







Tuple(T1, T2, …)
元素元组,每个元素都有一个单独的类型。元组必须至少包含一个元素。
元组用于临时列分组。在查询中使用IN表达式时,以及指定lambda函数的某些形式参数时,可以对列进行分组。有关更多信息,请参阅IN操作符和高阶函数部分。
元组可以是查询的结果。在这种情况下,对于JSON以外的文本格式,值在括号中以逗号分隔。在JSON格式中,元组作为数组输出(在方括号中)。
FixedString(N)
固定长度的N字节字符串(既不是字符也不是码点)。
要声明FixedString类型的列,请使用以下语法:
<column_name> FixedString(N)
Map(key, value)
Map(key, value) 数据类型存储 key:value 键值对。
Date
自1970-01-01以来的天数存储在两个字节中(unsigned)。允许在Unix时代开始后将值存储到编译阶段的常量(目前,这是在2149年之前,但最终完全支持的年份为2148)。
支持的取值范围:[1970-01-01,2149-06-06]。
存储日期值时不带时区。
Date32
一个日期。支持与DateTime64相同的日期范围。以本机字节顺序存储为有符号32位整数,其值表示自1970-01-01以来的天数(0表示1970-01-01,负值表示1970年之前的天数)。
DateTime
允许存储瞬间的时间,可以表示为日历日期和一天的时间。
DateTime([timezone])
支持的取值范围:[1970-01-01 00:00:00,2106-02-07 06:28:15]。
精度:1秒。
使用摘要
时间点被保存为Unix时间戳,与时区或夏令时无关。时区影响DateTime类型的值如何以文本格式显示,以及如何解析指定为字符串的值(’ 2020-01-01 05:00:01 ')。
与时区无关的Unix时间戳存储在表中,时区用于在数据导入/导出期间将其转换为文本格式或返回文本格式,或者用于对值进行日历计算(例如:toDate, toHour函数等)。时区不存储在表的行中(或结果集中),而是存储在列元数据中。
支持的时区列表可以在IANA时区数据库中找到,也可以通过SELECT * FROM system.time_zones查询。这份列表也可以在维基百科上找到。
在创建表时,可以显式地为DateTime类型列设置时区。例如:DateTime('UTC')。如果没有设置时区,ClickHouse将使用服务器设置或ClickHouse服务器启动时操作系统设置中的时区参数值。
如果在初始化数据类型时没有显式设置时区,则clickhouse-client默认应用服务器时区。要使用客户端时区,请使用--use_client_time_zone参数运行clickhouse-client。
ClickHouse根据date_time_output_format设置的值输出值。默认为YYYY-MM-DD hh:mm:ss文本格式。此外,还可以使用formatDateTime函数更改输出。
在向ClickHouse插入数据时,可以根据date_time_input_format设置的值,使用不同格式的日期和时间字符串。
DateTime64
允许存储时间上的瞬间,可以表示为日历日期和一天的时间,具有定义的亚秒精度
精度大小(precision):10^-precision精度秒。取值范围:[0,9]。通常使用- 3(毫秒),6(微秒),9(纳秒)。
DateTime64(precision, [timezone])
在内部,将数据存储为自epoch start (1970-01-01 00:00:00 UTC)以来的一些’ ticks '作为Int64。刻度分辨率由precision参数决定。此外,DateTime64类型可以存储整个列相同的时区,这会影响DateTime64类型的值如何以文本格式显示,以及如何解析指定为字符串的值(’ 2020-01-01 05:00:01.000 ')。时区不存储在表的行中(或结果集中),而是存储在列元数据中。具体请参见DateTime。
支持的取值范围:[1900-01-01 00:00:00,2299-12-31 23:59:59.99999999]
注:最大值精度为8。如果使用9位(纳秒)的最大精度,则支持的最大值为UTC时间的222-04-11 23:47:16。
Enum
由命名值(named values)组成的枚举类型。
命名值可以声明为'string' = integer 对或'string'名称。ClickHouse仅存储数字,但支持通过名称对值进行操作。
ClickHouse支持:
- 8 bit
Enum。最多可以包含256个[- 128,127]范围内的枚举值。 - 16-bit
Enum。它最多可以包含65536个在[-32768,32767]范围内枚举的值。
ClickHouse在插入数据时自动选择Enum类型。您还可以使用Enum8或Enum16类型来确定存储的大小。
用例
下面我们创建一个列类型为Enum8('hello' = 1, 'world' = 2)的表:
CREATE TABLE t_enum
(
x Enum('hello' = 1, 'world' = 2)
)
ENGINE = TinyLog
类似地,您可以省略数字。ClickHouse将自动分配连续的数字。默认从1开始分配号码。
CREATE TABLE t_enum
(
x Enum('hello', 'world')
)
ENGINE = TinyLog
您还可以为名字指定合法的起始编号。
CREATE TABLE t_enum
(
x Enum('hello' = 1, 'world')
)
ENGINE = TinyLog
CREATE TABLE t_enum
(
`x` Enum8('hello' = -129, 'world')
)
ENGINE = TinyLog
Query id: d68d56f5-1aa9-4d5b-8b34-a9dfef6b84a6
Elapsed: 0.287 sec.
Received exception from server (version 24.2.1):
Code: 69. DB::Exception: Received from localhost:9000. DB::Exception: Value -129 for element 'hello' exceeds range of Enum8. (ARGUMENT_OUT_OF_BOUND)
列x只能存储类型定义中列出的值:'hello'或'world'。如果您尝试保存任何其他值,ClickHouse将引发异常。自动选择此Enum的8位大小。
INSERT INTO t_enum VALUES ('hello'), ('world'), ('hello')
INSERT INTO t_enum FORMAT Values
Query id: b73e8f46-02e5-4196-832f-17f5353eecfe
Ok.
Exception on client:
Code: 691. DB::Exception: Unknown element 'a' for enum: while executing 'FUNCTION if(isNull(_dummy_0) : 3, defaultValueOfTypeName('Enum8(\'hello\' = 1, \'world\' = 2)') :: 2, _CAST(_dummy_0, 'Enum8(\'hello\' = 1, \'world\' = 2)') :: 4) -> if(isNull(_dummy_0), defaultValueOfTypeName('Enum8(\'hello\' = 1, \'world\' = 2)'), _CAST(_dummy_0, 'Enum8(\'hello\' = 1, \'world\' = 2)')) Enum8('hello' = 1, 'world' = 2) : 1': While executing ValuesBlockInputFormat: data for INSERT was parsed from query. (UNKNOWN_ELEMENT_OF_ENUM)
当从表中查询数据时,ClickHouse从Enum中输出字符串值。
SELECT * FROM t_enum
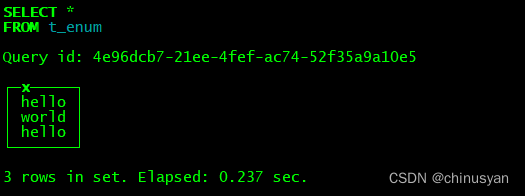
如果需要看到行的对应数字,则必须将Enum值强制转换为整数类型。
SELECT CAST(x, 'Int8') FROM t_enum
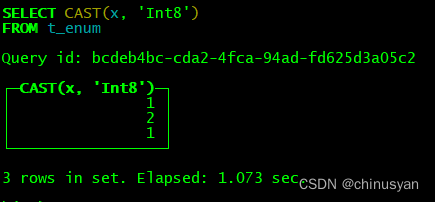
要在查询中创建Enum值,还需要使用CAST。
SELECT toTypeName(CAST('a', 'Enum(\'a\' = 1, \'b\' = 2)'))
一般规则及用法
每个值被分配一个范围在-128…127用于Enum8 或在-32768…32767用于Enum16。所有的字符串和数字必须是不同的。允许使用空字符串。如果指定了这种类型(在表定义中),则数字可以按任意顺序排列。然而,顺序并不重要。
Enum中的字符串和数字值都不能为NULL。
Enum可以包含为Nullable类型。因此,如果使用查询创建一个表
CREATE TABLE t_enum_nullable
(
x Nullable( Enum8('hello' = 1, 'world' = 2) )
)
ENGINE = TinyLog
不仅可以存储'hello'和'world',还可以存储NULL。
INSERT INTO t_enum_nullable Values('hello'),('world'),(NULL)
在RAM中,Enum列的存储方式与对应数值的Int8或Int16相同。
当以文本形式读取时,ClickHouse将值解析为字符串,并从Enum值集合中搜索相应的字符串。如果没有找到,则抛出异常。当以文本格式读取时,将读取字符串并查找相应的数值。如果没有找到,将抛出异常。当以文本形式写入时,它将值写入相应的字符串。如果列数据包含垃圾(不是来自有效集合的数字),则抛出异常。当以二进制形式读写时,它的工作方式与Int8和Int16数据类型相同。隐式默认值是数字最小的值。
在ORDER BY、GROUP BY、IN、DISTINCT等操作期间,Enum 的行为与相应的数字相同。例如,ORDER BY按数字排序。相等和比较操作符在enum上的工作方式与在底层数值上的工作方式相同。
枚举值不能与数字进行比较。枚举可以与常量字符串进行比较。如果比较的字符串不是Enum的有效值,则会引发异常。IN操作符支持左边的Enum和右边的一组字符串。字符串是对应Enum的值。
大多数数值和字符串操作不是为Enum值定义的,例如向Enum中添加数字或将字符串连接到Enum中。然而,Enum有一个自然的toString函数来返回它的字符串值。
枚举值也可以使用toT函数转换为数字类型,其中T是数字类型。当T对应于枚举的底层数字类型时,这种转换是零代价的。如果只更改了一组值,则可以使用ALTER零代价更改Enum类型。可以使用ALTER添加和删除Enum的成员(只有当被删除的值从未在表中使用过时,删除是安全的)。作为保护措施,更改先前定义的Enum成员的数值将引发异常。
使用ALTER,可以将Enum8更改为Enum16,反之亦然,就像将Int8更改为Int16一样。
Nullable(T)
允许存储特殊标记(NULL),表示“缺失值”,与T允许的正常值一起。例如,Nullable(Int8)类型列可以存储Int8类型的值,而没有值的行将存储NULL。
T不能是任何复合数据类型Array, Map和Tuple,但复合数据类型可以包含Nullable类型值,例如Array(Nullable(Int8))。
Nullable类型字段不能包含在表索引中。
NULL是任何Nullable类型的默认值,除非在ClickHouse服务器配置中另有指定。
存储特点
为了在表列中存储Nullable类型的值,ClickHouse除了使用带值的普通文件外,还使用带NULL掩码的单独文件。掩码文件(masks file)中的条目允许ClickHouse区分每个表行对应数据类型的NULL和默认值。由于有一个额外的文件,Nullable列比类似的普通列消耗更多的存储空间。
使用
Nullable几乎总是会对性能产生负面影响,在设计数据库时请记住这一点。
Finding NULL
可以通过使用null子列来查找列中的NULL值,而无需读取整个列。如果对应的值为NULL,则返回1,否则返回0。
例子:
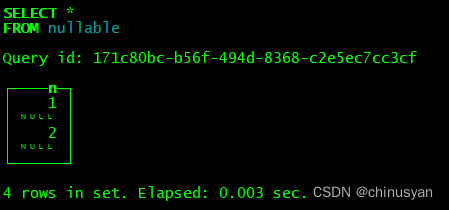
CREATE TABLE nullable (`n` Nullable(UInt32)) ENGINE = MergeTree ORDER BY tuple();
INSERT INTO nullable VALUES (1) (NULL) (2) (NULL);
SELECT n.null FROM nullable;
Array(T)
T类型项的数组,起始数组索引为1。T可以是任何数据类型,包括数组。
Creating an Array
你可以使用一个函数来创建一个数组:
array(T)
也可以使用方括号。
[]
例子:
SELECT array(1, 2) AS x, toTypeName(x)
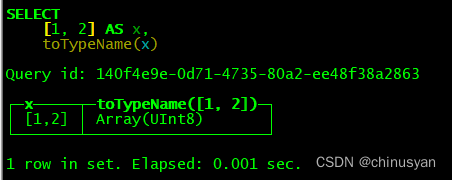
SELECT [1, 2] AS x, toTypeName(x)
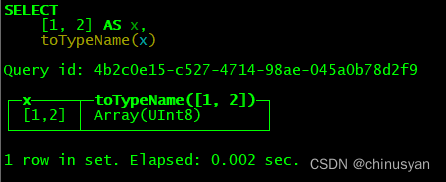
使用
在动态创建数组时,ClickHouse自动将参数类型定义为可以存储所有列出的参数的最窄的数据类型。如果存在任何Nullable或文字NULL值,则数组元素的类型也变为Nullable。
如果ClickHouse不能确定数据类型,它会生成一个异常。例如,当尝试同时创建字符串和数字的数组时(SELECT array(1, 'a'))就会发生这种情况。

自动数据类型检测的示例:
SELECT array(1, 2, NULL) AS x, toTypeName(x)
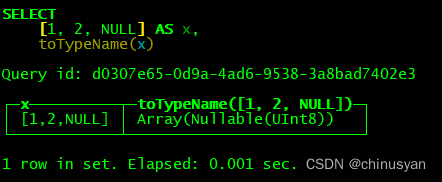
数组大小
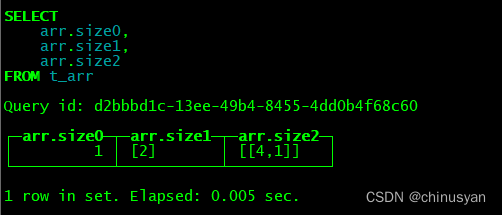
可以通过使用size0子列来查找数组的大小,而无需读取整个列。对于多维数组,您可以使用sizeN -1,其中N是所需的维度。
例子:
CREATE TABLE t_arr (`arr` Array(Array(Array(UInt32)))) ENGINE = MergeTree ORDER BY tuple();
INSERT INTO t_arr VALUES ([[[12, 13, 0, 1],[12]]]);
SELECT arr.size0, arr.size1, arr.size2 FROM t_arr;
UUID
UUID (Universally Unique Identifier)是一个16字节的值,用于标识记录。有关uuid的详细信息,请参见Wikipedia。
虽然存在不同的UUID变体(请参阅此处),但ClickHouse并不验证插入的UUID是否符合特定的变体。UUIDs 在内部被视为16个随机字节的序列,在SQL级别具有8-4-4-4-12表示。
UUID值示例:
61f0c404-5cb3-11e7-907b-a6006ad3dba0
默认UUID为全零。例如,当插入一条新记录但没有指定UUID列的值时,使用它:
00000000-0000-0000-0000-000000000000
生成UUID
ClickHouse提供generateUUIDv4函数来生成随机的UUID版本4值。
使用示例
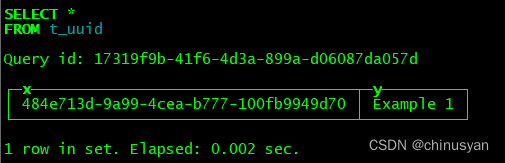
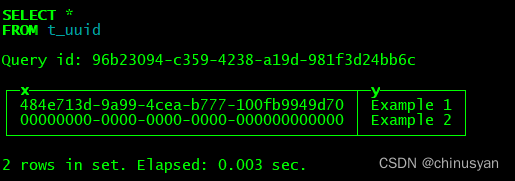
Example 1:
这个示例演示了如何创建一个包含UUID列的表,以及如何向表中插入一个值。
CREATE TABLE t_uuid (x UUID, y String) ENGINE=TinyLog
INSERT INTO t_uuid SELECT generateUUIDv4(), 'Example 1'
SELECT * FROM t_uuid
Example 2:
在本例中,插入记录时没有指定UUID列值,即插入默认的UUID值:
INSERT INTO t_uuid (y) VALUES ('Example 2')
SELECT * FROM t_uuid
限制
UUID数据类型只支持String数据类型也支持的函数(例如min、max和count)。
算术运算(例如abs)或聚合函数(例如sum和avg)不支持UUID数据类型。
Float32, Float64
如果您需要精确的计算,特别是如果您处理需要高精度的财务或业务数据,则应该考虑使用
Decimal。float可能导致不准确的结果,如下所示:
CREATE TABLE IF NOT EXISTS float_vs_decimal
(
my_float Float64,
my_decimal Decimal64(3)
)Engine=MergeTree ORDER BY tuple()
INSERT INTO float_vs_decimal SELECT round(randCanonical(), 3) AS res, res FROM system.numbers LIMIT 1000000; # Generate 1 000 000 random number with 2 decimal places and store them as a float and as a decimal
SELECT sum(my_float), sum(my_decimal) FROM float_vs_decimal;
500279.56300000014 500279.563
SELECT sumKahan(my_float), sumKahan(my_decimal) FROM float_vs_decimal;
500279.563 500279.563
别名:
Float32—FLOAT,REAL,SINGLE.Float64—DOUBLE,DOUBLE PRECISION.
在创建表时,可以设置浮点数的数值参数(例如FLOAT(12), FLOAT(15,22), DOUBLE(12), DOUBLE(4,18)),但ClickHouse会忽略它们。
使用浮点数
使用浮点数进行计算可能会产生舍入误差。
SELECT 1 - 0.9
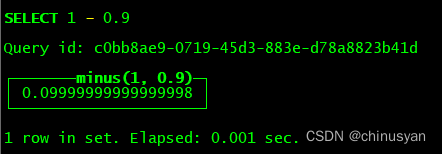
- 计算结果取决于计算方法(计算机系统的处理器类型和体系结构)。
- 浮点计算可能会产生诸如无穷大(
Inf)和“非数字”(NaN)之类的数字。在处理计算结果时应考虑到这一点。 - 从文本解析浮点数时,结果可能不是最接近的机器可表示的数字。
NaN and Inf
与标准SQL相比,ClickHouse支持以下类型的浮点数:
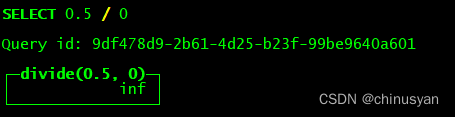
Inf– Infinity.
SELECT 0.5 / 0
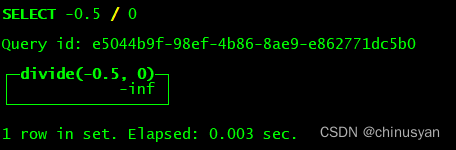
-Inf— Negative infinity.
SELECT -0.5 / 0
NaN— Not a number.
SELECT 0 / 0
Bool
bool类型在内部存储为UInt8。可能的值是true (1), false(0)。
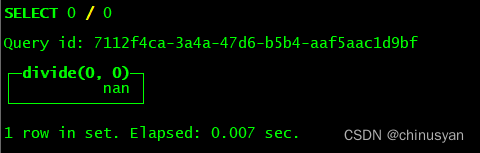
select true as col, toTypeName(col);
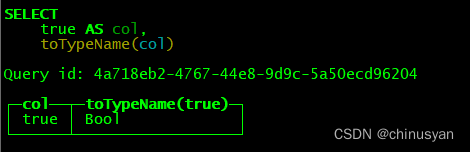
select true == 1 as col, toTypeName(col);
CREATE TABLE test_bool
(
`A` Int64,
`B` Bool
)
ENGINE = Memory;
INSERT INTO test_bool VALUES (1, true),(2,0);

JSON
这个特性是实验性的,还不能用于生产。如果您需要使用JSON文档,请考虑使用本指南。
在单列中存储JavaScript对象表示法(JSON)文档。
JSON is an alias for Object('json').
JSON数据类型是一个过时的特性。不要使用它。如果您想使用它,请设置allow_experimental_object_type = 1。
Example 1:
创建一个带有JSON列的表,并将数据插入其中:
CREATE TABLE json
(
o JSON
)
ENGINE = Memory
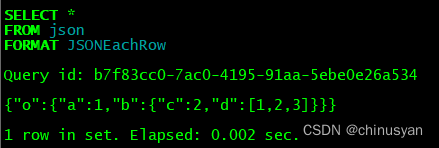
INSERT INTO json VALUES ('{"a": 1, "b": { "c": 2, "d": [1, 2, 3] }}')
SELECT o.a, o.b.c, o.b.d[3] FROM json

Example 2:
为了能够创建有序的MergeTree族表,必须将排序键提取到其列中。例如,插入一个JSON格式的HTTP访问日志压缩文件:
CREATE TABLE logs
(
timestamp DateTime,
message JSON
)
ENGINE = MergeTree
ORDER BY timestamp
INSERT INTO logs
SELECT parseDateTimeBestEffort(JSONExtractString(json, 'timestamp')), json
FROM file('access.json.gz', JSONAsString)
显示JSON列
在显示JSON列时,ClickHouse默认只显示字段值(因为在内部,它被表示为一个元组)。你也可以通过设置output_format_json_named_tuples_as_objects = 1来显示字段名:
SET output_format_json_named_tuples_as_objects = 1
SELECT * FROM json FORMAT JSONEachRow
Map(key, value)
Map(key, value) 数据类型存储 key:value 键值对.
参数
key— The key part of the pair.String,Integer,LowCardinality,FixedString,UUID,Date,DateTime,Date32,Enum.value— The value part of the pair. Arbitrary type, includingMapandArray.
要从a Map('key', 'value')列中获取值,请使用a['key']语法。这种查找现在以线性复杂度工作。
例子
考虑表:
CREATE TABLE table_map (a Map(String, UInt64)) ENGINE=Memory;
INSERT INTO table_map VALUES ({'key1':1, 'key2':10}), ({'key1':2,'key2':20}), ({'key1':3,'key2':30});
选择所有的key2值:
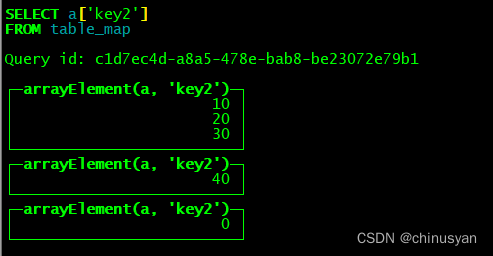
SELECT a['key2'] FROM table_map;

如果Map()列中没有这样的``,查询将为数值返回零、空字符串或空数组。
insert into table_map values ({'key1':4, 'key2': 40})
insert into table_map values ({'key1':4, 'key3': 40})
select a['key2'] from table_map
将元组转换为映射类型
你可以使用CAST函数将Tuple()转换为Map():
SELECT CAST(([1, 2, 3], ['Ready', 'Steady', 'Go']), 'Map(UInt8, String)') AS map;

Map.keys 和Map.values 子列
为了优化Map列处理,在某些情况下可以使用keys 和values 子列,而不是读取整个列。
Example:
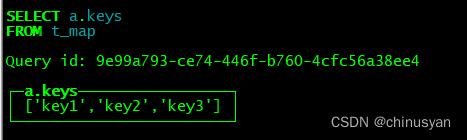
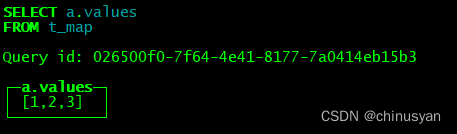
CREATE TABLE t_map (`a` Map(String, UInt64)) ENGINE = Memory;
INSERT INTO t_map VALUES (map('key1', 1, 'key2', 2, 'key3', 3));
SELECT a.keys FROM t_map;
SELECT a.values FROM t_map;
Related content
Blog: Building an Observability Solution with ClickHouse - Part 2 - Traces
LowCardinality
将其他数据类型的内部表示更改为字典编码。
LowCardinality(data_type)
data_type-String、FixedString、Date、DateTime和数字(Decimal除外)。LowCardinality对于某些数据类型不是有效的,请参见 allow_suspicious_low_cardinality_types 设置说明。
LowCardinality是改变数据存储方法和数据处理规则的上层结构。ClickHouse对LowCardinality-columns应用字典编码。对许多应用程序来说,使用字典编码的数据可以显著提高SELECT查询的性能。
使用LowCardinality数据类型的效率取决于数据多样性。如果字典包含少于10,000个不同的值,那么ClickHouse通常显示出更高的数据读取和存储效率。如果字典包含超过100,000个不同的值,那么与使用普通数据类型相比,ClickHouse的性能可能会更差。
在处理字符串时,考虑使用LowCardinality而不是Enum。LowCardinality在使用中提供了更大的灵活性,并且通常显示相同或更高的效率。
例子
创建一个LowCardinality列的表:
CREATE TABLE lc_t
(
`id` UInt16,
`strings` LowCardinality(String)
)
ENGINE = MergeTree()
ORDER BY id
相关设置和函数
Settings:
- low_cardinality_max_dictionary_size
- low_cardinality_use_single_dictionary_for_part
- low_cardinality_allow_in_native_format
- allow_suspicious_low_cardinality_types
- output_format_arrow_low_cardinality_as_dictionary
Functions:
- toLowCardinality
将输入参数转换为相同数据类型的LowCardinality版本。
要从LowCardinality数据类型转换数据,请使用CAST函数。例如,CAST(x as String)。
toLowCardinality(expr)
AggregateFunction
聚合函数可以具有实现定义的中间状态,该状态可以序列化为AggregateFunction(…)数据类型,并通常通过物化视图存储在表中。生成聚合函数状态的常用方法是调用带有-State后缀的聚合函数。要在将来获得聚合的最终结果,必须使用带-Merge后缀的相同聚合函数。
AggregateFunction(name, types_of_arguments…)- 参数数据类型。
- 聚合函数的名称。如果函数是参数化的,也要指定它的参数。
- 聚合函数参数的类型。
Example:
CREATE TABLE t
(
column1 AggregateFunction(uniq, UInt64),
column2 AggregateFunction(anyIf, String, UInt8),
column3 AggregateFunction(quantiles(0.5, 0.9), UInt64)
) ENGINE = ...
用法
数据插入
要插入数据,使用INSERT SELECT和aggregate -State -函数。
uniqState(UserID)
quantilesState(0.5, 0.9)(SendTiming)
与uniq和quantiles对应的函数相反,-State 函数返回状态,而不是最终值。换句话说,它们返回AggregateFunction类型的值。
在SELECT查询的结果中,AggregateFunction类型的值对于所有ClickHouse输出格式都具有特定于实现的二进制表示。例如,如果使用SELECT查询将数据转储为TabSeparated格式,则可以使用INSERT查询将此转储加载回来。
数据查询
当从AggregatingMergeTree表中选择数据时,使用GROUP BY子句和与插入数据时相同的聚合函数,但使用-Merge 后缀。
带有-Merge后缀的聚合函数接受一组状态,将它们组合起来,并返回完整数据聚合的结果。
例如,下面两个查询返回相同的结果:
SELECT uniq(UserID) FROM table
SELECT uniqMerge(state) FROM (SELECT uniqState(UserID) AS state FROM table GROUP BY RegionID)
SimpleAggregateFunction
SimpleAggregateFunction(name, types_of_arguments…)数据类型存储聚合函数的当前值,而不像AggregateFunction那样存储其完整状态。此优化可以应用于以下属性成立的函数:函数f对行集S1 UNION ALL S2的作用结果可以通过分别对行集的部分应用f,然后再对结果应用f得到:f(S1 UNION ALL S2) = f(f(S1) UNION ALL f(S2))。这个属性保证部分聚合结果足以计算合并后的结果,因此我们不必存储和处理任何额外的数据。
生成聚合函数值的常用方法是调用带有 -SimpleState后缀的聚合函数。
请注意,
-MapState不是相同数据的不变量,因为处于中间状态的数据顺序可以改变,尽管它不会影响该数据的摄取。















 1783
1783

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









