userid": 5
}
}
]
}
}
为什么过滤语句比查询语句好?

- 一条过滤语句会询问每个文档的字段值是否包含着特定值。
- 查询语句会询问每个文档的字段值与特定值的匹配程度如何
- 一条查询语句会计算每个文档与查询语句的相关性,会给出一个相关性评分 _score,并且 按照相关性对匹配到的文档进行排序。 这种评分方式非常适用于一个没有完全配置结果的全文本搜索。
- 一个简单的文档列表,快速匹配运算并存入内存是十分方便的, 每个文档仅需要1个字节。这些缓存的过滤结果集与后续请求的结合使用是非常高效的。
- 查询语句不仅要查找相匹配的文档,还需要计算每个文档的相关性,所以一般来说
查询语句要比过滤语句更耗时,并且查询结果也不可缓存。 - 建议:
做精确匹配搜索时,最好用过滤语句,因为过滤语句可以缓存数据。
分词
什么是分词?
分词就是对于一个句子,根据词汇等规则把整个句子分为多个单词。
也叫做文本分析,在ElasticSearch中称之为Analysis。
例如:
我昨天吃完晚饭就去直接睡觉了----> 我/昨天/吃/完/晚饭/就/去/直接/睡觉/了
使用分词
单词‘analyze’在es语法中代表使用分词的意思。
同时,还存在‘分词器’这种概念,这是分词要依照世界各国语言的不同来选择符合各自需求的分词器。
常用的英文分词器有’standard‘标准分词器,它也是es中默认的分词器。
别急,我们先不介绍中文分词器的应用,这里我们举例用英文分词器’standard‘来进行分词。
普通方式分词
post方式: localhost:9200/_analyze
# 127.0.0.1:9200/_analyze
{
"analyzer":"standard",# 指定分词器为标准分词器'standard'
"text":"you are hero"# 要分词的内容本文。
}
结果:
{
"tokens": [
{
"token": "you",
"start_offset": 0,
"end_offset": 3,
"type": "<ALPHANUM>",
"position": 0
},
{
"token": "are",
"start_offset": 4,
"end_offset": 7,
"type": "<ALPHANUM>",
"position": 1
},
{
"token": "hero",
"start_offset": 8,
"end_offset": 12,
"type": "<ALPHANUM>",
"position": 2
}
]
}
指定索引进行分词
post方式: localhost:9200/索引名/_analyze
# 127.0.0.1:9200/mytest/_analyze
{
"analyzer":"standard",
"text":"hello world"
}
结果:
{
"tokens": [
{
"token": "hello",
"start_offset": 0,
"end_offset": 5,
"type": "<ALPHANUM>",
"position": 0
},
{
"token": "world",
"start_offset": 6,
"end_offset": 11,
"type": "<ALPHANUM>",
"position": 1
}
]
}
使用中文分词
中文分词的难点就在于不能像英语那样,根据空格来区分句子中的词汇。
常用中文分词器,IK、jieba、THULAC等,我个人推荐使用IK分词器。
ik分词器的介绍
linux环境下安装ik分词器的话,具体参考这篇文章:https://zhuanlan.zhihu.com/p/98845218
windows环境下安装ik分词器的话,具体参考这篇文章:
https://blog.csdn.net/fgx_123456/article/details/108800699
我是windows环境,要注意哦,自己下载的ik分词器版本一定要和自己的ElasticSearch版本相对应

ik分词器的配置与使用。
ik分词器具有多种分词规则。所谓多种分词规则,就是对中文语句具有不同程度的分词粒度。例如k_max_word和ik_smart这两种分词规则。
- k_max_word:会将文本做最细粒度的拆分,例如「中华人民共和国国歌」会被拆分为「中华人民共和国、中华人民、中华、华人、人民共和国、人民、人、民、共和国、共和、和、国国、国歌」,会穷尽各种可能的组合
- ik_smart:会将文本做最粗粒度的拆分,例如「中华人民共和国国歌」会被拆分为「中华人民共和国、国歌」
关于ik分词器的更多配置说明,推荐参考这篇文章:https://www.cnblogs.com/haixiang/p/11810799.html
接下来我们开始尝试中文分词,虽说换了分词器,但是请求方式和url规则是不变的。
示例一:
# 127.0.0.1:9200/mytest/_analyze
{
"analyzer":"ik_max_word",# ik_max_word是ik分词器的一种。
"text":"你确定你说的正确吗"
}
结果:
{
"tokens": [
{
"token": "你",
"start_offset": 0,
"end_offset": 1,
"type": "CN_CHAR",
"position": 0
},
{
"token": "确定",
"start_offset": 1,
"end_offset": 3,
"type": "CN_WORD",
"position": 1
},
{
"token": "你",
"start_offset": 3,
"end_offset": 4,
"type": "CN_CHAR",
"position": 2
},
{
"token": "说",
"start_offset": 4,
"end_offset": 5,
"type": "CN_CHAR",
"position": 3
},
{
"token": "的",
"start_offset": 5,
"end_offset": 6,
"type": "CN_CHAR",
"position": 4
},
{
"token": "正确",
"start_offset": 6,
"end_offset": 8,
"type": "CN_WORD",
"position": 5
},
{
"token": "吗",
"start_offset": 8,
"end_offset": 9,
"type": "CN_CHAR",
"position": 6
}
]
}
示例二:
{
"analyzer":"ik_smart",# 此处选择ik_smart规则来进行分词
"text":"我希望世界大同,人类幸福安康"
}
结果:
{
"tokens": [
{
"token": "我",
"start_offset": 0,
"end_offset": 1,
"type": "CN_CHAR",
"position": 0
},
{
"token": "希望",
"start_offset": 1,
"end_offset": 3,
"type": "CN_WORD",
"position": 1
},
{
"token": "世界大同",
"start_offset": 3,
"end_offset": 7,
"type": "CN_WORD",
"position": 2
},
{
"token": "人类",
"start_offset": 8,
"end_offset": 10,
"type": "CN_WORD",
"position": 3
},
{
"token": "幸福",
"start_offset": 10,
"end_offset": 12,
"type": "CN_WORD",
"position": 4
},
{
"token": "安康",
"start_offset": 12,
"end_offset": 14,
"type": "CN_WORD",
"position": 5
}
]
}
全文搜索(分词字段)
概念
关于全文搜索,标准化的解释如下:
- 相关性( Relevance) 它是评价查询与其结果间的相关程度,并根据这种相关程度对结果排名的一种能力,这 种计算方式可以是 TF/IDF 方法、地理位置邻近、模糊相似,或其他的某些算法。
- 分词( Analysis) 它是将文本块转换为有区别的、规范化的 token 的一个过程,目的是为了创建倒排索引以及 查询倒排索引。
那么通俗地来解释的话,就是在创建索引时,为其某个字段指定一个分词器,让该字段能够被分词查询,且该字段的值普遍是句子或多个词汇组成的。
准备数据
创建结构化索引,这个索引中的‘suitableCrowd’(适宜人群)字段被指定了中文分词器,分词规则为最细分词粒度的k_max_word
# put:127.0.0.1:9200/medical 创建索引 ‘医疗’
{
"settings":{
"index":{
"number_of_shards":"5",# 分片数量为5
"number_of_replicas":"0"# 副本数量为0
}
},
"mappings":{
"properties":{
"id":{ # id字段
"type":"integer"
},
"medicalName":{ # 医疗名称字段
"type":"keyword"
},
"suitableCrowd":{ # 适宜人群字段 ,因为适宜人群可以是一个或多个,所以此处为其绑定了ik中文分词器
"type":"text",
"analyzer":"ik_max_word"
},
"medicalType":{ # 医疗类型
"type":"keyword"
}
}
}
}
插入数据
# post:127.0.0.1:9200/medical/_bulk
{"index":{"_index":"medical","_type":"_doc"}}
{"id":1,"medicalName":"新冠疫苗","suitableCrowd":"老人,青少年,儿童","medicalType":"针剂"}
{"index":{"_index":"medical","_type":"_doc"}}
{"id":2,"medicalName":"褪黑素组合片","suitableCrowd":"老人,青少年","medicalType":"内服"}
{"index":{"_index":"medical","_type":"_doc"}}
{"id":3,"medicalName":"妇炎洁","suitableCrowd":"女性","medicalType":"外用"}
{"index":{"_index":"medical","_type":"_doc"}}
{"id":4,"medicalName":"跌打镇痛膏","suitableCrowd":"老人,青少年,儿童","medicalType":"外用"}
{"index":{"_index":"medical","_type":"_doc"}}
{"id":5,"medicalName":"清热解毒胶囊","suitableCrowd":"青少年,儿童","medicalType":"内服"}


单词搜索
# post:127.0.0.1:9200/medical/_search
{
"query":{
"match":{
"suitableCrowd":"儿童"
}
}
}
结果:
{
"took": 16,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 3,
"relation": "eq"
},
"max_score": 0.41360325,
"hits": [
{
"_index": "medical",
"_type": "_doc",
"_id": "3G56_XgB2_2kwSyJeq2Q",
"_score": 0.41360325,
"_source": {
"id": 1,
"medicalName": "新冠疫苗",
"suitableCrowd": "老人,青少年,儿童",
"medicalType": "针剂"
}
},
{
"_index": "medical",
"_type": "_doc",
"_id": "3256_XgB2_2kwSyJeq2T",
"_score": 0.41360325,
"_source": {
"id": 4,
"medicalName": "跌打镇痛膏",
"suitableCrowd": "老人,青少年,儿童",
"medicalType": "外用"
}
},
{
"_index": "medical",
"_type": "_doc",
"_id": "4G56_XgB2_2kwSyJeq2T",
"_score": 0.2876821,
"_source": {
"id": 5,
"medicalName": "清热解毒胶囊",
"suitableCrowd": "青少年,儿童",
"medicalType": "内服"
}
}
]
}
}
解释:
搜索出适用范围(suitableCrowd)包括小孩的医疗产品。
过程说明:
- 检查字段类型
suitableCrowd 字段是一个 text 类型( 指定了IK分词器),这意味着查询字符串本身也应该被分词。 - 分析查询字符串 。
将查询的字符串 “儿童” 传入IK分词器中,输出的结果是单个项 儿童。因为只有一个单词项,所以 match 查询执行的是单个底层 term 查询。 - 查找匹配文档 。
用 term 查询在倒排索引中查找 “suitableCrowd” 然后获取一组包含该项的文档,本例的结果是文档:1,2,3 - 为每个文档评分。用term查询计算每个文档相关度评分 _score,这是种将词频(term frequency,即词“儿童”在相关文档的suitableCrowd字段中出现的频率)和 反向文档频率(inverse document frequency,即词 “儿童” 在所有文档的 suitableCrowd字段中出现的频率),以及字段的长度(即字段越短相关度越高)相结合的计算方式。
多词搜索
多词搜索是指对某个字段指定多个分词来搜索。
OR形式
# post:127.0.0.1:9200/medical/_search
{
"query":{
"match":{# match是标准查询,你也可以换为term。
"suitableCrowd":"儿童 青少年"# 指定搜索该字段中包含‘儿童’或‘青少年’的文档
}
}
}
结果:
{
"took": 17,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 4,
"relation": "eq"
},
"max_score": 1.2408097,
"hits": [
{
"_index": "medical",
"_type": "_doc",
"_id": "3G56_XgB2_2kwSyJeq2Q",
"_score": 1.2408097,
"_source": {
"id": 1,
"medicalName": "新冠疫苗",
"suitableCrowd": "老人,青少年,儿童",
"medicalType": "针剂"
}
},
{
"_index": "medical",
"_type": "_doc",
"_id": "3256_XgB2_2kwSyJeq2T",
"_score": 1.2408097,
"_source": {
"id": 4,
"medicalName": "跌打镇痛膏",
"suitableCrowd": "老人,青少年,儿童",
"medicalType": "外用"
}
},
{
"_index": "medical",
"_type": "_doc",
"_id": "4G56_XgB2_2kwSyJeq2T",
"_score": 0.8630463,
"_source": {
"id": 5,
"medicalName": "清热解毒胶囊",
"suitableCrowd": "青少年,儿童",
"medicalType": "内服"
}
},
{
"_index": "medical",
"_type": "_doc",
"_id": "3W56_XgB2_2kwSyJeq2T",
"_score": 0.5753642,
"_source": {
"id": 2,
"medicalName": "褪黑素组合片",
"suitableCrowd": "老人,青少年",
"medicalType": "内服"
}
}
]
}
}
我们可以看到,产品‘褪黑素组合片’,中包含有‘青少年’;‘清热解毒胶囊’包含有’儿童‘。所以他们都被归纳为结果响应过来了。
AND形式(operator)
如果我们想要查询suitableCrowd字段既包含’青少年‘,又包含’儿童‘的文档。那么就需要用到AND形式。
在ElasticSearch中,我们可以通过operator来指定词与词之间的逻辑关系。
# post:127.0.0.1:9200/medical/_search
{
"query":{
"match":{
"suitableCrowd":{# 查询suitableCrowd字段
"query":"青少年 儿童",# 通过query指定要匹配的词
"operator":"and"# 通过operator来指定逻辑关系,是and还是or或是其它
}
}
}
}
结果:
{
"took": 14,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 3,
"relation": "eq"
},
"max_score": 1.2408097,
"hits": [
{
"_index": "medical",
"_type": "_doc",
"_id": "3G56_XgB2_2kwSyJeq2Q",
"_score": 1.2408097,
"_source": {
"id": 1,
"medicalName": "新冠疫苗",
"suitableCrowd": "老人,青少年,儿童",
"medicalType": "针剂"
}
},
{
"_index": "medical",
"_type": "_doc",
"_id": "3256_XgB2_2kwSyJeq2T",
"_score": 1.2408097,
"_source": {
"id": 4,
"medicalName": "跌打镇痛膏",
"suitableCrowd": "老人,青少年,儿童",
"medicalType": "外用"
}
},
{
"_index": "medical",
"_type": "_doc",
"_id": "4G56_XgB2_2kwSyJeq2T",
"_score": 0.8630463,
"_source": {
"id": 5,
"medicalName": "清热解毒胶囊",
"suitableCrowd": "青少年,儿童",
"medicalType": "内服"
}
}
]
}
}
组合搜索
组合搜索就是说将多种条件规则用于分词字段。
以下举例中使用到的must,must_not这二个条件不代表所有组合用法,我们仅仅是将这二个条件组合在一起来演示组合搜索。
# post:127.0.0.1:9200/medical/_search
{
"query":{
"bool":{# bool 多条件
"must":{ # must 必须包含
"match":{
"suitableCrowd":"儿童"
}
},
"must_not":{ # must_not 必须不包含
"match":{
"suitableCrowd":"老人"
}
}
}
}
}
结果:
{
"took": 33,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.2876821,
"hits": [
{
"_index": "medical",
"_type": "_doc",
"_id": "4G56_XgB2_2kwSyJeq2T",
"_score": 0.2876821,
"_source": {
"id": 5,
"medicalName": "清热解毒胶囊",
"suitableCrowd": "青少年,儿童",
"medicalType": "内服"
}
}
]
}
}
扩展:
组合搜索还可以使用should来提高相似度。
详情参考:https://blog.csdn.net/chinatopno1/article/details/116061767
权重

权重是一个用数值来表示的概念,在Es中它用’boost‘这个名称来声明。
权重是加在某个查询子句下面的一个属性。
如:
"match": {
"hobby": {
"query": "音乐",
"boost": 10
}
}
权重的数值越大,评分(_score)越高。
那么他们的应用场景是什么呢?
假如用户要在我们的搜索引擎种搜索一种医疗服务,比如正骨按摩。
而有三家提供按摩服务的店家,作为我们的客户给我们掏钱进行竞价排名。分别叫做“百度按摩”,“阿里按摩”,“腾讯按摩”,其中腾讯按摩掏的钱是最多的,阿里其次,百度最次。那么他们的权重就分别依次为100,70,40.
这样一来,当用户搜索’正骨按摩‘时,es搜索出了一大堆和正骨按摩相关的结果,其中就有搜到这三家广告客户提供的服务,那么腾讯按摩的权重为100,意味着评分(_score)也就越高,排名也就越靠前;那么腾讯按摩就排在第一个。
示例:
# post 127.0.0.1:9200/medical/_search
{
"query":{
"bool":{
"must":{# 必须要有suitableCrowd字段值的分词中带有’青少年‘的
"match":{
"suitableCrowd":"青少年"
}
},
"should":[{ # should是有没有搜索到结果都没关系。如果medicalType中有值为’内服‘的,则设置权重。
"match":{
"medicalType":{
"query":"内服",
"boost":10 # 设置权重为10.
}
}
}]
}
}
}
结果:
{
"took": 9,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 4,
"relation": "eq"
},
"max_score": 3.4521847,
"hits": [
{
"_index": "medical",
"_type": "_doc",
"_id": "4G56_XgB2_2kwSyJeq2T",
"_score": 3.4521847,
"_source": {
"id": 5,
"medicalName": "清热解毒胶囊",
"suitableCrowd": "青少年,儿童",
"medicalType": "内服"
}
},
{
"_index": "medical",
"_type": "_doc",
"_id": "3W56_XgB2_2kwSyJeq2T",
"_score": 3.4521847,
"_source": {
"id": 2,
"medicalName": "褪黑素组合片",
"suitableCrowd": "老人,青少年",
"medicalType": "内服"
}
},
{
"_index": "medical",
"_type": "_doc",
"_id": "3G56_XgB2_2kwSyJeq2Q",
"_score": 0.8272065,
"_source": {
"id": 1,
"medicalName": "新冠疫苗",
"suitableCrowd": "老人,青少年,儿童",
"medicalType": "针剂"
}
},
{
"_index": "medical",
"_type": "_doc",
"_id": "3256_XgB2_2kwSyJeq2T",
"_score": 0.8272065,
"_source": {
"id": 4,
"medicalName": "跌打镇痛膏",
"suitableCrowd": "老人,青少年,儿童",
"medicalType": "外用"
}
}
]
}
}
我们可以看到,medicalType为内服的被设置了权重10,所以他们的排名都靠在前面。且评分(_score)都为3.4521847。
。
如果不设置权重的话,虽然依据匹配他们还是排名靠前,但是评分(score)不会那么高。
例如:
# 127.0.0.1:9200/medical/_search
{
"query":{
"bool":{
"must":{
"match":{
"suitableCrowd":"青少年"
}
},
"should":[{
"match":{
"medicalType":{
"query":"内服"
}
}
}]
}
}
}
结果:
{
"took": 5,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 4,
"relation": "eq"
},
"max_score": 0.8630463,
"hits": [
{
"_index": "medical",
"_type": "_doc",
"_id": "4G56_XgB2_2kwSyJeq2T",
"_score": 0.8630463,
"_source": {
"id": 5,
"medicalName": "清热解毒胶囊",
"suitableCrowd": "青少年,儿童",
"medicalType": "内服"
}
},
{
"_index": "medical",
"_type": "_doc",
"_id": "3W56_XgB2_2kwSyJeq2T",
"_score": 0.8630463,
"_source": {
"id": 2,
"medicalName": "褪黑素组合片",
"suitableCrowd": "老人,青少年",
"medicalType": "内服"
}
},
{
"_index": "medical",
"_type": "_doc",
"_id": "3G56_XgB2_2kwSyJeq2Q",
"_score": 0.8272065,
"_source": {
"id": 1,
"medicalName": "新冠疫苗",
"suitableCrowd": "老人,青少年,儿童",
"medicalType": "针剂"
}
},
{
"_index": "medical",
"_type": "_doc",
"_id": "3256_XgB2_2kwSyJeq2T",
"_score": 0.8272065,
"_source": {
"id": 4,
"medicalName": "跌打镇痛膏",
"suitableCrowd": "老人,青少年,儿童",
"medicalType": "外用"
}
}
]
}
}

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









