






实例
安装配置
- http://kafka.apache.org/documentation.html#quickstart
- https://www.confluent.io/blog/tutorial-getting-started-with-the-new-apache-kafka-0-9-consumer-client/
- assuming Zookeeper running on localhost:2181 and Kafka running on localhost:9092 (default)
# create the topic
>kafka-topics --zookeeper localhost:2181 \
--create \
--topic normal-topic \
--partitions 2 \
--replication-factor 1
# list topics
>kafka-topics --zookeeper localhost:2181 \
--list \
--topic normal-topic
# alter topics
>kafka-topics --zookeeper localhost:2181 \
--alter \
--topic normal-topic \
--partitions 2Producer
public class ProducerExample {
public static void main(String[] str) throws InterruptedException, IOException {
System.out.println("Starting ProducerExample ...");
sendMessages();
}
private static void sendMessages() throws InterruptedException, IOException {
Producer<String, String> producer = createProducer();
sendMessages(producer);
// Allow the producer to complete sending of the messages before program exit.
Thread.sleep(20);
}
/**
* Create and configure Producer
*/
private static Producer<String, String> createProducer() {
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("acks", "all");
props.put("retries", 0);
// Controls how much bytes sender would wait to batch up before publishing to Kafka.
props.put("batch.size", 10);
props.put("linger.ms", 1);
// Type of Key/Value in messages
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// Create the consumer with the defined properties
return new KafkaProducer(props);
}
private static void sendMessages(Producer<String, String> producer) {
// Specify Topic and Partition
String topic = "normal-topic";
int partition = 0;
long record = 1;
for (int i = 1; i <= 10; i++) {
// Create Message and Send via defined Producer
producer.send(new ProducerRecord<String, String>(topic,
partition,
Long.toString(record), Long.toString(record++)));
}
}
}Consumer
Consumer Registration
- Subscribe: Registration using the subscribe method call.
- Kafka rebalance available consumers when
- topic/partition gets added/deleted
- consumer gets added/deleted
- allow the consumer provide a listener in subscribe method to listen to rebalance events
- Kafka rebalance available consumers when
- Assign: Registration of consumer to Kafka with an assign method call.
- Kafka does not offer an automatic re-balance of the consumers.
- Either of the above registration options can be used for
- at-most-once
- at-least-once
- exactly-once
At-Most-Once
With this configuration of consumer, Kafka would auto commit offset at the specified interval.
- Set ‘enable.auto.commit’ to true.
- Set ‘auto.commit.interval.ms’ to a lower timeframe.
- Do not make call to consumer.commitSync(); from the consumer.
There is a chance that consumer could exhibit at-most-once or at-least-once behavior. Since at-most-once is the lower messaging guarantee, let us declare this consumer as at-most-once. Below are the explanations of such consumer behaviors.
public class AtMostOnceConsumer {
public static void main(String[] str) throws InterruptedException {
System.out.println("Starting AtMostOnceConsumer ...");
execute();
}
private static void execute() throws InterruptedException {
KafkaConsumer<String, String> consumer = createConsumer();
// Subscribe to all partition in that topic. 'assign' could be used here
// instead of 'subscribe' to subscribe to specific partition.
consumer.subscribe(Arrays.asList("normal-topic"));
processRecords(consumer);
}
private static KafkaConsumer<String, String> createConsumer() {
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
String consumeGroup = "cg1";
props.put("group.id", consumeGroup);
// Set this property, if auto commit should happen.
props.put("enable.auto.commit", "true");
// Auto commit interval, kafka would commit offset at this interval.
props.put("auto.commit.interval.ms", "101");
// This is how to control number of records being read in each poll
props.put("max.partition.fetch.bytes", "135");
// Set this if you want to always read from beginning.
// props.put("auto.offset.reset", "earliest");
// health check setting
props.put("heartbeat.interval.ms", "3000");
props.put("session.timeout.ms", "6001");
// message format setting
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
return new KafkaConsumer<String, String>(props);
}
private static void processRecords(KafkaConsumer<String, String> consumer) {
// keep listening
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
long lastOffset = 0;
for (ConsumerRecord<String, String> record : records) {
System.out.printf("\n\roffset = %d, key = %s, value = %s",
record.offset(), record.key(), record.value());
lastOffset = record.offset();
}
System.out.println("lastOffset read: " + lastOffset);
process();
}
}
private static void process() throws InterruptedException {
// create some delay to simulate processing of the message.
Thread.sleep(20);
}
}At-Least-Once
- Set ‘enable.auto.commit’ to false OR
- Set ‘enable.auto.commit’ to true with ‘auto.commit.interval.ms’ to a higher number.
- Consumer should now then take control of the message offset commits to Kafka by making the following call consumer.commitSync();
The consumer should make this commit call after it has processed the entire messages from the last poll. For this type of consumer, try to implement ‘idempotent’ behavior within consumer to avoid reprocessing of the duplicate messages.
public class AtLeastOnceConsumer {
public static void main(String[] str) throws InterruptedException {
System.out.println("Starting AutoOffsetGuranteedAtLeastOnceConsumer ...");
execute();
}
private static void execute() throws InterruptedException {
KafkaConsumer<String, String> consumer = createConsumer();
// Subscribe to all partition in that topic. 'assign' could be used here
// instead of 'subscribe' to subscribe to specific partition.
consumer.subscribe(Arrays.asList("normal-topic"));
processRecords(consumer);
}
private static KafkaConsumer<String, String> createConsumer() {
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
String consumeGroup = "cg1";
props.put("group.id", consumeGroup);
// Set this property, if auto commit should happen.
props.put("enable.auto.commit", "true");
// Make Auto commit interval to a big number so that auto commit does not happen,
// we are going to control the offset commit via consumer.commitSync(); after processing
// message.
props.put("auto.commit.interval.ms", "999999999999");
// This is how to control number of messages being read in each poll
props.put("max.partition.fetch.bytes", "135");
// health check setting
props.put("heartbeat.interval.ms", "3000");
props.put("session.timeout.ms", "6001");
// message format setting
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer","org.apache.kafka.common.serialization.StringDeserializer");
return new KafkaConsumer<String, String>(props);
}
private static void processRecords(KafkaConsumer<String, String> consumer) throws {
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
long lastOffset = 0;
for (ConsumerRecord<String, String> record : records) {
System.out.printf("\n\roffset = %d, key = %s, value = %s", record.offset(), record.key(), record.value());
lastOffset = record.offset();
}
System.out.println("lastOffset read: " + lastOffset);
process();
// Below call is important to control the offset commit. Do this call after you
// finish processing the business process.
consumer.commitSync();
}
}
private static void process() throws InterruptedException {
// create some delay to simulate processing of the record.
Thread.sleep(20);
}
}Exactly-Once (Dynamic via Subscribe)
- Set enable.auto.commit = false.
- Do not make call to consumer.commitSync(); after processing message.
- Register consumer to a topic by making a ‘subscribe’ call. Subscribe call behavior is explained earlier in the article.
- Implement a ConsumerRebalanceListener and within the listener perform consumer.seek(topicPartition,offset); to start reading from a specific offset of that topic/partition.
- While processing the messages, get hold of the offset of each message. Store the processed message’s offset in an atomic way along with the processed message using atomic-transaction.
- When data is stored in relational database atomicity is easier to implement.
- For non-relational data-store such as HDFS store or No-SQL store one way to achieve atomicity is as follows: Store the offset along with the message.
- Implement idempotent as a safety net.
public class ExactlyOnceDynamicConsumer {
private static OffsetManager offsetManager = new OffsetManager("storage2");
public static void main(String[] str) throws InterruptedException {
System.out.println("Starting ExactlyOnceDynamicConsumer ...");
readMessages();
}
private static void readMessages() throws InterruptedException {
KafkaConsumer<String, String> consumer = createConsumer();
// Manually controlling offset but register consumer to topics to get dynamically
// assigned partitions. Inside MyConsumerRebalancerListener use
// consumer.seek(topicPartition,offset) to control offset which messages to be read.
consumer.subscribe(Arrays.asList("normal-topic"), new MyConsumerRebalancerListener(consumer));
processRecords(consumer);
}
private static KafkaConsumer<String, String> createConsumer() {
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
String consumeGroup = "cg3";
props.put("group.id", consumeGroup);
// Below is a key setting to turn off the auto commit.
props.put("enable.auto.commit", "false");
// health check setting
props.put("heartbeat.interval.ms", "2000");
props.put("session.timeout.ms", "6001");
// Control maximum data on each poll, make sure this value is bigger than the maximum
// single message size
props.put("max.partition.fetch.bytes", "140");
// message format setting
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
return new KafkaConsumer<String, String>(props);
}
private static void processRecords(KafkaConsumer<String, String> consumer) {
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records) {
System.out.printf("offset = %d, key = %s, value = %s\n",
record.offset(), record.key(), record.value());
// Save processed offset in external storage.
offsetManager.saveOffsetInExternalStore(record.topic(), record.partition(), record.offset());
}
}
}
}
public class MyConsumerRebalancerListener implements org.apache.kafka.clients.consumer.ConsumerRebalanceListener {
private OffsetManager offsetManager = new OffsetManager("storage2");
private Consumer<String, String> consumer;
public MyConsumerRebalancerListener(Consumer<String, String> consumer) {
this.consumer = consumer;
}
public void onPartitionsRevoked(Collection<TopicPartition> partitions) {
for (TopicPartition partition : partitions) {
offsetManager.saveOffsetInExternalStore(partition.topic(), partition.partition(), consumer.position(partition));
}
}
public void onPartitionsAssigned(Collection<TopicPartition> partitions) {
for (TopicPartition partition : partitions) {
consumer.seek(partition, offsetManager.readOffsetFromExternalStore(partition.topic(), partition.partition()));
}
}
}
/**
* The partition offset are stored in an external storage. In this case in a local file system where
* program runs.
*/
public class OffsetManager {
private String storagePrefix;
public OffsetManager(String storagePrefix) {
this.storagePrefix = storagePrefix;
}
/**
* Overwrite the offset for the topic in an external storage.
*
* @param topic - Topic name.
* @param partition - Partition of the topic.
* @param offset - offset to be stored.
*/
void saveOffsetInExternalStore(String topic, int partition, long offset) {
try {
FileWriter writer = new FileWriter(storageName(topic, partition), false);
BufferedWriter bufferedWriter = new BufferedWriter(writer);
bufferedWriter.write(offset + "");
bufferedWriter.flush();
bufferedWriter.close();
} catch (Exception e) {
e.printStackTrace();
throw new RuntimeException(e);
}
}
/**
* @return he last offset + 1 for the provided topic and partition.
*/
long readOffsetFromExternalStore(String topic, int partition) {
try {
Stream<String> stream = Files.lines(Paths.get(storageName(topic, partition)));
return Long.parseLong(stream.collect(Collectors.toList()).get(0)) + 1;
} catch (Exception e) {
e.printStackTrace();
}
return 0;
}
private String storageName(String topic, int partition) {
return storagePrefix + "-" + topic + "-" + partition;
}
}Exactly-Once (Static Consumer via Assign)
- Set enable.auto.commit = false
- Don’t make call to consumer.commitSync(); after processing message.
- Register consumer to specific partition using ‘assign’ call.
- On start up of the consumer seek to specific message offset by calling consumer.seek(topicPartition,offset);
- While processing the messages, get hold of the offset of each message. Store the processed message’s offset in an atomic way along with the processed message using atomic-transaction. When data is stored in relational database atomicity is easier to implement. For non-relational data-store such as HDFS store or No-SQL store one way to achieve atomicity is as follows: Store the offset along with the message.
public class ExactlyOnceStaticConsumer {
private static OffsetManager offsetManager = new OffsetManager("storage1");
public static void main(String[] str) throws InterruptedException, IOException {
System.out.println("Starting ExactlyOnceStaticConsumer ...");
readMessages();
}
private static void readMessages() throws InterruptedException, IOException {
KafkaConsumer<String, String> consumer = createConsumer();
String topic = "normal-topic";
int partition = 1;
TopicPartition topicPartition = registerConsumerToSpecificPartition(consumer, topic, partition);
// EVERYTIME: Read the offset for the topic and partition from external storage
long offset = offsetManager.readOffsetFromExternalStore(topic, partition);
// EVERYTIME: Use seek and go to exact offset for that topic and partition.
consumer.seek(topicPartition, offset);
processRecords(consumer);
}
private static KafkaConsumer<String, String> createConsumer() {
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
String consumeGroup = "cg2";
props.put("group.id", consumeGroup);
// Below is a key setting to turn off the auto commit.
props.put("enable.auto.commit", "false");
// health check setting
props.put("heartbeat.interval.ms", "2000");
props.put("session.timeout.ms", "6001");
// control maximum data on each poll, make sure this value is bigger than the maximum
// single message size
props.put("max.partition.fetch.bytes", "140");
// message format setting
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
return new KafkaConsumer<String, String>(props);
}
/**
* Manually listens for specific topic partition. But, if you are looking for example of how to
* dynamically listens to partition and want to manually control offset then see
* ExactlyOnceDynamicConsumer.java
*/
private static TopicPartition registerConsumerToSpecificPartition(
KafkaConsumer<String, String> consumer, String topic, int partition) {
TopicPartition topicPartition = new TopicPartition(topic, partition);
List<TopicPartition> partitions = Arrays.asList(topicPartition);
consumer.assign(partitions);
return topicPartition;
}
/**
* Process data and store offset in external store. Best practice is to do these operations
* atomically.
*/
private static void processRecords(KafkaConsumer<String, String> consumer) throws {
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records) {
System.out.printf("offset = %d, key = %s, value = %s\n", record.offset(), record.key(), record.value());
offsetManager.saveOffsetInExternalStore(record.topic(), record.partition(), record.offset());
}
}
}
}对比
| RabbitMQ | RabbitMQ是使用Erlang编写的一个开源的消息队列,本身支持很多的协议:AMQP,XMPP, SMTP, STOMP,也正因如此,它非常重量级,更适合于企业级的开发。
|
| Redis | Redis是一个基于Key-Value对的NoSQL数据库,开发维护很活跃。虽然它是一个Key-Value数据库存储系统,但它本身支持MQ功能,所以完全可以当做一个轻量级的队列服务来使用。对于RabbitMQ和Redis的入队和出队操作,各执行100万次,每10万次记录一次执行时间。测试数据分为128Bytes、512Bytes、1K和10K四个不同大小的数据。实验表明:
|
| ZeroMQ | ZeroMQ号称最快的消息队列系统,尤其针对大吞吐量的需求场景。ZeroMQ能够实现RabbitMQ不擅长的高级/复杂的队列,但是开发人员需要自己组合多种技术框架,技术上的复杂度是对这MQ能够应用成功的挑战。
|
| ActiveMQ | ActiveMQ是Apache下的一个子项目。 类似于ZeroMQ,它能够以代理人和点对点的技术实现队列。同时类似于RabbitMQ,它少量代码就可以高效地实现高级应用场景。 |
| Kafka/Jafka | Kafka是Apache下的一个子项目,是一个高性能跨语言分布式发布/订阅消息队列系统,而Jafka是在Kafka之上孵化而来的,即Kafka的一个升级版。具有以下特性:快速持久化,可以在O(1)的系统开销下进行消息持久化;高吞吐,在一台普通的服务器上既可以达到10W/s的吞吐速率;完全的分布式系统,Broker、Producer、Consumer都原生自动支持分布式,自动实现负载均衡;支持Hadoop数据并行加载,对于像Hadoop的一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。Kafka通过Hadoop的并行加载机制统一了在线和离线的消息处理。Apache Kafka相对于ActiveMQ是一个非常轻量级的消息系统,除了性能非常好之外,还是一个工作良好的分布式系统。 |
Overview
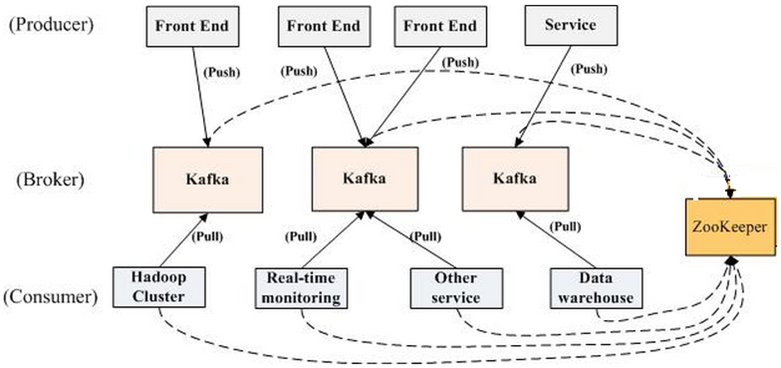
| Broker | Kafka集群包含一个或多个服务器,这种服务器被称为broker |
| Producer | 负责发布消息到Kafka broker |
| Consumer | 消息消费者,向Kafka broker读取消息的客户端。 |
| Topic | 每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。(物理上不同Topic的消息分开存储,逻辑上一个Topic的消息虽然保存于一个或多个broker上但用户只需指定消息的Topic即可生产或消费数据而不必关心数据存于何处) |
| Partition | Parition是物理上的概念,每个Topic包含一个或多个Partition. |
| Consumer Group | 每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group name,若不指定group name则属于默认的group)。 |
Topic&Partition
Topic
- Topic是逻辑上的概念,可以被认为是一个queue。Parition是物理存储上的概念,创建Topic时可指定Parition数量。Topic进行分区划分的主要目的是出于性能方面的考虑。
- 若创建topic1和topic2两个topic,且分别有13个和19个分区,则整个集群上会相应会生成共32个文件夹(本文所用集群共8个节点,此处topic1和topic2 replication-factor均为1)。
- Producer可将消息发布到指定的Topic中;同时Producer也能决定将此消息发送到哪个Parition(也可以采取随机、哈希、轮训等策略)。
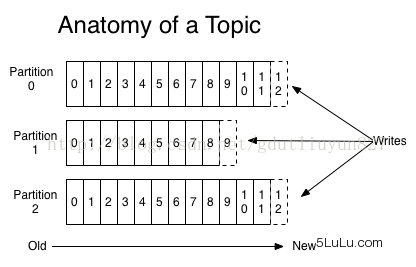
Partition
- 每个Partition在物理上对应一个文件夹。该文件夹下存储这个Partition的所有消息和索引文件。
- 每个Parition是一个有序的队列,每条消息在Parition中拥有一个offset。
- 新消息是添加在文件末尾,不论文件数据文件有多大,这个操作永远都是O(1)。
- 但是在读取的时候根据offset查找Message是顺序查找的,因此,如果数据文件很大的话,查找的效率就低。Kafka通过分段和索引解决查询效率问题。
- Kafka尽量的使所有分区均匀的分布到集群所有的节点上而不是集中在某些节点上,另外主从关系也尽量均衡,这样每个节点都会担任一定比例的分区的Leader。
Segment and Index
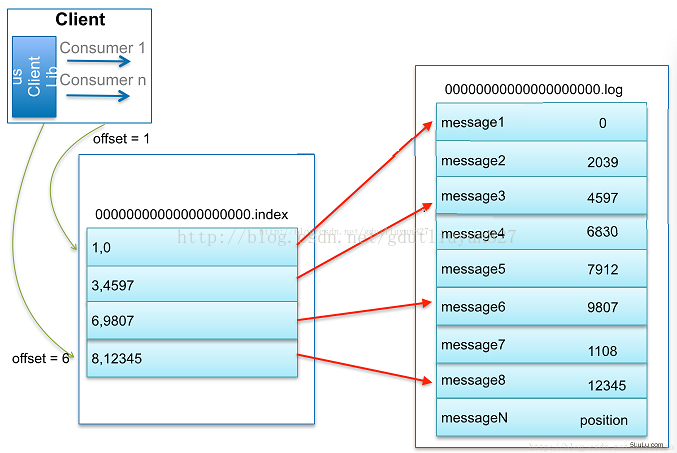
- Kafka 解决查询效率的手段之一是将数据文件分段,可以配置每个数据文件的最大值,每段放在一个单独的数据文件里面,数据文件以该段中最小的offset命名。这样在查找指定offset的Message的时候,用二分查找就可以定位到该Message在哪个段中。
- 数据文件分段使得可以在一个较小的数据文件中查找对应offset的Message了,但是这依然需要顺序扫描才能找到对应offset的Message。为了进一步提高查找的效率,Kafka为每个分段后的数据文件建立了索引文件,文件名与数据文件的名字是一样的,只是文件扩展名为.index。索引文件中包含若干个索引条目,每个条目表示数据文件中一条Message的索引——Offset与position(Message在数据文件中的绝对位置)的对应关系;
- index文件中并没有为数据文件中的每条Message建立索引,而是采用了稀疏存储的方式,每隔一定字节的数据建立一条索引。这样避免了索引文件占用过多的空间,从而可以将索引文件保留在内存中。但缺点是没有建立索引的Message也不能一次定位到其在数据文件的位置,从而需要做一次顺序扫描,但是这次顺序扫描的范围就很小了。
- 每个分段还有一个.timeindex索引文件,这个文件的格式与.index文件格式一样,所记录的东西是消息发布时间与offset的稀疏索引,用于消息定期删除使用。
- 这套机制是建立在offset是有序的;索引文件被映射到内存中,所以查找的速度还是很快的。一句话,Kafka的Message存储采用了分区(Parition)、分段(segment)和稀疏索引这几个手段来达到高效发布和随机读取。
Replication
default.replication.factor = 1- 默认情况下,Kafka的replication数量为1。 每个partition都有一个唯一的leader。
- 一般情况下partition的数量大于等于broker的数量,并且所有partition的leader均匀分布在broker上。follower上的日志和其leader上的完全一样。
- 所有的读写操作都在leader上完成,follower批量从leader上pull数据。
- Replication与Leader Election配合提供了自动的failover机制。Kafka只解决”fail/recover”,不处理"Byzantine"(“拜占庭”)问题。
- Replication对Kafka的吞吐率是有一定影响的,但极大的增强了可用性。
Follower Alive
和大部分分布式系统一样,Kakfa处理失败需要明确定义一个broker是否alive。对于Kafka而言,Kafka存活包含两个条件,
- 一是它必须维护与Zookeeper的session(这个通过Zookeeper的heartbeat机制来实现)。
- 二是follower必须能够及时将leader的writing复制过来,不能“落后太多”。
Leader会track“in sync”的node list。如果一个follower宕机,或者落后太多,leader将把它从”in sync” list中移除。这里所描述的“落后太多”指follower复制的消息落后于leader后的条数超过预定值,该值可在$KAFKA_HOME/config/server.properties中配置
In Sync List
- 一条消息只有被“ in sync” list里的所有follower都从leader复制过去才会被认为已提交。这样就避免了部分数据被写进了leader,还没来得及被任何follower复制就宕机了,而造成数据丢失(consumer无法消费这些数据)。
- 而对于producer而言,它可以选择是否等待commit消息,这可以通过
request.required.acks来设置。这种机制确保了只要“ in sync” list有一个或以上的flollower,一条被commit的消息就不会丢失。 - 这里的复制机制即不是同步复制,也不是单纯的异步复制。
- 同步复制要求“活着的”follower都复制完,这条消息才会被认为commit,这种复制方式极大的影响了吞吐率(高吞吐率是Kafka非常重要的一个特性)。
- 异步复制方式下,follower异步的从leader复制数据,数据只要被leader写入log就被认为已经commit,这种情况下如果follwer都落后于leader,而leader突然宕机,则会丢失数据
- Kafka的这种使用“ in sync” list的方式则很好的均衡了确保数据不丢失以及吞吐率。follower可以批量的从leader复制数据,这样极大的提高复制性能(批量写磁盘),极大减少了follower与leader的差距(前文有说到,只要follower落后leader不太远,则被认为在“ in sync” list里)。
LeaderElection
和大部分分布式系统一样,Kakfa处理失败需要明确定义一个broker是否alive。对于Kafka而言,Kafka存活包含两个条件,一是它必须维护与Zookeeper的session(这个通过Zookeeper的heartbeat机制来实现)。二是follower必须能够及时将leader的writing复制过来,不能“落后太多”。
leader会track“in sync”的node list。如果一个follower宕机,或者落后太多,leader将把它从”in sync” list中移除。这里所描述的“落后太多”指follower复制的消息落后于leader后的条数超过预定值,该值可在$KAFKA_HOME/config/server.properties中配置
Message
- 消息格式如下
- message length:4 bytes (value: 1+4+n)
- “magic” value:1 byte
- crc:4 bytes
- payload:n bytes
Delivery Guarantee
发布到Kafka的消息在一个Parition中是顺序存储的,发布者可以通过随机、哈希、轮训等方式发布到多个分区中,消费者通过指定offset进行消费;所以Kafka当中消息的顺序性更多的取决于使用方如何使用。
- 发布时的可靠性取决于两点:
- 发送端的确认机制:
- 发送端支持无确认。
- 主分区确认(主分区收到消息后发送确认回执,无需等待备份分区确认,也就是异步写入)。
- 主备分区确认(主分区收到消息后等待备份分区确认,只有备份分区确认后才发送确认回执。同步写入)。
- Kafka系统落地的策略:
- 通过配置消息数
- 配置刷盘时间间隔。
- 发送端的确认机制:
- 消费时的可靠性取决于消费者的读取逻辑,Kafka是不保存消息的任何状态的。At most once、At least once 、Exactly once 三种模式需要自己按照业务实现。最容易实现就是At least once,两外两种在分布式系统中都不可能做到完全的绝对实现,只能无限靠近,降低错误率。
Push vs. Pull
作为一个消息系统,Kafka遵循了传统的方式,选择由Producer向broker push消息并由Consumer从broker pull消息。一些logging-centric system,比如Facebook的Scribe和Cloudera的Flume,采用push模式。事实上,push模式和pull模式各有优劣。
push模式很难适应消费速率不同的消费者,因为消息发送速率是由broker决定的。push模式的目标是尽可能以最快速度传递消息,但是这样很容易造成Consumer来不及处理消息,典型的表现就是拒绝服务以及网络拥塞。而pull模式则可以根据Consumer的消费能力以适当的速率消费消息。
对于Kafka而言,pull模式更合适。pull模式可简化broker的设计,Consumer可自主控制消费消息的速率,同时Consumer可以自己控制消费方式——即可批量消费也可逐条消费,同时还能选择不同的提交方式从而实现不同的传输语义。
Kafka Delivery Guarantee
有这么几种可能的delivery guarantee:
- At Most Once 消息可能会丢,但绝不会重复传输
- At Least Onne 消息绝不会丢,但可能会重复传输
- Exactly Once 每条消息肯定会被传输一次且仅传输一次,很多时候这是用户所想要的。
- 当Producer向broker发送消息时,一旦这条消息被commit,因数replication的存在,它就不会丢。但是如果Producer发送数据给broker后,遇到网络问题而造成通信中断,那Producer就无法判断该条消息是否已经commit。虽然Kafka无法确定网络故障期间发生了什么,但是Producer可以生成一种类似于主键的东西,发生故障时幂等性的重试多次,这样就做到了Exactly once。截止到目前(Kafka 0.8.2版本,2015-03-04),这一Feature还并未实现,有希望在Kafka未来的版本中实现。(所以目前默认情况下一条消息从Producer到broker是确保了At least once,可通过设置Producer异步发送实现At most once)。
- 接下来讨论的是消息从broker到Consumer的delivery guarantee语义。(仅针对Kafka consumer high level API)。Consumer在从broker读取消息后,可以选择commit,该操作会在Zookeeper中保存该Consumer在该Partition中读取的消息的offset。该Consumer下一次再读该Partition时会从下一条开始读取。如未commit,下一次读取的开始位置会跟上一次commit之后的开始位置相同。当然可以将Consumer设置为autocommit,即Consumer一旦读到数据立即自动commit。如果只讨论这一读取消息的过程,那Kafka是确保了Exactly once。但实际使用中应用程序并非在Consumer读取完数据就结束了,而是要进行进一步处理,而数据处理与commit的顺序在很大程度上决定了消息从broker和consumer的delivery guarantee semantic。
- 读完消息先commit再处理消息。这种模式下,如果Consumer在commit后还没来得及处理消息就crash了,下次重新开始工作后就无法读到刚刚已提交而未处理的消息,这就对应于At most once
- 读完消息先处理再commit。这种模式下,如果在处理完消息之后commit之前Consumer crash了,下次重新开始工作时还会处理刚刚未commit的消息,实际上该消息已经被处理过了。这就对应于At least once。在很多使用场景下,消息都有一个主键,所以消息的处理往往具有幂等性,即多次处理这一条消息跟只处理一次是等效的,那就可以认为是Exactly once。(笔者认为这种说法比较牵强,毕竟它不是Kafka本身提供的机制,主键本身也并不能完全保证操作的幂等性。而且实际上我们说delivery guarantee 语义是讨论被处理多少次,而非处理结果怎样,因为处理方式多种多样,我们不应该把处理过程的特性——如是否幂等性,当成Kafka本身的Feature)
- 如果一定要做到Exactly once,就需要协调offset和实际操作的输出。精典的做法是引入两阶段提交。如果能让offset和操作输入存在同一个地方,会更简洁和通用。这种方式可能更好,因为许多输出系统可能不支持两阶段提交。比如,Consumer拿到数据后可能把数据放到HDFS,如果把最新的offset和数据本身一起写到HDFS,那就可以保证数据的输出和offset的更新要么都完成,要么都不完成,间接实现Exactly once。(目前就high level API而言,offset是存于Zookeeper中的,无法存于HDFS,而low level API的offset是由自己去维护的,可以将之存于HDFS中)
总之,Kafka默认保证At least once,并且允许通过设置Producer异步提交来实现At most once。而Exactly once要求与外部存储系统协作,幸运的是Kafka提供的offset可以非常直接非常容易得使用这种方式。
Streaming
- Request/Response: one input & one output
- Batch: all input & all output
- Streaming: some input & some output
Issues to Solve
- Partitioning and Scalability: spread program&data over many machines, being able to add/shrink the cluster elastically.
- Semantics and Fault Tolerance: how to handle failures.
- Unifying Tables and Streams: table=what available currently in hands (stock for example)
- Time:
- Re-processing:
Kafka
What
A distributed system that maintains the stream of data in a fault tolerant way, which sit in between Producers and Consumers as a message broker.
How
Kafka is a log store in which each log entry (record/line) is given a formal number (id), just like a database commit log.
Stream
Stream is a sequence record of logs, the thing is how to organize, partition and consume them. Stream processing = Logs + App Code..
- Logs -> App Code -> Logs
Maintaining a log of state changes.
Log Compaction
Groups
Allow scaling the consumers. Partitioning, Groups, Consumers.
Time
Being able to deal with late arrival data.
Structure
- Producer
- Consumer
- Kafaka Cluster
- Zookeeper
基于ISR的数据复制方案
如《 Kafka High Availability(上)》一文所述,Kafka的数据复制是以Partition为单位的。而多个备份间的数据复制,通过Follower向Leader拉取数据完成。从一这点来讲,Kafka的数据复制方案接近于上文所讲的Master-Slave方案。不同的是,Kafka既不是完全的同步复制,也不是完全的异步复制,而是基于ISR的动态复制方案。
ISR,也即In-sync Replica。每个Partition的Leader都会维护这样一个列表,该列表中,包含了所有与之同步的Replica(包含Leader自己)。每次数据写入时,只有ISR中的所有Replica都复制完,Leader才会将其置为Commit,它才能被Consumer所消费。
这种方案,与同步复制非常接近。但不同的是,这个ISR是由Leader动态维护的。如果Follower不能紧“跟上”Leader,它将被Leader从ISR中移除,待它又重新“跟上”Leader后,会被Leader再次加加ISR中。每次改变ISR后,Leader都会将最新的ISR持久化到Zookeeper中。
至于如何判断某个Follower是否“跟上”Leader,不同版本的Kafka的策略稍微有些区别。
- 对于0.8.*版本,如果Follower在replica.lag.time.max.ms时间内未向Leader发送Fetch请求(也即数据复制请求),则Leader会将其从ISR中移除。如果某Follower持续向Leader发送Fetch请求,但是它与Leader的数据差距在replica.lag.max.messages以上,也会被Leader从ISR中移除。
- 从0.9.0.0版本开始,replica.lag.max.messages被移除,故Leader不再考虑Follower落后的消息条数。另外,Leader不仅会判断Follower是否在replica.lag.time.max.ms时间内向其发送Fetch请求,同时还会考虑Follower是否在该时间内与之保持同步。
- 0.10.* 版本的策略与0.9.*版一致
对于0.8.*版本的replica.lag.max.messages参数,很多读者曾留言提问,既然只有ISR中的所有Replica复制完后的消息才被认为Commit,那为何会出现Follower与Leader差距过大的情况。原因在于,Leader并不需要等到前一条消息被Commit才接收后一条消息。事实上,Leader可以按顺序接收大量消息,最新的一条消息的Offset被记为High Wartermark。而只有被ISR中所有Follower都复制过去的消息才会被Commit,Consumer只能消费被Commit的消息。由于Follower的复制是严格按顺序的,所以被Commit的消息之前的消息肯定也已经被Commit过。换句话说,High Watermark标记的是Leader所保存的最新消息的offset,而Commit Offset标记的是最新的可被消费的(已同步到ISR中的Follower)消息。而Leader对数据的接收与Follower对数据的复制是异步进行的,因此会出现Commit Offset与High Watermark存在一定差距的情况。0.8.*版本中replica.lag.max.messages限定了Leader允许的该差距的最大值。
Kafka基于ISR的数据复制方案原理如下图所示。
(点击放大图像)

如上图所示,在第一步中,Leader A总共收到3条消息,故其high watermark为3,但由于ISR中的Follower只同步了第1条消息(m1),故只有m1被Commit,也即只有m1可被Consumer消费。此时Follower B与Leader A的差距是1,而Follower C与Leader A的差距是2,均未超过默认的replica.lag.max.messages,故得以保留在ISR中。在第二步中,由于旧的Leader A宕机,新的Leader B在replica.lag.time.max.ms时间内未收到来自A的Fetch请求,故将A从ISR中移除,此时ISR={B,C}。同时,由于此时新的Leader B中只有2条消息,并未包含m3(m3从未被任何Leader所Commit),所以m3无法被Consumer消费。第四步中,Follower A恢复正常,它先将宕机前未Commit的所有消息全部删除,然后从最后Commit过的消息的下一条消息开始追赶新的Leader B,直到它“赶上”新的Leader,才被重新加入新的ISR中。
使用ISR方案的原因
- 由于Leader可移除不能及时与之同步的Follower,故与同步复制相比可避免最慢的Follower拖慢整体速度,也即ISR提高了系统可用性。
- ISR中的所有Follower都包含了所有Commit过的消息,而只有Commit过的消息才会被Consumer消费,故从Consumer的角度而言,ISR中的所有Replica都始终处于同步状态,从而与异步复制方案相比提高了数据一致性。
- ISR可动态调整,极限情况下,可以只包含Leader,极大提高了可容忍的宕机的Follower的数量。与Majority Quorum方案相比,容忍相同个数的节点失败,所要求的总节点数少了近一半。
ISR相关配置说明
- Broker的min.insync.replicas参数指定了Broker所要求的ISR最小长度,默认值为1。也即极限情况下ISR可以只包含Leader。但此时如果Leader宕机,则该Partition不可用,可用性得不到保证。
- 只有被ISR中所有Replica同步的消息才被Commit,但Producer发布数据时,Leader并不需要ISR中的所有Replica同步该数据才确认收到数据。Producer可以通过acks参数指定最少需要多少个Replica确认收到该消息才视为该消息发送成功。acks的默认值是1,即Leader收到该消息后立即告诉Producer收到该消息,此时如果在ISR中的消息复制完该消息前Leader宕机,那该条消息会丢失。而如果将该值设置为0,则Producer发送完数据后,立即认为该数据发送成功,不作任何等待,而实际上该数据可能发送失败,并且Producer的Retry机制将不生效。更推荐的做法是,将acks设置为all或者-1,此时只有ISR中的所有Replica都收到该数据(也即该消息被Commit),Leader才会告诉Producer该消息发送成功,从而保证不会有未知的数据丢失。















 20万+
20万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









