






Yarn
Elements
- Resource Manager: manage the use of resources across the cluster.
- Node Manager: running on all the nodes in the cluster to launch and monitor containers.
- Container: executes an application specific process with a constrained set of resources, i.e. CPU, Memory and so on. The container might be a Unix process or Linux cgroup.
Application
Application Startup
- Client contacts the Resource Manager to start the Application Master.
- Resource Manager to find a Node Manager to run Application Master.
- Application Master determines what to do next, ask for Resources from Resource Manager to run Processes when needed.
- Communication between client, master, and processes have to be handled by application by itself.
- Resource Request can be made at any time.
- Up front - Spark.
- Dynamic
Application Lifespan
- One Application One Job - MapReduce;
- One Application One Workflow that contains multiple jobs - Spark
- One Application that is long-running and shared by different users - Application acts as Coordinator, for example, Impala daemon.
Scheduler
- FIFO Scheduler
- Capacity Scheduler
- Fair Scheduler
Hadoop I/O
Data Integrity
- CRC-32 (32 bits cyclic redudency check) for error detecting - ChecksumFileSystem;
- CRC-32C is an enhancement of CRC-32, which is the one HDFS use;
- dfs.bytes-per-checksum (default = 512 bytes and checksum is 4 bytes), i.e. rawData = 512 bytes and checksum = 4 bytes;
- Write
- Client -> Raw Data -> (Raw + CheckSum) Data -> send to 1st Data Node
- 1st Data Node -> (Raw + Checksum) Data -> 2nd Data Node
- Data Node -> verify the Raw Data using Checksum Data
- Read
- Data Node -> (Raw + Checksum) Data -> Client
- Client -> verify the Raw Data using Checksum Data
- Backend daemon to check data in Data Nodes regularlly to avoid bit rot;
- Disable Checksum
- FileSystem.setVerifyChecksum(false)
- FileSystem.open()
Compression
- Compression Method/Codec: DEFLATE, gzip, bzip2, LZO, LZ4, Snappy;
- Map task
- The compression method of the INPUT FILE can be determined by file EXTENSION, and thereafter be decompressed by Map task accordingly.
- To compress OUTPUT FILE :
- mapreduce.output.fileoutputformat.compress=true
- mapreduce.output.fileoutputformat.compress.codec=compression_codec
- mapreduce.output.fileoutputformat.compress.type
- RECORD: compress individual record, i.e. sequence file;
- BLOCK: compress groups of records
Serialization
The process of turning structured objects into a byte stream for transmission over a network or for writing to persistent storage, i.e.
- Interprocess communication
- Persist Data
Writeable
Hadoop uses its own serialization format, Writables, which is certainly compact and fast, but not easy to extend or use from other languages other than Java. Avro is designed to overcome some of the limitations of Writables. And there is some other serialization framework supported by Hadoop.
File-Based Data Structure
A persistent data structure for the binary key-value pair.
Sequence File
- Header: magic number, version, key/value class, compression details, user-defined metadata, sync marker
- Record: Record length, Key length, key, value (or compressed value)
- Keys are not compressed;
- Compression method
- Record compression
- Block compression: compress multiple records at a time (i.e. a block)
- io.seqfile.compress.blocksize
- Sync Point: randomly placed in.
Map File
A sorted sequence file with an index to permit lookup by key.
Other Files
- Avro File: objects stored in avro are described by a schema;
- Colum-Orientated File: row split then column followed by column;
- Hive's RCFiles, Hive's ORCFiles, Parquet
- Save the time on reading unnecssary column
- Requires more memory to load whole rows split.
- Not suitable for streaming.
Reference
http://bradhedlund.com/2011/09/10/understanding-hadoop-clusters-and-the-network/
- Avro
- Usage :
- Data Serialization
- Data Exchange (RPC)
- Data/File Format :
- Schema (JSON)
- Data (Binary) -> Compressed
- Data inlcudes marks that allow split (for big files)
- Allows Schema Update (Add/Remove Fields)
- Yet data remain unchanged, i.e. old fields still available for the previous customers;
- Usage :
- Parquet
- Columer format data file format.
- Problem :
- Storage and I/O.
- Good for analysis usually max/min/avg on certain columns ratehr than whole table row by row scan.
- Good for compression - type of each column is known.
- Good for optimziation - type of each column is known - eliminate unnecessary encode/decode - save CPU power.
- Flume
- Sqoop
- Crunch
- The Apache Crunch Java library provides a framework for writing, testing, and running MapReduce pipelines. Its goal is to make pipelines that are composed of many user-defined functions simple to write, easy to test, and efficient to run.
- Making creation of MapReduce jobs easier.
- Structure
- Source / Original Format (DoFn)
- Process Raw Data (Join)
- Filter (invalid data) (FilterFn)
- Group (Group By Key)
- Persist Result / Target Format (DoFn)
- Execution
- Map : Source / Original Format (DoFn)
- Reduce : Process Raw Data (Join)
- Reduce : Filter (invalid data) (FilterFn)
- Reduce : Group (Group By Key)
- Reduce : Persist Result / Target Format (DoFn)
- Spark
- Zookeeper
- Impla
- Hue
- Yarn
- Cloudera
- Tez (faster Tez)
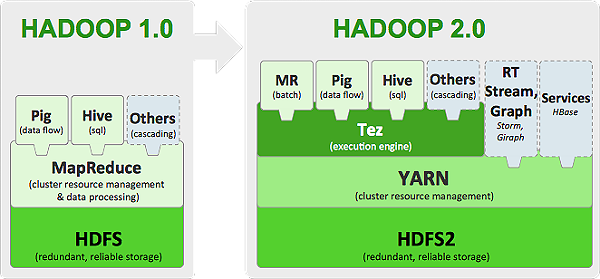
- Hue (Hadoop User Experience) / Cloudera
- Sit on top of difference services/apps, and expose those services via UI;
- Hase, Oozie, Sqoop, Hive, Pig, HDFS.
- Infrastructure
- Front End
- Mako Templates
- JQuery
- KnockoutJS
- Backend
- Python + Django driven
- Thrift + Web Client for Hadoop Components
- Spawning/CherryPy
- SDK
- Make your own App!
- build/env/bin/hue create_desktop_app <name>
- DB
- sqllite, mysql, postgres
- Front End
- Cascading - Workflow Abstraction
- Middleware in between Hadoop and other applications. A tool for enterpise.
- It addresses
- Staffing Bottleneck
- System Integration
- Operational Complexity
- Test Driven Dvelopment
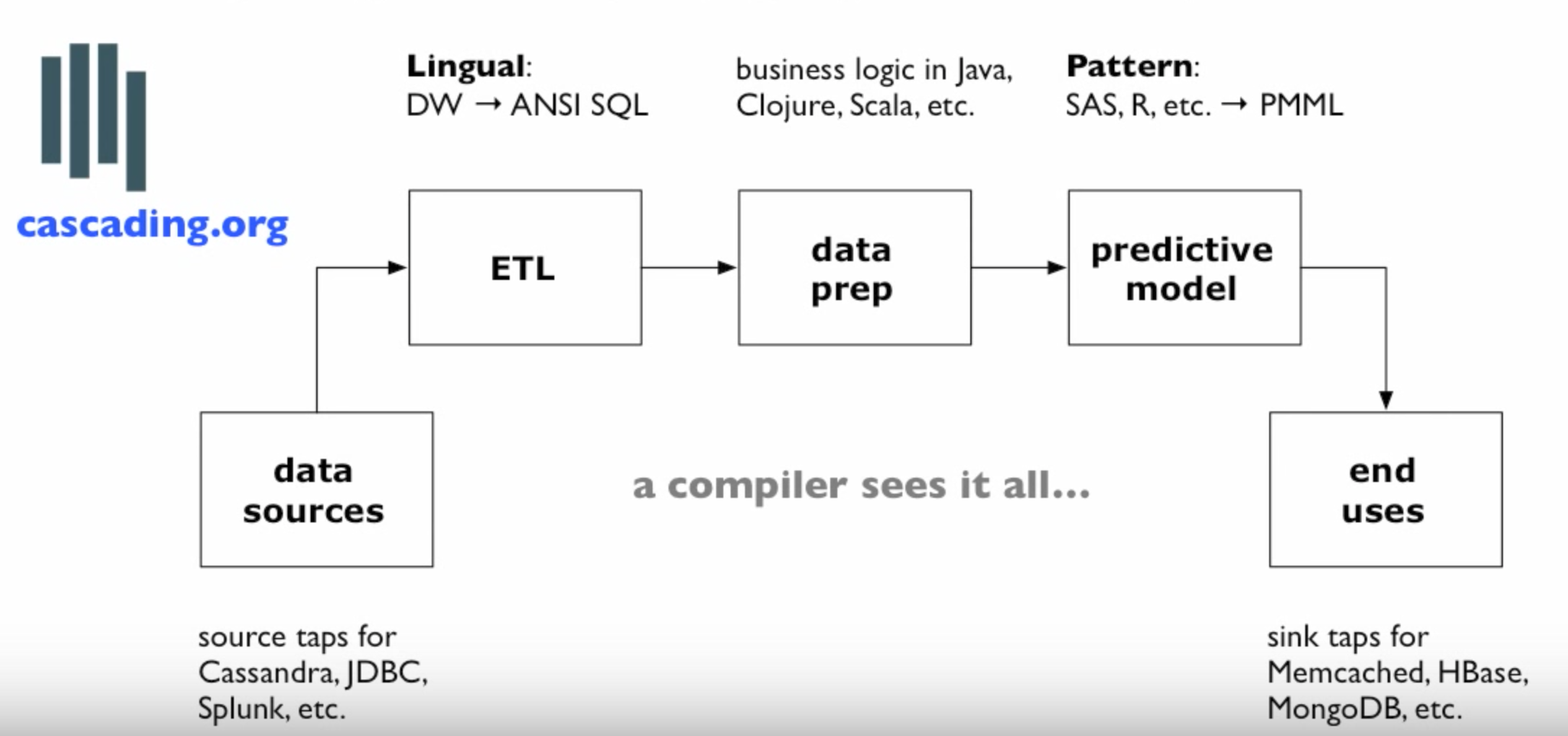
- Data Prep : Clean up the data (usually 80% of the work);
ETL

PMML
Hadoop
CPU, Disk, Rack
Storage
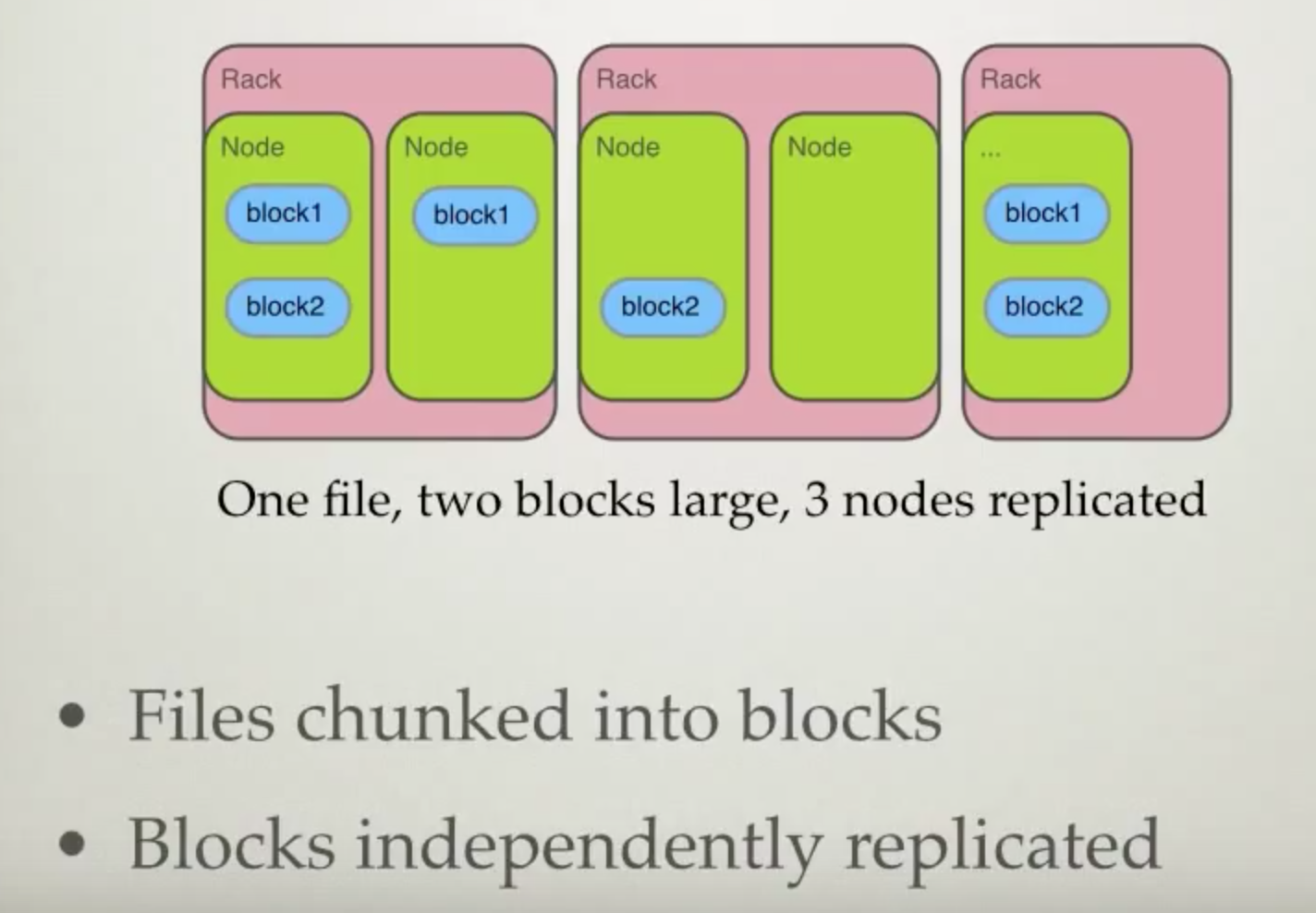
Execution
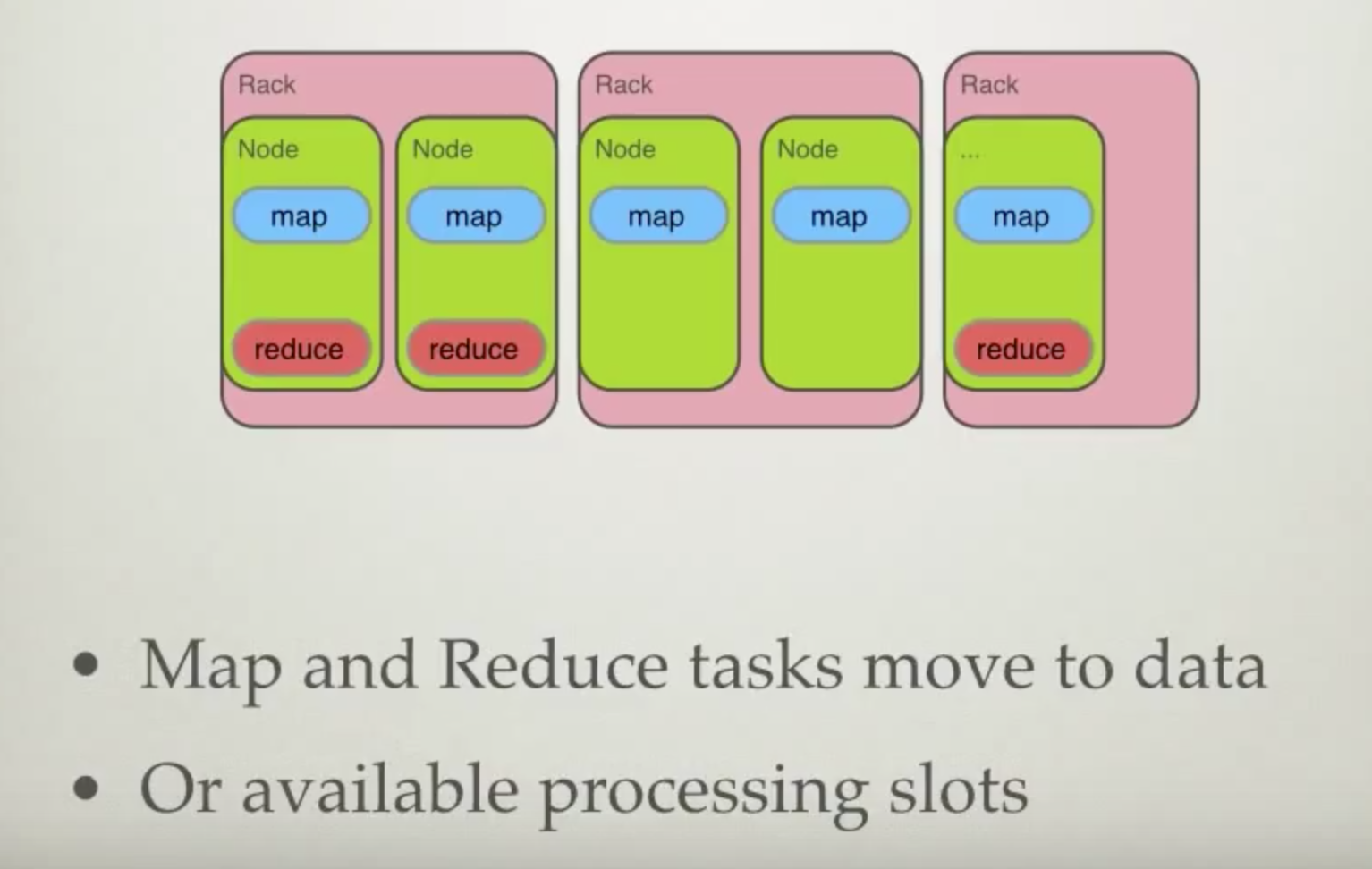
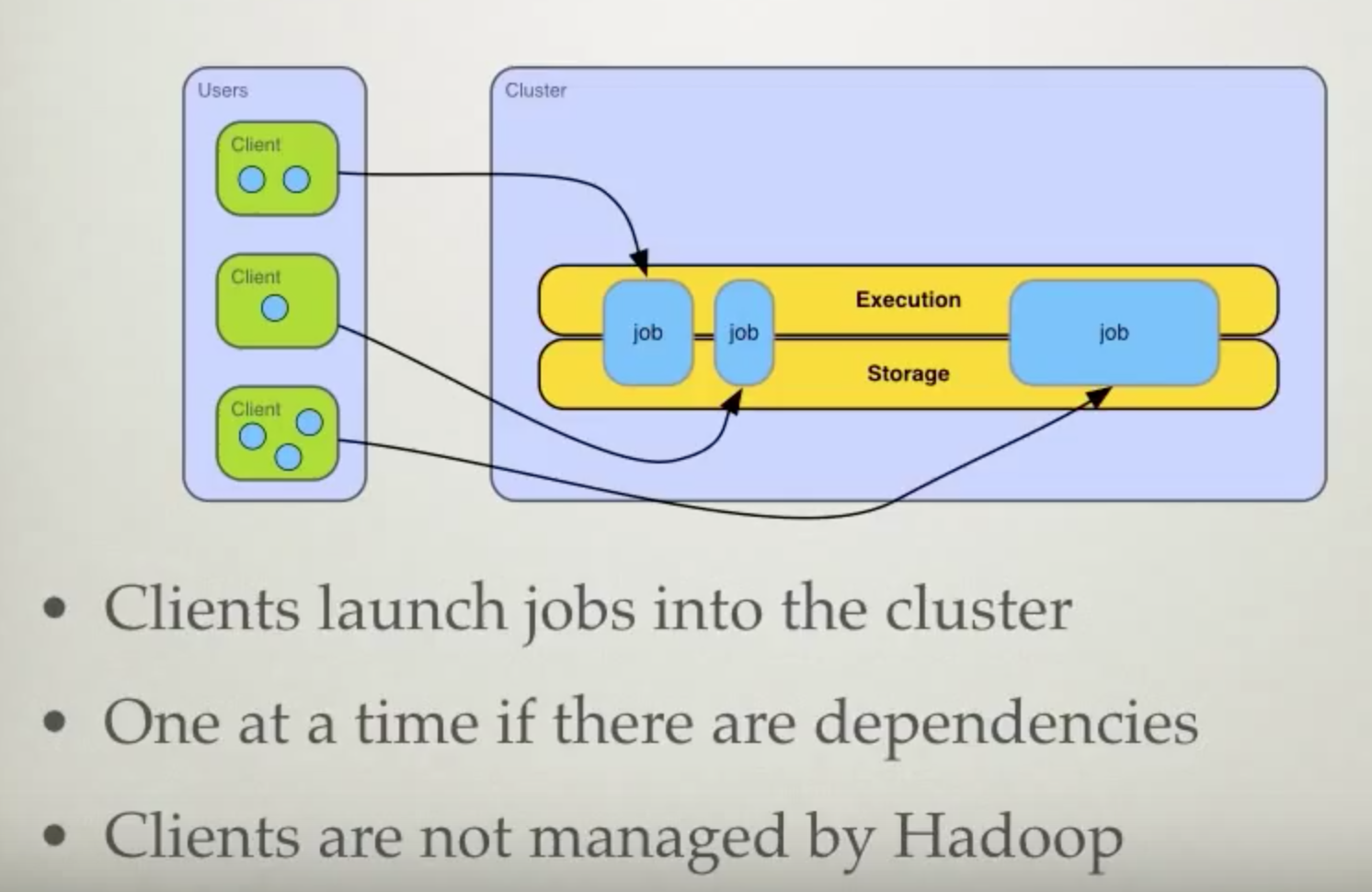
Client and Jobs
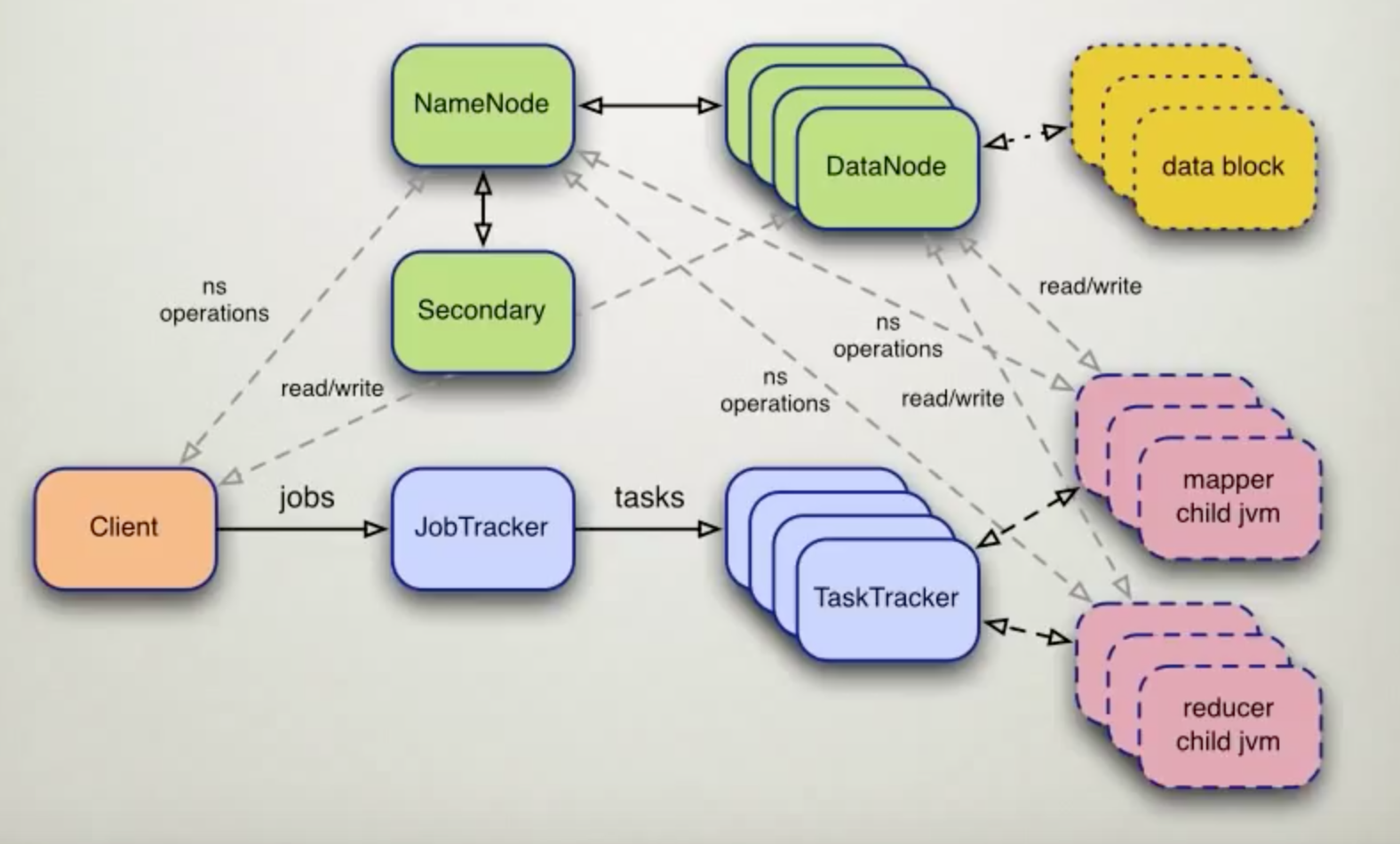
Physical Architecture
Deployment
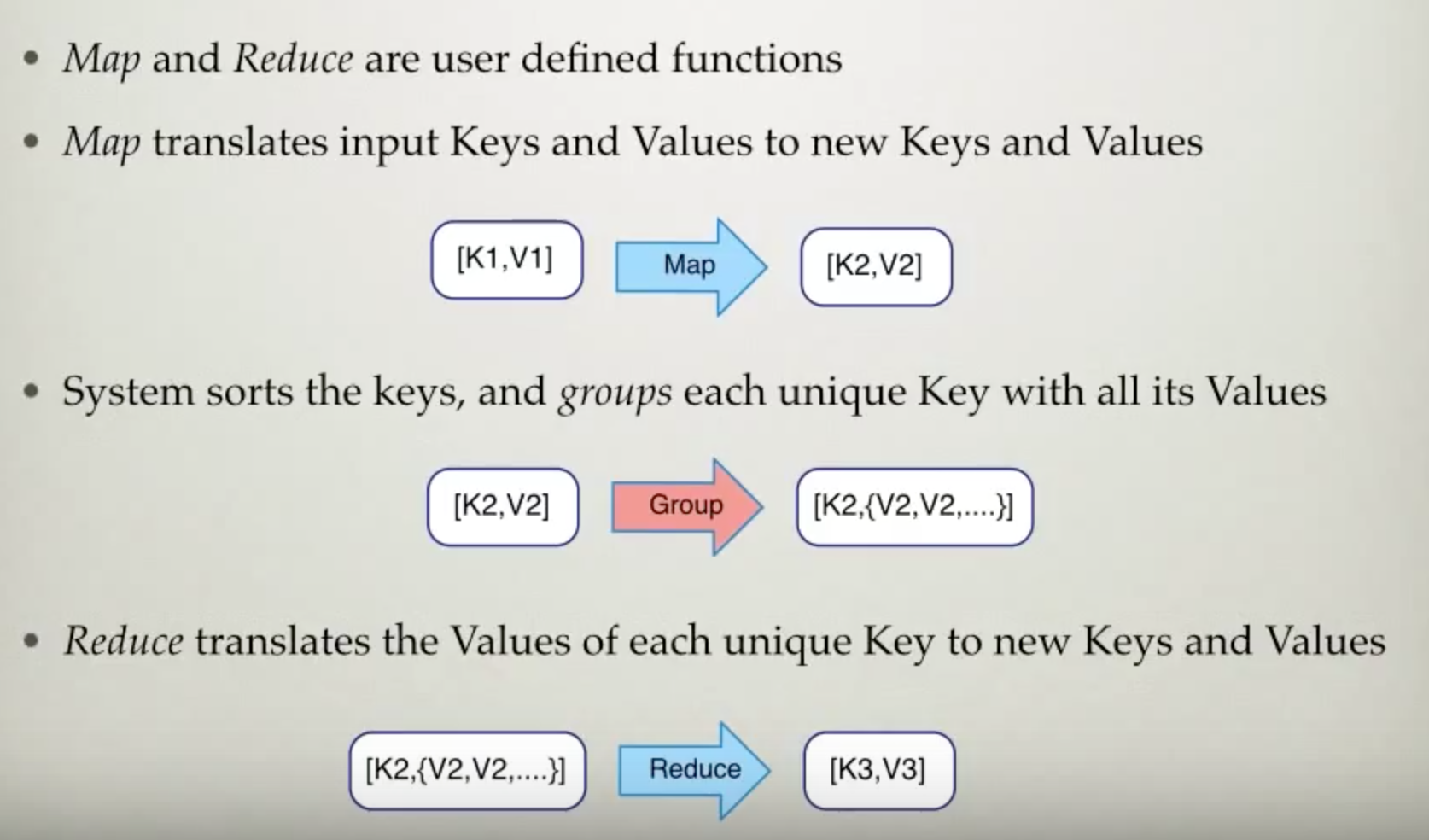
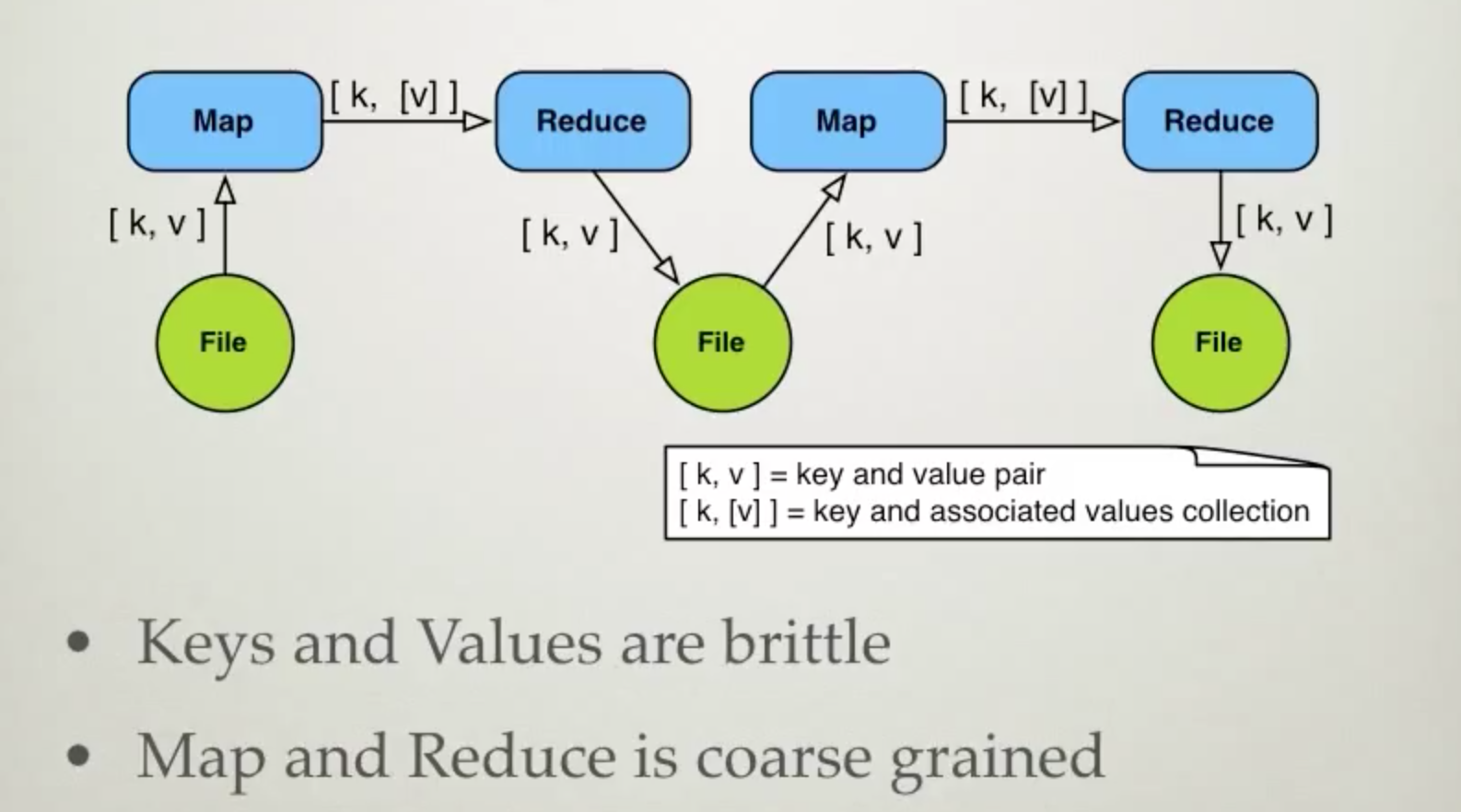
Map Group and Reduce
Word Count
Common Patterns

Advanced Patterns

Very Advanced

Trouble with MapReduce
Real World Apps
Not Thinking in MapReduce
In A Nut Shell

Language
- Java, Scala, Clojure
- Python, Rubty
Higher Level Language
- Hive
- Pig
Frameworks
- Cascading, Crunch
DSLs
- Scalding, Scrunch, Scoobi, Cascalog
Topics
Challenges: 5 Vs
- Store the data and process the data;
- Volume: due to
- Technology Advance: telephone - mobile phone - smart phone;
- IoT
- Social Network:
- 4.4 Zb today, 44 Zb anticipated in 2020;
- Variety :
- Structured
- Semi-structured
- Unstructured
- Velocity :
- Value: Data Mining
- Varicity: dealing with inconsistency
- missing data
- development
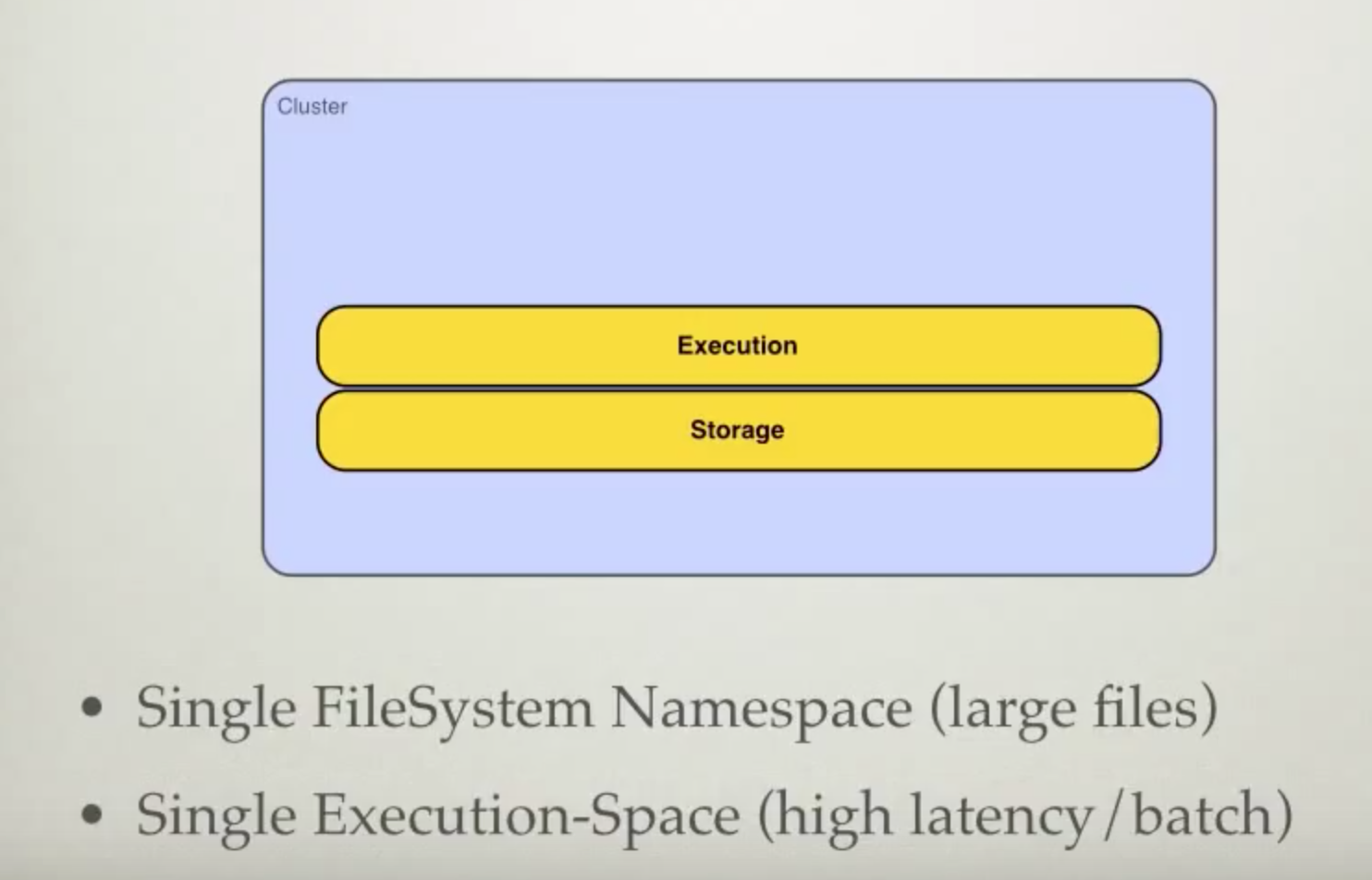
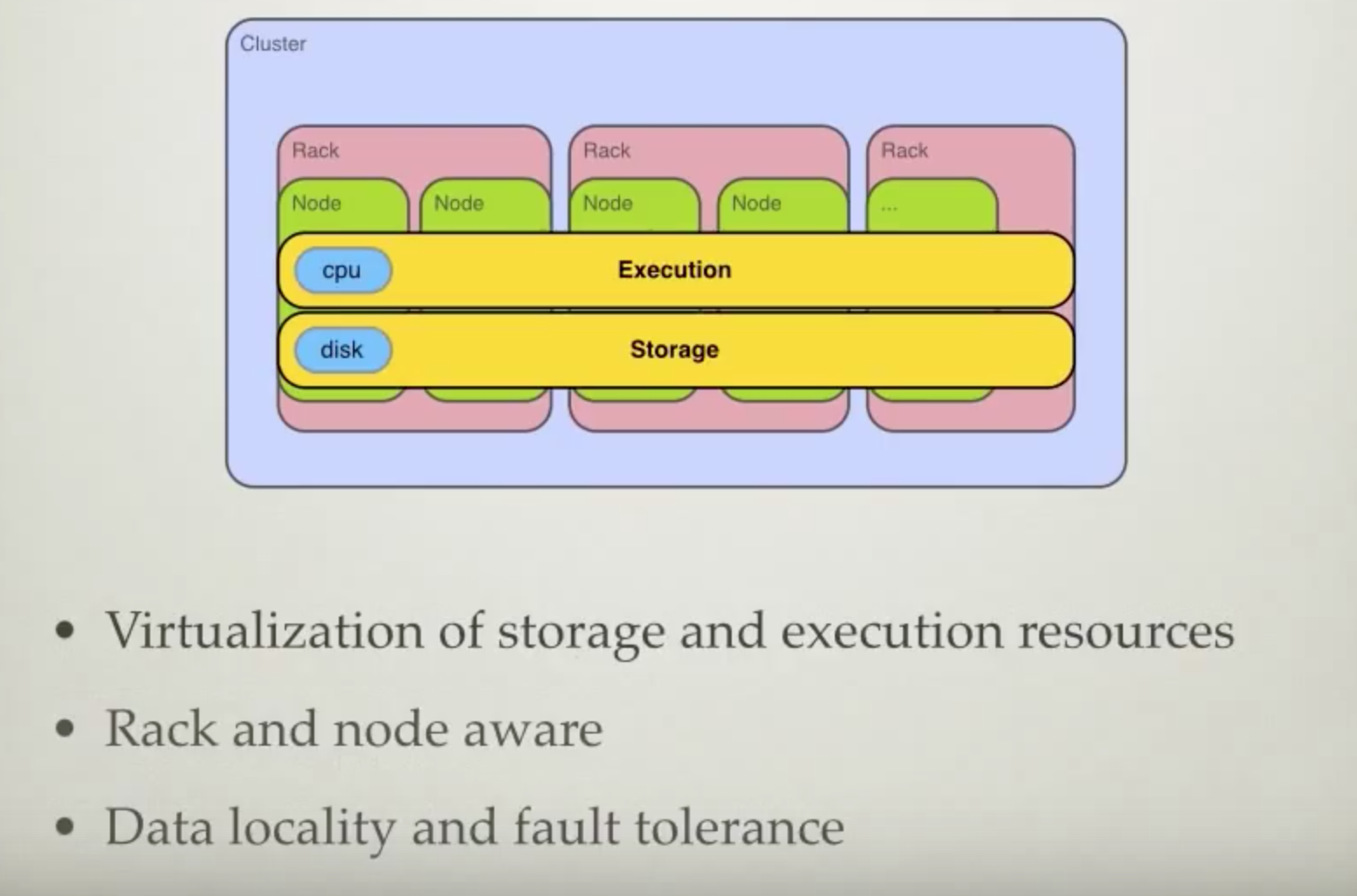
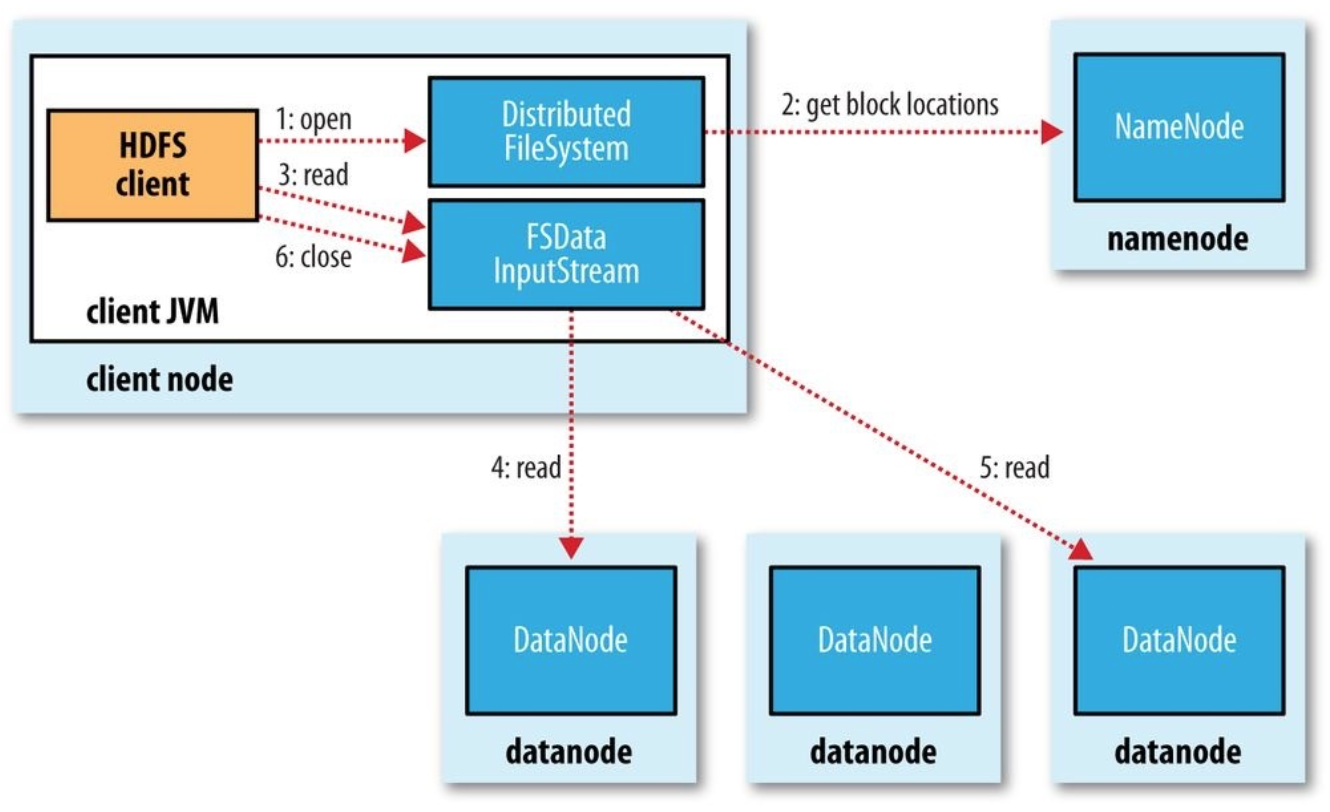
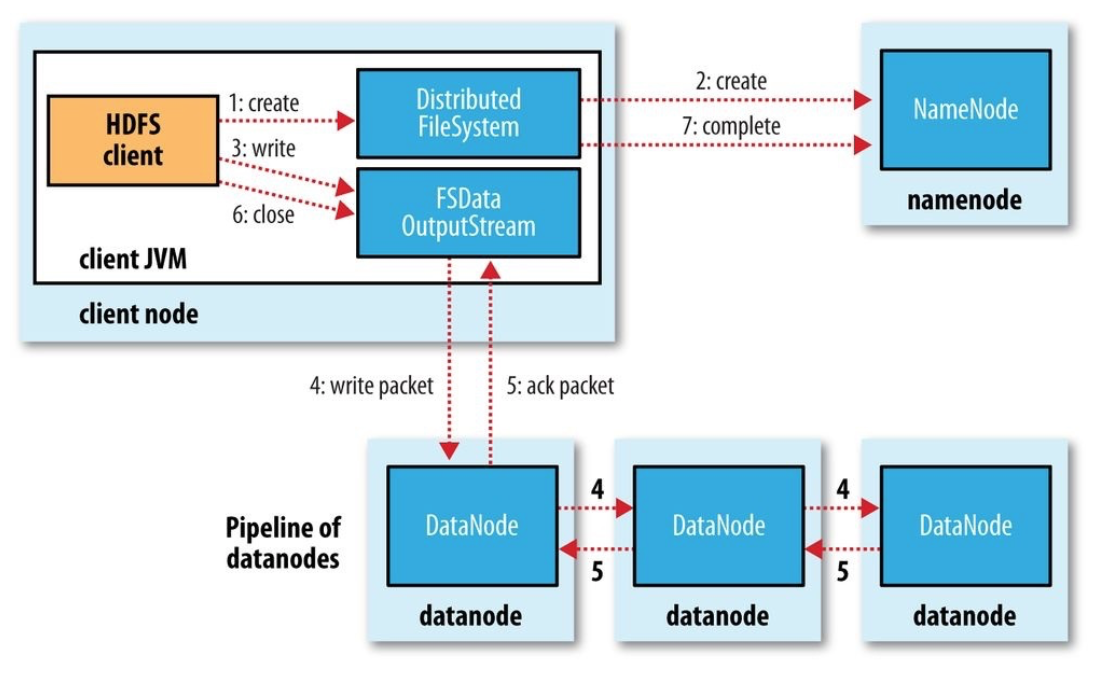
HDFS : Cluster
Name Node : meta data (block, location)
- Master/Slave;
Data Node :
- Data replication : default 3;
hadoop fs :
- hadoop fs -ls
- hadoop fs -put loca_lfilename hdfs_filename
- hadoop fs -get hdfs_filename loca_lfilename
- hadoop fs -mv hdfs_filename hdfs_newfilename
- hadoop fs -rm hdfs_filename
- hadoop fs -tail/cat/mkdir
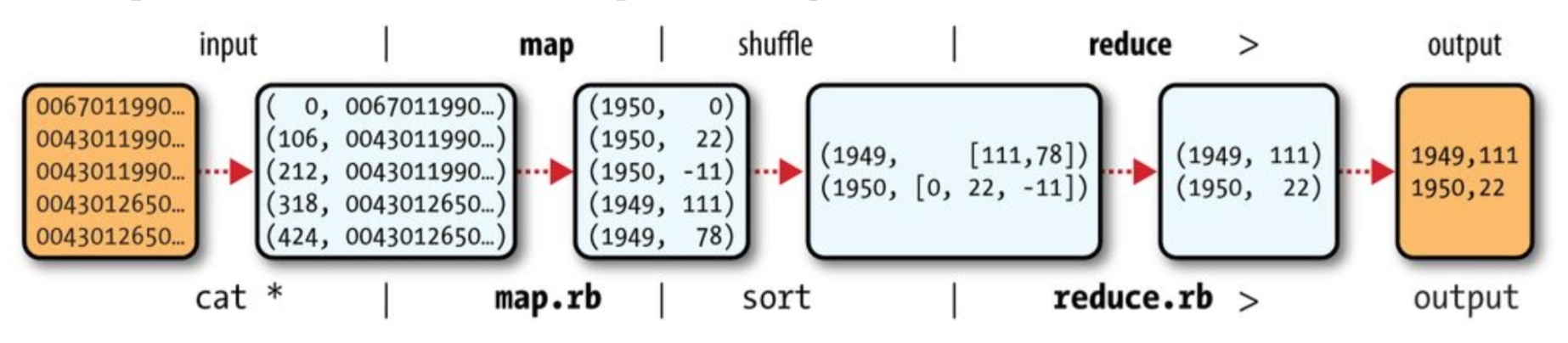
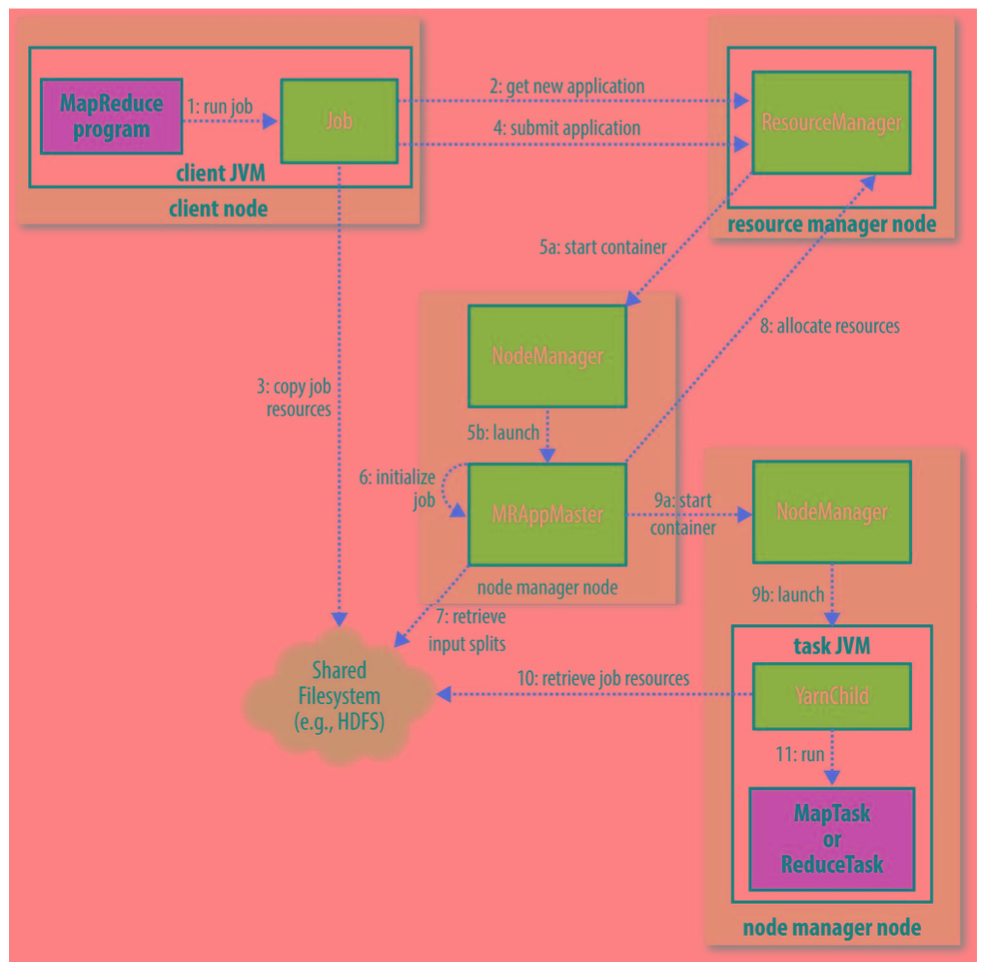
MapReduce : sending process to data v.s. sending data to node;
- Challenges with Hash Table : (Key-Value)
- Too many keys could result in OOM;
- Too much time;
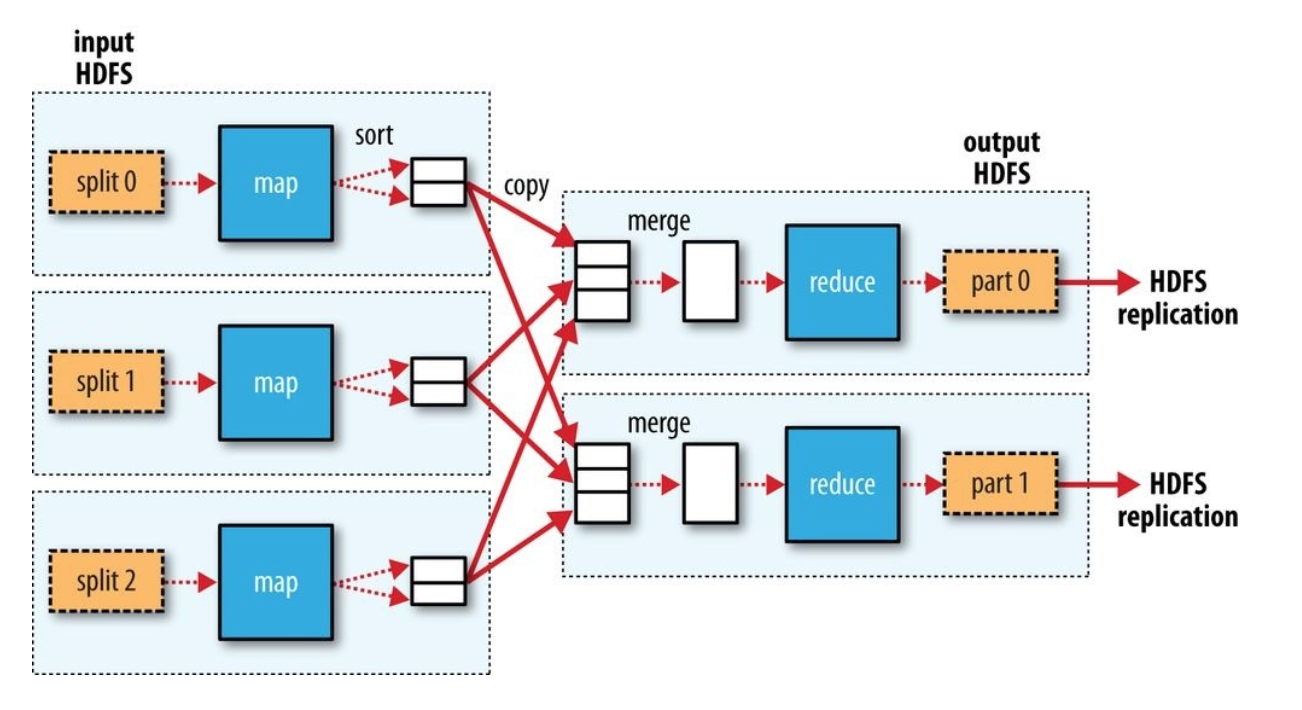
- Files broken down into chunks and processed in parallel;
- Mappers generate Intermediate Records (Key, Value)
- Shuffle : move Intermediate Records from Mapper to Reducer
- Sort : sort the Records;
- Reducer calcualte the final result;
- Partioner
- Imtermeidate data to which Reducer;
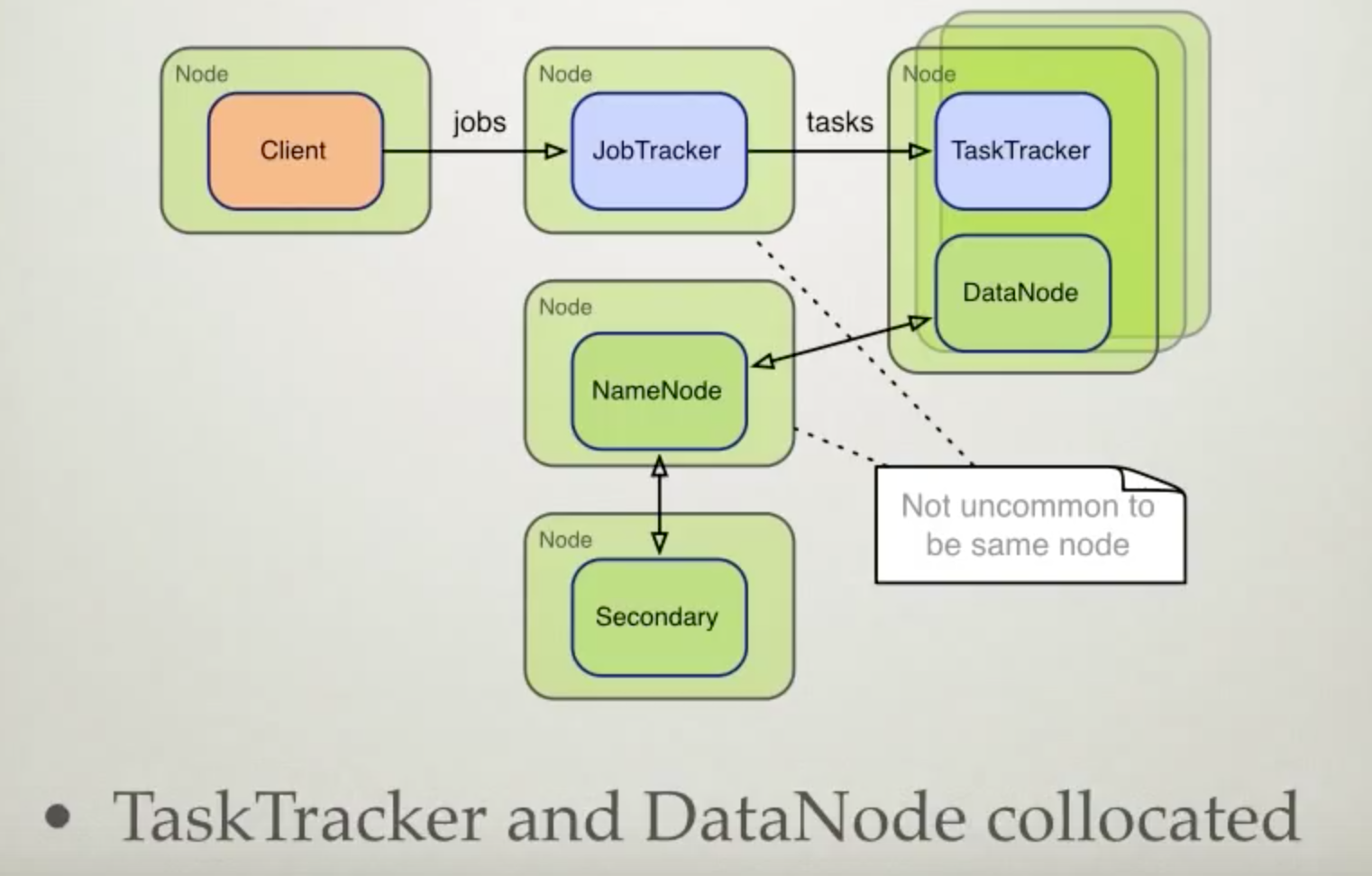
- Trackers
- JobTracker : split job into MapReduce tasks;
- TaskTracker : daemo running on data node;
- Mapper
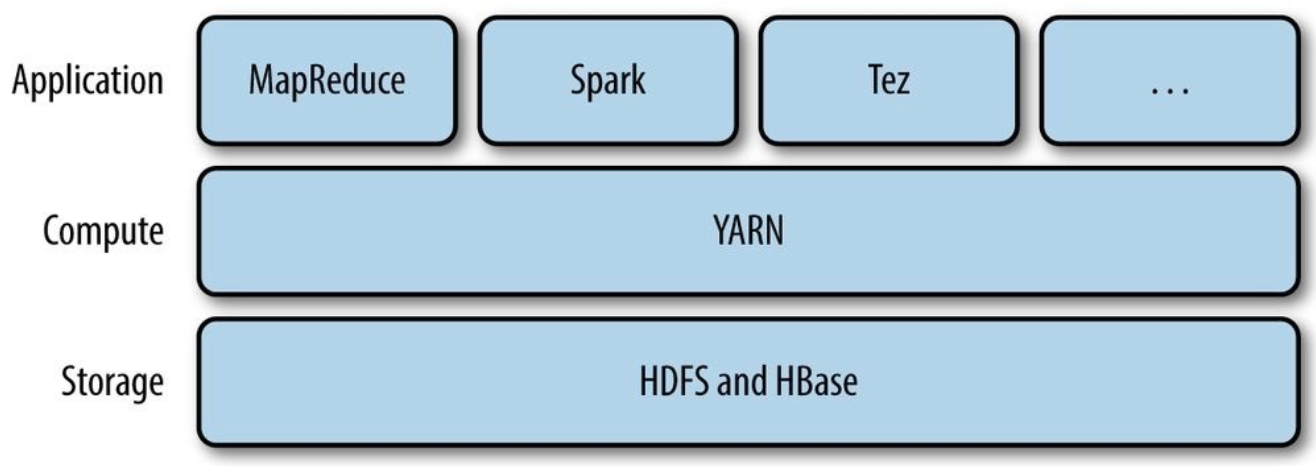
Ecosystem :
- Core Hadoop
- HDFS : Storage
- MapReduce : Processing
- SQL
- Pig/Hive : SQL working through MapReduce against HDFS; Code turned into MapReduce tasks; take long time to run; good for batch processing;
- Impala : SQL working directly against HDFS; Low latency queries;
- Apache Drill : SQL, combines a variety of data stores just by using a single query;
- Processing : Yarn
- Integration
- Sqoop : RDBMS data migration into HDFS or the other way around.
- Flume : Inject data into HDFS as it's being generated
- Others :
- Mahout : Machine Learning
- Hue : Graphical FrontEnd
- Oozie : Job Scheduler (Workflow and Coordinator)
- Workflow : sequential set of actions to be executed;
- Coordinator : job get triggered when certain condition is met (data availablity or time)
- HBase : working directly against HDFS; No SQL database; Can run without HDFS
- Spark : in-memory real-time computation; talk to HDFS directly or without HDFS;
- Ambari : cluster manager - provision, managing and monitoring Hadoop clusters.
Others :
- Defensive Programming;
- cat inputfile | mapper | sort | reducer
- hs mapper reducer inputdirectory outputdirectory;
- Combiners
- Mapper go through data
Patterns
- Filtering
- Sampling Data
- Top-N List
- Summarization
- Count/Max/Min/Avg ...
- Stastics : Mean, Median, Std. Dev ...
- Inverted Index
- Structural
- Combining Data Set
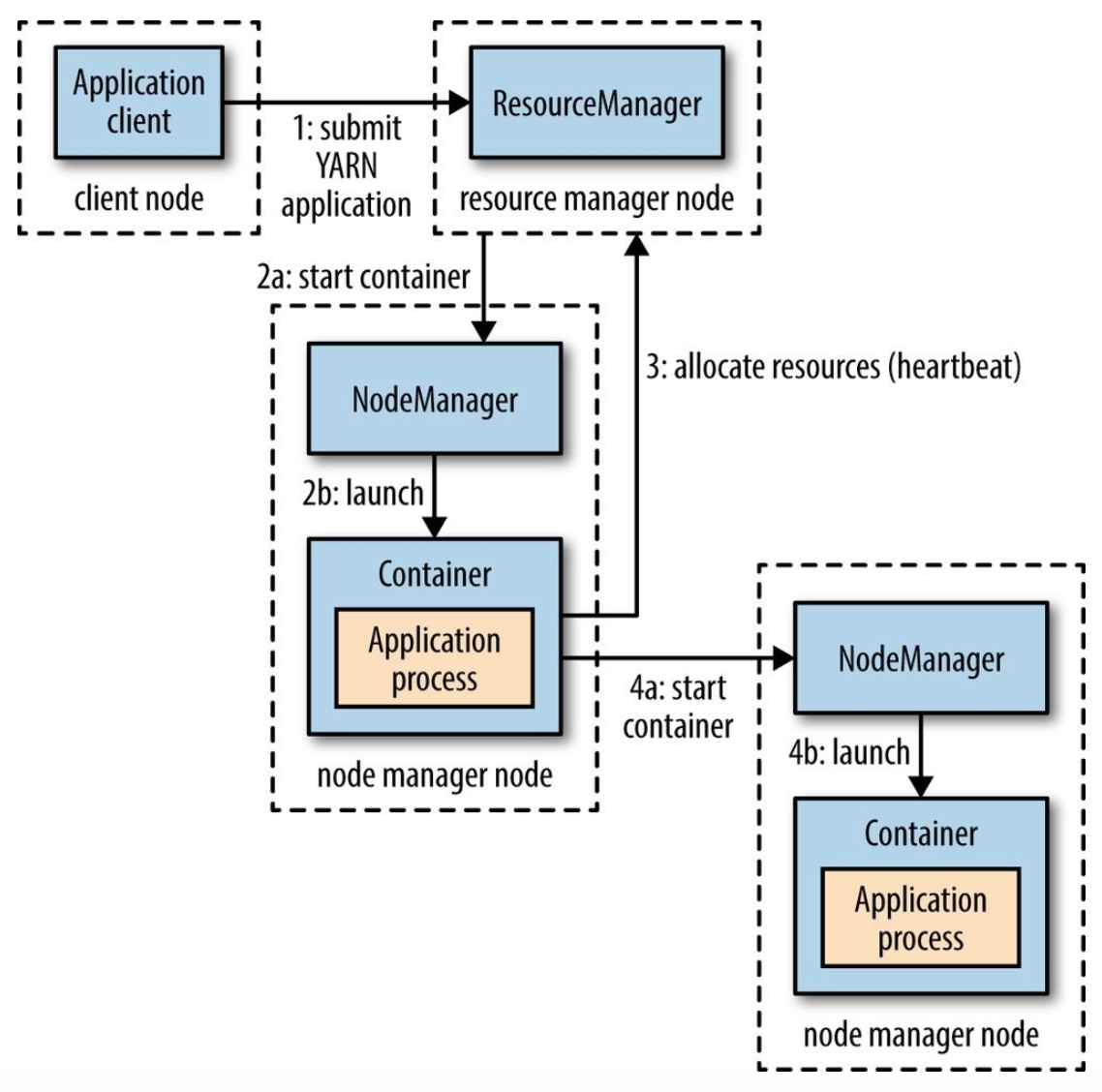
Yarn
ResourceManager: daemon running on master node;
- Cluster level resource manager
- Long life, high-quality hardware
NodeManager: daemon running on data node;
- One per data node;
- Moni
ApplicationMaster :
- One per application; Short life;
- Coordinate and Manage MapReduce jobs
- Negotiate with ResourceManager to schedule tasks
- The tasks are started by NodeManager
Job History Server:
- Maintains Information about submitted MapReduce jobs after their ApplicationMaster terminates;
Container :
- Created by NodeManager when requested;
- Allocate a certain amount of resources (CPU, Memory, etc) on a slave node;
Client -> Scheduler (RM) + ApplicationsManager (RM) -> Create AM (NM) -> Create Tasks -> Request Container (AM -> RM)
Pig
Workflow
- Pig Script ->
- Pig Server / Grunt Shell ->
- Parser ->
- Optimizer ->
- Compiler ->
- Execution Engine ->
- MapReduce -> HDFS
Components
Pig Latin:
- It is mad up of a series of operations or transformations that are applied to the input data and produce output
Pig Execution:
- Script : Contains Pig Commands in a file (.pig)
- Interactive shell for running pig commands
- Embedded : provisioning pig script in Java
Running Mode
- MapReduce Mode : running Pig over Hadoop cluster;
- command : pig
- Local Mode : local file system;
- command : pig -x local
Data Model
Tuple : row;
Bag : collection of tuples, which can contain all the fields or a few;
((field1value, field2value, field3value...), (field1value, field2value, field3value ...), ...)
Map : [Key#Value, Key#Value, Key#Value];
Atom : string, int, float, double, byte[], char[];
Operator
- LOAD : load data from local FS or HDFS into Pig;
grunt> employee = LOAD '/hdfsFile'
using PigStorage #storage type
(',') #delimiter
AS (ssn:chararray,
name:chararray,
department:chararry,
city:chararry)- STORE : save results to local FS or HDFS;
grunt> STORE emp_filter INTO '/pigresult';- FOREACH :
grunt> emp_foreach = foreach employee
generate name, department; # returning colums- FILTER :
grunt> emp_filter = filter employee
by city=='Shanghai' # condition- JOIN :
- ORDER BY :
grunt> emp_order = order employee
by ssn desc; # column to sort by- DISTINCT :
- GROUP :
- COGROUP : same as group, but handle multiple fields;
- DUMP : display the result on the screen;
Example :
# log_analysis.pig
# pig directory/log_analysis.pig
log = LOAD '/sample.log';
LEVELS = foreach log generate REGEXT_EXTRACT($0, '(TRACE|DEBUG|INFO|WARN|ERROR|FATAL)', 1) as LOGLEVEL;
FILTEREDLEVELS = FILTER LEVELS by LOGLEVEL is not null;
GROUPEDLEVELS = GROUP FILTEREDLEVELS by LOGLEVEL;
FREQUENCIES = foreach GROUPEDLEVELS generate group as LOGLEVEL, COUNT(FILTEREDLEVELS.LOGLEVEL) as COUNT;
RESULT = order FREQUENCIES by COUNT desc;
DUMP RESULT;Diagram
Cloudra















 3643
3643

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









